Безопасность машинного обучения: эффективные методы защиты или новые угрозы?
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-07-11 21:09
Одними из самых популярных и обсуждаемых новостей последние несколько лет являются — кто куда добавил искусственный интеллект и какие хакеры что и где сломали. Соединив эти темы, появляются очень интересные исследования, и на хабре уже было несколько статей посвященных тому, что есть возможность обманывать модели машинного обучения, к примеру: статья про ограничения глубокого обучения, про то как омбанывать нейронные сети. Далее хотелось бы рассмотреть подробней эту тему с точки зрения компьютерной безопасности:

Рассмотрим следующие вопросы:
- Важные термины.
- Что такое машинное обучение, если вдруг вы все еще не знали.
- При чем тут компьютерная безопасность?!
- Можно ли манипулировать моделью машинного обучения, чтобы провести целевую атаку?
- Можно ли ухудшить производительность системы?
- Можно ли воспользоваться ограничениями моделей машинного обучения?
- Категоризация атак.
- Способы защиты.
- Возможные последствия.
1. Первое, с чего хотелось бы начать — с терминологии.
Возможное данное утверждение может вызвать большой холивар со стороны как научного, так и профессионального сообщества в силу уже написанных нескольких статей на русском, но хотелось бы отметить, что термин «adversarial intelligence» переводится как «разведка противника». А само слово «adversarial» стоило бы переводить не юридическим термином «состязательный», а более подходящим термином из безопасности «вредоносный» (к переводу названия архитектуры нейронной сети претензий нет). Тогда все сопутствующие термины на русском языке приобретают куда более яркий смысл, такие как «adversarial example» — вредоносный экземпляр данных, «adversarial settings» — вредоносная среда. А саму область, которую мы будем рассматривать «adversarial machine learning» — вредоносное машинное обучение.
По крайне мере в рамках данной статьи будут использоваться именно такие термины на русском. Надеюсь, удастся показать, что эта тема куда больше про безопасность, чтобы справедливо пользоваться терминами именно из этой области, а не первым примером из переводчика.
Так вот, теперь, когда мы готовы говорить на одном языке, можно начинать по сути :)
2. Что такое машинное обучение, если вдруг вы все еще не знали
Под методами машинного обучения обычно мы понимаем такие методы построения алгоритмов, которые способны обучаться и действовать без явного программирования их поведения на заранее подобранных данных. Под данными мы можем подразумевать все что угодно, если мы можем описать это какими-то признаками либо измерить. Если есть какой-то признак, который для части данных неизвестен, а нам он очень нужен, мы применяем методы машинного обучения, чтобы, основываясь на уже известных данных, этот признак восстановить или предсказать.
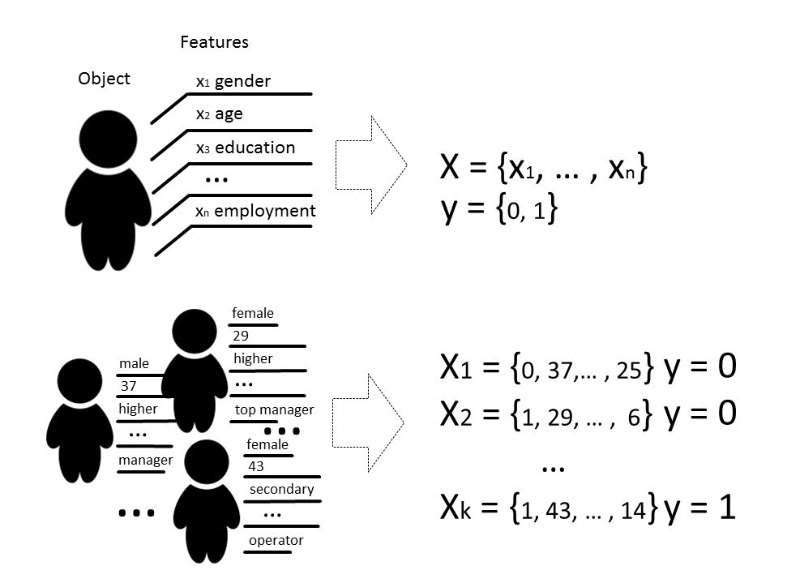
Существует несколько видов задач, которые решаются с помощью машинного обучения, но мы будем говорить по большей части о задаче классификации.
Классически цель стадии обучения модели классификатора — подобрать такую зависимость (функцию), которая покажет соответствие между признаками конкретного объекта и одним из известных классов. В более сложном случае требуется предсказание вероятности принадлежности к той или иной категории.
То есть задачей классификации является построение такой гиперплоскости, которая разделит пространство, где, как правило, его размерностью является размер вектора признаков, — чтобы объекты разных классов лежали по разные стороны от этой гиперплоскости.
Для двумерного пространства такая гиперплоскость это линия. Рассмотрим простой пример:

На рисунке можно увидеть два класса, квадраты и треугольники. Найти зависимость и наиболее точно разделить их линейной функцией невозможно. Поэтому с помощью машинного обучения можно подобрать такую нелинейную функцию, которая бы наилучшим образом разделяла эти два множества.
Задача классификации — довольно типичная задача обучения с учителем. Для обучения модели необходим такой набор данных, чтобы можно было выделить признаки объекта и его класс.
3. При чем тут компьютерная безопасность?!
В компьютерной безопасности различные методы машинного обучения давно применяются в фильтрации спама, анализе трафика, при обнаружении фрода или вредоносного программного обеспечения.
И в каком-то смысле это игра, где сделав ход, ты ожидаешь реакции противника. Поэтому, играя в эту игру, постоянно приходится корректировать модели, обучая на новых данных, — или менять их полностью с учетом последних достижений науки.
К примеру, в то время, как антивирусы используют сигнатурный анализ, эвристики и правила, составленные вручную, которые довольно трудно поддерживать и расширять, индустрия безопасности все же спорит о реальной пользе антивируса и многие считают антивирусы мертвым продуктом. Все эти правила злоумышленники обходят, к примеру, с помощью обфускации и полиморфизма. В итоге предпочтение отдается инструментам, использующим более интеллектуальные техники, например методы машинного обучения, которые позволяют автоматически выделять признаки (даже такие, которые не интерпретируются человеком), могут быстро обрабатывать большие объемы информации, обобщать их и быстро принимать решения.
То есть, с одной стороны, машинное обучение применяется для защиты как некоторый инструмент. С другой же, этот инструмент применяется и для более интеллектуальных атак.
Посмотрим, может ли этот инструмент быть уязвимым?
Для любого алгоритма очень важен не только сам подбор параметров, но и данные, на которых алгоритм обучается. Конечно, в идеальной ситуации необходимо, чтобы данных для обучения было достаточно, классы были бы сбалансированными, а время на обучение прошло незаметно, что в реальной жизни практически невозможно.
Под качеством натренированной модели обычно понимается точность классификации на данных, которых модель еще «не видела», в общем случае — как некоторое отношение правильно классифицированных экземпляров данных к общему количеству данных, которое мы передали модели.
Вообще все оценки качества напрямую связаны с предположениями об ожидаемом распределении входных данных системы и не учитывают вредоносные условия среды (adversarial settings), которые часто выходят за рамки ожидаемого распределения входных данных. Под вредоносной средой понимается такое окружение, где есть возможность противостоять или взаимодействовать с системой. Типичные примеры таких сред — это среды, использующие спам-фильтры, алгоритмы обнаружения фрода, системы анализа вредоносного программного обеспечения.
Таким образом, точность можно рассматривать как меру средней производительности системы в среднестатистическом ее использовании, тогда как оценка безопасности заинтересована в наихудшем ее исполнении.
То есть обычно модели машинного обучения тестируют в довольно статичной среде, где точность зависит от количества данных каждого конкретного класса, но в реальности нельзя гарантировать такое же распределение. А мы заинтересованы в том, чтобы модель ошибалась. Соответственно, наша задача — найти как можно больше таких векторов, которые дают неверный результат.
Когда говорят про безопасность какой-то системы или сервиса, то обычно подразумевают невозможность нарушения политики безопасности в рамках заданной модели угроз в аппаратном или программном обеспечении, стараясь проверять систему как на этапе разработки, так и на этапе тестирования. Но на сегодняшний день огромное количество сервисов работают на основе алгоритмов анализа данных, поэтому риски скрываются не только в уязвимой функциональности, но и в самих данных, на основе которых система может принимать решения.
Никто не стоит на месте, и хакеры тоже осваивают что-то новое. А методы, помогающие исследовать алгоритмы машинного обучения на возможность компрометации злоумышленником, который может использовать знания о том, как работает модель, — называются adversarial machine learning, или по русски все-таки вредоносное машинное обучение.
Если говорить о безопасности моделей машинного обучения с точки зрения информационной безопасности, то концептуально хотелось бы рассмотреть несколько вопросов.
4. Можно ли манипулировать моделью машинного обучения, чтобы провести целевую атаку?
Приведем наглядный пример с поисковой оптимизацией. Люди изучают, как работают интеллектуальные алгоритмы поисковых систем, и манипулируют данными своих сайтов, чтобы оказаться выше в рейтинге поиска. Вопрос о безопасности такой системы в данном случае стоит не столь остро, пока это не скомпрометировало какие-то данные или не нанесло серьезный ущерб.
В качестве примера такой системы можно привести сервисы, которые в своей основе используют онлайн-обучение модели, то есть такое обучение, при котором модель получает данные в последовательном порядке для обновления текущих параметров. Зная о том, как система обучается, можно спланировать атаку и подавать системе заранее подготовленные данные.
Например, таким способом обманываются биометрические системы, которые постепенно обновляют свои параметры по мере небольших изменений во внешности человека, например при естественном изменении возраста, что является абсолютно естественной и необходимой функциональностью сервиса в данном случае. Воспользовавшись этим свойством системы, можно подготовить данные и подавать их биометрической системе, обновляя модель до тех пор, пока она не обновит параметры до другого человека. Таким образом злоумышленник переобучит модель и сможет идентифицировать себя вместо жертвы.

5. Может ли злоумышленник подбирать такие валидные данные, которые всегда будут срабатывать неправильно, что приведет к ухудшению производительности системы в той степени, что ее придется отключить?
Эта проблема возникает вполне закономерно из того факта, что модель машинного обучения часто тестируют в довольно статичной среде, а ее качество оценивается при том распределении данных, на котором модель обучалась. При этом очень часто перед специалистами по анализу данных ставятся вполне конкретные вопросы, на которые необходимо ответить модели:
- Является ли файл зловредным?
- Относится ли данная транзакция к фроду?
- Является ли текущий трафик легитимным?
И вполне ожидаемо, что алгоритм не может быть точным на 100%, он лишь может с какой-то вероятностью отнести объект к какому-то классу, поэтому приходится искать компромиссы в случае ошибок первого и второго рода, когда наш алгоритм не может быть полностью уверен в своем выборе и все-таки ошибается.
Возьмем систему, которая очень часто выдает ошибки первого и второго рода. Например, антивирус заблокировал ваш файл, потому что посчитал его вредоносным (хотя это не так), или антивирус пропустил файл, который был вредоносным. В таком случае пользователь системы считает ее неэффективной и чаще всего попросту отключает, хотя вполне вероятно, что просто попался набор таких данных.
А набор данных, на которой модель показывает результат хуже всего, существует всегда. И задачей злоумышленника становится поиск таких данных, чтобы заставить отключить систему. Подобные ситуации довольно неприятны, и конечно, модель должна их избегать. И можно представить масштабы последствий расследований всех ложных инцидентов!
Ошибки первого рода воспринимаются как трата времени, в то время как ошибки второго рода — как упущенная возможность. Хотя на самом деле стоимость этих видов ошибок для каждой конкретной системы может быть разной. Если для антивируса дешевле может быть ошибка первого рода, потому что лучше перестраховаться и сказать, что файл вредоносный, и в случае если клиент отключит систему, а файл действительно оказался вредоносным, то антивирус «как бы предупреждал» и ответственность останется на пользователе. Если взять, к примеру, систему для медицинской диагностики, то обе ошибки будут достаточно дорогостоящими, ведь пациенту в любом из случаев грозит неправильное лечение и риск здоровью.
6. Может ли злоумышленник использовать свойства метода машинного обучения, чтобы нарушить работу системы? То есть, не вмешиваясь в процесс обучения, найти такие ограничения модели, которые заведомо дают неверные предсказания.
Казалось бы, системы глубокого обучения практически защищены от вмешательства человека при выборе признаков, поэтому можно было бы сказать, что тут нет человеческого фактора при принятиях каких-либо решений моделью. Вся прелесть глубокого обучения в том, что достаточно подать на вход модели практически «сырые» данные, а модель сама, путем многократных линейных преобразований, выделяет признаки, которые она «считает» наиболее значимыми, и принимает решение. Однако так ли хорошо это на самом деле?
Есть работы, которые описывают методики подготовки таких вредоносных примеров на модели глубокого обучения, которые система классифицирует неверно. Одним из немногих, но популярных примеров является статья об эффективных физических атаках на модели глубокого обучения (Robust Physical-World Attacks on Deep Learning Models).
Авторы проделали эксперименты и предложили методики обхода моделей, основанных на ограничении глубокого обучения, которые обманывают системы «зрения», на примере распознавания дорожных знаков. Для положительного результата злоумышленникам достаточно найти такие области на объекте, которые наиболее сильно сбивают классификатор, и он ошибается. Эксперименты проводились на знаке «STOP», который благодаря изменениям исследователей квалифицировался моделью как знак «SPEED LIMIT 45». Свой подход они проверили и на других знаках и получили положительный результат.
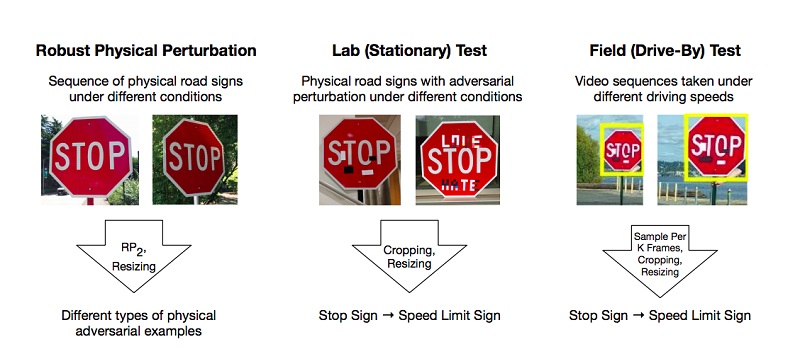
В итоге авторы предложили два способа, с помощью которых можно обмануть систему машинного обучения: Poster-Printing Attack, которая подразумевает ряд небольших изменений по всему периметру знака, названных камуфляжем, и Sticker Attacks, когда на знак в определенные области наслаивались какие-то стикеры.
А ведь это вполне жизненные ситуации — когда знак в грязи от придорожный пыли или когда на нем юные таланты оставили свое творчество. Вполне вероятно, что искусственному интеллекту и искусству не место в одном мире.

Или недавние исследования о целевых атаках на системы автоматического распознавания речи. Голосовые сообщения стали довольно модной тенденцией при общении в социальных сетях, но слушать их не всегда удобно. Поэтому появились сервисы, которые позволяют транслировать аудиозапись в текст. Авторы работы научились анализировать оригинальные аудио, учитывать звуковой сигнал, а затем научились создавать другой звуковой сигнал, который на 99% схож с оригиналом, путем добавления в него небольшого изменения. В итоге классификатор расшифровывает запись так, как хочет злоумышленник.
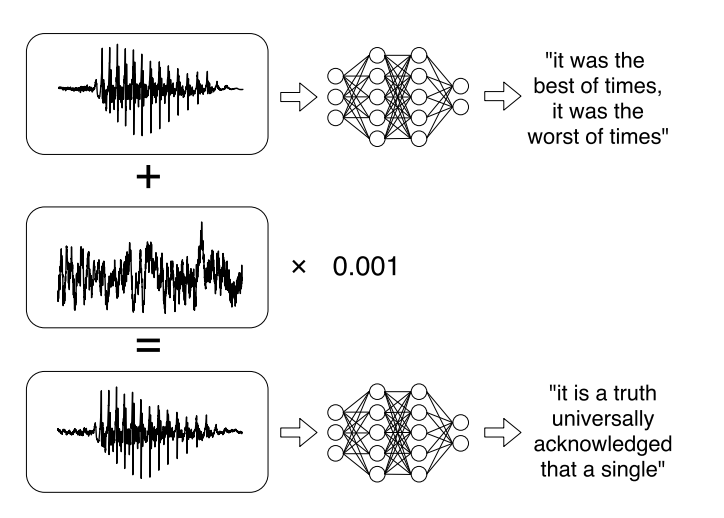
7. В связи с этим, можно было бы категоризировать существующие атаки несколькими способами:
По способу воздействия (Influence):
- Каузальные атаки (Causative attacks) влияют на обучение модели через вмешательство в обучающую выборку.
- Произвольные атаки (Exploratory attacks) используют ошибки классификатора, не влияя на обучающую выборку.
Нарушение безопасности (Security violation):
- Нарушение целостности (Integrity attacks) компрометируют систему через ошибки второго рода.
- Нарушение доступности (Availability attacks) заставляет отключить систему, обычно основаны на ошибках первого рода.
Специфика:
- Таргетированные атака (Targeted attack) направлена на изменение предсказания классификатора к определенному классу.
- Массовая атака (Indiscriminate attack) направлена на изменение ответа классификатора к любому классу, кроме правильного.
Цель безопасности — защищать ресурсы от злоумышленника и соблюдение требований, нарушения которых приводит к частичной или полной компрометации ресурса.
Различные модели машинного обучения используют для обеспечения безопасности. К примеру, системы обнаружения вирусов имеют цель уменьшить незащищенность от вирусов путем обнаружение их до заражения системы, либо обнаружить уже существующий для удаления. Другим примером являются системы обнаружения вторжений (intrusion detection system — IDS), которые обнаруживают, что система скомпрометирована путем обнаружения вредоносного трафика или подозрительного поведения в системе. Еще одна близкая задача — системы предотвращения вторжений (intrusion prevention system — IPS), которые обнаруживают попытки вторжения и не допускают вмешательства в систему.
В контексте задач безопасности целью моделей машинного обучения является в общем случае отделение вредоносных событий и предотвращение их от вмешательства в систему.
В общем случае цель можно разделить на две:
целостность: предотвращать доступ злоумышленника от ресурсов системы
доступность: предотвращать вмешательство злоумышленника в нормальную работу.
Здесь явная связь между ошибками второго рода и нарушениями целостности: вредоносные экземпляры, которые проходят в систему могут нанести ущерб. Также как ошибки первого рода обычно нарушают доступность, поскольку сама система отклоняет достоверные экземпляры данных.
8. Какие существуют способы защиты от злоумышленников, манипулирующих моделями машинного обучения?
На данный момент защитить модель машинного обучения от вредоносных атак сложнее, чем атаковать ее. Просто потому, что сколько бы мы ни обучали модель, всегда найдется набор данных, на которых она будет работать хуже всего.
И на сегодняшний день нет достаточно эффективных способов сделать так, чтобы модель работала со 100%-ной точностью. Но есть несколько советов, которые могут сделать модель более устойчивой к вредоносным примерам.
Вот основной из них: если есть возможность не использовать модели машинного обучения в вредоносной среде — лучше их не использовать. Нет смысла отказываться от машинного обучения, если перед вами стоит задача классифицировать картинки или генерировать мемы. Здесь вряд ли можно нанести какой-то значимый ущерб, который бы привел к каким-то социально или экономически значимым последствиям в случае намеренной атаки. Однако если система связана с выполнением действительно важных функций, например с диагностикой заболеваний, детектированием атак на промышленные объекты или управлением беспилотным автомобилем, то, конечно, последствия компрометации безопасности такой системы могут оказаться катастрофическими.
Если вспомнить упрощенную постановку задачи классификации о том, что нам важно построить такую гиперплоскость, которая бы разделяла пространство на классы, то можно заметить некоторое противоречие. Давайте проведем аналогию на двумерном пространстве.
С одной стороны, мы пытаемся найти такую функцию, которая максимально точно разделит два класса на разные группы. С другой стороны, мы не может построить точную линию, потому что, как правило, у нас есть не генеральная совокупность данных, поэтому наша задача заключается в том, чтобы подобрать такую функцию, при которой ошибка классификации будет минимальной. То есть, с одной стороны, мы пытаемся построить точную линию, с другой стороны, мы пытаемся избежать переобучения на конкретных данных, которые у нас есть сейчас, и все же предугадать поведение остальных.
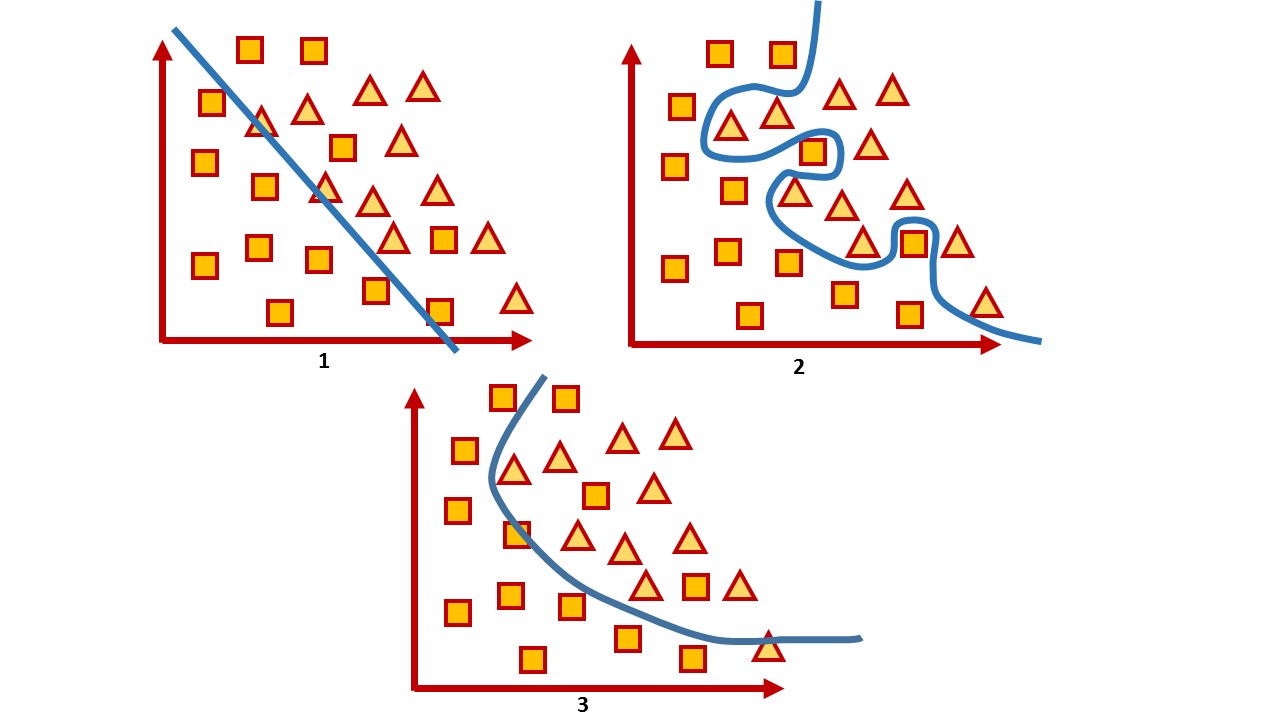
Как бороться с недообучением модели, вроде, понятно: чаще всего это увеличение сложности модели. Для переобучения применяются методы регуляризации. По факту они делают модель более устойчивой к небольшим выбросам, но не к вредоносным примерам.
Проблема неправильной классификации вредоносных примеров фактически очевидна. Модель не видела таких примеров в своей обучающей выборке, поэтому чаще всего она будет ошибаться. Вполне работающим решением будет дополнение своей обучающей выборки такими вредоносными примерами, чтобы не дать себя обмануть хотя бы на них. Но сгенерировать все возможные вредоносные примеры и получить 100%-ную точность вряд ли удастся опять же из-за того, что мы пытаемся найти компромисс между переобучением на тестовых данных и недообучением.
Еще можно воспользоваться генеративно-состязательной нейронной сетью, которая по своей структуре состоит из двух нейронных сетей — генеративной и дискриминативной. Задачей дискриминативной модели является научиться отличать поддельные данные от реальных, а задачей генеративной модели — научиться генерировать такие данные, чтобы обмануть первую модель. Найдя компромисс между достаточным качеством классификации дискриминатора и своим терпением относительно времени ее обучения, можно получить довольно устойчивую к вредоностным примерам модель.
Но несмотря на использование таких методов, все равно можно подобрать такой набор данных, на которых модель будет принимать неверное решение.
9. Каковы потенциальные последствия использования машинного обучения с точки зрения безопасности?
Давно идут споры об ответственности моделей машинного обучения за ошибки и за их социальные последствия. Для процесса создания и эксплуатации таких интеллектуальных систем можно выделить несколько влияющих на конечный результат ролей: тех, кто разрабатывает алгоритм, кто предоставляет данные и тех, кто эксплуатирует систему, являясь ее владельцами в итоге.
С первого взгляда кажется, что разработчик системы имеет огромное влияние на конечный результат. От выбора конкретного алгоритма до подбора параметров и тестирования. Но по факту разработчик всего лишь делает некоторый программный продукт, который должен соответствовать требованиям. Как только модель начинает им соответствовать, работа разработчика обычно заканчивается, и модель переходит в стадию эксплуатации, где и могут проявиться некоторые «баги».
С одной стороны, это происходит из-за того, что на этапе обучения у разработчиков имеется не вся генеральная совокупность данных. Но с другой стороны, это может быть просто от тех данных, что в реальности есть. Очень ярким примером является чат-бот для Twitter, созданный Microsoft, который в итоге дообучился на реальных данных и стал писать расистские твиты.
И все же это баг или фича? Алгоритм обучился на данных, которые увидел, и стал им подражать — казалось бы, это потрясающее достижение разработчиков, к которому все и стремились. С другой стороны, данные оказались именно вот такими, какими были, поэтому с моральной точки зрения данный бот оказался непригодным для использования — просто потому, что он настолько хорошо научился делать то, что от него хотели.
Может быть, прав Илон Маск, утверждая, что «искусственный интеллект — это самый большой риск, с которым мы сталкиваемся как цивилизация»?
Телеграм: t.me/ainewsline
Источник: habr.com