Сегментация объектов на видео в реальном времени с помощью Pixel-Wise обучения
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-06-25 17:32

Видео остается одним из самых информационно емких источников данных, но при этом одним из самых дорогих в обработке. Для разработчиков любых приложений важна скорость, глубина и точность обработки данных. Задача выделения объектов на видео сейчас не может быть решена с удовлетворительным качеством и приемлемой скоростью.
Новый метод
Исследователи из технологического университета Цюриха решили построить интуитивно понятную, но в то же время неизученную модель. Задача формулируется как попиксельный (pixel-wise) поиск в пространстве эмбеддинга. В идеальном случае пиксели, принадлежащие одному и тому же объекту, должны быть расположены близко друг к другу в векторном пространстве эмбеддинга, а принадлежащие разным—далеко. Модель, построенная с помощью обучения полной сверточной сети (Fully Convolutional Network, FCN) как модель для эмбеддинга, использует модифицированный triplet loss, заточенный для выделения объектов на видео, где не видно четкого соответствия пикселей друг другу.
У такой постановки задачи есть свои преимущества. Во-первых, предложенный метод крайне эффективен, поскольку нет тонкой настройки в тестовом режиме, и он требует только однократного прямого прохода по нейросети эмбеддинга и поиска ближайшего соседа для обработки каждого кадра. Во-вторых, этот метод подстраивается под различные типы пользовательского ввода (например, кликанье по точкам, выделение рисованием, маски сегментации и т.д.) в виде единого фреймворка. Более того, процесс отображения в пространство эмбеддинга происходит независимо от ввода. Таким образом, вектора в эмбеддинге не нужно пересчитывать, когда меняются входные данные, что делает этот метод идеальным для интерактивных задач:
- Интерактивная сегментация объектов на видео. Опирается на взаимодействие с пользователем для выделения интересующего объекта. Всего было предложено несколько техник для решения данной задачи.
- Глубокое метрическое обучение: ключевая идея deep metric learning обычно состоит в преобразовании необработанных признаков сетью и сравнении полученных новых объектов в пространстве эмбеддинга. Обычно метрическое обучение применяется для выявления сходства между изображениями или их частями, и методы, основанные на pixel-wise метрике, ограничены в возможностях.
Архитектура
Проблема заключается в том, чтобы сформулировать сегментацию видеообъектов как задачу pixel-wise поиска, то есть для каждого пикселя на видео нужно найти самый похожий опорный пиксель в пространстве эмбеддинга и присвоить ему соответствующую метку. Метод содержит два этапа:
- Добавить каждый пиксель в d-мерное пространство, используя предлагаемую эмбеддинг сеть.
- Выполнить поиск в векторном пространстве для каждого пикселя и получить метку для каждого из них в соответствии с его ближайшим опорным пикселем.
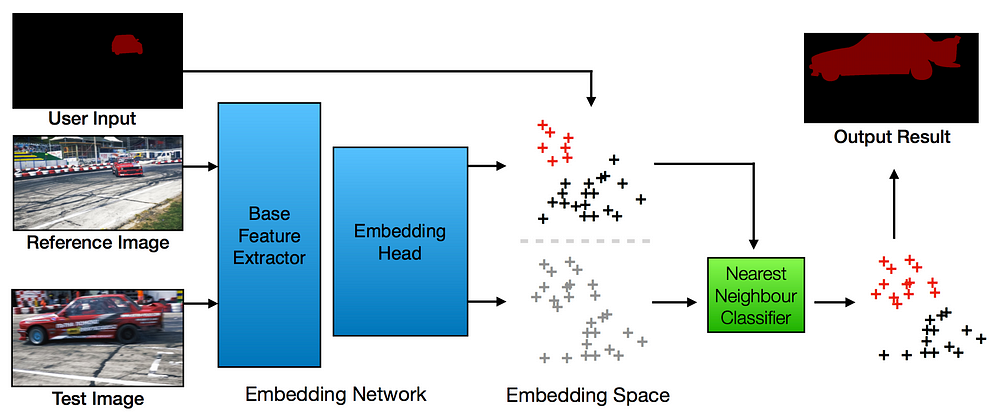
Пользовательский ввод для тонкой настройки модели
Первый способ—точно подстроить сеть для конкретных объектов, опираясь на пользовательский ввод. Например, техники OSVOS или MaskTrack для точной настройки сети в тестовом режиме основаны на пользовательском вводе. Во время обработки нового видео они требуют большого количества итераций тренировки для того, чтобы модель “приспособилась” к специфичному целевому объекту. Это может быть очень времязатратно (секунды на видеоряд), а потому непрактично для real-time приложений, особенно когда в рабочей цепочке присутствует человек.
Пользовательские данные на вход сети
Другой подход заключается в том, чтобы взаимодействие с пользователем подключить как дополнительный вход нейросети. При этом в тестовом режиме работы “пользовательского” обучения не происходит. Недостаток подхода в том, что сеть должна быть пересчитана, как только пользовательский ввод изменится. Это по-прежнему может занимать значительное время, особенно для видео, содержащего большое количество кадров.
В отличие от методов, приведенных выше, в предлагаемой работе пользовательский ввод не учитывается. Таким образом, прямой проход сети должен быть рассчитан только один раз. Единственным вычислением после ввода пользователем является поиск ближайшего соседа, который происходит быстро и позволяет моментально реагировать на действия пользователя.
Модель эмбеддинга: В предложенной модели f, где каждый пиксель xj,i представлен d-мерным вектором в пространстве эмбеддинга ej,i = f(xj,i). В идеальном случае, пиксели, принадлежащие одному объекту, должны находиться близко друг к другу в векторном пространстве. Модель представления построена на DeepLab, основанном на каркасе ResNet.
- Нейросеть предобучается для семантической сегментации на датасете COCO.
- Удаляется последний?—?классифицирующий?—?слой и заменяется новым сверточным слоем c d выходными каналами
- Затем следует тонкая настройка для обучения эмбеддинга для выделения объектов на видео.
Архитектура DEEP lab является базовым средством выделения признаков и двумя сверточными слоями в качестве начала эмбеддинга. Результирующая сеть является полностью сверточной, поэтому отображенный вектор всех пикселей в кадре может быть получен за один прямой проход по сети. Для изображения размера h ? w пикселей выход представляет собой тензор [h / 8, w / 8, d], где d?—?размерность пространства отображения. Поскольку FCN развертывается как модель эмбеддинга, пространственная и временная информация не сохраняется из-за инвариантности операции свертки. Формально функцию отображения (эмбеддинга) можно представить как:
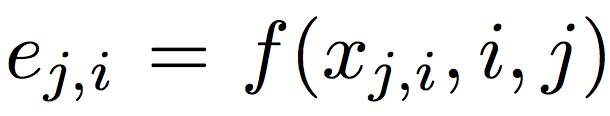
где i и j относятся к i-му пикселю на j-ом кадре. Затем используется модифицированный triplet loss:
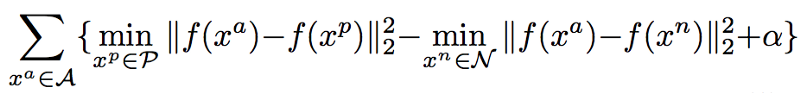
Предложенный метод был опробован на датасетах DAVIS 2016 и DAVIS 2017, оба в сценариях “с частичным привлечением учителя” и “интерактивный режим”. В контексте частично размеченной сегментации объектов на видео (Video Object Segmentation, VOS) была предоставлена полностью описанная маска для первого кадра входа.
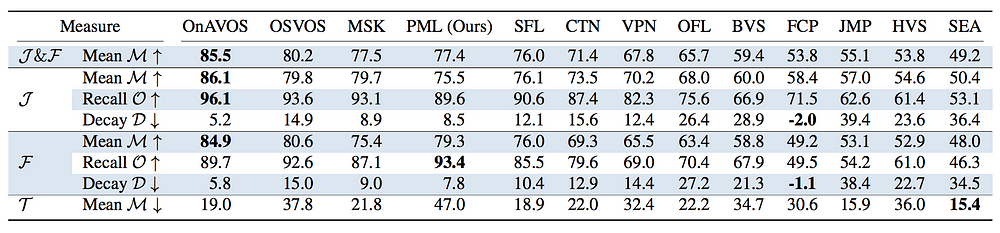
Результаты запуска на валидации из DAVIS 2016
Результаты
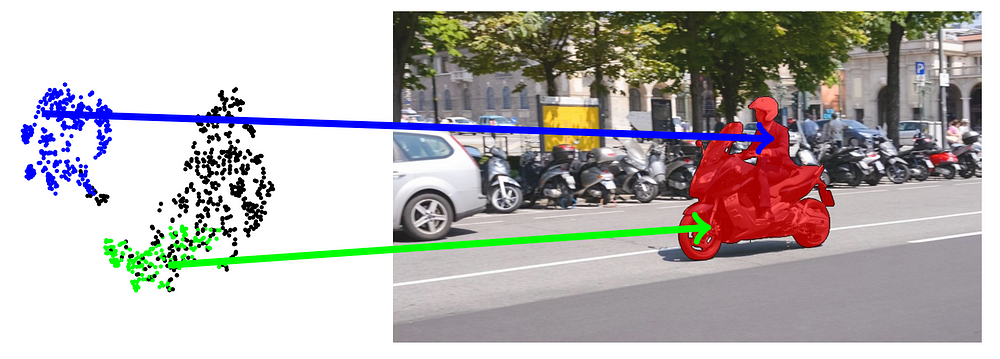
Иллюстрация распределения пиксельных признаков (pixel-wise features)
В работе представлен концептуально простой, но очень эффективный метод выделения объектов на видео. Задача представлена в виде пиксельного поиска в пространстве эмбеддинга, полученного с помощью модификации triplet loss, специально предназначенных для сегментации видеообъектов. При таком подходе вручную размеченные пиксели на видео (рисованием, сегментацией по первой маске, кликаньем и т.д.) являются эталонными образцами, а остальные пиксели классифицируются с помощью простого и быстрого метода поиска ближайшего соседа. Скорость вычислений превосходит существующие методы и позволяет моментально реагировать на действия пользователя.

Перевод—Эдуард Поконечный, оригинал—Muneeb Ul Hassan
Телеграм: t.me/ainewsline
Источник: medium.com