В чём разница между Machine Learning и анализом данных, кто сидит в «Одноклассниках» и как начать свой путь в машинном обучении — об этом мы беседуем в двенадцатом выпуске ток-шоу для программистов.
Видео на канале Технострим Ведущий программы — технический директор медиапроектов Павел Щербинин, гость — инженер-аналитик «Одноклассников» Дмитрий Бугайченко. 00:56 Дмитрий Бугайченко: из аутсорса в ОК и научную деятельность 02:42 Зачем совмещать работу в университете и в крупной компании 02:57 Где машинное обучение применяется в ОК 03:49 Машинное обучение и анализ данных — в чем разница? 05:08 Скринкаст «Разбираем аудиторию ОК с помощью анализа данных» 22:34 Одноклассники — это сервис знакомств? 24:07 С чего начать изучение Machine Learning? 25:33 Стоит ли участвовать в чемпионатах по машинному обучению? 26:53 Как попасть на практику в ОК 28:18 Настольная книга по машинному обучению 30:28 Мероприятия по Machine Learning 32:48 Как устроен data pipeline в ОК (показываем на доске) 43:42 Блиц-опрос
Расскажи немного о себе.
Можно считать, что мой карьерный путь начался еще в 1999 году, когда я поступил на матмех. В течение пяти лет активно изучал математику, программирование и разные сопутствующие дисциплины. Потом достаточно долго проработал в аутсорсинговой компании. Аутсорсинг — это очень интересный опыт. Мне удалось поработать в самых разнообразных проектах, от написания драйвера для холодильника до создания распределенных энтерпрайз-систем.
Всё это время, помимо основной работы, я преподавал в университете ради поддержки контакта с академическим сообществом, что было достаточно трудно. Когда в 2011 году меня пригласили в «Одноклассники» заниматься рекомендательными системами, это был очень хороший шанс, которым я воспользовался. Здесь удается сочетать и математическую подготовку университета, и практический опыт программирования. Тем не менее, я продолжаю преподавать в университете.
Много времени занимает преподавание?
1,5 дня в неделю уходит на университет, но оно того стоит, потому что у нас в штате уже три моих бывших студента. То есть университет работает и как кузница кадров.
На работе спокойно относятся к тому, что тебя нет 1,5 дня?
Смирились. Все понимают, какой от этого профит, поэтому не встречаю противодействия.
Расскажи, где машинное обучение применяется в «Одноклассниках».
У нас очень много сфер применения. Исторически первой системой на основе машинного обучения была рекомендация музыки. С неё всё начиналось в 2011 году. Дальше был просто взрывной рост: рекомендация сообществ, рекомендация друзей, «возможно, вы знакомы», попытки ранжировать контент в ленте человека. Сейчас развивается очень много проектов. В какую часть «Одноклассников» ни ткни, везде есть компоненты, связанные либо с машинным обучением, либо с анализом данных.
Помоги нашим читателям разделить эти два понятия: машинное обучение и анализ данных.
Данные анализируются человеком, чтобы найти какие-то закономерности, связи, проверить какие-то гипотезы. Для этого используются разные средства математической статистики. Машинное обучение — это более продвинутый способ поиска закономерностей, при котором используются методики, в основе которых, как правило, лежит какая-то большая, сложная модель с большим числом параметров.
Мы пытаемся подбирать параметры этой модели так, чтобы она хорошо описывала тот феномен, который нам нужен. Есть много разных алгоритмов, способов перебора параметров, но всё это делается для того, чтобы найти некоторую закономерность. Например, по данным о каком-то посте в социальной сети оценить вероятность, что конкретный человек поставит этому посту «класс». То есть машинное обучение — это инструмент для анализа данных.
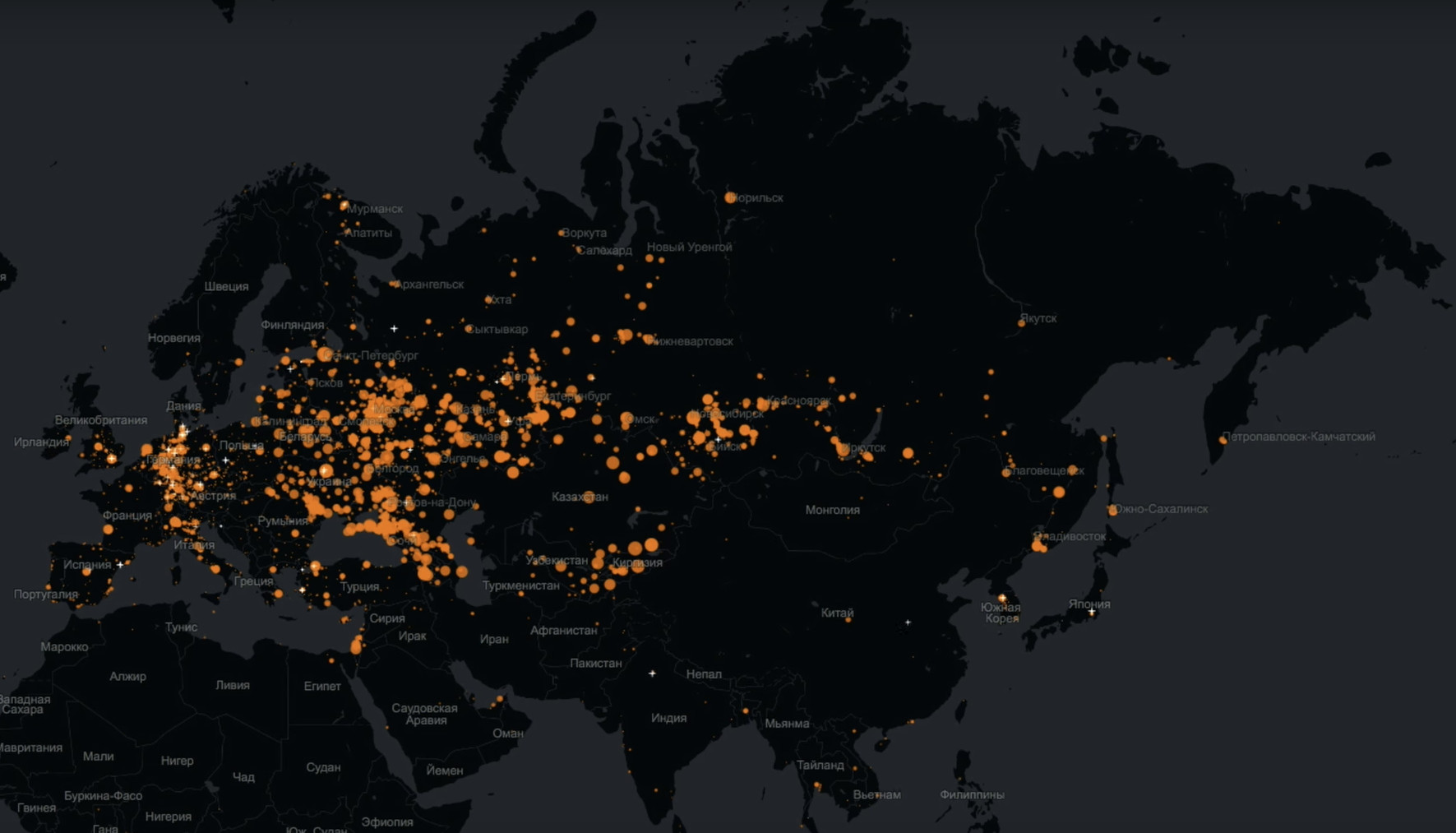
Мы с тобой могли бы развенчать один из мифов об «Одноклассниках», согласно которому в этой соцсети очень возрастная аудитория?
Без проблем. Это карта, которая в реальном времени отражает логины каждого конкретного пользователя. То есть каждая точка — это человек, который залогинился и что-то делает в «Одноклассниках».
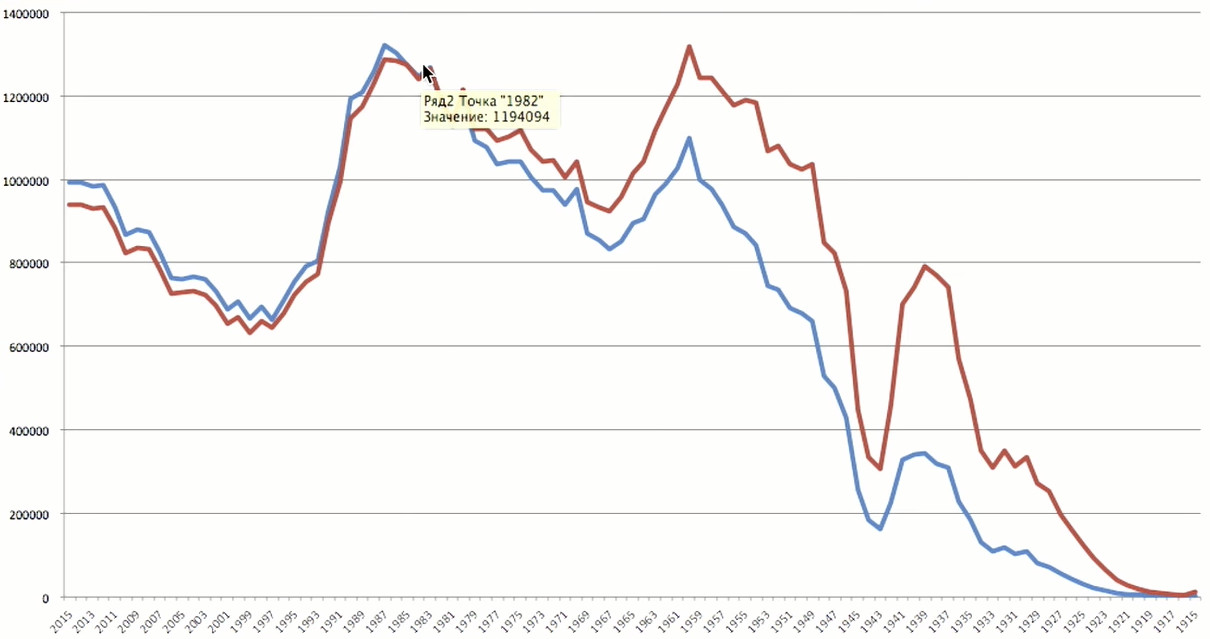
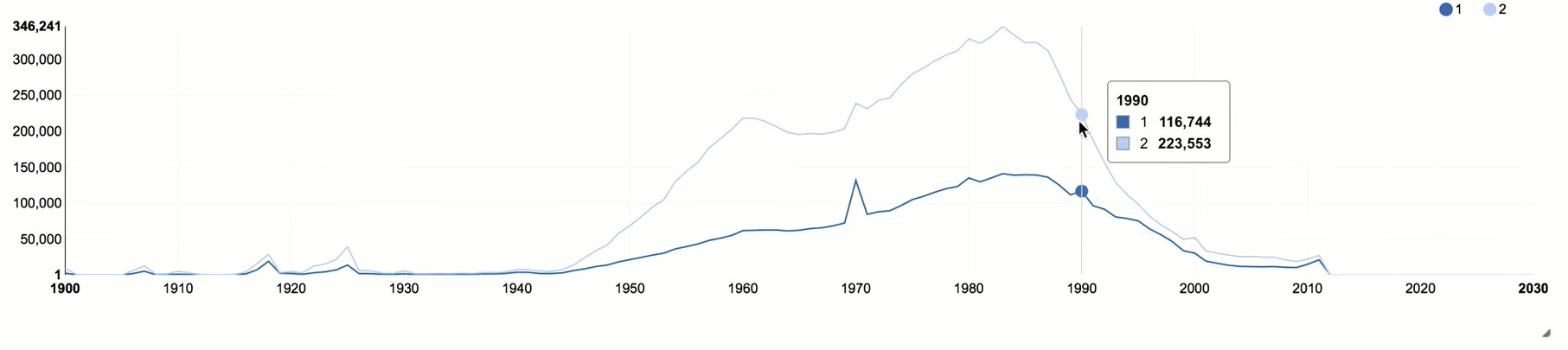
Большие рыжие кружки — это города, из которых к нам пришло много пользователей. Здесь очень хорошо видно, что «Одноклассники» не просто живы, они охватывают практически всю Евразию. Посчитаем, сколько пользователей вчера ставили «класс» в «Одноклассниках», и посмотрим распределение по возрастам. С чего начинается написание кода? Конечно, с импорта разных полезных данных для будущего подсчёта агрегатов. Наш основной инструмент — Spark, для доступа к которому мы используем веб-фронт Zeppelin. В основном, данные приходят через Apache Kafka, складываются в пакеты и разбиваются на разные блоки. В данном случае нас интересует блок, описывающий активность пользователей за вчерашний день, в частности, классы. Там есть поле, в котором хранится демография пользователей, в том числе дни рождения. На выходе получаем год рождения десяти первых записей. Теперь попробуем построить из этого некоторый агрегат. Мы хотим посчитать количество уникальных пользователей. Нужны id и год рождения, сгруппируем по годам и посчитаем количество уникальных пользователей. И немного подстрахуемся: наверняка будут люди, у которых год рождения не указан, поэтому мы их отфильтруем, чтобы не создавали шум на графике. Чтобы сделать расчет, системе нужно перелопатить порядка 1 ТБ данных. Получаем результат и представляем его графически: Возрастной пик приходится на 1983 год — 35 лет. То есть вполне себе не старые пользователи. Чтобы полнее представлять ситуацию, недостаточно информации из одного источника. Если мы говорим о демографии пользователей, то самый интересный источник для сравнения — статистика по населению России. С сайта Росстата я скачал данные о годах рождения россиян, собранные в 2016 году. Пик в статистике очень близок к пику по данным «Одноклассников» — у нас пользователи 1983 года рождения, у Росстата — 1987 года. Что меня поразило, это два больших провала. Яма начала 1940-х годов — это Великая Отечественная. Война стоила нам не только больше 20 млн погибших, но и миллионов не родившихся людей. Это демографическая яма, которая чувствуется до сих пор. Вторая яма — 1990-е. И от этого кризиса мы до конца не оправились. Ту же самую картину мы наблюдаем в данных «Одноклассников»: после 1990 года рождения идет сильный спад. Людей 2015 года рождения у нас еще быть не может, потому что минимальный возраст регистрации — 5 лет. Добавим в нашу выборку атрибут gender и сгруппируем не только по году, но и по полу. После 1990 года идет резкий спад, который коррелирует с общей возрастной ситуацией по России. Женщины гораздо активней ставят «класс», почти в два раза больше, чем мужчины. Это достаточно характерная картина для социальных сетей, потому что женщины более социально активны по сравнению с мужчинами. Ещё можно обратить внимание на несколько пиков, которые коррелируют с «круглыми» годами. По этим пикам можно оценить влияние ботов или людей, которые намеренно искажают свой возраст, потому что в таких случаях чаще всего указывают какие-то круглые даты. Также нас интересует географическое распределение наших пользователей. Нам нужен ID пользователя, чтобы посчитать уникальных посетителей, и указанные в профилях адреса проживания. Сгруппируем по городу и посчитаем агрегат. Отсортируем по количеству пользователей в убывающем порядке и оставим только первые 200 городов. Запускаем агрегацию:
Это топ городов по количеству ставивших класс пользователей «Одноклассников». Естественно, Москва в лидерах. Юг России представлен гораздо лучше, чем Северо-Запад. У нас есть пользователи в США, Канаде, немало в Германии, очень много в Израиле. Интересный факт: за день лайкнули 36 тыс. человек из Южно-Сахалинска. А всего в городе, по данным Википедии, проживает 180 тыс. человек. 20 % населения Южно-Сахалинска зашли в «Одноклассники» и поставили «класс». Увеличим масштаб и посмотрим, что у нас происходит в Москве и ближнем Подмосковье. Очень хорошо представлены в «Одноклассниках» среднеазиатские республики, Молдавия, Украина. Сразу видно, где пытались блокировать доступ к нашей соцсети, а где нет. Как видите «Одноклассники» — живой, динамичный продукт, которым пользуются и молодежь, и пожилые люди по всему миру, иногда даже там, где вы не ожидаете. Среди всех возрастных категорий у нас больше всего 30-летних. Социальные сети строятся вокруг сообществ. Очень часто бывает так, что если какое-то сообщество вошло в некую социальную сеть, оно очень мало знает о других соцсетях. Поэтому, например, у профессионального сообщества журналистов может возникнуть иллюзия, что у «Одноклассников» в основном пожилая аудитория. На самом деле это субъективное мнение какого-то сообщества. У нас есть пользователи в возрасте 50-60 лет и старше, есть школьники, есть 20-летняя молодежь, есть зрелые, сформировавшиеся люди 30—35 лет. Покрытие «Одноклассников» — это все регионы России, ближнее зарубежье, Украина, Белоруссия, Средняя Азия. У нас очень хорошо представлены диаспоры, например, германская диаспора российских эмигрантов, американская диаспора, израильская. Они достаточно активно общаются со своими родными, оставшимися в России и бывших советских республиках. С этой точки зрения «Одноклассники» очень хорошо способствуют реализации базовой функции социальной сети — поддерживать контакты между людьми, живущими далеко друг от друга.
Бытует мнение, что «Одноклассники» так привлекательны для многих потому, что это легкий способ познакомиться с друзьями и знакомыми твоих друзей и родных. То есть «Одноклассников» представляют как dating-сервис. Насколько этот способ знакомства востребован и является частью идеологии «Одноклассников»?
Потребность в знакомстве с другими людьми, в том числе противоположного пола, это базовая потребность человека. Естественно, она выражена в любой социальной сети. Но в «Одноклассниках» она выражена не больше и не меньше, чем в других соцсетях. Никакого акцентирования на dating-сервисах у нас нет. Идеология развития нашей соцсети строится на такой общей ценности, как общение людей. Нам не так важно, будут ли это одноклассники, которые разъехались по разным городам, или люди, которые ищут себе пару. Оба варианта нас вполне устраивают. Мы рады, что люди нашли друг друга и общаются. Но не более того
Ты много занимаешься машинным обучением. Эта тема сейчас будоражит многих. С чего начать, как прийти в эту профессию?
Во-первых, нужно получить некоторые знания. С этим никаких проблем нет, есть замечательные курсы на Coursera, на Stepik и в некоторых университетских программах, которые дают очень хорошие базовые знания о машинном обучении. Чтобы реально влиться в эту сферу, нужна цель и понимание, где вы это можете применить. Потому что просто слушать абстрактный курс далеко не так эффективно, как если вы действительно будете решать какую-то задачу или проблему. В случае со студентами идеальный вариант — курсовые, дипломные работы. И даже в этом случае я стараюсь не спускать задачу сверху, а способствовать тому, чтобы идеи шли от студентов, тогда у них будет куда больше мотивации. То есть, поставив себе цель, прослушайте онлайн-курсы, а дальше пробуйте применять знания. И всё получится.
Мне кажется, задач сегодня достаточно. На Кегле проходит огромное количество соревнований от «Сбербанка», «Тинькофф» и многих других компаний.
Безусловно. Но они ориентированы, в первую очередь, на тех, кто уже плотно занимается машинным обучением. При этом очень часто на подобных соревнованиях можно наблюдать не машинное обучение, а шапкозакидательство. Те модели, которые обучаются на Кегле, никак не помогут в решении практических задач, потому что в них загоняют слишком много параметров. В результате модели специализируются именно под конкретные соревнования на Кегле, и только в них получаются какие-то результаты. А если перенести эти модели в реальный мир, работать они не будут.
Лучший опыт — это практика. Как попасть на практику к тебе в команду?
Есть очень много способов. Если говорить об исследовательских коллективах, то у нас есть проект под названием OK Data Science Lab, в рамках которого мы предоставляем вычислительные ресурсы, данные, свои знания и опыт людям, которые хотят развивать свои идеи, связанные с машинным обучением и анализом данных. И необязательно для социальной сети. Например, у нас есть исследование, в ходе которого автор пытается понять, что больше всего интересно современным школьникам.
Если вы специалист и ищете работу, у нас всегда есть немало открытых вакансий, связанных с машинным обучением. Приходите к нам на собеседование.
Есть какая-нибудь книга, хрестоматия по машинному обучению?
Это настолько быстро меняющаяся сфера, что писать по машинному обучению книгу или хрестоматию слишком амбициозно. Могу посоветовать классическую работу “Elements of statistical learning”. Это про самые основные методы машинного обучения, берущие начало в статистике. Сергей Николенко выпустил книжку по глубокому машинному обучению.
На мой взгляд, глубокое обучение — это не то, с чего следует начинать. Если вы уже владеете классическим машинным обучением, тогда это хороший вариант. Но если вы еще не знаете классических приемов, начинать сразу с глубокого обучения неправильно, потому что оно часто отодвигает исследователя от проблемы, это очень мощный инструмент. Прежде чем его применять, надо проанализировать проблему «вручную», более простыми способами. И уже потом, с пониманием предметной области, переходить к глубинному обучению. Иначе ваша модель выучится, а вы — нет. Когда вы становитесь глупее вашей модели, это, мягко говоря, неэффективно. Вы не сможете развивать модель дальше, а это тупик. Поэтому лучше сначала поднатореть в классическом ML. Это не значит, что нужно потратить годы, вполне можно освоить за разумное время.
Вы проводите какие-нибудь мероприятия по машинному обучению?
У нас есть серия хакатонов SNA Hackathon. Пока проходили два раза. В первый раз хакатон был посвящен анализу текста и попытке предсказать, сколько «классов» наберет определенный пост. Второй хакатон прошел год назад и был посвящен анализу графов. Там произошло много интересных событий. Мы предоставили информацию о «дружбах» части наших пользователей, казалось бы, небольшой кусочек данных примерно на 1 Гб. Но когда участники, которые хотели отправить свои прогнозы, попытались с ним работать, почти ни у кого это не получалось, даже на машинах с 16 и 32 Гб памяти всё валилось, улетало в swap, никак не хотело работать. Нам даже пришлось спешно разъяснять, как надо и как не надо работать с данными. Выяснилось, что очень многие, даже достаточно продвинутые специалисты по машинному обучению оторвались от корней и начали забывать базовые основы программирования. Забывать, что такое боксинг, как устроены хэш-таблицы, какой может быть оверхед по памяти, если вы используете хэш-таблицы. Если про всё это не думать и делать в лоб на Python, Java или Scala, будут описанные проблемы. Мы делали демку на Python, те же самые грабли есть в других языках. Граф из 40 млн связей, который мог бы уместиться в 200 Мб памяти, резко взрывается на 20 Гб просто из-за того, что вы забыли, как устроены базовые структуры данных. Это очень многих тогда впечатлило. Даже если вы специалист по машинному обучению, основы программирования забывать нельзя. Как устроен ваш рабочий процесс обработки данных?
Пользователи взаимодействуют с целой экосистемой наших продуктов. Условно можно выделить два уровня: фронтенд-приложения (мобильные приложения, портал, мобильная версия, разные дополнительные приложения) и бизнес-логика. Фронты часто взаимодействуют с пользователями и имеют доступ к очень ограниченному количеству серверов, поэтому в бизнес-логике есть некоторые специальные методы, которые позволяют фронтам журналировать данные.
Эти данные попадают в единую шину данных Apache Kafka. Это очередь, ставшая практически индустриальным стандартом, которая используется для сбора сырых данных. Естественно, сырые данные анализировать в Kafka сложно, поэтому они регулярно перекладываются в большой и толстый Hadoop. Кто-то может сказать, что Hadoop — это прошлый век, сейчас рулит Spark. Но Hadoop — это платформа, на которой можно запускать очень много инструментов. У нас поверх Hadoop крутятся различные инструменты для аналитики. Я часто прибегаю к такой классификации:
Стиль поступления данных.
Пакетная обработка. Есть какой-то объём данных, которые вы как-то обрабатываете.
Потоковая обработка. Вы работаете с данными в реальном времени, которые поступают непосредственно из потоков, в данном случае из нашей Kafka.
Если при пакетной обработке могут быть достаточно серьезные задержки — собрали статистику днём, а модель обучаете ночью, — то в случае с потоковой обработкой задержки измеряются единицами секунд между поступлением данных и их обработкой.
Операционная аналитика. Это контроль процессов и мониторинг. Обслуживает production, должна работать сама, без участия человека.
Интерактивная аналитика. То, чем занимается человек. Здесь важна быстрота реакции: что-то сделали, получили результат.
В каждой из этих ниш у нас есть своя экосистема продуктов. Например, в пакетной операционной аналитике в основном используются классический MapReduce, Apache Tez и немного Spark. Если мы говорим про интерактивную пакетную аналитику, то это Spark SQL и скриптовые языки Pig и Hive.
Конечно, чёткой грани нет, потому что некоторые интерактивные языки часто используются и для операционной пакетной аналитики. А для операционной потоковой аналитики у нас используется Apache Samza. Это интересная разработка на базе платформы LinkedIn. Мы внедрили её еще в 2014 году. Что касается интерактивного анализа потоков, то здесь мы используем Spark Streaming, интегрируя его с веб-интерфейсом.
Результаты аналитики нужно каким-то образом предоставить в production, иначе они не приносят пользы. Как правило, для этого мы используем ту же Kafka, но у нее есть недостатки. Kafka — это очередь, она позволяет много и быстро записать, но не позволяет читать по ключу. Чтобы вытаскивать данные, которые были записаны в Kafka адресно по конкретным ключам, мы разработали специальное приложение Streaming Index. Оно считывает данные из Kafka и раскладывает их в две базы: встроенную Casandra и большой встроенный кэш на основе разделяемой памяти, SMC.
То есть практически все операции в первую очередь выполняются с кэшем, хитрейт у нас очень высокий, порядка 99 %. А сервисы бизнес-логики уже общаются со Streaming Index, получают из него данные и используют для корректировки своей работы. В частности, скачивают информацию о количестве кликов и количестве показов поста, о том, сколько раньше один пользователь ставил «класс» другому пользователю, и так далее. То есть всю информацию для подбора самого релевантного, интересного контента.
В завершение ответь, пожалуйста, на несколько блиц-вопросов. Какую ОС предпочитаешь?
Mac.
IDE?
Idea.
Что бы ты выбрал: стартап или крупную компанию?
Стартап.
Почему?
Динамика, новые технологии.
Как ты думаешь, что будет новым IT-трендом через 10 лет?
Думаю, что это будет нейроинтерфейс и взаимодействие непосредственно с мозгом человека.
На что тебе не хватает денег?
Я давно усвоил истину: главное, чтобы желания совпадали с твоими возможностями. Пожалуй, всё, что я хотел от жизни, у меня есть.
Биткоины у тебя есть?
Слава богу, нет. К биткоинам у меня очень скептическое отношение. По сути, полноценный ядерный реактор работает только на то, чтобы люди майнили биткоины. С учетом всех наших проблем с экологией и с энергетическим кризисом, это явно не то, что нужно человечеству.
Это самый убедительный ответ, который я слышал. Что твои друзья чаще всего спрашивают тебя об «Одноклассниках»?
То же, что и журналисты: сколько людей осталось в «Одноклассниках».