Как создать свой датасет с Киркоровым и Фейсом на Яндекс Толоке
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-06-07 14:18
свёрточные нейронные сети, большие данные big data, примеры ии

Нейронными сетями уже никого не удивишь. Практически каждый человек знает, что такое машинное обучение, линейная регрессия, random forest. Каждый год тысячи людей проходят курсы по машинному обучению на ODS и Coursera. Любой школьник за пару недель теперь может освоить keras и клепать нейроночки. Но в нейронных сетях, как и во всем машинном обучении, помимо создания хорошего алгоритма, необходимы данные, на которых алгоритм будет обучаться.
Разрешите представиться, меня зовут Куцев Роман. Я работаю в RnD команде в Prisma AI и занимаюсь созданием датасетов под наши задачи.
Итак, вдруг поступает продуктовый запрос: нам срочно нужна нейронка, которая будет отличать Киркорова от Фейсa (конечно, пример вымышленный, мы такой ерундой не занимаемся).
Спрашиваю у Антона (главный по нейронкам), в каком виде нужны данные, в ответ слышу: “Две папки, в одной изображения Фейсa, в другой Киркорова, желательно где-то по 500 изображений на класс, и чтобы 299х299 были”.
Где найти данные?
- Смотрим публичные датасеты, такие как ImageNet, COCO, openimages.
- Если нужных размеченных данных в популярных публичных датасетах нет, то гуглим, открываем на arxiv.org статьи по этим темам в надежде, что где-нибудь там будет ссылка на нужный нам датасет.
- Если первые два пункта провалились, значит нужного датасета нет, и его надо создать!
Очевидно, что никто раньше не занимался задачей классификации Киркорова и Фейса. Поэтому придется самим создать такой датасет.
Пайплайн такой:
- Скачиваем из гугла по 1к изображений Киркорова и Фейса.
- Ресайзим к нужному размеру.
- Проверяем их фрилансерами на Яндекс Толоке.
Для скачивания воспользуемся Google Images Download.
В терминале пишем:
googleimagesdownload -k ‘Киркоров’ -l 1000 -t photo -s '>400*300' -o 'Kirkorov' googleimagesdownload -k ‘репер Face’ -l 1000 -t photo -s '>400*300' -o 'Face'(на самом деле все не так просто, за один запрос можно скачать только 100 изображений, поэтому приходится выкачивать с разными настройками)
Сразу ресайзнем изображения до размера 299х299, для этого я набросал такую функцию:
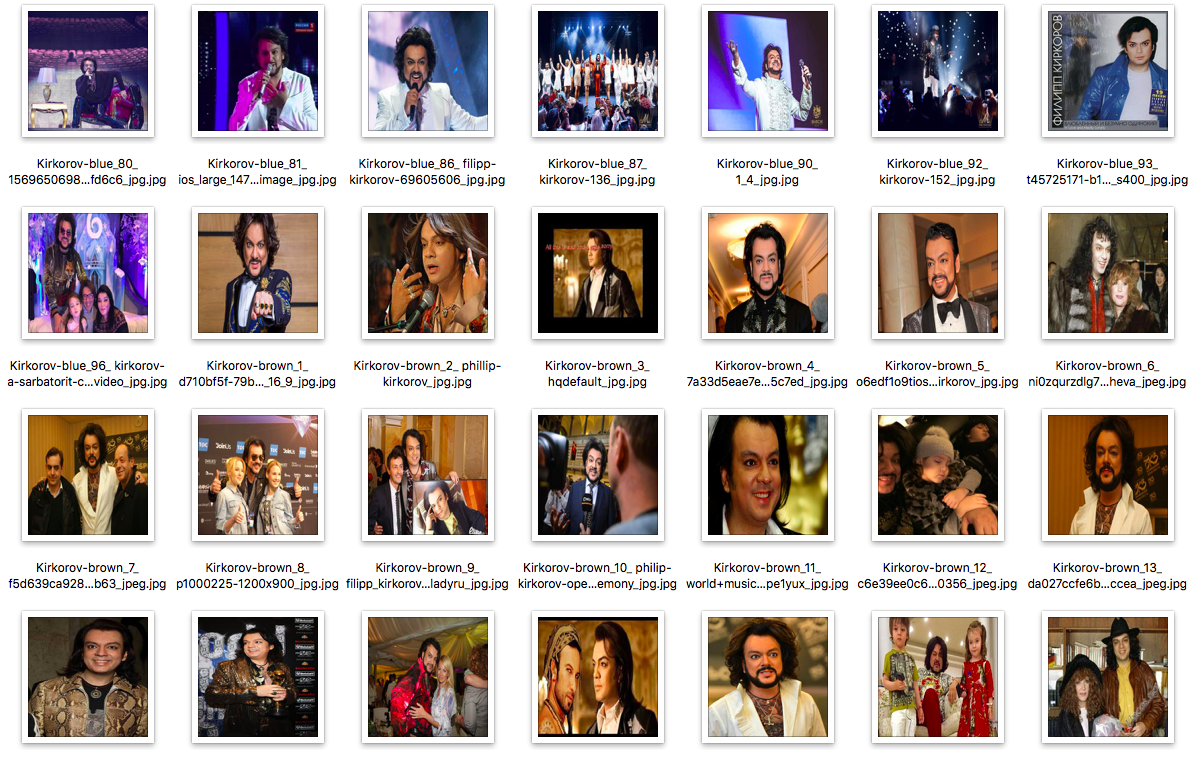
from PIL import Image import multiprocessing, time, os def resize_img(img_path): img = Image.open(os.path.join('Kirkorov',img_path)) img = img.resize((299,299), Image.ANTIALIAS) img.save(os.path.join('Kirkorov_resize',img_path)) num_processes = multiprocessing.cpu_count() pool = multiprocessing.Pool(processes=num_processes) st = time.time() pool.map(resize_img, os.listdir('Kirkorov')) print("Execution time: ", time.time()-st)Посмотрев на изображения, видим, что в основном скачались нужные изображения, но местами присутствует мусор.




Отлично, первые два пункта готовы, остался третий.
Если вы до сих пор не знаете, что такое Яндекс Толока, то советую прочитать эту и эту статью.
В двух словах: Толока — фриланс биржа на стероидах, где заказчик создает задание, загружает данные и фрилансеры его выполняют. Конечно, есть и другие инструменты для разметки, но для данной задачи удобнее всего воспользоваться Толокой.
Как начать пользоваться Яндекс Толокой:
1. Регистрируемся на sandbox.toloka.yandex.ru и toloka.yandex.ru в качестве заказчика (sandbox — песочница, в которой вы создаете задания, проверяете на корректность со стороны фрилансеров, и, если все хорошо, переносите его в toloka.yandex.ru).
2. В личном кабинете toloka.yandex.ru пополняем свой баланс.
3. В sandbox.toloka.yandex.ru во вкладке "Проекты" выбираем "Создать проект".

4. Вам будут предложены готовые шаблоны. Из всех шаблонов нам лучше всего подходит шаблон "Категоризация изображений". Выбираем его.

5. Создаем инструкцию для фрилансеров и название проекта.
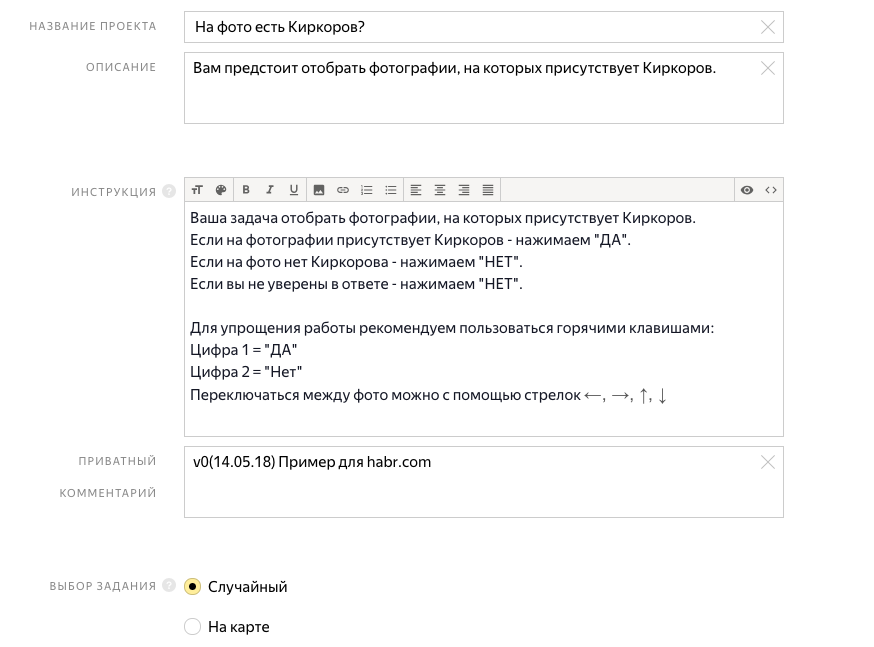
6. Во входных параметрах к заданию у нас будет URL на изображение. В выходных: строка output. Интерфейс задания пишется на html и javascript (это очень удобно, так как практически под любую задачу мы можем сверстать страничку, которая будет показываться исполнителям). Чуть-чуть изменяем шаблон html, и все готово. Сохраняем проект.
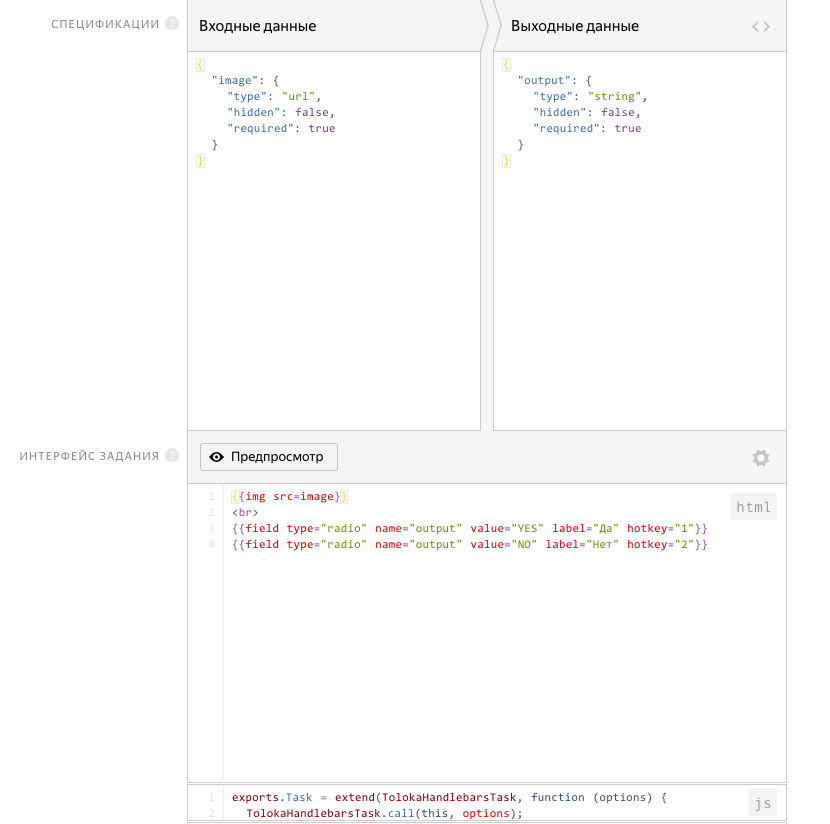
7. Проект готов. Теперь можно добавить пул заданий. В данной статье я не буду создавать пул обучения (надеясь на то, что фрилансеры способны сразу выполнить наше наисложнейшее задание). Но вы всегда создавайте в своем задании пул обучения. Это позволит:
- Отсеять людей, которые не поняли задание.
- Не допустить к заданию ботов, которые всегда выбирают один и тот же ответ.
- Научить исполнителей правильно и качественно выполнять задание.
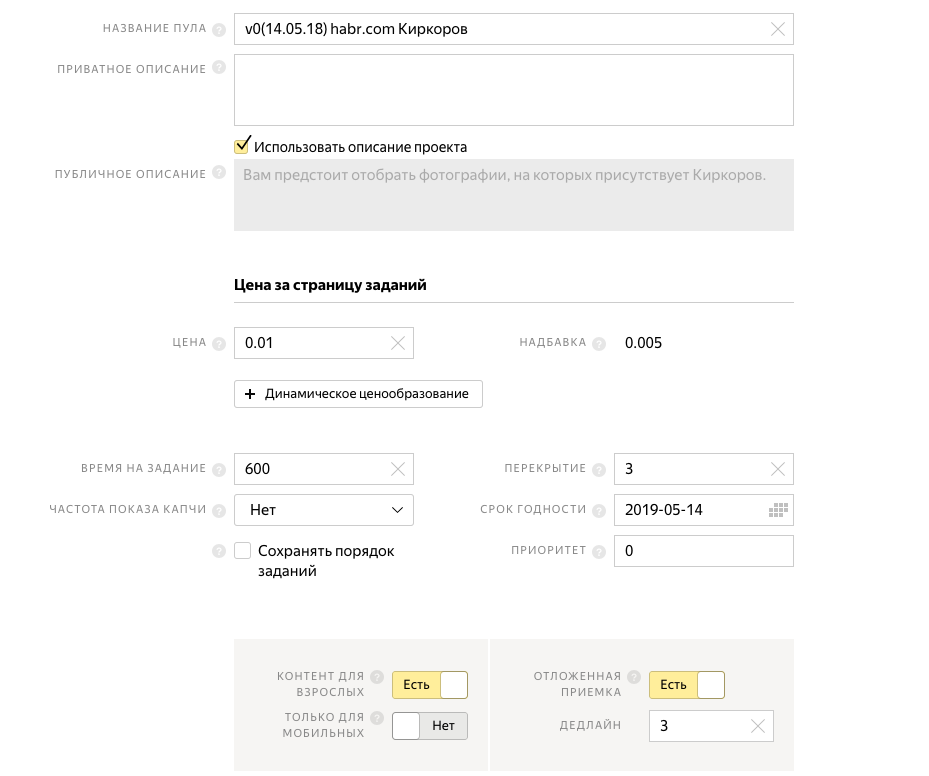
Придумываем название пула (оно видно только нам). Задаем цену 0.01$ за страницу заданий. Жадный Яндекс берет комиссию 0.005$. Время на задание: 10 минут. Перекрытие: 3 (каждая наша фотография будет показываться трем разным людям). Включим "КОНТЕНТ ДЛЯ ВЗРОСЛЫХ", а то мало-ли что плохого мы из интернета могли скачать. И активируем "ОТЛОЖЕННАЯ ПРИЕМКА", чтобы не дать денег тем фрилансерам, которые будут плохо выполнять задание.
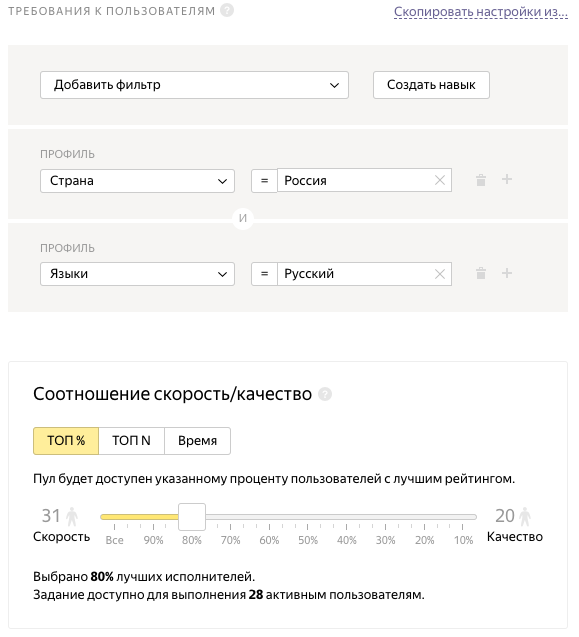
Далее идет пункт: "ТРЕБОВАНИЯ К ПОЛЬЗОВАТЕЛЯМ", в котором мы можем предъявить требования к исполнителям. В нашем случае исполнитель должен быть из России и владеть русским языком. Каждый исполнитель имеет свой рейтинг и мы можем выбрать исполнителей только с хорошим рейтингом. Выберем 80% лучших исполнителей.
Самым важным и самым сложным в плане освоения является блок контроля качества. Отдельное его описание потянет на целую статью, так что рекомендую ознакомиться с ним самостоятельно. В нашем проекте я выбрал ограничение на быстрые ответы. Если исполнитель 3 раза из 5 отвечает быстрее, чем за 40 секунд, то система его заблокирует.
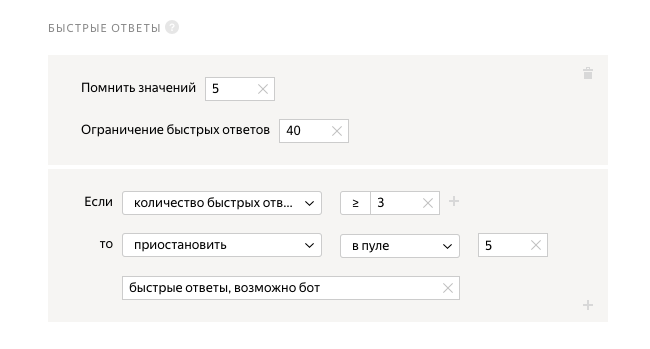
Отлично, мы на финишной прямой, осталось чуть-чуть. Сохраняем пул.
8. В созданном пуле скачиваем пример загрузочного файла. Загружаем наши изображения на Яндекс Диск или к себе на сервер, чтобы они были доступны по ссылке. В поле "INPUT:image" вставляем URL на наши изображения. Пример:
INPUT:image http://kucev.ru/Kirkorov/Kirkorov-pink_17_ 21787_l_jpg.jpg http://kucev.ru/Kirkorov/Kirkorov-green_82_ hqdefault_jpg.jpg http://kucev.ru/Kirkorov/Kirkorov-pink_25_ hqdefault_jpg.jpgЗагружаем полученный tsv файл на Яндекс Толоку. Указываем сколько изображений будет показываться исполнителю за один раз.
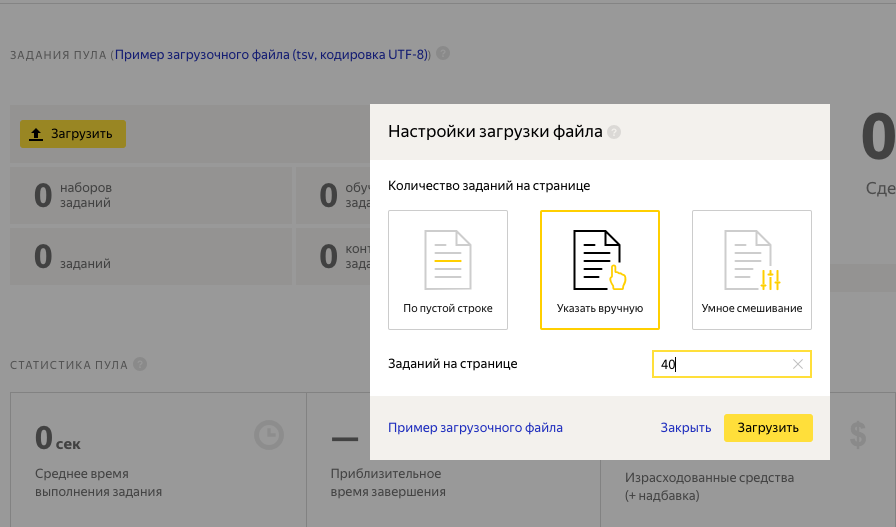
Отлично, никаких ошибок не вылезло, значит мы все сделали правильно и можем запустить наш пул.
9. Теперь нам надо проверить, что со стороны исполнителя все отображается правильно. Для этого создаем новый аккаунт на sandbox.toloka.yandex.ru, только теперь в качестве исполнителя. В аккаунте заказчика выбираем вкладку "Пользователи" и добавляем наш новый аккаунт исполнителя в список доверенных пользователей.
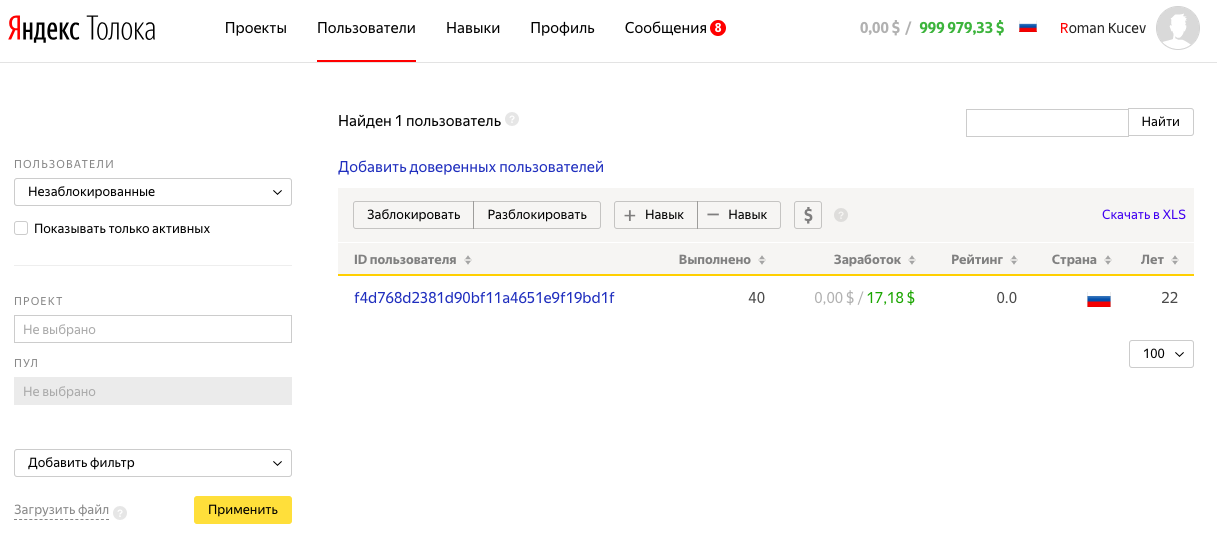
Отлично, если наш пул запущен, то теперь из тестового аккаунта исполнителя доступно наше задание.
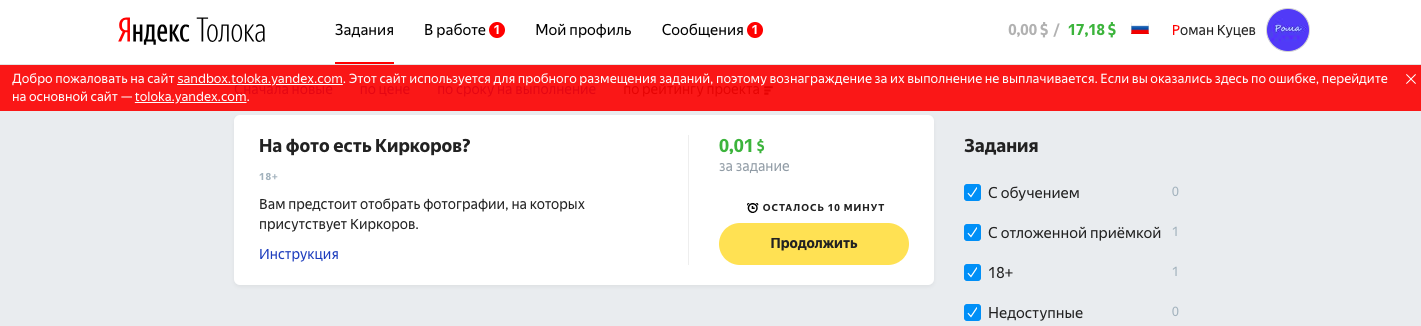
Нажимаем "Продолжить". Вот так будет выглядеть наша страничка для исполнителей:
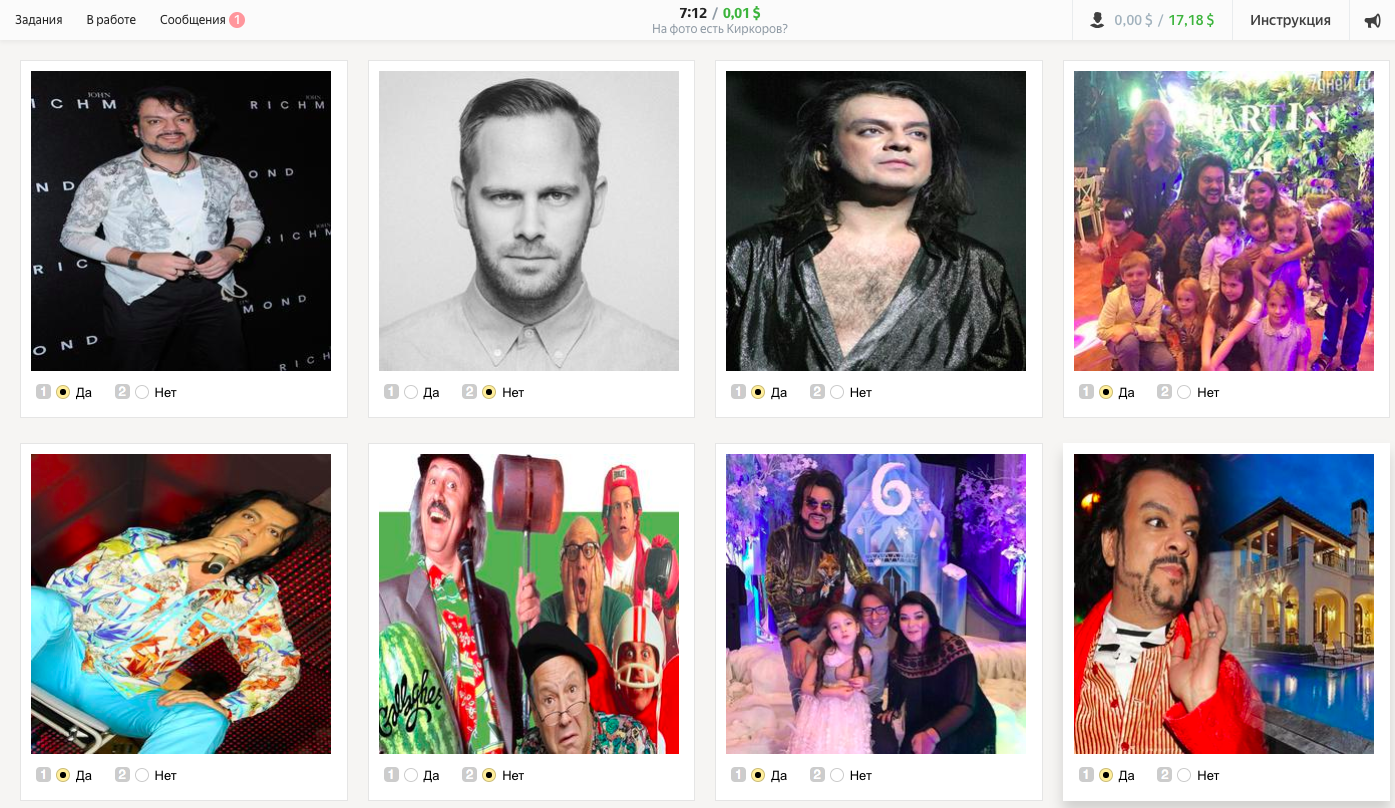
Проверяем, что все работает правильно и никаких багов не возникает.
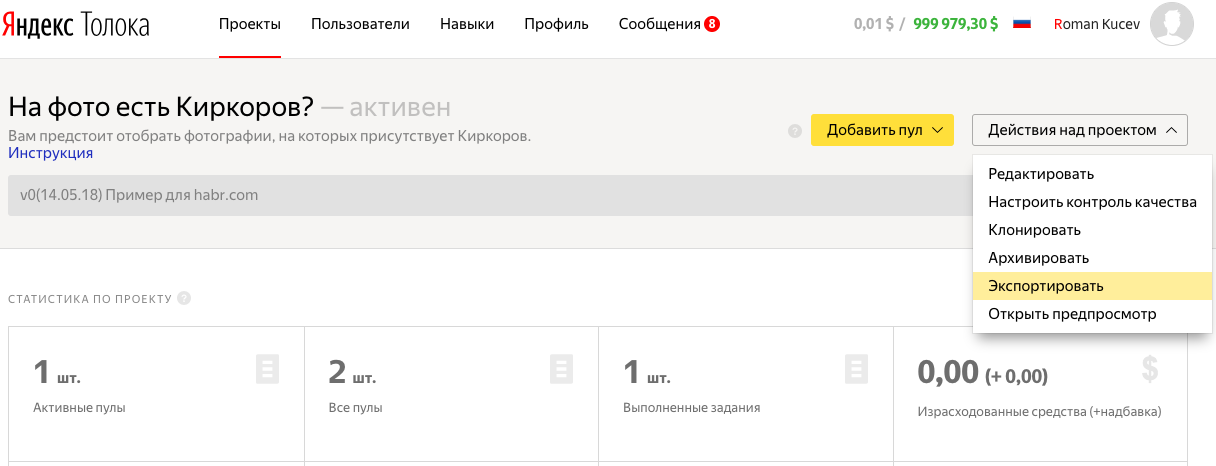
10. Если вы довольны результатом, то пора отпустить младенца в большой мир, т.е перенести наш проект из sandbox на основную Толоку. Для этого в аккаунте исполнителя во вкладке "Действия над проектом" выбираем "Экспортировать".
Заходим на toloka.yandex.ru и видим, что наш проект удачно экспортировался.
Открываем его, еще раз проверяем, что все верно. Как-то раз я допустил ошибку, неправильно сформировав задание и 2000 исполнителей, выполнив его, не смогли отправить результат (до сих пор неизвестно, сколько людей я убил).
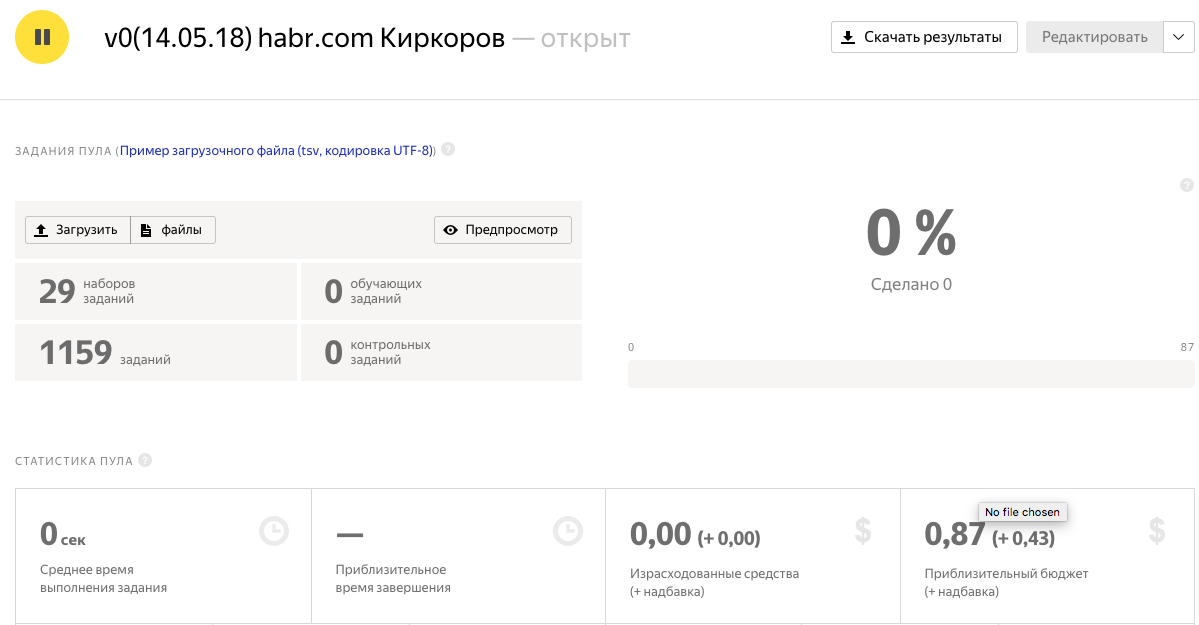
11. Запускаем пул, ждем 20 мин и получаем результат:

Итого: у нас было 1159 фото. На одной страничке для фрилансера размещалось по 40 фото. Т.е. было 1159 / 40 = 29 наборов заданий. Но мы делали с перекрытием 3, значит всего было показано 29 x 3 = 87 страничек. За одну страничку мы платим 0.01$ + 0.005$. Следовательно, чтобы проверить 1159 фото, у нас ушло 1.3$ или 80 руб. При этом фрилансеры получили всего 0.87$ или 50 руб, приблизительно потратив 97 сек x 87 заданий = 2 часа 20 минут. А готовы ли вы работать за 25 руб в час?
12. Проверяем задания и скачиваем результат.
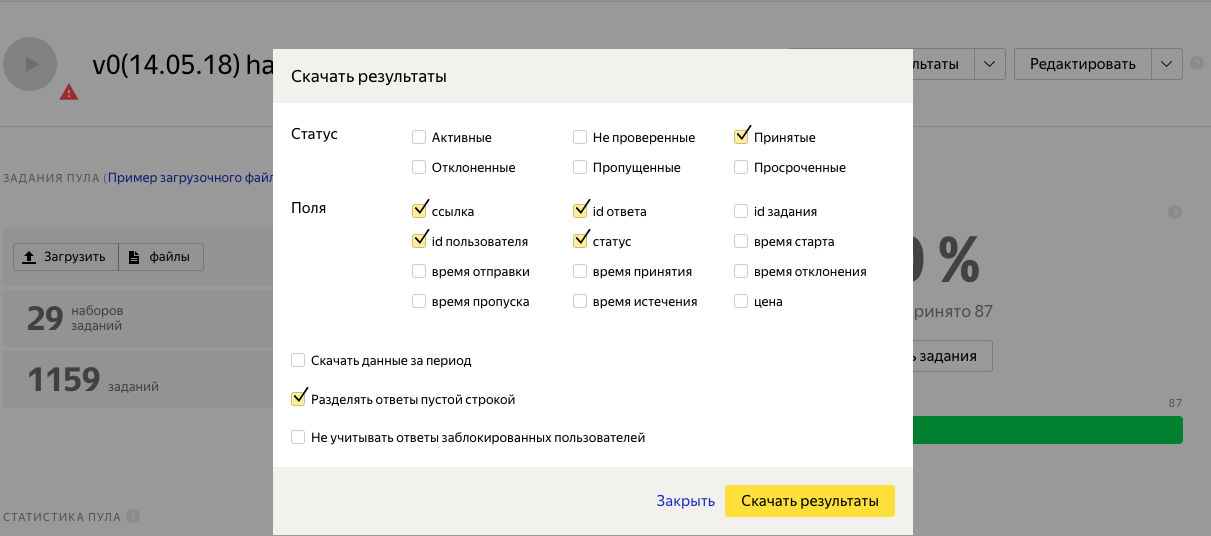
Открываем полученный файл в pandas, групируем по "INPUT:image"
import pandas as pd data = pd.read_csv('assignments_v0(14.05.18).tsv',sep = ' ') data['OUTPUT:output'] = data['OUTPUT:output'].map({'NO':0,'YES':1}) data_groupby = data.groupby('INPUT:image').sum()Получили:

data_groupby['OUTPUT:output'].value_counts() 3.0 634 0.0 445 2.0 57 1.0 23Используя метод голосования, и считая, что на фото Киркоров, если хотя бы два исполнителя проголосовали за него, получили 634 + 57 = 691 фото.
Подводя итог, хочется сказать, что:
- Толока — гибкий инструмент, который можно подстроить под любую задачу.
- На Толоке очень дешевая рабочая сила.
- На Толоке порядка 10000 исполнителей, что позволяет размечать огромные объемы данных за очень короткий промежуток времени.
- Толока обладает очень удобными инструментами для контроля исполнителей, что позволяет создавать качественную разметку датасета.
Из огромных минусов: нельзя на Толоке размечать персональные данные, так как с исполнителями не подписываются никакие NDA и это будет являеться нарушением 152-ФЗ и GDPR.
Если вам интересна тема по созданию датасетов, то ставьте плюсы и в следующей статье я расскажу, как создавать датасеты для приложения sticky-ai.
Телеграм: t.me/ainewsline
Источник: habr.com