Как имитация нейронной сети может помочь нам понять обучение и обобщение?
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-06-23 17:00
Автор Maithra Рагху, Google Brain Team и С. Ари Моркос, DeepMind
Для решения задач глубокие нейронные сети (Dnn) постепенно преобразуют входные данные в последовательность сложных представлений (т. е. в модели активаций отдельных нейронов). Понимание этих представлений критически важно не только для интерпретируемости, но и для того, чтобы мы могли более разумно проектировать системы машинного обучения. Однако понимание этих представлений оказалось довольно сложным, особенно при сравнении представлений в сетях. В предыдущем посте мы определили преимущества канонический Корреляционный Анализ (ССА) в качестве инструмента для понимания и сравнения представления сверточных нейронных сетей (CNNs), показывает, что они сходятся в восходящий паттерн, с ранних слоев, сходящихся к их окончательной представления до позднейших наслоений в течение обучения. В “выводы о представительских сходство в нейронных сетях с канонической корреляции"мы развиваем эту работу в дальнейшем, чтобы дать новые представления о представительском сходстве CNN, включая различия между сетями, которые запоминают (например, сети, которые могут только классифицировать изображения, которые они видели раньше) от тех, которые обобщают (например, сети, которые могут правильно классифицировать ранее невидимые изображения). Главное, мы также расширить этот метод, чтобы обеспечить понимание динамики рекуррентных нейронных сетей (RNNs), класс моделей, которые особенно полезны для последовательных данных, таких как язык. Сравнение Rnn трудно во многих из тех же способов, как CNN, но Rnn представляют дополнительную проблему, что их представления изменяются в течение последовательности. Это делает CCA, с его полезными инвариантами, идеальным инструментом для изучения Rnn в дополнение к CNN. Таким образом, мы дополнительно с открытым исходным кодом этот код используется для применения КЦА на нейронных сетях с надеждой, что поможет научному сообществу лучше понять сеть динамика. Представительские сходство запоминания и обобщения CNNs В конечном счете, система машинного обучения полезна только в том случае, если она может быть обобщена на новые ситуации, которых она никогда не видела. Таким образом, понимание факторов, которые различают сети, которые обобщают, и те, которые не являются необходимыми, может привести к новым методам повышения производительности обобщения. Чтобы исследовать, является ли репрезентативное сходство предсказательным для обобщения, мы изучали два типа CNNs
- обобщающее сетей: CNNs обучение на данных с немодифицированными, точный метки и где узнать решения, которые обобщают новые сведения.
- запоминание сетей: CNNs подготовленных наборов данных с рандомизированным таких лейблах, что они должны запомнить данные и не может, по определению, обобщать (как в Чжан и соавт., 2017).
Мы тренировались несколько экземпляров каждой сети, отличающихся только в начальной рандомизированных значений весов сети и порядок подготовки данных и использовать новый взвешенный подход для расчета ОСО "измерить расстояние" (см. нашу газету за подробности) для сравнения представлений в каждой группе сетей и между запоминания и обобщения сети. Мы обнаружили, что группы из разных обобщающее сетей неизменно сходились, чтобы больше подобных представлений (особенно в более поздних слоях), чем группы заучивание сети (см. рисунок ниже). На softmax, который обозначает конечное предсказание сети, расстояние CCA для каждой группы обобщающих и запоминающих сетей существенно уменьшается, поскольку сети в каждой отдельной группе делают похожие прогнозы.
 |
| Группы обобщающих сетей (синие) сходятся к более сходным решениям, чем группы запоминания сетей (красные). Расстояние CCA было рассчитано между группами сетей, обученных на реальных метках CIFAR-10 (”обобщение“) или рандомизированных метках CIFAR-10 (”запоминание“) и между парами запоминания и обобщения сетей (”Интер"). |
Возможно, самое удивительное, что в более поздних скрытых слоях репрезентативное расстояние между любой заданной парой сетей запоминания было примерно таким же, как репрезентативное расстояние между сетью запоминания и обобщения (“Inter” в приведенном выше сюжете), несмотря на то, что эти сети были обучены данным с совершенно другими метками. Интуитивно этот результат предполагает, что хотя существует много разных способов запоминания обучающих данных (что приводит к большей ОСО расстояния), есть меньше способов научиться обобщать решений. В будущей работе мы планируем изучить, можно ли использовать это понимание для упорядочения сетей, чтобы узнать больше обобщаемых решений. Понимание динамики обучения Рекуррентных нейронных сетей До сих пор мы применяли только CCA к CNNs, обученным данным изображений. Тем не менее, CCA также может быть применен для расчета репрезентативного сходства в Rnn, как в течение обучения, так и в течение последовательности. Применение КЦА на RNNs, мы сначала просили ли RNNs выставлять такие же снизу вверх сходимости картину мы наблюдали в нашей предыдущей работе для CNNs. Чтобы проверить это, мы измерили расстояние CCA между представлением на каждом слое RNN в течение курса обучения с его окончательным представлением в конце обучения. Мы обнаружили, что расстояние CCA для слоев ближе к входным данным упало раньше в обучении, чем для более глубоких слоев, демонстрируя, что, как CNN, RNS также сходятся в восходящем шаблоне (см. рисунок ниже).
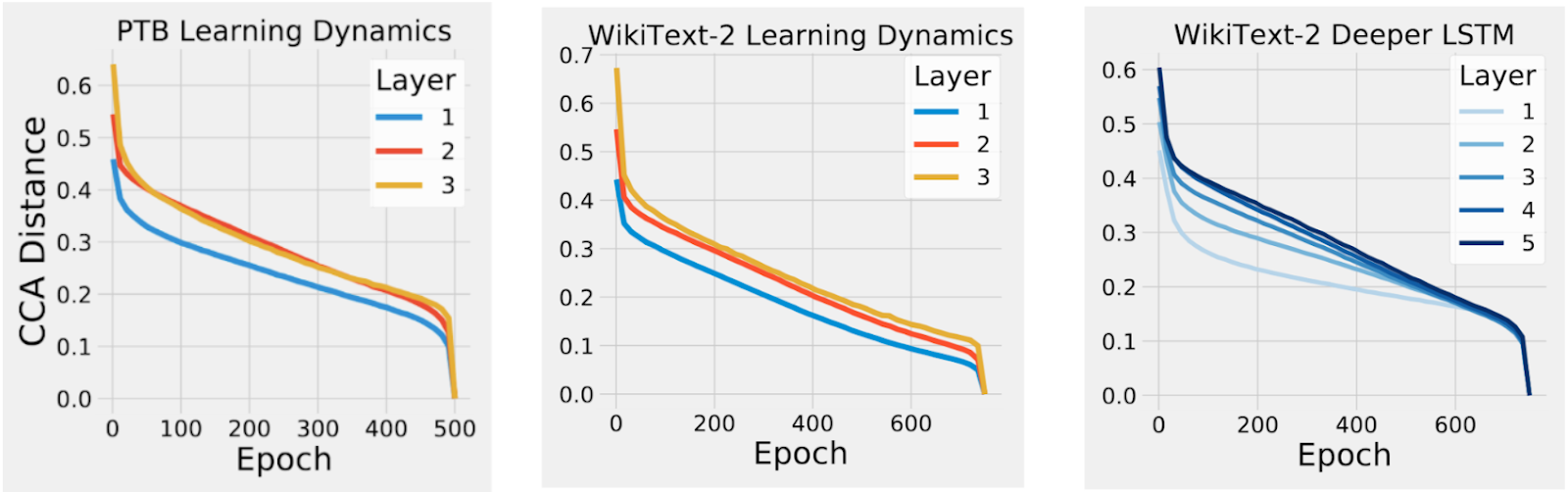 |
| Динамика конвергенции для Rnn в течение обучения показывает снизу вверх конвергенцию, так как слои ближе ко входу сходятся к их окончательным представлениям раньше в обучении, чем более поздние слои. Например, уровень 1 сходится к своему окончательному представлению раньше в обучении, чем уровень 2, чем уровень 3 и так далее. Epoch обозначает количество раз, когда модель видела весь набор обучения, в то время как различные цвета представляют динамику конвергенции различных слоев. |
Дополнительные результаты в нашей работе показывают, что более широкие сети (например, сети с большим количеством нейронов на каждом слое) сходятся к более похожим решениям, чем узкие сети. Мы также обнаружили, что обученные сети с идентичными структурами, но разными скоростями обучения сходятся к отдельным кластерам с аналогичной производительностью, но сильно отличающимися друг от друга представлениями. Мы также применяем cca к динамике RNN в течение одной последовательности, а не просто в течение обучения, обеспечивая некоторое первоначальное понимание различных факторов, которые влияют на представления RNN с течением времени. Выводы Эти результаты укрепляют полезность анализа и сравнения представлений DNN, чтобы получить представление о сетевой функции, обобщении и сходимости. Тем не менее, все еще остается много открытых вопросов: в будущей работе мы надеемся выяснить, какие аспекты представления сохраняются в сетях, как в CNN, так и в Rnn, и могут ли эти идеи использоваться для улучшения производительности сети. Мы призываем всех попробовать код , используемый для газеты, чтобы выяснить, что ОАС может рассказать нам о других нейронных сетей!
Телеграм: t.me/ainewsline
Источник: ai.googleblog.com