Efficient Interactive Annotation of Segmentation Datasets with Polygon-RNN++
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-06-21 18:08
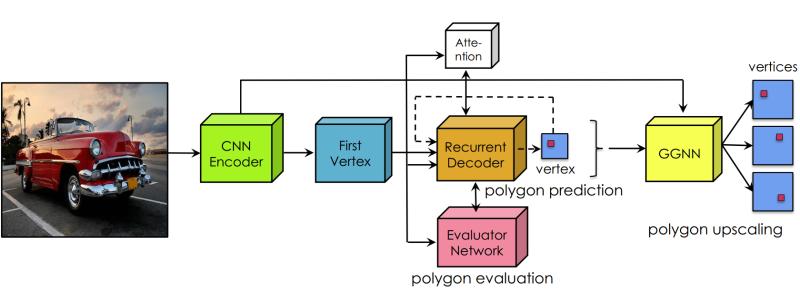
Как мы говорили ранее, сотрудник CVisionLab отправился в Солт-Лейк-Сити на международную конференцию CVPR. Одной из самых интересных работ стала презентация команды из университета Торонто. Она представила рекуррентную сеть PolygonRNN++, предсказывающую точки полигона.
Начальной инициализацией служит bounding box нарисованный пользователем вокруг объекта. После этого сеть предсказывает точки полигона. При этом сеть быстро работает даже на не самых сильных устройствах: на презентации она учла все изменения и быстро обработала данные на простом ноутбуке.
Обучение выполняется на сегментационном датасете, но при этом информация о классах объектов не используется, поэтому обученная сеть умеет выделять любые объекты, а не только те, которые были размечены в датасет: например, натренировавшись на модели города, она справилась и с медицинскими изображениями.
Мы учимся прогнозировать интерактивные полигональные аннотации объектов, чтобы сделать аннотации наборов данных сегментации намного быстрее.
Маркировка наборов данных вручную масками объектов занимает очень много времени. В этой работе мы следуем идее PolygonRNN для создания полигональных аннотаций объектов в интерактивном режиме с использованием Human-in-the-loop. Мы вводим несколько важных улучшений к модели: 1) мы конструируем новое зодчество шифратора CNN, 2) показываем как эффектно к тренируйте модель с усилением обучения, и 3) значительно увеличивайте выходное разрешение с помощью графа Neural Сеть, позволяющая модели точно комментировать объекты highresolution в изображениях. Обширная оценка Набор данных Cityscapes показывает, что наша модель, которую мы называем Polygon-RNN++, значительно превосходит оригинальную модель в автоматическом режиме (10% абсолютное и 16% относительное улучшение среднего IoU) и интерактивных режимов (требуется 50% меньше кликов по аннотаторам). Далее мы анализируем междоменный сценарий, в котором наша модель обучена на одном dataset, и используемый из коробки на наборах данных от меняя доменов. Результаты показывают, что Polygon-RNN++ обладает мощными возможностями обобщения, достигая значительных улучшения по сравнению с существующими пиксельными методами. Используя простую онлайн-настройку, мы достигаем высокого сокращения времени аннотации для новых наборов данных, приближая шаг к интерактивному инструменту аннотации, который будет использоваться на практике.
# работа выполнена, когда Д. А. был в UofT
 | Дэвид Акуну*, Хуань Лин*, Amlan Кар*, Саня Фидлер Эффективные аннотации Сегментация данных с PolygonRNN++ CVPR, 2018. (казаться |
Результаты


Автоматическая Аннотация городских пейзажей (с учетом ограничителей GT
Автоматическая Аннотация на ADE20k (учитывая ограничительные рамки GT, используя модель, обученную только на городских пейзажах). Наши в желтом, GT в белом

Среднее количество кликов на один экземпляр, необходимое в нашей модели (слева и выше лучше
Телеграм: t.me/ainewsline
Источник: www.cs.toronto.edu