Женские сети: кто делает за нас выбор?
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-05-15 11:39
У нас была возможность использовать нейронные сети для решения задачи по предсказанию поведения людей, а специфика области применения была связана с индустрией красоты. Основной аудиторией для “опытов” стали женщины. Мы по сути пришли к вопросу: может ли искусственная нейронная сеть понять настоящую нейронную сеть (человека) в той области, в которой даже сам человек еще не осознал своего поведения. Как мы ответили на этот вопрос и что у нас получилось в итоге, можно узнать далее.

Вместо массированных бомбардировок рекламой применяем точечные персонализированные предложения
Любому ритейлеру хочется повысить свои продажи. Для этого нам надо предложить товары, которые клиент купит с наибольшей вероятностью, с помощью наиболее оптимального канала коммуникации и сделать это в подходящий момент. Таким образом, в первую очередь магазину нужна рекомендательная система, а также систематическая оркестровка каналов и несколько предсказательных моделей. Такую AI-задачу взяли мы, CleverDATA, по заказу агентства Beauty Brains.

Преимуществом новой экспериментальной системы стало то, что использовалась, во-первых, дополнительная информация о продуктах из их текстовых описаний, и во-вторых, учитывалась последовательность покупок клиентов.
Далее мы стали подключать различные каналы коммуникаций: в первую очередь, почтовую рассылку, которая является одним из самым дешевых каналов. Кроме того, адресатам стали доставляться сообщения в Facebook и реклама через Adwords.
В итоге мы подготовили для маркетологов заказчика self-driving решение, которое представляет собой ежедневный набор рассылок высокой степени персонализации. Естественно, количество кампаний ощутимо выросло, а численность получателей каждой из них драматически уменьшилась. То есть мы предоставили маркетологу в качестве инструмента множество “микрокампаний”, где каждый конкретный покупатель получает предложение с наиболее релевантным товаром на индивидуальных условиях (с персональной скидкой, подарками, пробниками, если последние интересуют покупателя и т.п.).
Кроме того, у нас в распоряжении было знание, полученное при анализе большого массива бьюти-блогов. О результатах анализа этого корпуса я уже подробно писал на Хабре. Разумеется, в рассылках используются LTV-прогнозирование, предсказание оттока, расчет лояльности, предсказание подходящей скидки, а также предсказание восприимчивости клиента к подаркам и пробникам. Чем больше вероятность, что клиент скоро совершит покупку, тем меньшую скидку он получает. А если покупок давно не было, человек попадает в группу клиентов, которых бренд рискует потерять, скидки для него увеличиваются.
Тестирование системы проводилось в течение сентября-декабря 2017 года, в результате проект был признан успешным. Далее я рассмотрю конкретный случай, который нам пришлось решать в рамках проекта.
Учим сети понимать людей. Какие инструменты выбрать?

{kind=link}
Т.е. нам необходимо предсказать поведение людей и запускать кампании только на узкой целевой аудитории. Дополнительной информации об этих потенциальных клиентах нет, бренд знает только, как они открывали письма и по каким ссылкам переходили. Поэтому мы пришли к задаче научить машину понимать поведение людей.
Эту задачу возможно решить множеством способов. Мы пошли по направлению нейронных сетей.
Итак, мы будем работать с последовательностью действий получателя рассылки,
а для обработки серии событий хорошо подходят рекуррентные нейронные сети (часто их используют для обработки текстов). Про это семейство уже многократно писалось на Хабре (например, здесь или здесь). Рекуррентные нейронные сети в их классической реализации обладают рядом характерных проблем, например, они быстро забывают. Если мы будем тренировать классическую рекуррентную нейронную сеть на книге, то к середине главы она забудет, с чего эта глава начиналась. Сегодня широкое распространение получили LSTM-нейронные сети, которым удалось преодолеть многие проблемы классических нейронных сетей. LSTM нейронные сети обладают памятью: они оперируют ячейками, которые могут запоминать, воспроизводить и забывать информацию. Кроме того, LTSM-сети хороши в тех случаях, когда события разделены временными лагами с неопределенной продолжительностью и границами.

{kind=link}
Если мы результат работы модели планируем использовать в других моделях, то необходимо очень тщательно следить за тем, чтобы информация о будущем не перешла вместе с предсказаниями модели. Если непреднамеренно случится перетекание информации о будущем, то новая модель будет переобучаться. Поэтому для последующего использования будет удобнее тренироваться на событиях, не зная их результата, и сводить последовательность событий в признаки, которые потом можно было бы использовать в других предсказательных моделях. И в этом нам способен помочь автоэнкодер, или автокодировщик.
Про автоэнкодеры на Хабре тоже можно почитать, например здесь и здесь. Они построены так, что имеют одинаковую размерность на входе и выходе, а размерность в середине значительно меньше. Такое ограничение заставляет нейронную сеть искать обобщения и корреляции в последовательности событий, поэтому автокодировщики вынуждены как-то обобщать входящие данные. В тренировке такой сети используется принцип обратного распространения ошибки, как в обучении с учителем, однако мы можем требовать, чтобы сигнал на входе и сигнал на выходе сети были максимально близкими. В итоге мы будем тренироваться, не используя информацию о результате, к которому привела последовательность действий, т.е. получится обучение без учителя.

Общая структура нашей нейронной сети понятна: это будет автоэнкодер, использующий LSTM-ячейки. Осталось решить, как закодировать последовательность действий потенциального покупателя. Одним из вариантов является one-hot-encoding: действие кодируется единицей, остальные альтернативы действия — нулем.



На одном из брендов мы получили датасет из нескольких тысяч компаний, рассылаемых на ~ 200 000 человек. Таким образом, тренировочная выборка состояла из примерно 200 000 векторов, кодирующих последовательность действий получателей рассылки.
От теории к практике
В начале кодировщика ставим слой LSTM-ячеек, который будет переводить серию событий в вектор, содержащий информацию обо всей последовательности. Можно сделать ряд последовательных LSTM-слоев, постепенно уменьшая их размерность. Чтобы вернуть представление от вектора к последовательности событий, повторим этот вектор n раз перед тем, как подать его на вход LSTM-слоя декодера. Общая схема такого автокодировщика на keras будет занимать буквально несколько строк и приведена ниже. Обратите внимание на то, что LSTM-слой декодера должен возвращать не вектор, а последовательность, что указывается посредством параметра return_sequences=True.
from keras.layers import Input, LSTM, RepeatVector from keras.models import Model inputs = Input(shape=(timesteps, input_dim)) encoded = LSTM(latent_dim)(inputs) decoded = RepeatVector(timesteps)(encoded) decoded = LSTM(input_dim, return_sequences=True)(decoded) sequence_autoencoder = Model(inputs, decoded) encoder = Model(inputs, encoded)Если ничего не напутать с размерностями тензоров, то сеть будет тренироваться. В дальнейшем для повышения качества модели мы добавили несколько дополнительных LSTM-слоев как в кодировщик, так и в декодировщик, а в качестве “бутылочного горлышка” использовали несколько обычных полносвязных слоев нейронов, естественно, не забывая про Dropout, Batch Normalization и другие приемы для тренировки нейронных сетей.
Для сравнения мы попробовали обучить актокодировщик на сверточных нейронных сетях (Сonvolution Neural Networks, CNN) на том же наборе данных. Сверточные слои помогают установить паттерны поведения объектов и позволяют сократить количество параметров модели, что ощутимо ускоряет обучение. Про сверточные нейронные сети тоже есть статьи на Хабре (здесь, здесь и, например, здесь), поэтому мы не будем останавливаться на них подробно. Схематично архитектура автокодировщика на сверточных нейронных сетях выглядит следующим образом:
from keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D from keras.models import Model input_tensor = Input(shape=input_dim) x = Conv2D(16, (3, 3), activation='relu', padding='same')(input_tensor) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) encoded = MaxPooling2D((2, 2), padding='same')(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(encoded) x = UpSampling2D((2, 2))(x) x = Conv2D(8, (3, 3), activation='relu', padding='same')(x) x = UpSampling2D((2, 2))(x) x = Conv2D(16, (3, 3), activation='relu')(x) x = UpSampling2D((2, 2))(x) decoded = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x) autoencoder = Model(input_tensor, decoded)Т.к. элементы тензоров принимают значения в диапазоне от 0 до 1, то можно воспользоваться функцией потерь перекрёстной энтропии (binary crossentropy).
Результат обучения автокодировщика на CNN по метрике качества оказался даже выше, чем автокодировщика на LSTM, а время обучения заметно быстрее.
Кроме того, возможно сделать автокодировщик на CNN и LSTM: сначала несколько сверточных слоев, затем автокодировщик на основе LSTM, завершающийся декодировщиком на основе сверточных слоев. Такой автокодировщик будет объединять положительные стороны обоих подходов. По нашему опыту, такой автокодировщик незначительно лучше автококодировщика на CNN и значительно лучше автокодировщика на LSTM по метрикам качества на валидационной выборке.
После тренировки кодировщик переводит последовательность действий для каждого получателя в вектор признаков, и таким образом мы получаем аналог word2vec для серии событий. Полученный вектор возможно использовать в других предиктивных моделях, кластеризации, в поиске близких по поведению людей, а также выполнять поиск аномалий.
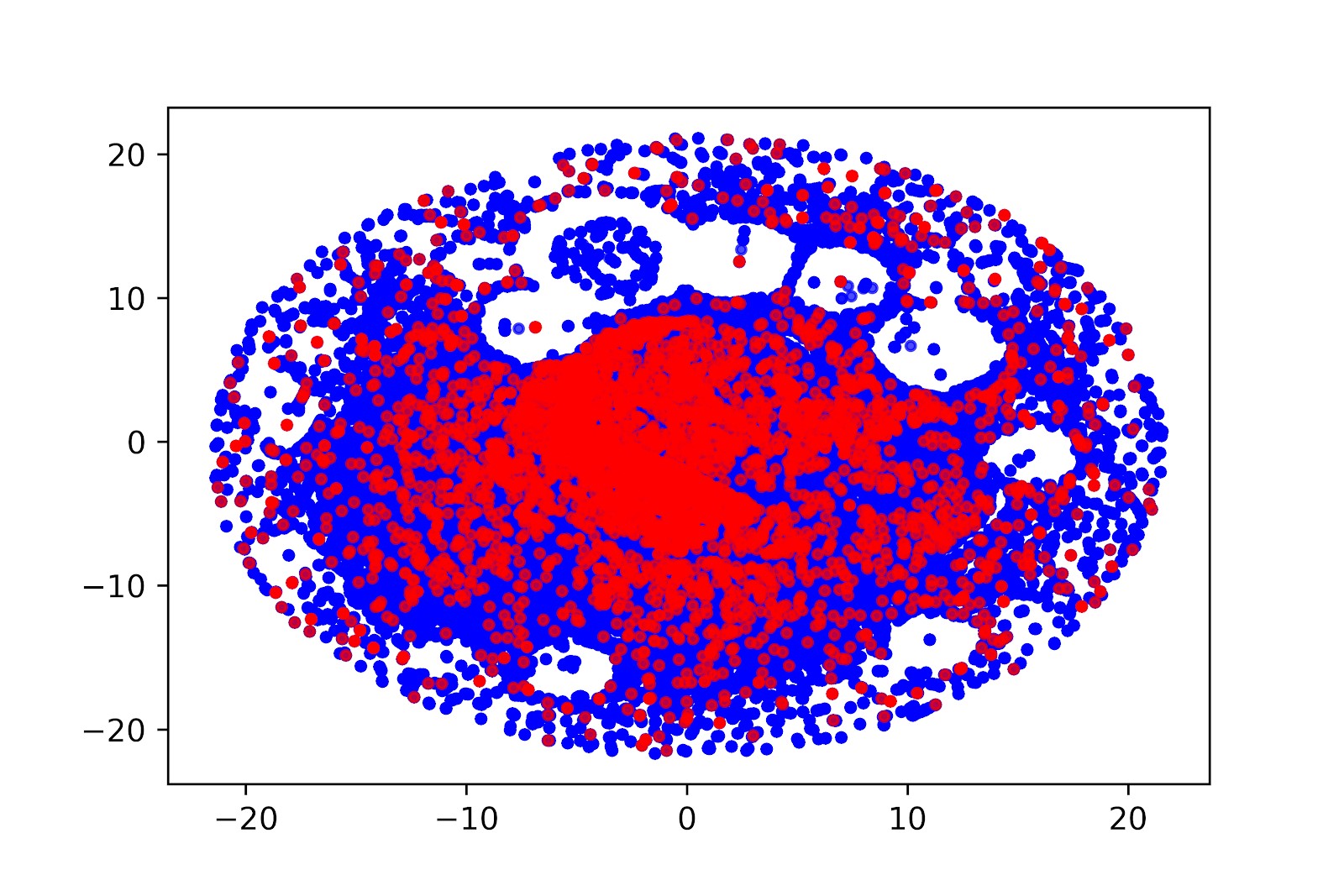
В нашем случае мы строили модель, предсказывающую вероятность покупки получателя письма. Модель на ряде основных признаках давала roc-auc 0.74-0.77, а с добавленными векторами, отвечающими за поведение человека, roc-auc достигал 0.84-0.88.
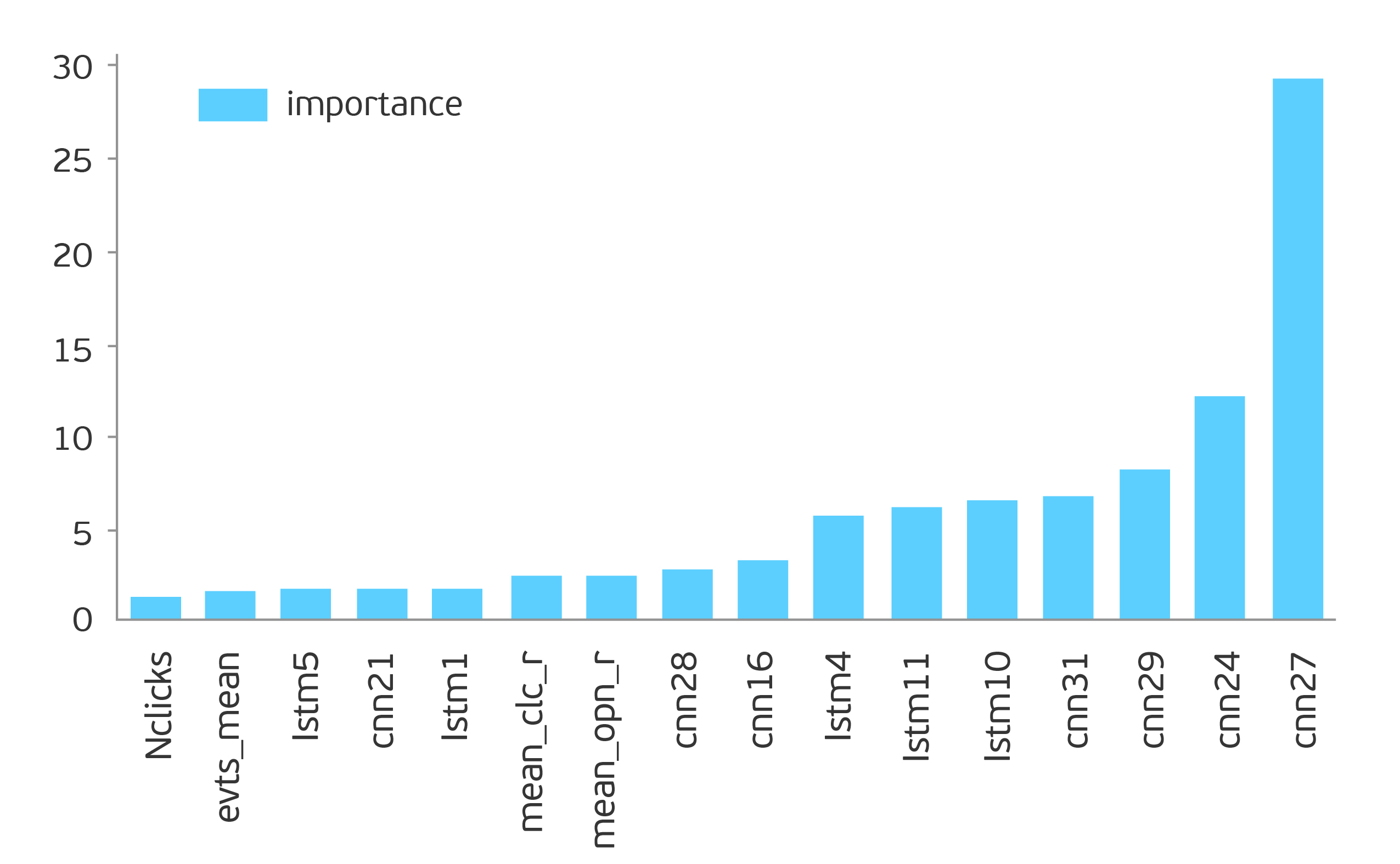
Необходимо признать, что использование автокодировщика на основе CNN для данной задачи давало более качественный результат, однако автокодировщик на основе LSTM давал вектора меньшей размерности и позволил немного дополнительно подтянуть roc-auc. Если использовать признаки на основе автокодировщика СNN + LSTM, то roc-auc получается в диапазоне 0.82-0.87.

Выводы
Наш опыт подтвердил тот факт, что поведение людей возможно закодировать посредством автокодировщика на нейронных сетях: в нашем случае последовательность поведения получателей рассылки были закодированы с помощью автокодировщиков на LSTM и на CNN-архитектурах. Рассылкой писем применение этого подхода не ограничено: закодированное поведение объектов можно использовать в других задачах, требующих работы с поведением человека: поиск мошеннических действий, предсказания оттока, поиск аномалий и т.д.
Предложенный подход можно развивать в сторону вариационных автокодировщиков, если в этом есть потребность в моделировании поведения людей.
Тот факт, что автокодировщик на основе CNN с рассмотренной задачей справляется лучше, чем на LSTM, дает возможность предположить, что паттерны поведения позволяют для данной задачи извлечь более информативные признаки, чем признаки на основе временных связей между событиями. Тем не менее, на подготовленном наборе данных есть возможность использовать оба подхода, и суммарный эффект от совместного использования признаков обоих автокодировщиков дает прирост к roc-auc на 0.01-0.02.
Таким образом, нейронные сети в состоянии понять по поведению человека, что он склонен к покупке, возможно даже до того, как сам человек это осознает. Удивительный пример фрактальности нашего мира: нейроны людей помогают организовать тренировку нейронных сетей с целью предсказать результат работы нейронов других людей.

Телеграм: t.me/ainewsline
Источник: habr.com