Разговорный AI: как работают чат-боты и кто их делает
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-05-28 12:32

Чатботы и искусственный интеллект для понимания естественного языка (NLU – Natural Language Understanding) тема достаточно горячая, про нее не раз говорилось на Хабре. Тем не менее достаточно редко попадаются верхнеуровневые и структурированные обзоры этих технологий и рынка в целом. В своей статье мы попробуем немного разобраться, чем обусловлен спрос на эти технологии, как выглядит современная диалоговая платформа для NLU, какие компании и разработки присутствуют на этом рынке.
Мы, в Just AI (а ранее в i-Free), работаем в этом сегменте с 2011 года, разрабатываем и совершенствуем свою платформу для понимания и обработки естественного языка (NLU-алгоритмы): даем компаниям возможность автоматизации колл-центров и служб поддержки, создаем бизнес-навыки для Яндекс.Алисы. Еще мы учим говорить роботов и умные устройства: в 2017 году был выпущен наш детский робот «Емеля» — первый девайс на российском рынке, который понимает естественный язык (и, кстати, на сегодняшний день свой дом обрели уже около 7000 Емель). Статья – вводная, и если эта тема покажется интересной, то мы будем периодически писать об особенностях создания разговорных интерфейсов, в том числе в формате конкретных кейсов, которые были реализованы для наших клиентов, а также об особенностях различных платформ, технологий и алгоритмов.
Совсем немного истории
Хотя AI — это достаточно широкая область, включающая в себя машинное зрение, предиктивный анализ, машинный перевод и другие области – понимание естественного языка (NLU) и его генерация (NLG) является значительной и быстрорастущей его частью. Первые чатботы и системы их разработки появились достаточно давно. Опуская историю, начавшуюся еще в 50-е годы с Алана Тьюринга и программы Элиза в 60-е годы, а также научные исследования в области лингвистики и машинного обучения 90-х годов, значимым событием более новой истории стало появление языка разметки AIML (Artificial Intelligence Markup Language), разработанной в 2001-м году Ричардом Уэлсом (Richard Wallace) и созданным на его основе чатботом A.L.I.C.E.
В течение последующих десяти лет подходы к написанию чатботов во многом представляли из себя переработки или улучшения этой методологии, получившей название «rule-based подход» или «подход на основе формальных правил». Его суть состоит в выделении семантически значимых элементов фраз, их кодификации, создания специальных формальных скриптовых языков программирования, позволяющих описывать сценарии диалогов. В большинстве привычных нам сегодня ассистентов, в основе своей, используется именно этот подход. Новейшие среды разработки на основе формальных правил – это сложные и комплексные системы, включающие в себя:
- системы ранжирования гипотез разбора,
- выделение именованных сущностей из текста,
- морфологический анализ фраз,
- системы управления диалогом и сохранения локального и глобального контекста,
- интеграции и вызовы внешних функций.
Тем не менее, большая часть разговорных решений на основе подобных систем достаточно трудоемка в своей реализации: чтобы чатбот общался на широкий спектр тем или глубоко и полно покрывал специфичную область знаний требуется большое количество человеческого труда.
Ситуация в этой области существенно изменилась в последнее время с развитием алгоритмов определения семантической близости текстов и технологий машинного обучения в целом, сделавших подходы к классификации текстов и обучению NLU-систем гораздо более быстрыми и удобными. Например, в диалогах, где чатботу требуется получать доступ к большим массивам внешних данных, выделять сотни тысяч именованных сущностей и интегрироваться с внешними информационными системами, по-прежнему требуется приложение большого количества человеческого труда, но процесс создания сложных чатботов стал в разы проще, а точность распознавания интентов пользователя – существенно выше. Именно эти технологии, вместе с заметным продвижением в области технологий синтеза и распознавания речи, а также распространением мессенджеров и вебчатов – обусловили стремительный рост количества внедрений NLU-технологий в 2015-2018-м годах.
Почему эти технологии стали так популярны именно сейчас?
На сегодняшний день есть несколько ключевых драйверов, обеспечивающих рыночный рост технологий NLU.
1. Контакт-центры
Это наиболее крупный рынок для применения NLU-алгоритмов (по данным Everest Group – 330 млрд. долларов в год). Контакт-центры используются сотнями тысяч компаний в мире, начиная с банков, крупных ритейлеров и заканчивая небольшими бизнесами, обслуживающими клиентов силами 2-3 менеджеров отдела поддержки. Огромное количество рутинных операций все чаще передаются искусственному интеллекту: чатботы могут быть использованы для ответов на типовые вопросы (по принципу FAQ, но с понимаем естественного языка и запросов пользователя), в режиме “call steering” для маршрутизации пользователя в нужный ему отдел компании через умный IVR, а также в качестве «суфлеров» — ботов для интеллектуальных подсказок операторам колл-центра. Все это позволяет существенно сократить издержки на персонал и повысить пропускную способность КЦ без увеличения штата. Однако, наиболее эффективна связка AI+Human, когда сложные аналитические вопросы переводятся на оператора, который имеет возможность уделить клиенту достаточное количество времени, по-настоящему помочь и решить проблему.
2. Говорящие устройства
3 года назад появился Amazon Echo, и привычный мир стал еще немного комфортнее: ассистент Alexa умеет будить в заданное время, включать любимую музыку, управлять умным домом, находить и рассказывать новости, заказывать продукты на дом, позволяет вызвать такси или заказать пиццу с доставкой. Это первое массовое устройство на рынке США, обладающее качественным распознаванием речи и умением слышать запрос даже в условиях сильных внешних шумов. Следом появилось устройство Google Home от Google, и на текущий момент они с Amazon делят рынок в примерном соотношении 3:1 (преимущество на стороне Amazon). На рынке Китая борьба еще более жесткая, каждый из интернет-гигантов к 2018 выпустил свою собственную умную колонку – это компании Baidu, Xiaomi, Alibaba, Tencent и JD.com.
Но умными колонками этот рынок не ограничивается – роботы, детские игрушки, девайсы для автомобилей и интеллектуальная бытовая техника, в 2018 году здесь еще предстоит много удивительных открытий. Только у себя, в Just AI, мы работаем над 5-ю подобными проектами в настоящее время.
3. Голосовые ассистенты (IVA)
Alexa от Amazon, Google Assistant от Google, Siri от Apple, Cortana от Microsoft, Алиса от Яндекса – они определяют интенты (намерения) пользователей и исполняют команды. Значительная часть скилов (навыков) создается на сторонних NLU-платформах. Яндекс сейчас формирует вокруг своего ассистента Алисы целую экосистему навыков, открыв бета-версию Яндекс.Диалогов для сторонних разработчиков. При этом рынок виртуальных ассистентов интересен не только для рынка конечных пользователей устройств, он имеет все шансы занять часть рынка автоматизации саппорта для бизнеса (уже сейчас Google Assistant маршрутизирует запросы пользователей в контакт-центры компаний).
В целом, говорящие девайсы и ассистенты – наиболее интересная и перспективная область применения технологий разговорного AI. Плюс это – прямая точка контакта бизнеса и конечного потребителя. Спрос на подобные технологии увеличивается с каждым годом, и Россия не исключение.
Как устроены технологии разговорного AI?
Кратко схему взаимодействия пользователя и, например, чатбота можно представить так:
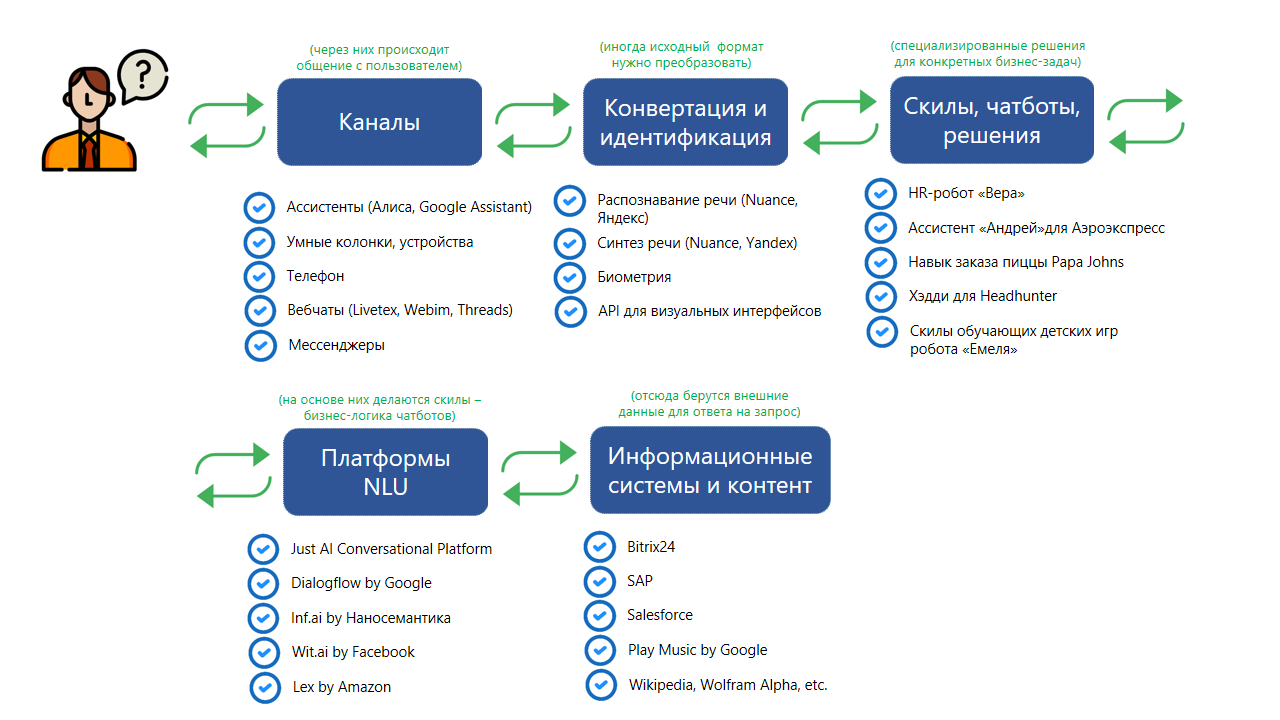
Первоначально пользователь адресует свой запрос в какой-либо из доступных ему каналов. За запросом стоит некое намерение, интент, т.е. желание получить ответ на вопрос, получить услугу, товар или какой-либо контент, например, музыку или видео. В качестве каналов могут выступать умные устройства, ассистенты, встроенные в устройства или мобильные телефоны, привычный звонок на номер телефона, мессенджеры или вебчаты, подобные популярным в России Livetex, Jivosite или Webim.
Далее, может потребоваться дополнительная обработка или конвертация формата сообщения. Диалоговые платформы всегда работают с текстом, в то время как ряд каналов предполагают голосовое общение. За эту конвертацию отвечают платформы ASR (распознавание речи), TTS (синтез речи), системы интеграции с телефонией. В некоторых случаях может быть необходимо узнавать собеседника по голосу – в этом случае используются платформы биометрии. Отдельные каналы, например, мессенджеры или ассистент Алиса в мобильном телефоне, позволяют совмещать визуальные интерактивные элементы (например, кнопки или карточки товаров, на которые можно тапнуть) и естественный язык. Для работы с ними необходима интеграция с соответствующими API.
Запрос, преобразованный в текст, поступает в диалоговую платформу. Ее задача – понять смысл сказанного, уловить пользовательский интент и эффективно обработать его, отдав результат. Для этого диалоговые платформы используют множество технологий, таких как нормализация текста, морфологический анализ, анализ семантической близости сказанного, ранжирование гипотез, выделение именованных сущностей и, наконец, формирование запросов уже на машинном языке, через совокупность API к внешним базам данных и информационным системам. Примером таких внешних систем может быть 1С, Битрикс24, SAP, CRM системы, базы контента или сервисы, наподобие Deezer или Google Play Music. Получив данные, диалоговая платформа генерирует ответ – текст, голосовое сообщение (с помощью TTS), включает стриминг контента или уведомляет о совершенном действии (например, размещении заказа в электронном магазине). Если в первоначальном запросе данных для принятия решений по дальнейшему действию недостаточно, платформа NLU инициирует уточняющий диалог, чтобы получить все недостающие параметры и снять неопределенность.
Как устроена логика обработки запросов в диалоговых платформах (на примере Just AI)?
Здесь мы хотим немного рассказать о внутреннем устройстве систем, обрабатывающих запросы пользователей в диалоговых системах.
Рассмотрим процесс обработки мы на примере нашей платформы, но надо отметить, что на верхнем уровне основные черты одинаковы если не во всех, то по крайней мере в известных нам платформах (здесь мы имеем ввиду платформы для бизнес-скилов, а не «болталку»). Общую схему работы нашей платформы можно представить так:

Основной цикл обработки запроса клиента состоит из следующих событий и действий:
- Система получает запрос клиента в модуль управления диалогом — DialogManager.
- DialogManager загружает контекст диалога из базы данных.
- Запрос клиента (вместе с контекстом) отправляется на обработку в NLU-модуль, в результате чего определяется интент (намерение) клиента и его параметры. В случае обработки не текстовых событий (кнопки и т.п.) этот шаг пропускается.
- На основе сценария диалога и извлечённых данных, DialogManager определяет следующее наиболее подходящее состояние (блок, экран, страницу диалога), наиболее полно соответствующее высказыванию клиента.
- Выполнение бизнес-логики (скриптов) в соответствии с заданным сценарием чат-бота.
- Вызов внешних инфосистем, если таковые запрограммированы в бизнес-логике.
- Генерация текстового ответа с использованием макроподстановок и функций согласования слов на естественном языке.
- Сохранение контекста и параметров диалога в Dialog State DB для обработки последующих обращений
- Отправка ответа клиенту.
Важной частью процесса работы системы является управление ходом диалога (DialogManager), в рамках которого определяется общий контекст сказанного и связь с предыдущими и последующими высказываниями. Благодаря этому процессу та или иная фраза будет восприниматься по-разному, в зависимости от того, в какой момент она сказана, кто ее сказал, какие дополнительные данные были переданы в систему вместе с запросом (например, местоположение пользователя). В некоторых системах DialogManager так же управляет наполнением контекста фразы необходимыми данными (slot filling), которые могут быть получены либо из фразы клиента, либо из контекста предыдущих фраз, либо явно запрошены у клиента. В нашей же системе эти функции вынесены на уровень «сценария» диалога таким образом, чтобы этот процесс был полностью контролируемым разработчиком бота.
Наиболее сложным этапом работы диалоговой платформы является процесс разбора высказывания клиента. Данный процесс называется NLU — Natural Language Understanding, понимание смысла запроса.
В самом упрощённом виде, процесс «понимания» языка состоит из следующих крупных этапов:
- Предварительная обработка текста,
- Классификация запроса, соотнесение с одним из классов, известных системе,
- Извлечение параметров запроса.
И именно в этом месте, наверное, кроются наиболее значительные различия в платформах различных поставщиков. Кто-то использует глубокие нейронные сети, кому-то хватает регулярных выражений или формальных грамматик, кто-то полагается на сторонние сервисы.
Архитектура нашей системы предполагает следующий подход к обработке запроса на естественном языке:
- Разбиение текста на слова.
- Исправление опечаток (при этом сохраняются оба варианта текста).
- Пополнение текста морфологическими признаками – определение нормальной формы (леммы) слов и частей речи (граммем).
- Расширение запроса с помощью словарей синонимов.
- Расширение запроса информацией об «информационной значимости» (весов) отдельных слов.
- Расширение запроса деревом синтаксического разбора.
- Расширение запроса результатами разрешения кореферентности (разрешение местоимений).
- Определение именованных сущностей.
- Классификация запроса с помощью двух подходов (могут быть использованы параллельно): a. на основе примеров фраз и алгоритмов на базе машинного обучения; b. на основе формальных правил (шаблонов).
- Ранжирование гипотез классификации в соответствии с текущим контекстом беседы.
- Заполнение информационных «слотов» — параметров запроса, переданных во фразе пользователя.
Более подробный рассказ о работе модуля NLU — это тема отдельной статьи, которую мы планируем подготовить в ближайшем будущем.
Что должна включать в себя диалоговая платформа?
Современная комплексная диалоговая платформа или, как их еще называют, Conversational Platform, должна включать в себя множество функций и технологических модулей. Схематично их можно показать так:
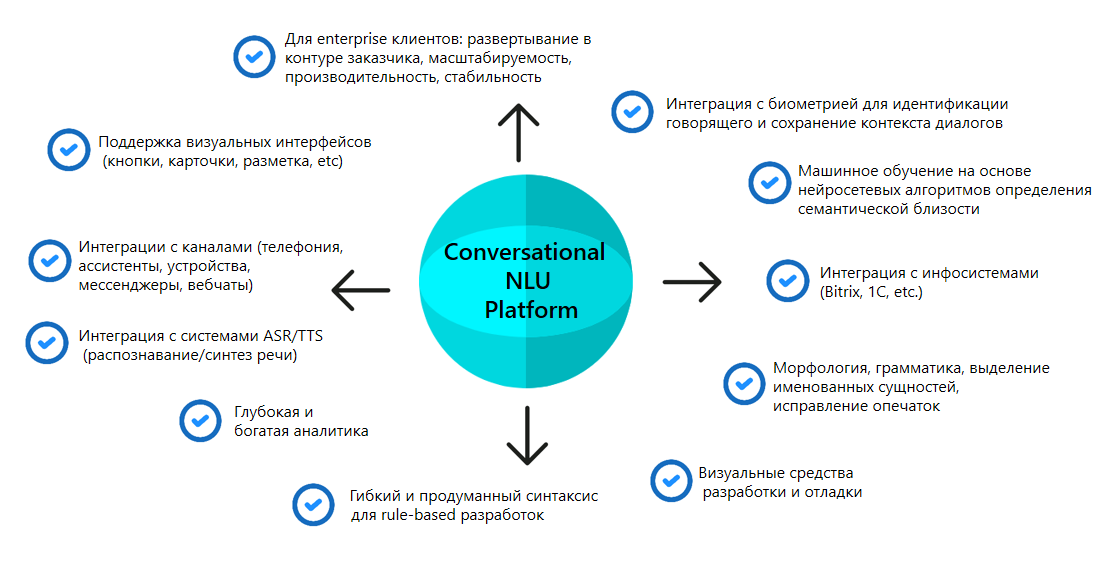
Чем больше у платформы интеграций, тем быстрее и проще можно создать на ее базе готовый скил. Наличие развитого rule-based синтаксиса может ускорить разработку чатботов в разы. Кроме того, отдельные задачи управления диалогом вообще не реализуемы без формальных правил. Наличие систем классификации и машинного обучения позволяет ускорить создание чатботов на порядки, проанализировав, скажем, огромное количество записей логов за короткое время. Интеграция всего этого в единую систему позволяет комбинировать разные методы в рамках разработки одного проекта, в зависимости от его целей.
Визуальные инструменты конструирования скилов помогают ускорять их создание, упрощать отладку и визуализировать дальнейший поток общения пользователей с системой. Анализ эмоций, богатая и глубокая аналитика, специальные фильтры (например, на использование ненормативной лексики), языковая поддержка, хранение контекста, как и собственно, точность работы используемых нейросетевых алгоритмов, а также производительность, масштабируемость и стабильность – все это также важные, хотя и не всегда очевидные со стороны, особенности диалоговых платформ.
И, несмотря на большое количество компаний, создающих чатботов, единицы имеют полнофункциональные системы NLU и далеко не все существующие системы одинаково подходят для разных задач и языков. На рынке существуют широко известные Lex от Amazon, Microsoft Bot Framework, IBM Watson, Wit.ai от Facebook, но не все они представлены на русском языке или же имеют недостаточно эффективные алгоритмы для русского языка.
Кто участвует в создании технологий NLU в России и на международном рынке?
Теперь интересно посмотреть, кто занимается NLU-технологиями на международном и российском рынках. В приведенную ниже схему включены основные разработчики и решения, приведены ключевые игроки международного рынка, не работающие с русским языком, но достаточно значимые, чтобы их упомянуть. Отдельно отмечены российские или международные компании, которые имеют продукты с адаптацией к российскому рынку и имеющие поддержку русского языка на уровне платформ.

Отдельные компании фокусируются на каналах и интерфейсах доступа пользователя, с точки зрения value-chain они находятся ближе всего к потребителю и обычно имеют своих ассистентов или устройства. В России наиболее значимым каналом является Яндекс с его ассистентом «Алиса». Есть целая группа компаний, которые создают разговорные решения для конечных компаний, поставщиков контента, товаров или услуг, т.е. разрабатывают те самые навыки (скилы) для ассистентов. Среди них есть специализированные компании, а есть интеграторы или разработчики, создающие подобные решения наряду с другими проектами. Все они пользуются теми или иными диалоговыми платформами либо решениями, связанными с сопутствующими технологиями (синтез, распознавание речи), создаваемых либо специализированными командами разработчиков подобного ПО, либо глобальными корпорациями (Microsoft, IBM, Amazon). Ну и конечно, на рынке присутствуют отдельные игроки, фокусирующиеся на отдельных, специфичных областях – например, чатботы для HR, компании, собирающие статистику или консалтинговые компании в этой области. В настоящее время рынок достаточно быстро растет и от месяц к месяцу на нем появляется все больше и больше игроков.
Мы стараемся отслеживать появление новых участников и технологий в этой области и собираемся регулярно обновлять и дополнять новыми участниками и категориями приведенную карту рынка. Кроме того, мы подготовим обзор диалоговых платформ и опишем наши собственные кейсы создания разговорных скилов. Отдельный интерес представляет также сравнение различных алгоритмов определения семантической близости в применении к разным предметным областям и технологии обучения разговорных систем. Всему этому мы и хотим посвятить блог команды Just AI на Хабре.
Телеграм: t.me/ainewsline
Источник: habr.com