Ежедневно десятки тысяч людей выполняют задания в Толоке: оценивают релевантность сайтов, классифицируют изображения, отмечают объекты на фотографиях. Решая эти и многие другие задачи, они помогают нам улучшать существующие и создавать новые алгоритмы, а также поддерживать актуальность данных.
С одной стороны, Толока появилась сравнительно недавно — в 2014 году. С другой, она служит важнейшей частью всех ключевых сервисов Яндекса и десятков сервисов поменьше. Артём Григорьев ortemij объяснил, как эта краудсорсинговая платформа устроена, какие технологии и архитектурные решения применяются при её разработке. Кроме того, Артём рассказал про логику раздачи заданий пользователям, работу с геоданными на карте и управление качеством.
— Пару слов обо мне. Я более семи лет работаю в петербургском офисе Яндекса. Когда я только пришел сюда, я занимался различными инструментами для оценки качества поиска. Мы разрабатывали разные метрики, сравнивали себя с конкурентами и разными версиями других поисковых систем. Сейчас я руковожу службой с длинным названием, как на слайде. Вкратце, мы работаем по трем основным направлениям. Во-первых, занимаемся разработкой нашей краудсорсинговой платформы Яндекс.Толока. Во-вторых, разрабатываем разнообразные сервисы для асессоров. Это специальные люди в Яндексе типа модераторов. Специалисты поддержки, для них делаем разные сервисы, контент-менеджеры и т. д. И наконец, мы разрабатываем инфраструктуру, которая позволяет всем командам Яндекса работать с перечисленными людьми и результатами их работы. Эта инфраструктура связывает то, что мы делаем и чем занимаются люди, например, при разработке поиска.
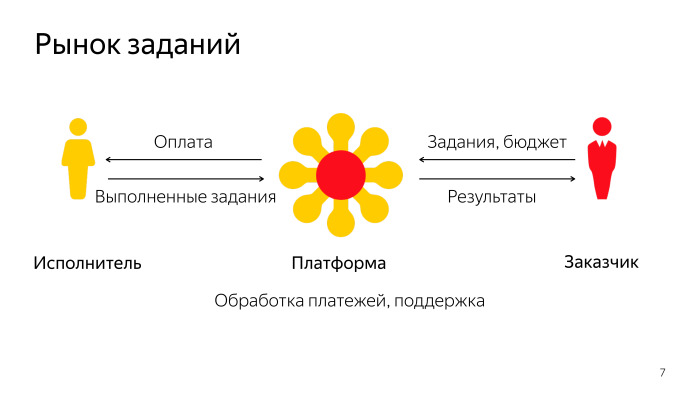
Доклад будет про нашу краудсорсинговую платформу. Вначале хочется пояснить понятие краудсорсинга. Не путайте с разработкой на аутсорсе или сбором денег через краудфандинг, это немножко другое. Давайте представим, что вы занимаетесь machine learning. Например, вы хотите обучить какой-то классификатор, и у вас есть набор данных, который нужно разметить и получить какие-то знания. Этот набор данных можно представить в виде некоторого количества задач, написать инструкцию, по которой задания можно выполнить, и отправить некоторым людям, которые это сделают. Суть краудсорсинга в том, чтобы разбивать вашу работу на некоторые отдельные задачи, отправлять это облаку исполнителей, а потом забирать оттуда результат. В мире существует несколько различных краудсорсинговых платформ, и одну из них разрабатываем мы. Второй вопрос. Поясню термин Толока?. Многие могут сказать, что я неправильно это слово произношу. По-русски ударение ставят на второй слог, но мы отдаем дань тому, что этот сервис начали делать изначально в нашем белорусском офисе, многие ребята приехали поотвечать на ваши вопросы в кулуарах. Когда мы начинали делать этот сервис и придумывали название, то вспомнили, что есть такое интересное понятие. Значение этого слова — в том, что мы перенесемся в древние времена. Люди в деревне собираются вместе и что-то делают на благо общества. Каждый по отдельности, может, эту работу сделать не смог бы, но они вместе собрались, пошли собирать урожай или строить какой-то сарай для общественных нужд. Толока — это некоторый обычай собираться вместе и помогать друг другу. Мы подумали, что это схоже с современным термином краудсорсинга, поэтому такое название для нашего сервиса и выбрали. В целом Толока и другие краудсорсинговые платформы работают по простому принципу: они соединяют между собой заказчиков и исполнителей. Платформы задания обеспечивают некоторый бюджет на их выполнение, а исполнители, выполняя задания, зарабатывают деньги и отправляют заказчикам результат. Платформа занимается тем, что она процессит все платежи, все взаимодействе между заказчиком и исполнителем, разрешает различные конфликтные ситуации и т. д. Нашей платформой пользуются, без малого, все сервисы Яндекса. Она очень популярна.
Могу привести несколько примеров заданий, которые реально сейчас в платформе размещаются. Например, задания на простую классификацию фотографий. Или задания для обучения беспилотных автомобилей. Может, видели видео, где машина Яндекса едет по Хамовникам в Москве, разметку для того, чтобы обучать компьютерное зрение в этом автомобиле, собирали в том числе в Толоке. Задания для распознавания цен на фотографиях и т. д. В принципе, базово понятно, гуманитарную вводную часть на этом заканчиваю. Если кому-то интересно поподробнее про краудсорсинг узнать, я осенью выступал на конференции SmartData, в Youtube можно найти видео с таким названием, там более подробно рассказывается о том, что такое краудсорсинг и про особенности интересные в нем. Мы здесь собрались, чтобы узнать внутренние, технические особенности работы нашей платформы, поэтому перейдем к этой части.
Толока доступна в нескольких формах. Можно зайти в браузере на сайт toloka.yandex.ru, выполнять задания там. Также у нас есть мобильные приложения под iOS и под Android. Они используются, в частности, для различных заданий, где требуется мобильность, люди ходят по местности и выполняют задания «в полях», ну и где нужны специальные фичи телефона, например, диктофон или камера. Наш бэкенд написан в основном на Java. Мы используем активно SpringBoot и всевозможные его составляющие. И в итоге Толока представлена в виде набора микросервисов, каждый из которых разворачивается в виде Docker-контейнере в нашей облачной системе. Мы деплоимся в наше внутреннее облако. В качестве хранилищ мы используем несколько разных. Самая основная бизнес-логика сделана на PostgreSQL, потому что мы работаем с деньгами, нам очень важно обеспечивать транзакции между заказчиками и пользователями. Вся логика, где критична эта особенность, у нас находится в PostgreSQL. Для тех мест, где это не нужно, мы используем MongoDB. Во многих микросервисах, которые построены вокруг Толоки, используется это хранилище. Это наша внутренняя реализация MapReduce, похожа на BigTable, в Яндексе ее ласково называют Ыть. В разработке Толоки есть несколько основных направлений, в которых мы решаем свои задачи. Сама предметная область краудсорсинга и сам сервис довольно сложный, поэтому у нас довольно много задач на реализацию разнообразной бизнес-логики. Мы активно используем разнообразные технологии, используем всевозможные оптимизации, поэтому такой класс задач у нас тоже довольно большой. Наконец, предметная область довольно интересно и динамично развивается, и в мире довольно много исследований на эту тему, поэтому мы внутри тоже такими исследованиями занимаемся. Чтобы приоткрыть завесу на то, что внутри происходит, я по одной задаче из каждой области приведу, и попытаюсь рассказать что-то интересное, что происходит, на эту тему.
Начнем с бизнес-логики.
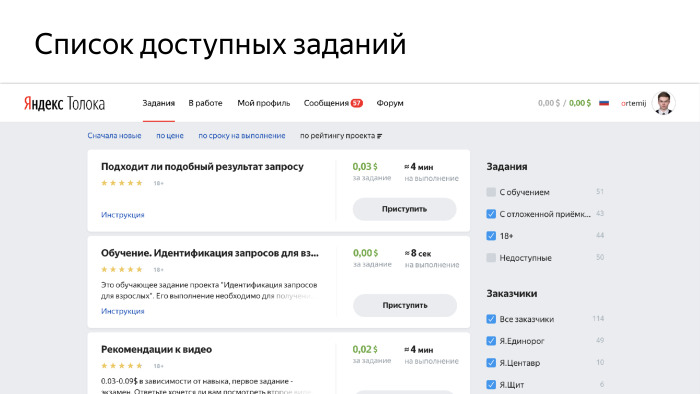
Самое важное, что есть в системе, это выбор заданий пользователями. Первое, что видит человек, который зарегистрируется в Толоке — главную страницу, на которой показан список доступных ему заданий.
Попробуем разобраться, что за этим скрывается. Страница выглядит довольно просто, но на самом деле за каждым проектом, который на экране видят пользователи, скрывается огромная очередь заданий, которые туда заливают заказчики. Заказчики обычно формируют некоторые пулы заданий, множества заданий, доступные определенному количеству исполнителей, и пачками туда эти задания загружают. У нас получается большая очередь, в которую, с одной стороны, заказчики заливают пулы и новые задачи, с другой стороны, приходят исполнители и спрашивают, какие задания мне доступны, выбирают себе интересные, и потом туда отправляют результаты. Как работает получение списка доступных заданий, главная страница Яндекс.Толоки?
Во-первых, мы ищем пулы, которые подходят исполнителям по фильтрам. Про это дальше еще расскажу, но не все задания доступны каждому, поэтому мы должны отфильтровать те, которые показать данному пользователю. После этого мы проверяем, не забанен ли на данном проекте пользователь. В системе те исполнители, которые не очень хорошо справляются с заданиями, они от них отстраняются, и по разным причинам пользователь может быть забанен. Важный момент, что задания мы отдаем не по одному, а страницами, на которых показывается сразу несколько заданий, это сделано для оптимизации скорости. Мы должны найти те пулы, в которых у пользователя есть достаточно заданий, чтобы показать страницу. И важно, что мы одни и те же задания пользователю второй раз не показываем, он делает все по одному разу. Отфильтровав это все, мы группируем и показываем страницу на фронтенде, которую видит человек.
Исполнитель в нашей системе представлен несколькими характеристиками. Есть вычислимые поля, допустим, ОС, с которой заходит пользователь, можем по этому критерию пользователей отфильтровать. Или его IP-адрес, регион, вычисленный по этому IP и т. д.
Есть некоторые данные, которые пользователь ввел о себе в профиле — пол, возраст, образование. По этим срезам тоже могут заказчики фильтровать пользователей для выполнения своих заданий.
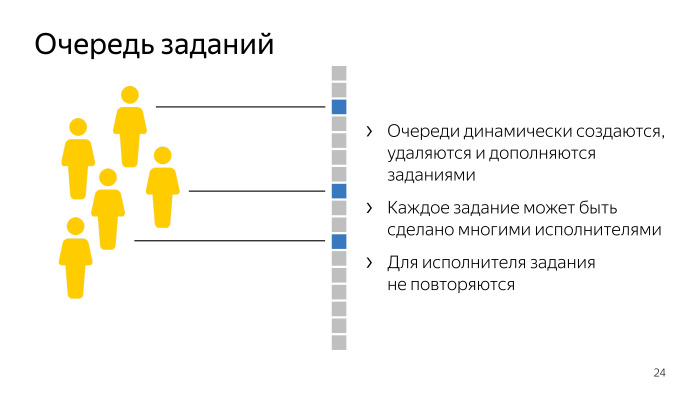
Еще одно понятие — навык. Это некая численная характеристика, которую заказчик может назначить исполнителю по итогу выполнения заданий на его проектах. Обычно она характеризует, насколько качественно человек справляется с данной задачей. Пользователь представляется в виде длинной JSON, в которой все эти характеристики записаны. С другой стороны, у нас есть некоторые пулы, где заданы фильтры. Допустим, для выполнения некоторых заданий нам нужны пользователи, которые по номеру телефона указали, что они находятся в России, Украине, Казахстане или Беларуси, и еще некоторое ограничение по навыкам. Когда пользователь заходит на страницу, мы матчим это представление фильтра на некотором псевдоязыке с JSON представлением пользователя, которое у нас есть на данный момент. Представление пользователя может меняться, и заказчик тоже может менять фильтры, настроенные на пуле. Раньше мы компилировали представление фильтров на JSquery, такой плагин для пользователя. Сейчас мы это делать перестали, потому что представление фильтра на JSquery, плагин такой для PostgreSQL. Сейчас мы это делать перестали, потому что фильтровать на самом бэкенде в памяти оказалось сильно быстрее. Мы отфильтровали пулы, и надо проверить, что в них достаточно заданий, которые пользователь еще не делал, чтобы показать ему полную страницу. И мы опять возвращаемся к очередям. Каждый пул заданий — это очередь заданий для различного количества пользователей. У нее есть некоторый набор свойств. Во-первых, эти очереди динамически создаются, удаляются, и также заказчики могут доливать в пулы новые задания, поэтому эти очереди могут дополняться новыми элементами. Во-вторых, каждое задание может быть сделано многими исполнителями. В этой очереди для каждого задания получается много разных потребителей. И для исполнителей задания повторяться не должны, мы не должны два раза платить человеку за то, что он делает. Все эти ограничения вкупе с тем, что таких очередей может быть десятки тысяч, выкладываются в то, чтобы отрисовать главную страницу, которую спрашивают у нас примерно 150 раз в секунду, нам нужно сделать около 40 тыс. проверок того, что в данной очереди, в данном пуле заданий есть доступные для пользователя. Это тяжелое место, и мы его соптимизировали следующим образом — мы перенесли все эти проверки в базу данных.
Использовали такую штуку в PostgreSQL, называется lateral join, он позволяет для каждого элемента из левой таблицы выполнить запрос в цикле по одному разу. Получается, вместо того, чтобы джоинить огромные таблицы, мы делаем простую выборку и повторяем эту проверку на бэкенде базы каждый раз. Запросы, которые находятся внутри, довольно легкие, от этого получается, что вместо 40 тыс. проверок мы делаем на порядки меньше, они все унесены в базу, из бэкенда мы туда в цикле не ходим. Отфильтровали, поняли, какие пулы доступны пользователю. Представим, что он на кнопку «Приступить» нажимает. В этот момент мы должны зарезервировать ему некоторое задание, страницу, которую он будет видеть, и за выполнение которой потом получит деньги. Снова проверяем, что этот пул, в котором данное задание находится, все еще доступен пользователю. После этого ищем уже готовую страницу. Если где-то есть подготовленная, которую пользователь еще не делал, мы ему ее отдаем. Если такой страницы нет, мы ее подготавливаем заново, мы берем из нескольких источников задания, смешиваем друг с другом и отображаем на экране для пользователя.
В этот же момент мы производим финансовую операцию. Мы берем деньги со счета заказчика и резервируем их на выполнение этого задания.
Если пользователь в конечном итоге задания выполнит, все будет хорошо, эти деньги переведутся ему на счет. Если он от задания откажется или по каким-то причинам оно будет отклонено, деньги вернутся на счет заказчика.
Это все происходит в транзакции, именно по причине того, что мы работаем здесь с деньгами, и нам очень важно ничего лишнего не потратить, не выдать одно и то же два раза разным людям, если это не надо, и т. д.
И это накладывает такую сложность на и так не очень простую бизнес-логику.
Представьте, что многие пользователи видят одни и те же задания, и пытаются одновременно к ним приступить. Получается, эти люди конкурируют примерно за одни и те же задачи. Важно, чтобы они друг друга не перелочили в базе. Здесь полезна такая штука, которая позволяет заблокированные строки пропускать при селекте.
Перейдем к части про технологии. Я много говорил, что мы сильно используем PostgreSQL. Хочется рассказать, как мы пришли к тому, что начали использовать реплики, и какой был к этому тернистый путь. Практически любое приложение, которое использует БД, обычно начинает с того, что все запросы идут на мастер, реплики используются для отказоустойчивости. И на бэкенде используется некий пул соединений, который позволяет эти соединения переиспользовать. Сервисом пользуются, нагрузка на него начинает расти. Вы увеличиваете размер этого пула соединений. Потом начинаете смотреть, что на мастере начинает кончаться CPU, начинаете оптимизировать ваши запросы, смотреть, какие там долгие транзакции, почему соединения выделяются лишний раз. Так же поступали и мы. В какой-то момент добавили pgbouncer, который позволяет иметь заготовленный пул соединений и не тратить процессор на то, чтобы выделять новые. По-всякому крутили клиентские настройки, перешли на быстро работающий пул соединений hikari-cp. В конечном итоге получалось так, что все эти наши оптимизации не приводили к нужному эффекту, и нагрузка, и те фичи, которые мы постоянно добавляли, превосходили нас, поэтому в какой-то прекрасный момент мы пришли к выводу, что пришла пора читать с реплик. Тоже понятная простая задача, давайте добавим еще несколько датасорсов, будем на них направлять те транзакции, которые только данные читают, read only, и попробуем найти способ определять эти read only транзакции. В Java есть метод с длинным названием, который должен позволять это определять в момент выполнения транзакций. Но есть некоторые особенности, например, при использовании автоматически сгенерированных запросов Spring JPA он у нас не работал. Тогда мы нашли эти места и обернули во вспомогательный метод, мы форсируем чтение с реплик в этих местах, давайте так поступать, все будет хорошо. Но тут можно найти логическую проблему. Она в том, что довольно много мест в коде, где вы сначала какую-то сущность создаете, а потом ее читаете, начинаете с ней работать, и это происходит в разных транзакциях. Получается, что сущность, созданная на мастере, до реплики еще не успела доехать. И код, который работает дальше, ничего не прочитывал.
Или другой момент. Пользователь в UI, заказчик, создал новый пул заданий, его страничка отрисовывается, а его на самом деле нет, потому что создавался он на мастере, а чтение пошло с реплик. Такие места мы отловили различными автоматическими тестами, и первое, что нам пришло в голову, давайте захачим и начнем форсированно читать все с мастера.
Синонимичный метод создали, все нашли, поправили и поняли, что мы в интересной ситуации, потому что мы боролись за то, чтобы чтение перенести на реплики, а мы взяли и практически все сложные места все равно читаем с мастера, ничего полезного не произошло.
Есть еще способ в PostgreSQL, есть флажок remote_apply, он говорит о том, что нам нужно эту транзакцию закоммитить еще на реплики. Она не будет закоммичена до тех пор, пока не пройдет на мастере и на реплике.
По идее можно было его использовать, но особенность в том, что она работает только для синхронных реплик. С асинхронными репликами этот флаг не действует, а держать кучу синхронных реплик накладно, сильно замедляется запись, мы это делать не хотели.
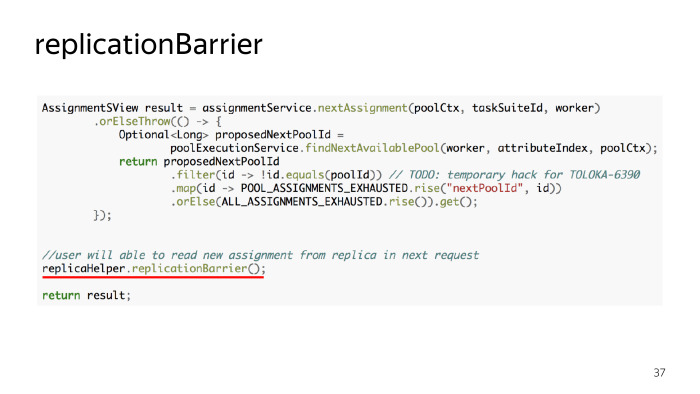
А хотели примерно такого. Здесь тоже представлен кусочек кода. Мы хотели сделать некоторый вспомогательный метод, назвали его replicationBarrier, суть его в том, что в тех местах, где нам обязательно надо дождаться, что данные доехали до реплик, мы вставляем эту строчку кода, и приложение не выйдет из этого метода до тех пор, пока данные, созданные в транзакциях до этого места в этом потоке, не доедут до реплик. Кажется удобный и простой метод. Давайте подумаем, как его можно реализовать. В 11-м PostgreSQL — сейчас в продакшен внедряют 10-й — будет специальная команда WAIT FOR LSN, где LSN — lock sequence numbers. И мы можем прочитать, в какой позиции мы в логе находимся, и подождать, когда эта позиция будет достигнута на реплике. Пока 11-го PostgreSQL нет, этим пользоваться не можем. Еще вариант — вспомогательная вьюха в PostgreSQL, pg_stat_replication, в ней есть всякая диагностическая информация на тему того, как у нас работают реплики. В момент, когда мы транзакции провели, давайте замерять, на какой позиции в логе мы находимся, и потом через replay_location в этой таблице на каждой реплике проверять, где мы есть. И если мы находимся в позиции, которая нам нужна, или позже, то мы будем выходить из этого барьера. Реализовали, на тестовых окружениях все было хорошо, на продакшене под более высокой нагрузкой это не заработало, были моменты, когда реплики почему-то были рассинхронизированы. Мы подумали, что наверное, мы используем не совсем по назначению диагностическую таблицу, и глубже копать не стали, потому что в голову пришла другая мысль. Мы придумали так называемый replication_counter.
Завели специальную таблицу, в ней у каждого бэкенда есть строчка, где хранится счетчик. Мы увеличиваем этот счетчик в момент, когда заходим в барьер, и ждем, пока все реплики вернут значение не меньше того, который мы только что заинкрементили. И для того, чтобы получать значение с реплик, у нас есть отдельный процесс. Помимо того, что он получает значение счетчика, он еще следит за живостью реплик. Реплики могут по тем или иным причинам отваливаться, на короткие моменты времени плохо работать, и он еще мониторингом доступности занимается.
Понятно, тут еще можно сделать оптимизации. Если несколько потоков одновременно пришли ожидать этот счетчик, запрашивать его только один раз, и если у нас происходит одновременно из разных потоков увеличение этого счетчика, тоже делать это увеличение только однажды.
В итоге наша база сейчас по объему занимает где-то 2 ТБ, у нас есть мастер, есть три реплики, на каждом из серверов по 32 ядра. Примерно 1,5 тыс. запросов в секунду выполняется на мастере. Это практически только запросы на создание или изменение каких-то данных. И 10 тыс. запросов на каждой из реплик, это запросы на чтение. В replication_counter таблицу мы обращаемся где-то 200 раз в секунду за тем, чтобы получить значение счетчика, а увеличиваем его около 80 раз. Ну и медиана ожидания барьера примерно равна времени ping до реплики — очень быстро.
С технической частью все, теперь про исследования. И здесь хочется рассказать про самую главную проблему в краудсорсинге — проблему качества данных.
Можете представить, что есть система, где платят деньги за выполнение каких-то заданий. Куча людей хотят как-то считить, получить это недобросовестным образом. Есть люди, которые пытаются случайно все прокликать, чтобы заработать побольше. Есть какие-то более продвинутые, которые пишут различные скрипты, которые пытаются автоматически эти деньги с нас намайнить.
Проблема контроля качества в платном краудсорсинге одна из самых важных, и мы довольно много исследований посвящаем этой теме.
Чтобы контролировать качество, существует несколько методов. Самый известный способ ловить роботов — это, конечно, капча. Мы ей тоже пользуемся. Иногда, когда мы подозреваем исполнителя в том, что он может быть роботом, показываем ему капчу, и если он несколько раз не справляется с ней, мы его в системе баним. Также можно использовать различные эвристики по скорости выполнения заданий. Если задания выполняются настолько быстро, что исполнитель вообще не думает, как это выполнить качественно, или это бот, в который забыли вставить таймаут между сабмитом заданий, то мы тоже можем считать данного исполнителя подозрительным. Или если ответы идут одинаковые, тоже довольно простой паттерн — сидеть и одну и ту же кнопку все время нажимать, так тоже обычно поступают читеры. Есть более сложные способы. Например, ханипоты, это, на которые мы заранее знаем ответы, но визуально они никак не отличаются от настоящих. И когда мы страницу заданий показываем исполнителю, в ней в некоторых местах есть ханипоты. Они все примерно одинаково выглядят, но на серверной стороне мы уже можем проверить, сравнить ответ пользователя и ответ, который мы считаем правильным. И если исполнитель часто ошибается, это тоже подозрительно. Либо он некачественно делает задания, либо это вариант бота.
Еще в краудсорсинге одни и те же задания часто специально выдают нескольким исполнителям. Это нам позволяет нам сравнивать их ответы между собой. И тех, кто отвечает часто не так, как остальные, мы тоже подозреваем в какой-то недобросовестности выполнения заданий.
Эти способы в платформе Толоки доступны из коробки. Мы постоянно внедряем новые способы контроля качества, которые будут доступны заказчикам.
Я упомянул, что одни и те же задания часто делают несколько исполнителей, и возникает интересная задача — задача агрегации ответов. Обычно, чтобы потом эти данные использовать — например, для обучения классификатора, — нам нужно по каждому входному элементу иметь итоговый вердикт. Нам неинтересно иметь пять разных мнений. И самой простой моделью агрегации является модель majority vote — надеюсь, так у нас выборы работают. Берем тот результат, за который проголосовало большее количество исполнителей.
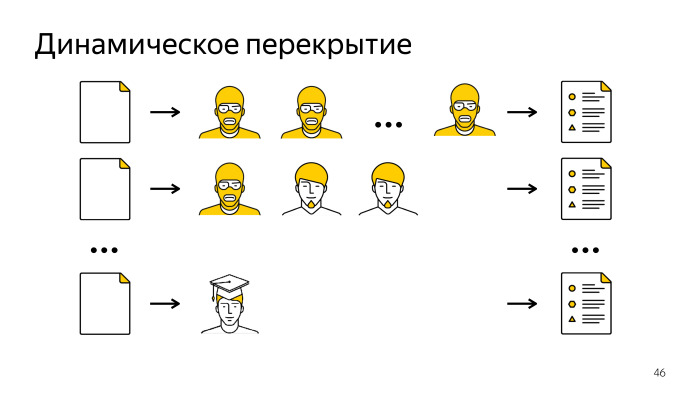
Но есть модели и более сложные, которые используют различные характеристики заданий и исполнителей, вероятностные модели, которые строят в процессе своей работы разные предсказания о качестве работы людей. Мы провели исследования, сравнили много разных моделей, и за счет выбора правильной модели под конкретную задачу для итоговой агрегации данных можно выиграть в качестве до 15 процентных пунктов. Просто за счет того, что мы ответы исполнителей правильным образом сагрегировали. Поверьте, это очень много. Перекрытия тоже не всегда можно использовать полностью. На картинке представлено, что к нам пришли исполнители-анонимы, мы про них ничего не знаем, а есть те, кто работает на нашем задании давно. У нас про них накоплена какая-то статистика. Или вообще у нас, может, есть мегаэксперт, одного ответа которого будет достаточно, чтобы итоговое решение принять. И за счет того, что мы при раздаче заданий не всегда отдаем это, например, пяти исполнителям, а используем динамическое перекрытие, мы можем выигрывать в экономии денег. За счет динамического перекрытия можно экономить до 40% бюджета без снижения в качестве. Я продемонстрировал три разных направления разработки в Толоке. Может, что-то из этого будет полезно вам в ваших проектах. Может, кто-то из вас занимается ML или Data Science и захочет попробовать Толоку для своих задач. Напомню, она открыта для любых заказчиков, у нее есть API, можно заливать туда свои задания и собирать данные для себя. У нас много интересных задач — может, кто-то захочет с ними помочь. Спасибо, на этом все.