Интеллектуальные системы поддержки принятия решений — краткий обзор
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-05-28 13:58

Дисклеймер
Целью написания этой статьи было сделать краткий обзор принципов построения Интеллектуальных Систем Поддержки Принятия Решений (ИСППР), роли машинного обучения, теории игр, классического моделирования и примеров их использования в СППР. Целью статьи не является забуриться вглубь тяжелой теории автоматов, самообучаемых машин, равно как и инструментов BI.
Введение
Существет несколько определений ИСППР, которые, в общем-то, крутятся вокруг одного и того же функционала. В общем виде, ИСППР — это такая система, которая ассистирует ЛПР (Лицам, Принимающим Решения) в принятии этих самых решений, используя инструментарии дата майнинга, моделирования и визуализации, обладает дружелюбным (G)UI, устойчива по качеству, интерактивна и гибка по настройкам.
Зачем нужны СППР:
- Сложность в принятии решений
- Необходимость в точной оценке различных альтернатив
- Необходимость предсказательного функционала
- Необходимость мультипотокового входа (для принятия решения нужны выводы на основе данных, экспертные оценки, известные ограничения и т.п.)
С начала 80-х уже можно говорить о формировании подклассов СППР, таких как MIS (Management Information System), EIS (Executive Information System), GDSS (Group Decision Support Systems), ODSS (Organization Decision Support Systems) и др. По сути, эти системы представляли собой фреймворки, спососбные работать с данными на различных уровнях иерархии (от индивидуального до общеорганизационного), а внутрь можно было внедрить какую угодно логику. Примером может служить разработанная Texas Instruments для United Airlines система GADS (Gate Assignment Display System), которая поодерживала принятие решений в Field Operations — назначение гейтов, определение оптимального времени стоянки и т.п.
В конце 80-х появились ПСППР (Продвинутые — Advanced), которые позволяли осуществлять «what-if» анализ и использовали более продвинутый инструментарий для моделирования.
Наконец, с середины 90-х на свет стали появляться и ИСППР, в основе которых стали лежать инструменты статистики и машинного обучения, теории игр и прочего сложного моделирования.
Многообразие СППР
На данных момент существует несколько способов классификации СППР, опишем 3 популярных:
По области применения
- Бизнес и менеджмент (прайсинг, рабочая сила, продукты, стратегия и т.п.)
- Инжиниринг (дизайн продукта, контроль качества...)
- Финансы (кредитование и займы)
- Медицина (лекарства, виды лечения, диагностика)
- Окружающая среда
По соотношению данныемодели (методика Стивена Альтера)
- FDS (File Drawer Systems — системы предоставления доступа к нужным данным)
- DAS (Data Analysis Systems — системы для быстрого манипулирования данными)
- AIS (Analysis Information Systems — системы доступа к данным по типу необходимого решения)
- AFM(s) (Accounting & Financial models (systems) — системы рассчета финансовых последствий)
- RM(s) (Representation models (systems) — системы симуляции, AnyLogic как пример)
- OM(s) (Optimization models (systems) — системы, решающие задачи оптимизации)
- SM(s) (Suggestion models (systems) — системы построения логических выводов на основе правил)
По типу использумого инструментария
- Model Driven — в основе лежат классические модели (линейные модели, модели управления запасами, транспортные, финансовые и т.п.)
- Data Driven — на основе исторических данных
- Communication Driven — системы на оснвое группового принятия решений экспертами (системы фасилитации обмена мнениями и подсчета средних экспертных значений)
- Document Driven — по сути проиндексированное (часто — многомерное) хранилище документов
- Knowledge Driven — внезапно, на основе знаний. При чем знаний как экспертных, так и выводимых машинно
Я требую жалобную книгу! нормальную СППР
Несмотря на такое многообразие вариантов классификаций, требования и атрибуты СППР хорошо ложаться в 4 сегмента:
- Качество
- Организация
- Ограничения
- Модель
На схеме ниже покажем, какие именно требовани и в какие сегменты ложаться:

Архитектура и дизайн ИСППР
Существет несколько подходов к тому, как архитектурно представить СППР. Пожалуй, лучшее описание разности подходов — «кто во что горазд». Несмотря на разнообразие подходов, осуществляются попытки создать некую унифицированную архитектуру, хотя бы на верхнем уровне.
Действительно, СППР вполне можно разделить на 4 больших слоя:
- Интерфейс
- Моделирование
- Data Mining
- Data collection
А уж в эти слои можно напихать какие угодно инструменты.
На схеме ниже представляю мое видение архитектуры, с описанием функционала и примерами инструментов:
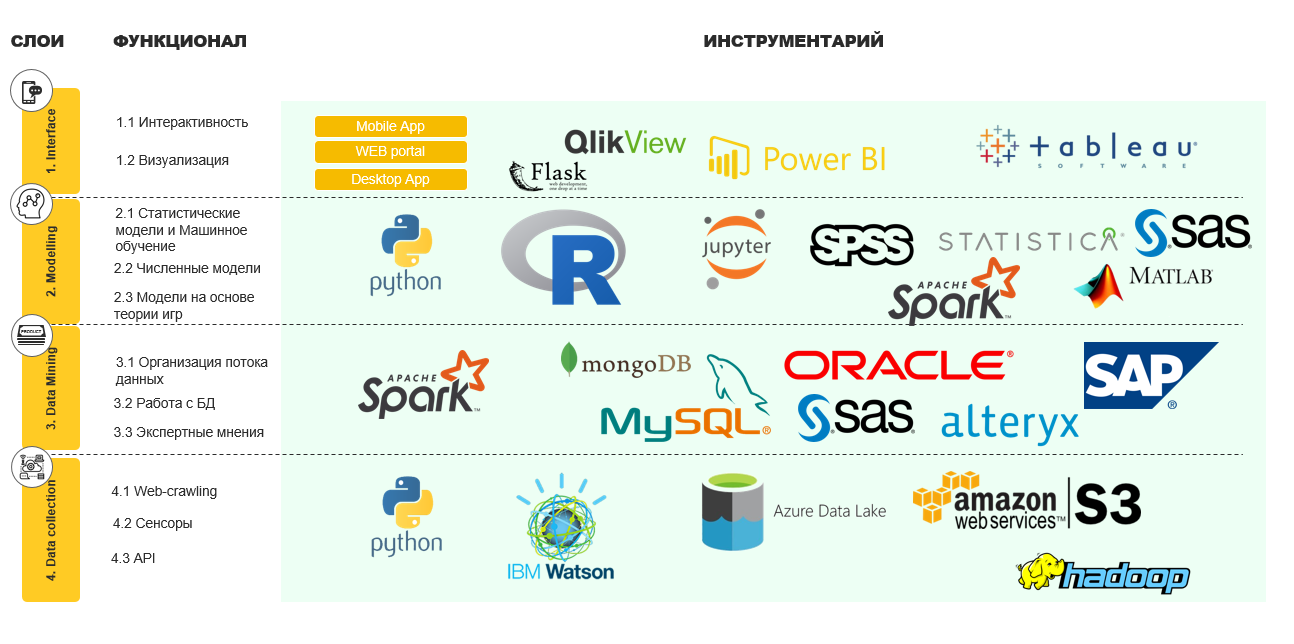
- Анализ домена (собственно, где мы будем нашу ИСППР использовать)
- Сбор данных
- Анализ данных
- Выбор моделей
- Экспертный анализинтерпретация моделей
- Внедрение моделей
- Оценка ИСППР
- Внедрение ИСППР
- Сбор обратной свзяи (на любом этапе, на самом деле)
На схеме это выглядит так:


А где тут машинное обучение и теория игр?
Да практически везде! По крайней мере в слое, связанном с моделированием.
С одной стороны, есть классические домены, назовем их «тяжелыми», вроде управления цепями поставок, производства, запасов ТМЦ и проч. В тяжелых доменах наши с вами любимые алгоритмы могут привнести дополнительные инсайты для зарекомендовавших себя классических моделей. Пример: предиктивная аналитика по выходам из строя оборудования (машинное обучение) отлично сработается с каким-нибудь FMEA анализом (классика).
С другой стороны, в «легких» доменах, вроде клиентской аналитики, предсказании churn, выплаты кредитов — алгоритмы машинного обучения будут на первых ролях. А в скоринге, например, можно совмещать классику с NLP, когда решаем выдавать ли кредит на основе пакета документов (как раз-таки document driven СППР).
Классические алгоритмы машинного обучения
Допустим, есть у нас задачка: менеджеру по продажам стальной продукции надо еще на этапе получения заявки от клиента понимать, какого качества готовая продукция поступит на склад и применить некое управляющее воздействие, если качество будет ниже требуемого.
Поступаем очень просто:
Шаг 0. Определяем целевую переменную (ну, например, содержание оксида титана в готовой продукции)
Шаг 1. Определяемся с данными (выгружаем из SAP, Access и вообще ото всюду, куда дотянемся)
Шаг 2. Собираем фичигенерим новые
Шаг 3. Рисуем процесс data flow и запускаем его в продакшн
Шаг 4. Выбираем и обучаем модельку, запускаем ее крутиться на сервере
Шаг 5. Определяем feature importances
Шаг 6. Определяемся со вводом новых данных. Пусть наш менеджер их вводит, например, руками.
Шаг 7. Пишем на коленке простой web-based интерфейс, куда менеджер вводит ручками значения важных фич, это крутится на серваке с моделькой, и в тот же интерфейс выплевываестя прогнозируемое качество продукции
Вуа-ля, ИСППР уровня детсад готова, можно пользоваться.
Подобные «простые» алгоритмы также использует IBM в своей СППР Tivoli, которая позволяет определять состояние своих супер-компьютеров (Watson в первую очередь): на основе логов выводится информация по перформансу Watson, прогнозируется доступность ресурсов, баланс cost vs profit, необходимость обслуживания и т.п.
Компания ABB предлагает своим клиентам DSS800 для анализа работы электродвигателей той же ABB на бумагоделательной линии.
Финская Vaisala, производитель сенсоров для минтранса Финляндии использует ИСППР для предсказания того, в какие периоды необходимо применять анти-обледенитель на дорогах во избежания ДТП.
Опять-таки финская Foredata предлагает ИСППР для HR, которая помогает принимать решения по годности кандидата на позицию еще на этапе отбора резюме.
В аэропорту Дубай в грузовом терминале работает СППР, которая определяет подозрительность груза. Под капотом алгоритмы на основе сопровидительных документов и вводимых сотрудниками таможни данных выделяют подозрительные грузы: фичами при этом являются страна происхождения, информация на упаковке, конкретная информация в полях декларации и т.п.
Тысячи их!
Обычные нейронные сети
Кроме простого ML, в СППР отлично ложиться и Deep Learning.
Некоторые примеры можно найти в ВПК, например в американской TACDSS (Tactical Air Combat Decision Support System). Там внутри крутятся нейронки и эволюционные алгоритмы, помогающие в определении свой-чужой, в оценке вероятности попадания при залпе в данный конкретный момент и прочие задачки.
В немного более реальном мире можно рассмотреть такой пример: в сегменте B2B необходимо определить, выдавать ли кредит организации на основе пакета документов. Это в B2C вас оператор замучает вопросами по телефону, проставит значения фич у себя в системе и озвучит решение алгоритма, в B2B несколько посложнее.
ИСППР там может строиться так: потенциальный заемщик приносит заранее согласованный пакет документов в офис (ну или по email присылает сканы, с подписями и печатями, как положено), документы скармливаются в OCR, затем передаются в NLP-алгоритм, который дальше уже делит слова на фичи и скармливает их в NN. Клиента просят попить кофе (в лучшем случае), или вот где карту оформляли туда и идите прийти после обеда, за это время как раз все и обсчитается и выведет на экран девочке-операционисту зеленый или красный смайлик. Ну или желтый, если вроде ок, но нужно больше справок богу справок.
Подобными алгоритмами пользуются также в МИД: анкета на визу + прочие справки анализируются прямо в посольстве консульстве, после чего сотруднику на экране высвечивается один из 3 смайликов: зеленый (визу выдать), желтый (есть вопросы), красный (соискатель в стоп-листе). Если вы когда-нибудь получали визу в США, то то решение, которое озвучивает вам сотрудник консульства — это именно результат работы алгоритма в совокупности с правилами, а никак не его личное субъективное мнение о вас:)
В тяжелых доменах известны также СППР на основе нейронок, определяющие места накопления буфера на производственных линиях (см, напимер, Tsadiras AK, Papadopoulos CT, O’Kelly MEJ (2013) An artificial neural network based decision support system for solving the buffer allocation problem in reliable production lines. Comput Ind Eng 66(4):1150–1162), Общие Нечеткие Нейронные Сети на основе мин-макса (GFMMNN) для кластеризации потребителей воды (Arsene CTC, Gabrys B, Al-Dabass D (2012) Decision support system for water distribution systems based on neural networks and graphs theory for leakage detection. Expert Syst Appl 39(18):13214–13224) и другие.
Вообще стоит отметить, что NN как нельзя лучше подходят для принятия решений в условиях неопределенности, т.е. условиях, в которых и живет реальный бизнес. Алгоритмы кластеризации также хорошо вписались.
Байесовские сети
Бывает иногда и так, что данные у нас неоднородны по видам появления. Приведем пример из медицины. Поступил к нам больной. Что-то мы про него знаем из анкеты (пол, возраст, вес, рост и т.п.) и анамнеза (перенесенные инфаркты, например). Назовем эти данные статическими. А что-то мы про него узнаем в процессе периодического обследования и лечения (несколько раз в день меряем температуру, состав крови и проч). Эти данные назовем динамическими. Понятно, что хорошая СППР должна уметь учитывать все эти данные и выдавать рекомендации, основываясь на всей полноте информации.
Динамические данные обновляются во времени, соответственно, паттерн работы модели будет такой: обучение-решение-обучение, что в общем похоже на работу врача: примерно определить диагноз, прокапать лекарство, посмотреть за реакцией. Таким образом, мы постоянно пребываем в состоянии неопределенности, подействует лечение или нет. И состояние пациента меняется динамически. Т.е. нам надо построить динамическую СППР, причем еще и knowledge driven.
В таких случаях нам отлично помогут Динамические Байесовские Сети (ДБС) — обобщение моделей на основе фильтров Калмана и Скрытой Марковской Модели.
Разделим данные по пациенту на статические и динамические.
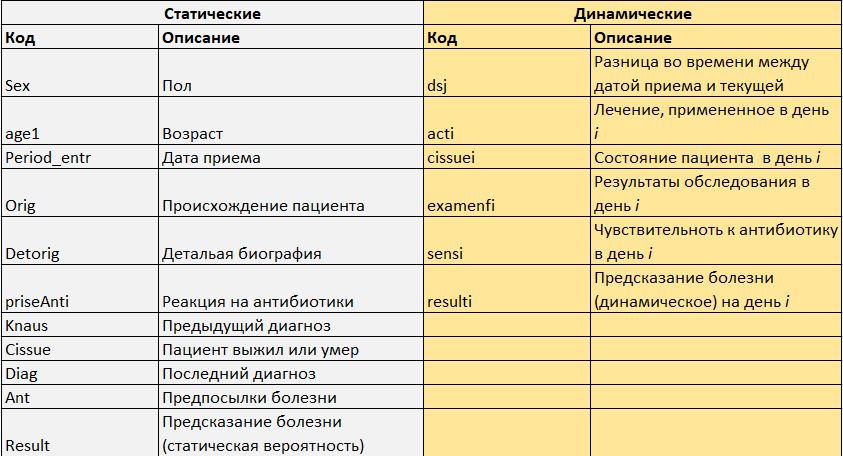
, где — узел нашей сетки (вершина графа, по сути), т.е. значение каждой переменной (пол, возраст....), а С — предсказываемый класс (болезнь).
Статическая сетка выглядит так:
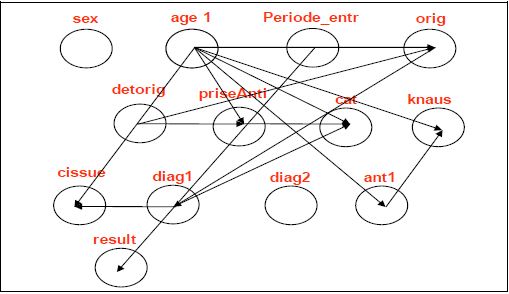
Сначала, в день приема пацитента, строим статическую сетку (как на картинке выше). Потом, в каждый день i строим сетку на основе динамически меняющихся данных:
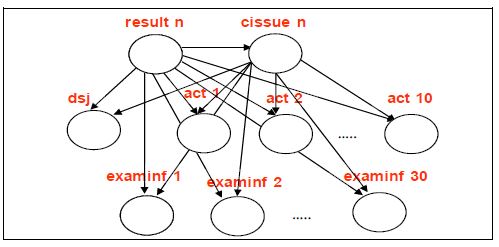
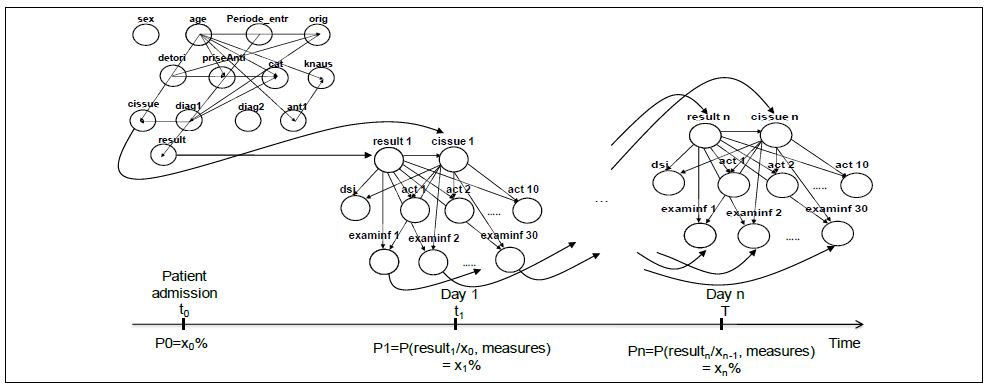
, где T — совокупное время госпитализации, N — количество переменных на каждом из шагов ДБС.
Внедрить эту модель в СППР необходимо несколько иначе — скорее тут надо идти от обратного, сначала эту модель зафиксировать, а потом строить интерфейс вокруг. Т.е., по сути, мы сделали хард модель, внутри которой динамические элементы.
Теория игр
Теория игр, в свою очередь, гораздо лучше подойдет для ИСППР, созданных для принятия стратегических решений. Приведем пример.
Допустим, на рынке существует олигополия (малое количество соперников), есть определенный лидер и это (увы) не наша компания. Нам необходимо помочь менеджменту принять решение об объемах выпускаемой нами продукции: если мы будем выпускать продукцию в объеме , а наш соперник — , уйдем мы в минус или нет? Для упрощения возьмем частный случай олигополии — дуополию (2 игрока). Пока вы думаете, RandomForest тут или CatBoost, я вам предложу использовать классику — равновесие Штакельберга. В этой модели поведение фирм описывается динамической игрой с полной совершенной информацией, при этом особенностью игры является наличие лидирующей фирмы, которая первой устанавливает объём выпуска товаров, а остальные фирмы ориентируются в своих расчетах на неё.
Для решения нашей задачи нам надо всего-то посчитать такое , при котором решиться задача оптимизации следующего вида:
Для ее решения (сюрприз-сюрприз!) надо лишь приравнять первую производную по к нулю.
При этом для такой модели нам понадобится знать только предложение на рынке и стоимость за товар от нашего конкурента, после чего построить модель и сравнить получившееся q с тем, которое хочет выкинуть на рынок наш менеджмент. Согласитесь, несколько проще и быстрее, чем пилить NN.
Для таких моделей и СППР на их основе подойдет и Excel. Конечно, если вводимые данные надо посчитать, то нужно что-то посложнее, но не сильно. Тот же Power BI справится.
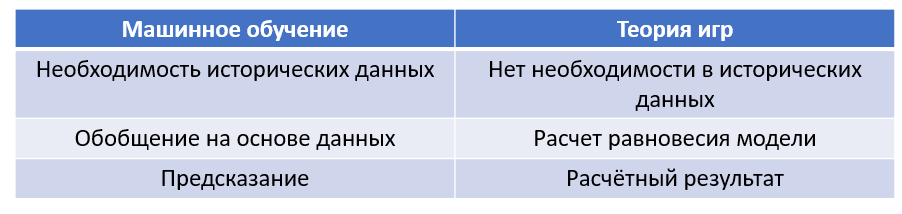
Искать победителя в битве ML vs ToG бессмысленно. Слишком разные подходы к решению задачи, со своими плюсами и минусами.
Что дальше?
С современным состоянием ИСППР вроде бы разобрались, куда идти дальше?
В недавнем интервью Джуда Перл, создатель тех самых байесовских сетей, высказал любопытное мнение. Если слегка перефразировать, то
«все, чем сейчас занимаются эксперты в машинном обучении, это подгонка кривой под данные. Подгонка нетривиальная, сложная и муторная, но все-таки подгонка.»(почитать) Скорее всего, вангую, через лет 10 мы перестанем жестко хардкодить модели, и начнем вместо этого повсеместно обучать компьютеры в создаваемых симулируемых средах. Наверное, по этому пути и пойдет реализация ИСППР — по пути AI и прочих скайнетов и WAPR'ов. Если же посмотреть на более близкую перспективу, то будущее ИСППР за гибкостью решений. Ни один из предложенных способов (классические модели, машинное обучение, DL, теория игр) не универсален с точки зрения эффективности для всех задач. В хорошей СППР должны сочетаться все эти инструменты + RPA, при этом разные модули должны использоваться под разные задачи и иметь разные интерфейсы вывода для разных пользователей. Этакий коктейль, смешанный, но ни в коем случае не взболтанный.

Литература
- Merkert, Mueller, Hubl, A Survey of the Application of Machine Learning in Decision Support Systems, University of Hoffenhaim 2015
- Tariq, Rafi,Intelligent Decision Support Systems- A Framework, India, 2011
- Sanzhez i Marre, Gibert, Evolution of Decision Support Systems, University of Catalunya, 2012
- Ltifi, Trabelsi, Ayed, Alimi, Dynamic Decision Support System Based on Bayesian Networks, University of Sfax, National School of Engineers (ENIS), 2012
Телеграм: t.me/ainewsline
Источник: habr.com