Bigdata, машинное обучение и нейросети – для руководителей
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-05-25 23:28
новости нейронных сетей, большие данные big data, алгоритмы машинного обучения
Если менеджеру попытаться разобраться в этой области и получить конкретные бизнес-ответы, то, скорее всего, страшно заболит голова и екнет сердце от ощущения ежеминутно упускаемой выгоды.
"AlphaGo обыграл чемпиона по Go" впервые за всю историю человечества, скоро наши улицы заполонят беспилотные автомобили, распознавание лиц и голоса теперь в порядке вещей, а в квартиру к нам завтра постучатся AI-секс-куклы с грудью наивысшего размера с шампанским под мышкой и настраиваемым уровнем интенсивности и продолжительности оргазма.
Все оно так, но что делать-то прямо сейчас. Как на этом заработать в краткосрочной перспективе? Как заложить прочный фундамент на будущее?
Постараюсь дать исчерпывающие ответы на все мучающие вас вопросы, «вскрыть» подводные камни и, главное — здраво оценить риски в AI и научиться ими правильно управлять. Ведь то, что не понимаем, то и не “танцуем”.
Много «мути» и сложных слов
Это, пожалуй, самое страшное – когда бизнесмен «попадает на науку».
Если у человека от квадратного уравнения в школе до сих пор болит голова и подергивается правое ухо на левой ноге, то от слова «перцептрон» может вообще произойти потеря сознания и неконтролируемое мочеиспускание.
Поэтому дальше – говорим только понятными словами. Чтобы было легче – представим, что мы сидим в баньке, пьем пиво и рассуждаем человеческим языком.

«Умные» коробочки с очень высокими амбициями
Как проще всего понять принципы применения моделей машинного обучения в бизнесе? Представьте себе робота, или «умную» коробочку с претензией на решение сложнейших задач.
Решать такие задачи в лоб — нереально. Машине нужно буквально прописать миллионы правил и исключений – поэтому так никто не делает.
Делают иначе – «умные» коробочки обучают на данных, например о ваших клиентах. А если BigData у вас уже есть, то «умная» коробочка потенциально может стать еще «умнее» — опережая «коробочки» конкурентов или обычных сотрудников не только по скорости, но и по качеству решений.
Итого, делаем глоток пива и запоминаем – чем больше данных вы сможете достать, тем более «умной» станет ваша робо-коробочка.

Сколько нужно данных?
Комично, но у человечества до сих пор нет точного ответа на этот вопрос. Но зато известно, что чем больше «качественных» данных— тем лучше.
И только нейросети, как правило, лучше других известных сейчас способов, могут качественно вытащить информацию из этих данных.
На пальцах — принято считать, что различные алгоритмы НЕ на нейросетях способны обучаться на десятках, сотнях и тысячах (и даже больше) примеров. И даже неплохо работать. Но обучать их на реально больших объемах данных — часто бессмысленно и бесполезно. Подобные алгоритмы просто не в состоянии "впитать" в себя знания, сколько бы мы не пытались в них засунуть.
Нейросети же, особенно «глубокие», содержат каскады нейронных слоев и килограммы сложно объяснимых алгоритмических "потрохов". Им, часто, гораздо лучше «скармливать» сотни тысяч и миллионы примеров из BigData. Но… десятки и сотни примеров им не подойдут — они их просто запомнят и не смогут адекватно предсказывать будущее на новых данных.
Поэтому. Делаем глоток пива, обнимаем девушку за талию и запоминаем — если данных мало – то НЕ нейросети (а, например, catboost), если много – нейросети, а если данных очень много – то ТОЛЬКО нейросети. Сложные, интересные, привлекательные и «глубокие» (deep learning).

Какие нужны данные?
Комично до слез, но разумного ответа на этот вопрос пока тоже нет: cобирайте все, что можно и нельзя. За примером не нужно далеко ходить: крупные вендоры типа Google, Facebook, Amazon, Яндекс, Mail.ru успешно делают это уже многие годы, почти нас не спрашивая. Дальше — будет еще хуже.
Активность людей, интересы, пристрастия, перемещения, знакомые – все это фиксируется в часто достаточно обезличенной форме. Но… с привязкой к идентификатору человека.
Банально — по кукам в браузере или по номеру мобильного телефона. А когда к вам на сайт приходит кто-то в интернете, вы легко можете достать цифровую историю следов этой личности — и не важно, это Иван Иванович или "abh4756shja" — он интересуется ритуальными топорами, так покажем ему все их разновидности!
Если говорить более конкретно, то, например, от клиентов компании обычно собирают такую статистику:
- число обращений в техподдержку
- число и продолжительность звонков в компанию за определенный период
- приобретенные товары и услуги
- поисковые запросы на сайте компании
- заявки и пожелания
- данные заполненных анкет
- все что можно собрать в таком духе
Интернет-магазины обычно фиксируют посещенные страницы и их названия. заказанные товары, поисковые запросы, обращения в чат поддержки.
В итоге, забираемся на полочку повыше, там, где в баньке погорячее. Ибо дальше будет еще жарче. И фиксируем в голове – нужно собирать/покупать все что МОЖНО о наших клиентах. Все, что характеризует их активность, динамику и интересы.
Чем больше всякой биометрии и телеметрии мы соберем — тем лучше мы сможем потом обучить "умную коробочку" и дальше сможем оторваться от наших конкурентов.

Риски – качество данных
Рассмотрим пример. Допустим, мы пытаемся определить — беременна ли сотрудница нашей компании? Для этого предварительно собираем несколько параметров:
- число обращений к врачу компании
- число посещений спортзала компании
- число больничных в днях
- время звонков с клиентами в минутах
- число досрочных уходов с работы домой
- времени до окончания рабочего дня в минутах
И в таком духе. Никто не знает, что нужно собирать, но интуиция подсказывает, что пригодится все, даже фазы Луны и номера повторно просмотренных сезонов "Игры престолов".
Если соберем десятки, а желательно сотни (тысячи) примеров и они не будут повреждены багами программистов то, скорее всего, наша предиктивная модель обучится хорошо. Но если мы решили собирать 500 параметров по каждой беременности, а статистики по поведению беременных сотрудниц у нас всего на 10 примеров из реальной жизни — это не сработает. Даже ребенок поймет — так «умная» коробочка ничему толковому не научится, т.к. данные будут сильно разряженными.
А бывает еще так, особенно в крупных компаниях. Вы — большой босс или маленький боссик, отвечающий за крупный рост конверсии (так тоже иногда бывает). Аналитики приносят вам данные о покупателях. Но глаза «дающих» спрятаны или бегают. Или выпучены в безумной отваге. В общем, вы сомневаетесь в качестве этой бигдаты. И это — правильно.
Чтобы распознать подвох — разузнайте об использовании инженерных практик в подразделениях разработки у технического директора:
Пишут ли команды программистов модульные и интеграционные тесты к коду?
К сожалению, часто бывает так: программист увольняется, а те, кто остался, не понимают «как оно работает». А дальше разработчики легко могут поломать код. В любой момент. Пока не узнают об этом из жалоб от разгневанных клиентов. Или об этом узнаете вы, когда не сможете обучить нейронку из-за «кривой» бигдаты.
Настроено ли автоматизированное тестирование и мониторинг инфраструктуры, которая собирает данные о ваших покупателях? Ведется ли точный учет и отработка ошибок? Или определить процент потерянных данных без экзорциста невозможно?
Если все это есть — то, скорее всего, вам принесли качественную bigdata, иначе — толку от собранных данных будет мало, но, все же, попробовать стоит.

Данные есть. Что дальше?
Хотите на пальцах понять, что умеет обученная на собранных данных "предиктивная" модель? В большинстве случаев она может ответить «да» или «нет», уверенно или не уверенно и … всё. Обязательно, прямо сейчас, напишите фразу "предиктивная" модель несколько раз на спине загорелой девушки, сидящей рядом на банной полке, затем нанесите несколько шлепков дубовым веником. Повторите.
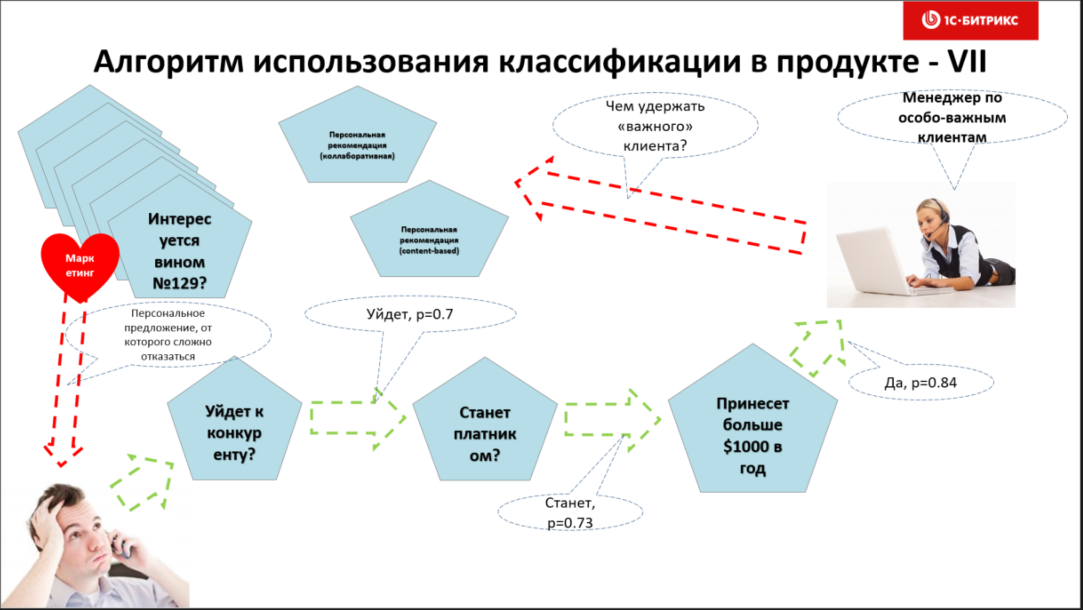
Пример. Вы — интернет-провайдер. У вас есть условно-бесплатный клиент. Вы хотите предсказать, перейдет ли он на платный тариф или нет? Ведь если вы сможете заранее знать будущее и еще не проявленные склонности клиентов — вы сможете более эффективно использовать маркетинговый бюджет, работая с потенциальными и не обращая внимания на тех, кто и нас скоро уйдет от вас.
«Нейронка», в лучшем случае, после обучения на данных, ответит вам либо уверенное «да», либо неуверенное «да», либо уверенное «нет», либо неуверенное «нет». И тут нужно очень хорошо понять, как же правильно работать с понятием "уверенности" классификатора и потренироваться.
Допустим, вы отбираете только «уверенные» ответы модели – и вот тут может оказаться, что из 100 ваших клиентов, машина уверенно определит склонность стать платным только для 7 пользователей. А на самом деле у вас 50 потенциально платных клиентов. Т.е. модель, из-за вашей осторожности, не продемонстрировала весь свой предсказательный потенциал.
Если же вы снизите порог "уверенности" и начнете принимать менее уверенные ответы модели — она, скорее всего, вернет вам почти всех действительно потенциально платных клиентов, но и немало других, не платных — а что вы хотите получить, понизив точность?
Т.е. либо применяем высоко-точное оружие и поражаем 5% злодеев, не нанося ущерб мирному населению, либо бахаем кассетными бомбами, уничтожаем всех злодеев, но вместе с ними всю флору, фауну и низколетящие НЛО.
И вот мы уперлись в понимание качества предиктивной модели или бинарного классификатора. Без него — дальше ну никак. На этой фразе вы можете подавиться, но ничего страшного — дальше будет только хуже ;) Важно понять, что чем лучше вы натренировали модель, чем более адекватную архитектуру вы подобрали для нейросети, чем больше вы достали bigdata — тем точнее предсказательная модель приблизится к идеалу: предсказывать правильно. В понимании этого принципа — залог вашего успеха.
Сделайте глоточек пива и разберем еще один пример.
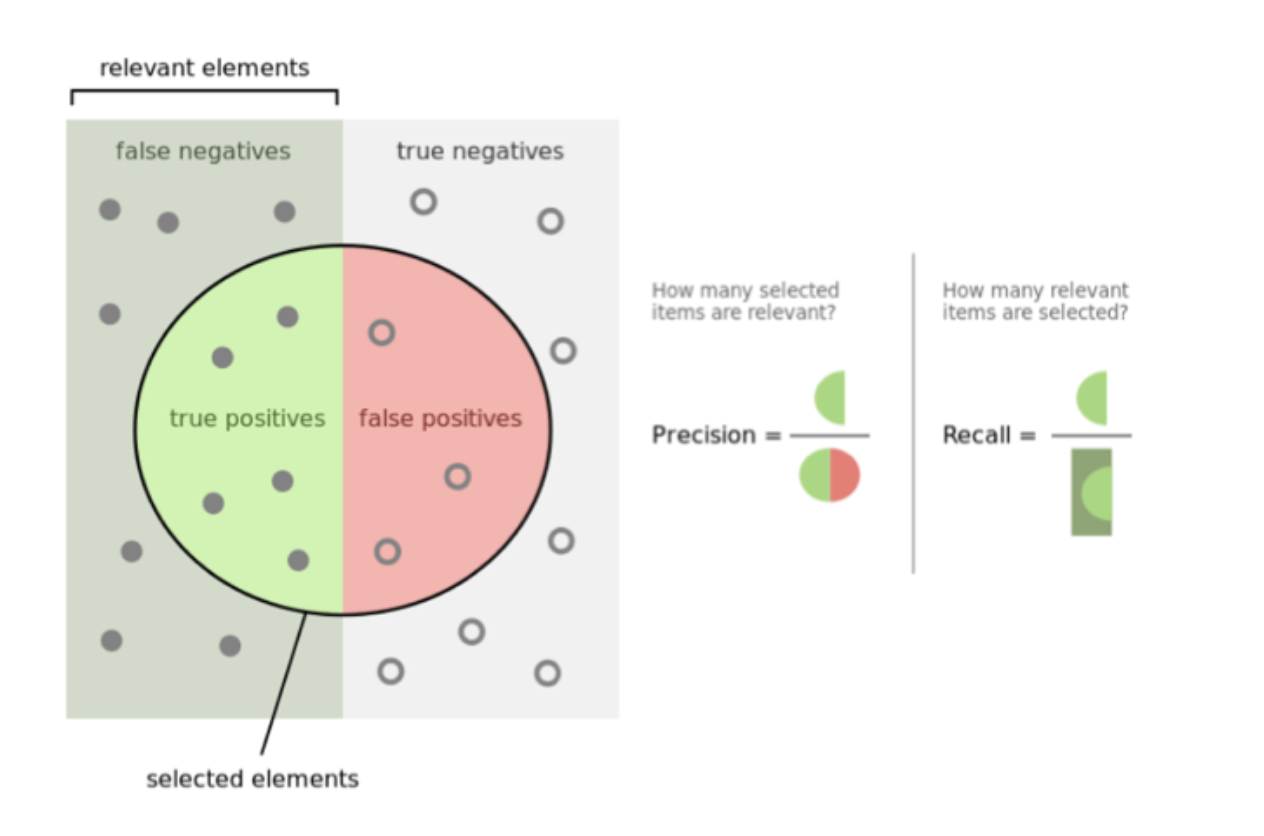
Качество бинарного классификатора
Допустим, вы собрали данные по 120 клиентам и вы точно знаете — 60 клиентов стали платными, 60 человек ничего не купили. Берем 100 примеров для обучения модели и 20 — для контроля.
Обучаем «умную» коробочку с помощью бесплатного софта и хотим проверить — а как она будет предсказывать поведение НОВЫХ клиентов? Задержитесь на этой фразе и прочувствуйте – бинарный классификатор уже обучен на статистике с уже известным исходом. Клиент или стал «платником», или нет. Ваша цель теперь — применить его на новых клиентах, которых Скайнет в глаза не видел, и заставить его предсказать – купит он ваш продукт или нет?
Поняли идею? У вас получился оракл, мать его за ногу! Оно действительно работает! В этом — сила и суть машинного обучения. Обучиться на исторических данных и предсказывать будущее!
Итак, вернемся на грешную землю.
Вы обучили «нейронку» на 100 клиентах. Берем оставшиеся 20, которые «умная» коробочка еще не видела и проверяем — что она скажет?
Вам заранее известно — 10 клиентов из оставшихся стали платными, а 10 – не стали.
В идеале классификатор должен «уверенно» ответить «да» по 10 и «уверенно» ответить «нет» по 10 оставшимся клиентам.
Порог «уверенности» установим в >=90% или >=0.9 из 1.0.
На этом этапе можно начать «крутить» порог уверенности вверх, часто получая гораздо меньше уверенных ответов, зато без ошибок (предсказание платника, когда на самом деле нужно было предсказать бесплатника): нужно было предсказать 10 платников из 10, а предсказали только 4.
И наоборот, если покрутить порог уверенности вниз – «коробочка» начнет делать больше предсказаний, но будет больше ошибаться и говорить на черное-белое и наоборот.
Еще раз: по порогу уверенности есть 2 варианта «выкручивания громкости»:
- AI будет выдавать вам меньше ответов, но с максимальной «уверенностью» и точностью = высоко-точное оружие
- Получаем больше ответов, но точности — меньше и начнутся ложные срабатывания = ковровые бомбардировки
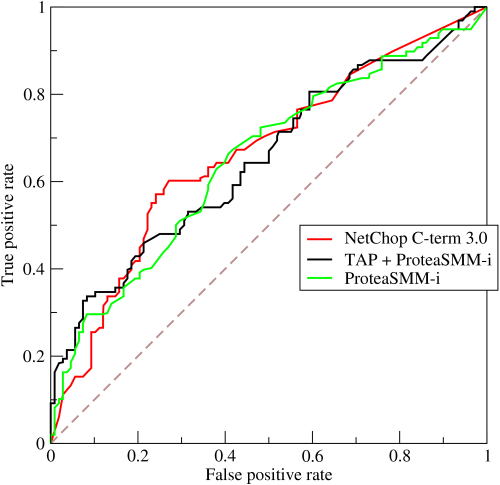
Чтобы не сойти с ума в оценке качества бинарных классификаторов, придумали простой параметр AUC. Чем он ближе к 1, тем ближе ваша модель к идеалу. И тем ближе вы к идеальному предсказанию покупок клиентов.
Еще раз, только проще, но теперь с KPI и премиями:
- Разработчики «учат» ваш бинарный классификатор
- Если на выходе его AUC больше 0.9 – люди идут в отпуск с премиями
- Если AUC меньше 0.9 — «ночь работе не помеха» и все думают, где собрать больше данных о клиентах, как выбрать лучшую архитектуру для модели и где еще остались баги в коде сбора данных и обучения нейросети
В общем, самое простое тут: установите вашей команде целевой KPI по качеству классификатора AUC — максимально приблизиться к показателю 1.0 и вы наверняка обойдете конкурентов!
Бизнес-применение «умных» коробочек
Вы еще живы? Правильно, дальше будет самое интересное.
Окунувшись в леденящую воду математики и протрезвев, предлагаю вернуться к девушкам и естественным удовольствиям.
Теперь вы знаете, что нужно для получения качественной «нейронки». А где их сейчас применяют? Да везде, где нужно получить ответ «да» или «нет»:
- выдавать кредит?
- купит ли действующий клиент ваш новый продукт?
- станет ли ваш бесплатный клиент платным?
- уйдет ли ваш клиент к конкуренту?
- уволится ли ваш сотрудник?
- доволен ли клиент качеством вашего сервиса?
В «Битрикс24» мы успешно применяли и применяем бинарные классификаторы для предсказаний:
- купит ли бесплатный клиент платный тариф «Битрикс24»?
- уйдет ли от нас платный клиент?
- как надолго он останется с нами?
А еще весь этот хайтек сейчас активно применяют и в персонализации товаров и услуг, и в задачах CRM и где только не применяют и дальше будет хуже.
Персонализация услуг и автоматизация работы маркетинга
Я веду вас к одному правильному выводу: на кой крендиль делать лишнюю работу своими руками, если ее можно автоматизировать? Для этого — созданы программисты и для этого созданы предсказательные модели.
«Умные» коробочки и другие виды предиктивных моделей можно легко внедрить для автоматизации рутины, например, отдела маркетинга: авто-таргетирование рекламных предложений на сайте или в email-рассылке.
Так сделайте же это скорее! Интегрируйте в ваш интернет-магазин робота, который будет предлагать вашим посетителям персонализированные товары и услуги.
Конверсия и лояльность ваших клиентов гарантированно вырастет.
Самый простой способ это сделать — обучение нескольких бинарных классификаторов для каждой группы товаров. А еще лучше — для каждой предлагаемой услуги на основе бигдаты покупок ваших клиентов.
Потом, когда клиент вернется на ваш сайт, AI сразу «поймет» чем его можно «зацепить». Это же так просто.
Видите, сколько появилось простых и эффективных способов увеличить конверсию. Так реализуйте их скорее.
В чем подвох?
Да, это все просто. На самом деле.
Внедрить предиктивные модели, нарастить проектную мощность маркетинга и конверсию в CRM – действительно несложно. Более того – возможно вам вообще не придется ничего покупать. Софт для обучения «Скайнетов» сейчас совершенно бесплатный. И его полно.
Если совсем лень в пень – можно поднять модель в облаке и оплачивать лишь хостинг, например в Amazon Machine Learning.
Но почему мы видим такие технологии в основном только в западных компаниях, решениях и продуктах? Ответ прост – инертность, нежелание менеджмента среднего звена развивать эффективность компании. В конце концов, просто… всем пофиг.
Я искренне убежден, в ближайшее время нас захлестнет поток решений на базе предиктивной аналитики и «нейронного» маркетинга. Это хорошо видно по скорости внедрения машинного обучения в рекламные сервисы Facebook, Google, Яндекс и Mail.ru. Кто не внедрит — уступит место конкурентам.
Достаточно вспомнить относительно недавние возможности по выгрузке в Facebook или Google хэшей от емейлов и телефонов ваших клиентов и математическое расширение рекламной аудитории чтобы понять, что дальше будет только … лучше и веселее
Еще одна причина – маркетологи часто просто не понимают, что дает им машинное обучение! Сколько времени у них освободится на креатив, если закрыть рутинное таргетирование и персонализацию рекламных предложений и email-рассылок с помощью «Скайнетов»!
Поэтому я и пишу такие подробные обзорные статьи для менеджмента. Кто, кроме топ-менеджеров или инициативных сотрудников, сможет продвинуть в компаниях настолько революционные проекты?
План действий
В принципе, теперь вы знаете достаточно, чтобы эффективно внедрить машинное обучение, предиктивный маркетинг, повысить конверсию и автоматизировать кучу рутины.
Давайте я опишу конкретные шаги к цели:
Раз. С помощью подразделения разработки или руками одного талантливого инженера – собираете данные о клиентах или покупаете их. Начните со сбора данных на сайте или в мобильном приложении. 5 строк правильно работающего г… нокода — и вы начнете получать статистику уже через 72 часа
Срок: 2-3 дня
Два. Руками одного аналитика создаете несколько предиктивных моделей, они же – бинарные классификаторы. Можно вообще ничего не программировать, а сразу загрузить данные в Amazon Machine Learning (https://aws.amazon.com/aml/details/).
Срок: 2-3 дня
Три. Внедряете «Скайнет» в ваши бизнес-процессы на сайт и в мобильное приложение
Срок: 7 дней
ЧеРтыре. Собираете обратную связь по качеству работы предиктивных моделей. Например, через статистику, голосование, анкеты. Цель – убедиться, что ваш обученный AI нормально работает с реальными данными.
Есть очень простое правило – обновлять эти модели раз, скажем, в PI (пи) — месяцев. Кому-то чаще, кому-то реже.
Если конверсия выше, чем без использования моделей – значит можно модели не обновлять. Упала – обновляйте.
Пять. Направьте освободившиеся ресурсы из подразделения маркетинга для решения более насущных задач – например на подготовку более качественных презентаций, вычитку текстов, создание красивых текстов для таргетированной рекламы.
Теперь таргетированием и персонализацией у вас занимаются роботы, а творчеством – люди – как и задумано в «первый день творения».
Шесть. Наслаждайтесь эффективностью, ищите новые точки бизнеса, где предиктивные бинарные классификаторы смогут защитить людей от рутины!
Друзья, на этом у меня пока все. Удачи вам, успешной автоматизации рутины, послушных роботов и хорошего настроения!
Телеграм: t.me/ainewsline
Источник: habr.com