Новый подход в Deep Learning: популяционное обучение нейросетей
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-04-14 18:00
новости нейронных сетей, алгоритмы машинного обучения, реализация нейронной сети
Рассказываем о новом подходе, предложенном компанией DeepMind для настройки гиперпараметров в моделях Deep Learning: популяционное обучение нейросетей.
Оптимизация моделей глубокого обучения является одним из сложных аспектов создания машинного интеллекта. Аналитики приходят к правильному набору алгоритмов для решения конкретной проблемы, потратив много времени в поисках оптимальной модели.
Оптимизация традиционных моделей глубокого обучения ориентирована на минимизацию ошибок на тестовой выборке без существенного изменения компонентов модели. Оптимизация глубокого обучения сосредоточена вокруг настройки этих гиперпараметров. Как правило, гиперпараметры в программах глубокого обучения включают такие элементы, как количество скрытых элементов или скорость обучения, настраиваемые для повышения производительности конкретной модели.
Оптимизация гиперпараметров превращается в своеобразную игру по нахождению баланса между эффективностью функции глубокого обучения и ее стоимостью. В основном для оптимизации гиперпараметров глубокого обучения применяются два подхода: случайный поиск и ручная настройка.
Случайный поиск
При случайном поиске популяция моделей обучается независимо и параллельно, а в конце обучения выбирается наиболее эффективная модель. Как правило, это означает, что лишь небольшая часть набора моделей будет обучена с хорошими гиперпараметрами, а остальные будут тренироваться с плохими, бессмысленно тратя ресурсы компьютера.
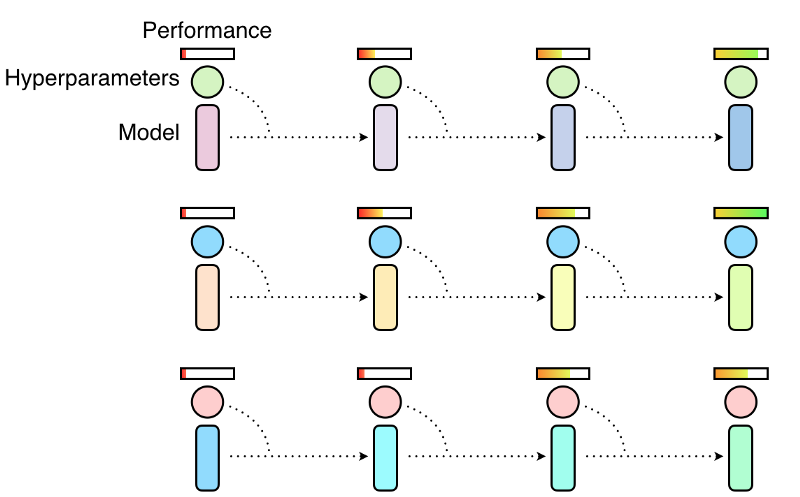
Ручная настройка
В методе ручной настройки исследователь настраивает гиперпараметры, исходя из собственного опыта, а после обучения оценивает производительность. Последовательная оптимизация требует выполнения нескольких тренировочных прогонов (возможно, с ранней остановкой), после чего выбираются новые гиперпараметры, и модель заново переучивается с найденными гиперпараметрами. Процесс можно автоматизировать методами Байесовской оптимизации, но цепочка последовательных процессов приводит к долгой оптимизации гиперпараметров, хотя сам процесс и использует меньшие вычислительные ресурсы, чем подход случайного поиска.
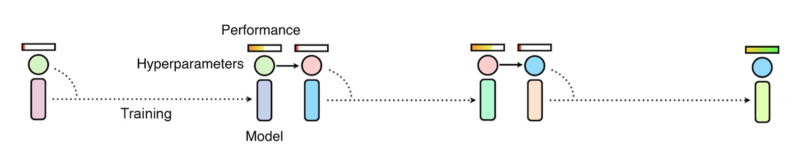
И для случайного поиска, и для методов ручной настройки имеются свои преимущества и ограничения. В конце прошлого года компания DeepMind опубликовала исследовательскую работу, в которой предложила новый подход к обучению и оптимизации моделей глубокого обучения, представляющий гибрид двух вышеописанных методов и известный как популяционное обучение нейросетей (population based training, PBT).
Популяционное обучение нейросетей
Популяционное обучение нейросетей так же, как и случайный поиск, начинается с параллельного обучения популяции нейросетей со случайными значениями гиперпараметров. Но вместого того, чтобы обучать нейросети независимо, время от времени они опрашиваются для уточнения гиперпараметров моделей, исходя из гиперпараметров тех моделей, что претендуют на роль оптимальных. Популяционный подход вдохновлен генетическими алгоритмами, в которых каждый член популяции получает информацию остальных членов и может, например, копировать параметры наиболее эффективных моделей или исследовать возможность вариации их текущих значений.
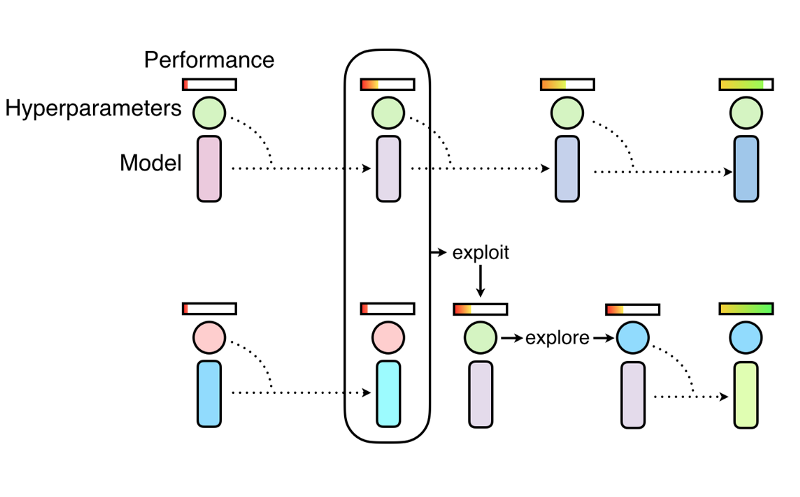
По мере обучения периодически проводится процесс копирования и вариации найденных популяцией лучших гиперпараметров, так что все модели в популяции в каждый момент времени имеют хороший базовый уровень производительности. При этом постоянно происходит изучение новых гиперпараметров. Таким образом, популяционное обучение нейросетей позволяет оптимизировать гиперпараметры в процессе обучения, а вычислительные ресурсы сосредоточить на гиперпараметрах и весовых пространствах, для которых наиболее вероятно получить хорошие результаты обучения. Итог – метод настройки гиперпараметров, одновременно приводящий к быстрому обучению и менее требовательный к вычислительным ресурсам.
Эксперименты DeepMind показали, что популяционное обучение нейросетей может эффективно использоваться для множества задач из различных областей. Ниже представлены результаты тестирования нового подхода для обучения нейросетей на актуальных задачах. Во всех представленных примерах полученные результаты обучения превысили результаты текущих решений.
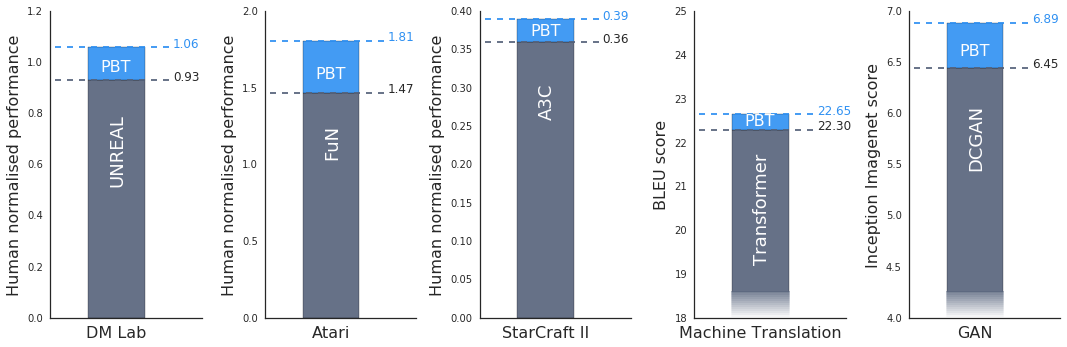
Также было обнаружено, что популяционное обучение эффективно работает при обучении генеративно-состязательной сети, задача настройки которых остается трудной проблемой (см. последний столбец диаграммы выше). Подход был применен и к современным системам машинного перевода Google. Подбор гиперпараметров в нейросетях машинного перевода обычно производится при помощи метода ручной настройки и занимает месяцы оптимизации. Популяционное обучение позволило превысить современные результаты без длительных многократных прогонов.
Подробнее о методе вы можете прочитать в публикации DeepMind на arXiv.org.
Другие материалы по теме нейросетей
Телеграм: t.me/ainewsline
Источник: proglib.io