Каким будет Web 3.0: блокчейн-маркетплейсы для машинного обучения
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-04-05 11:34
 Сегодня основные элементы подобных систем только формируются. Простые начальные версии подобных решений внушают надежду на успех. Эти торговые площадки обеспечат переход от нынешней эпохи монопольного владения данными Web 2.0 к Web 3.0 — открытой конкуренции за данные и алгоритмы с возможностью непосредственной монетизации.
Сегодня основные элементы подобных систем только формируются. Простые начальные версии подобных решений внушают надежду на успех. Эти торговые площадки обеспечат переход от нынешней эпохи монопольного владения данными Web 2.0 к Web 3.0 — открытой конкуренции за данные и алгоритмы с возможностью непосредственной монетизации.Возникновение идеи
Идея такой площадки возникла у меня в 2015 году после разговора с Ричардом из хедж-фонда Numerai. Они проводили конкурс на разработку модели фондового рынка и отправляли зашифрованные рыночные данные любому специалисту, желающему участвовать в нем. В итоге Numerai объединяет лучшие модели в «метамодель», продает ее и выплачивает вознаграждение тем специалистам, чьи модели работают эффективно.
Конкуренция между специалистами по обработке и анализу данных показалось перспективной идеей. Тогда я задумался: можно ли создать полностью децентрализованную версию такой системы, которая носила бы общий характер и могла быть использована для решения любых задач? Считаю, что на этот вопрос можно ответить утвердительно.
Проектирование
В качестве примера давайте попробуем создать полностью децентрализованную систему для торговли криптовалютами на децентрализованных биржах. Вот одна из возможных схем:
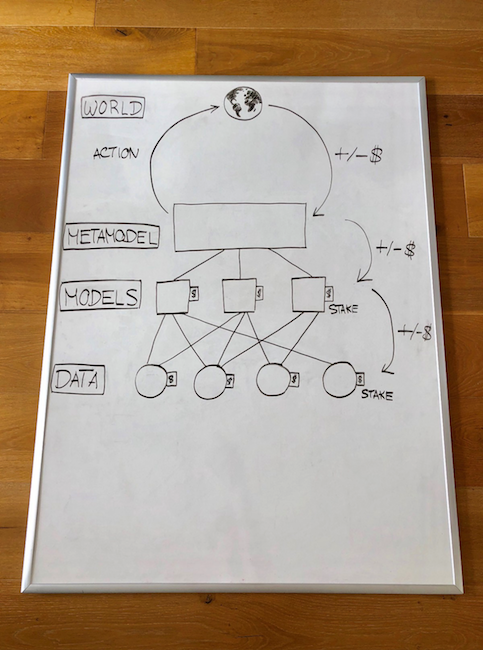
Модели. Разработчики моделей выбирают, какие данные использовать, и создают модели. Обучение проводится с использованием безопасного метода вычислений, который позволяет обучать модели, не раскрывая используемые данные. Модели выставляются на биржу так же, как и данные.
Метамодели. Метамодель создается на основе алгоритма, который учитывает биржевую цену каждой модели. Создание метамодели необязательно — некоторые модели используются и без объединения в метамодель. Смарт-контракт использует метамодель в электронных торгах посредством децентрализованных биржевых механизмов (on-chain транзакции).
Распределение прибыли / убытков. По прошествии некоторого времени торги дают прибыль или убыток, которые делятся между разработчиками метамодели, в зависимости от их вклада в ее усовершенствование. Модели, которые оказали отрицательное влияние на метамодель, теряют привлеченные средства полностью либо частично. И поставщики данных для этой модели тоже терпят некоторые убытки.
Верификация вычислений. Вычисления на каждом этапе выполняются двумя способами. Либо централизованно, но с возможностью верификации и опротестования через механизмы типа Truebit. Либо децентрализовано, с использованием протокола конфиденциального вычисления.
Хостинг. Данные и модели размещаются либо на IPFS, либо на нодах в защищенной системе конфиденциального вычисления с большим количеством участников. On-chain хранилище в этом случае будет слишком дорогим.
Почему это будет эффективно и производительно?
Перечислим основные преимущества такой системы:
- Стимул для привлечения наиболее востребованных данных. Как правило, для большинства проектов машинного обучения основным ограничивающим фактором является отсутствие качественных данных. Правильно спроектированная структура вознаграждений позволит получить доступ ко всем наиболее ценным данным точно так же, как появление биткойна с системой вознаграждений участников привело к появлению мощнейшей в мире вычислительной сети. Кроме того, прекратить работу системы, в которой данные поступают из тысяч или миллионов источников, практически невозможно.
- Конкуренция между алгоритмами. Модели и алгоритмы напрямую конкурируют друг с другом в сферах, где раньше такого не было. Представьте себе децентрализованную сеть Facebook с тысячами конкурирующих между собой алгоритмов новостных лент.
- Прозрачность вознаграждений. Поставщики данных и моделей видят, что они получают справедливую цену за свои продукты, поскольку все вычисления можно проверить. Это будет привлекать еще больше поставщиков данных.
- Автоматизация. Транзакции проводятся в среде блокчейна и стоимость генерируется непосредственно в токенах. Таким образом все взаимодействие становится автоматизированным и замкнутым, не требующим установления доверительных отношений.
- Сетевой эффект. Участие пользователей, поставщиков данных и специалистов по обработке и анализу данных обеспечивает многосторонний сетевой эффект и делает систему саморазвивающейся. Чем лучше она работает, тем больше капитала привлекает. Больше капитала — больше потенциальных выплат. Это, в свою очередь, привлекает больше поставщиков данных и специалистов по их обработке, которые делают систему более совершенной и рациональной. В результате привлекается больше вложений, и далее по кругу.
Конфиденциальность системы
В дополнение к перечисленному, важнейшим свойством является конфиденциальность. Гарантия конфиденциальности позволяет рядовым пользователям спокойно предоставлять любые личные данные. А также препятствовать утрате экономической ценности как данных, так и моделей. Если оставить данные и модели незашифрованными в открытом доступе, они будут скопированы бесплатно и использованы другими лицами, которые не вносят какого-либо вклада в общее дело («эффект безбилетника»).
Частичным решением проблемы безбилетника является продажа данных в частном порядке. Даже если покупатели захотят перепродать или раскрыть данные, это не так страшно, потому что стоимость данных со временем все равно амортизируется. Однако при таком подходе данные используются исключительно в краткосрочной перспективе, а проблемы с обеспечением их конфиденциальности никак не решаются. Так что использование защищенных вычислений представляется хоть и более сложным, но и более действенным подходом.
Защищенные вычисления
Безопасные методы вычислений позволяют обучать модели без раскрытия самих данных. В настоящее время используются и исследуются три основных вида защищенных вычислений: гомоморфное шифрование (HE), протокол конфиденциального вычисления (MPC) и доказательство с нулевым разглашением (ZKP). Для машинного обучения с использованием личных данных сегодня чаще всего используется MPC, поскольку HE обычно работает слишком медленно, а как применять для машинного обучения ZKP — пока неясно. Методы безопасных вычислений — это актуальнейшая тема современных компьютерных исследований. Такие алгоритмы, как правило, требуют гораздо больше времени, чем обычные вычисления, и становятся бутылочным горлышком системы. Но в последние годы они были заметно усовершенствованы.
«Идеальная рекомендательная система»
Чтобы проиллюстрировать потенциал машинного обучения на частных данных, представьте себе приложение под названием «Идеальная рекомендательная система». Оно следит за всем, что вы делаете на своих устройствах: анализирует все посещаемые сайты, все действия в приложениях, просмотренные картинки на телефоне, данные о местоположении, историю расходов, информацию с носимых датчиков, текстовые сообщения, данные с камер в вашем доме и на ваших будущих очках дополненной реальности. Эта информация позволит приложению давать вам рекомендации: какой следующий веб-сайт посетить, какую статью прочитать, какую песню послушать или какой товар купить.
Эта рекомендательная система будет чрезвычайно мощной, мощнее любой из существующих «силосных башен» с данными Google, Facebook или кого-нибудь еще. Все благодаря максимально глубокому анализу и возможности обучаться с помощью самых чувствительных личных данных, которыми вы бы ни с кем больше не поделились. Как и в предыдущем примере с системой торговли криптовалютами, залогом функционирования рекомендательной системы является создание рынка моделей, ориентированных на разные области (например, рекомендации веб-сайтов или музыки). Эти модели конкурировали бы за доступ к вашим зашифрованным данным, возможность рекомендовать — и, вероятно, даже платили бы вам за использование ваших данных или за ваше внимание к рекомендациям.
Систему распределенного обучения Google и систему дифференциальной приватности компании Apple можно считать шагами в направлении машинного обучения с использованием личных данных. Но эти решения всё равно подразумевают установление доверительных отношений, не позволяют пользователям самостоятельно отслеживать свою безопасность и хранят данные обособленно.
Реализованные подходы
Говорить о полноценных системах такого рода еще рано. На данный момент мало у кого уже есть что-то работающее, и большинство идет к таким системам постепенно.
Компания Algorithmia Research разработала достаточно простое решение, которое премирует за модель с точностью выше определенного порога, определяемого ретроспективно:
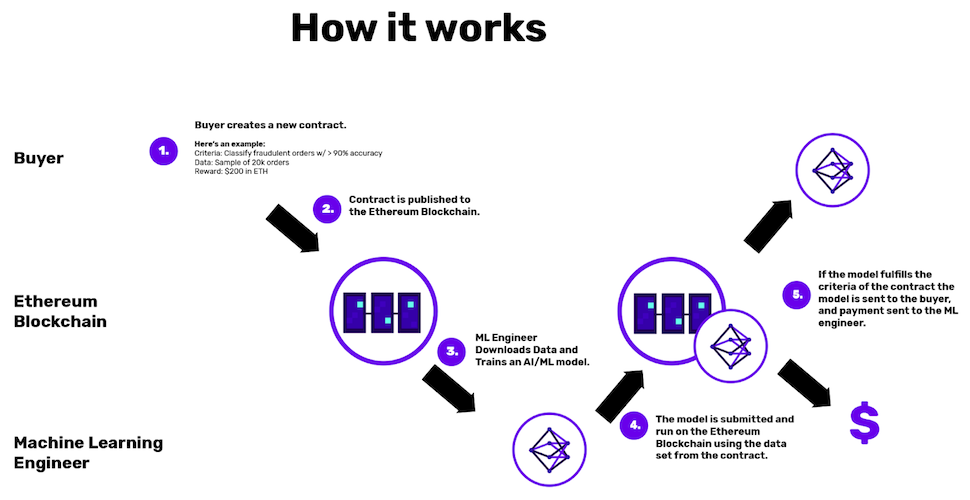
Хедж-фонд Numerai ушел на три шага вперед. Его система:
- использует зашифрованные данных (хотя такой вид шифрования нельзя считать полностью гомоморфным),
- объединяет краудсорсинговых моделей в метамодель,
- премирует модели через собственный Ethereum-токен Numeraire на основании будущей эффективности (недели биржевой торговли), а не ретроспективного тестирования.
Специалисты по анализу данных должны использовать Numeraire в качестве оболочки, тем самым подтверждая собственный интерес и стимулируя будущую производительность. И всё же на текущий момент Numerai распространяет данные централизованно, так что самая важная характеристика системы все еще не реализована.
На данный момент успешный маркетплейс данных на основе блокчейна еще не создан. Первой попыткой разработать такую систему, хотя бы в общих чертах, стал The Ocean. Другие начинают с постройки безопасных вычислительных сетей. В рамках проекта Openmined ведется работа по созданию многопользовательской вычислительной сети для обучения моделей машинного обучения на базе Unity, которая может работать на любом устройстве, включая игровые консоли (аналогичные Folding at Home). Впоследствии планируется расширить эту систему до протокола конфиденциального вычисления. Аналогичного подхода придерживается компания Enigma.
В результате этих работ было бы здорово получить метамодели, которые предоставляли бы совладельцам — поставщикам данных и разработчикам моделей — права собственности в объеме, пропорциональном их вкладу в совершенствование метамодели. Модели были бы токенизированы и могли бы со временем приносить доход, а те, кто обучал их, могли бы даже управлять ими. Это был бы своего рода роевой интеллект, находящийся в совместной собственности. Из всего, что я пока видел, ближе всего к такой системе подошел проект Openmined, если верить видеоролику о нем.
Что может сработать быстрее?
Не буду утверждать, что знаю, какой проект лучше, но у меня есть некоторые мысли на этот счет.
Применительно к блокчейну я оцениваю систему следующим образом. Если разложить ее в непрерывном спектре «физическое-цифровое-блокчейн», то чем больше будет от блокчейна, тем лучше. Чем меньше в ней от блокчейна, тем больше приходится привлекать доверенных сторон. Так система становится сложнее, и ее все менее удобно использовать в качестве составной части других систем.
Это означает, что система заработает с большей вероятностью, если создаваемая ей стоимость будет поддаваться количественной оценке. В идеале — в денежном выражении, а еще лучше в виде токенов. Это позволит создать полностью замкнутую систему. Для оценки эффективности сравните систему выше, например, с системой распознавания опухолей на рентгене. В последнем случае вам нужно убедить страховую компанию в том, что рентгеновские снимки имеют какую-то ценность, договориться о том, насколько они ценны, а затем доверить небольшой группе людей подтверждение успеха или неудачи рентгена.
Такая система может использоваться и в массе других полезных сценариев. Их можно привязать к рынкам курирования (curation market) — они смогут работать в замкнутом цикле по блокчейн-модели, а токены этого рынка могут выступать в качестве премии. Сейчас картина еще не ясна, но я предполагаю, что со временем число областей, требующих применения блокчейна, будет только расти.
Последствия для рынка
Децентрализованные рынки данных и моделей для машинного обучения могут разрушить монополию на данные, которой обладают современные корпорации. На протяжении последних 20 лет они занимались стандартизацией и торговлей основным источником стоимости в интернете: проприетарными сетями передачи данных и тем влиянием, которое они оказывают. Но теперь создание стоимости связано уже не с данными, а с алгоритмами.
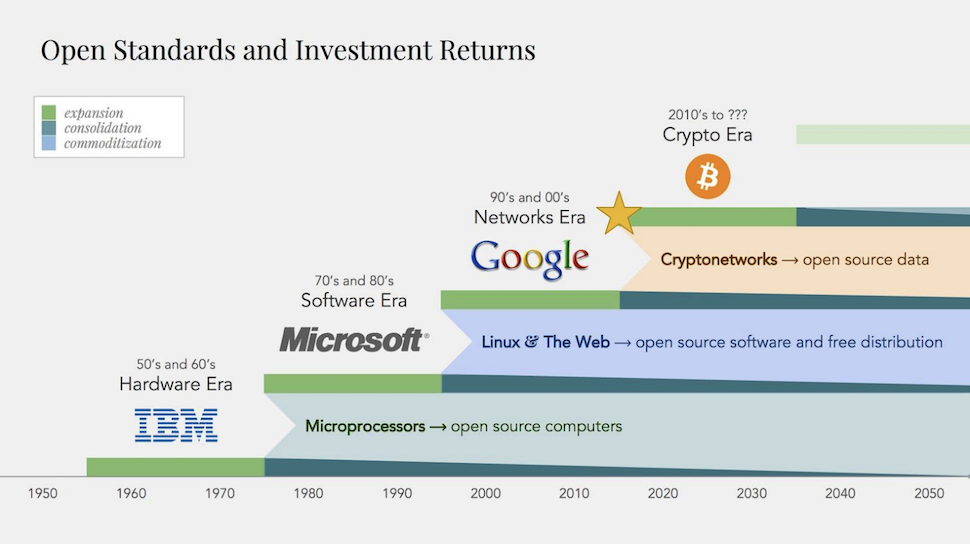 Циклы стандартизации и коммерциализации технологий. Мы приближаемся к концу эры сетей, монополизирующих данные.
Циклы стандартизации и коммерциализации технологий. Мы приближаемся к концу эры сетей, монополизирующих данные.
Иными словами, они создают бизнес-модель искусственного интеллекта, основанную на прямом взаимодействии, обеспечивают и предоставление данных, и обучение моделей.
Появление децентрализованных рынков данных и моделей для машинного обучения может привести к созданию самых мощных ИИ в мире. За счет прямых экономических стимулов они смогли бы получать наиболее ценные данные и модели. Их сила увеличивается благодаря многосторонним сетевым эффектам. Монополии сетевых данных эпохи Web 2.0 превращаются в товары повседневного спроса и становятся хорошим материалом для новой конгломерации. Вероятно, нам к этому идти еще несколько лет, но мы идем в правильном направлении.
Как показывает пример рекомендательной системы, процесс поиска глобально инвертируется. Сейчас люди ищут товары — а в будущем товары будут искать людей и конкурировать за них. У каждого потребителя будут личные рынки курирования, на которых системы рекомендаций будут конкурировать за размещение наиболее релевантного контента на своих каналах. А релевантность будет определяться потребителем.
Новые модели позволят нам получать те же преимущества от мощных сервисов на основе машинного обучения, к которым мы привыкли на примере услуг Google и Facebook. Но без предоставления личных данных.
Наконец, машинное обучение будет развиваться быстрее, так как получить доступ к открытому маркетплейсу данных сможет любой инженер-разработчик, а не только небольшая группа инженеров в крупных Web 2.0 компаниях.
Проблемы
Прежде всего, безопасные методы вычислений в настоящее время работают медленно, а машинное обучение уже требует больших вычислительных мощностей. С другой стороны, начинает появляться интерес к методам безопасных вычислений, а их производительность растет. За последние полгода я видел несколько новых подходов, которые значительно улучшают производительность HE, MPC и ZKP.
Сложно определять ценность конкретного набора данных или модели для метамодели.
Вычищать и форматировать краудсорсинговые данные тоже непросто. Скорее всего, ряд инструментов будут использоваться в сочетании друг с другом, и в сегменте начнутся процессы стандартизации при активном участии небольших компаний.
Наконец, как это ни парадоксально, бизнес-модель для создания подобной обобщенной системы менее очевидна, чем в случае с системой частной. Та же ситуация со множеством новых криптопримитивов, в том числе с рынками курирования.
Заключение
Комбинация машинного обучения на основе частных данных с блокчейн-вознаграждениями может привести к созданию самых производительных систем искусственного интеллекта различного назначения. Сейчас существуют большие технические проблемы, которые со временем представляются вполне решаемыми. Этот сегмент обладает огромным потенциалом в долгосрочной перспективе, а его становление может ослабить доминирующее положение крупных интернет-компаний в области доступа к данным. Эти системы даже внушают некоторые опасения: они сами загружаются, самостоятельно развиваются, потребляют конфиденциальные данные и становятся почти неубиваемыми, заставляя меня задаться вопросом, а не приведет ли их создание к появлению самого мощного Молоха в истории. В любом случае, эти системы — еще один пример того, как криптовалюты могут сперва медленно, а затем стремительно ворваться во все сферы хозяйственной деятельности.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru