Как работать с глубоким обучением, когда у вас мало данных?
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-04-25 22:30
Это часть 2 о том, как использовать глубокое обучение, когда у вас есть ограниченные данные. Извлечение Часть 1 Здесь.

Мы все были там. У вас есть Звездная концепция, которая может быть реализована с помощью модели машинного обучения. Чувствуя ebullient, вы открываете свой веб-браузер и искать соответствующие данные. Скорее всего, вы нашли набор данных , который имеет около несколько сотен изображений.
Тебе напомнить, что наиболее популярные наборы данных имеют изображения в порядок десятки тысяч (или больше). Вы также помните, что упоминание о большом наборе данных имеет решающее значение для хорошей производительности. Чувство разочарования, вам интересно; могут ли мои “государство-оф-арт-” нейронные сети работать хорошо с скудные объем данных у меня нет?
Ответ: да! Но прежде чем мы перейдем к магии, что делает, что произошло, мы должны задуматься на некоторые основные вопросы.
Зачем нужен большой объем данных?

Количество параметров (в миллионах), для популярных нейронных сетей.
Когда поезд машинного обучения модели, что вы действительно делаете настройки ее параметров , чтобы его можно сопоставить конкретный входной сигнал (например, изображения) для некоторых выход (метки). Наша цель оптимизации-преследовать то сладкое место, где потеря нашей модели низкая, что происходит, когда ваши параметры настроены правильно.
Современные нейронные сети обычно имеют параметры порядка миллионов!
Естественно, если у вас есть много параметров, вам нужно показать ваш машинного обучения модель пропорциональное количество примеров, чтобы получить хорошую производительность. Кроме того, количество параметров, вам нужно пропорционально к сложности задания, ваша модель должна выполнять.
Как получить больше данных, если у меня нет “больше данных”?
Вам не нужно искать новые новые изображения, которые могут быть добавлены в набор данных. Причина? Потому что, нейронные сети не умны для начала. Например, плохо обученная нейронная сеть будет думать, что эти три теннисных мяча, показанные ниже, являются различными, уникальными образами.

Тот же теннисный мяч, но переведен.
Таким образом, чтобы получить больше данных, нам просто нужно внести незначительные изменения в наш существующий набор данных. Незначительные изменения, такие как сальто или переводы или ротации. Наша нейронная сеть все равно будет думать, что это разные изображения.
Увеличение данных в игре
В сверточной нейронной сети, которая может эффективно классифицировать объекты, даже если его поместить в разных направлениях, как говорят, имеют свойство инвариантности. Более конкретно, CNN может быть инвариантной относительно перевода, точки зрения, размера и подсветки (или комбинация выше).
По сути, это предпосылка данные аугментации. В реальной ситуации, возможно, у нас есть набор данных, снимков, сделанных в ограниченном наборе условий. Но, наша цель приложения могут существовать в различных условиях, таких как различные ориентации, местоположения, масштаба, яркость и т. д. Мы учитываем такие ситуации путем обучения в нашей нейронной сети с дополнительным синтетически измененные данные.
Может ли увеличение помочь, даже если у меня много данных?
ДА. Это может помочь увеличить количество соответствующих данных в наборе данных. Это связано с тем, как нейронные сети учатся. Позвольте мне проиллюстрировать это на примере.

Два класса в нашем гипотетическом наборе данных. Тот, который находится слева, представляет Бренд A (Ford), а тот, что справа, - Бренд B (Chevrolet).
Представьте, что у вас есть набор данных, состоящий из двух марок автомобилей, как показано выше. Давайте предположим, что все автомобили бренда будут выровнены в точности как на картинке слева (т. е. все автомобили , стоящие перед левой) . Кроме того, все автомобили марки B совпадают в точности как на картинке в правом (т. е. вправо) . Теперь вы подаете этот набор данных в свою” современную " нейронную сеть, и вы надеетесь получить впечатляющие результаты, как только он будет обучен.

Автомобиль Ford (Brand a), но обращенный вправо.
Допустим, это уже обучение, и вы подаете изображение выше, которое является брендом автомобиля. Но ваша нейронная сеть показывает, что это автомобиль марки B! Ты в замешательстве. Разве вы не получили точность в 95% на своем наборе данных, используя свою” современную " нейронную сеть? Я не утрирую, подобные инциденты и ошибки имели место в прошлом.
Почему это происходит? Это происходит потому, что большинство алгоритмов машинного обучения работе. Он находит наиболее очевидные признаки, отличающие один класс от другого. Здесь особенность заключалась в том, что все автомобили марки А стояли налево, а все автомобили марки в-направо.
Ваша нейронная сеть так же хороша, как и данные, которые вы ее подаете.
Как предотвратить это? Мы должны уменьшить количество несущественных признаков в наборе данных. Для нашего классификатора моделей автомобилей выше простым решением было бы добавление изображений автомобилей обоих классов, обращенных в другом направлении к нашему исходному набору данных. Еще лучше, вы можете просто перевернуть на изображения в существующих базах данных по горизонтали таким образом, что они сталкиваются с другой стороны! Теперь, обучая нейронную сеть этому новому набору данных, Вы получаете производительность, которую вы намеревались получить.
Путем выполнять увеличение, смогите предотвратить вашу нейронную сеть от учить неуместные картины, существенно форсируя общую характеристику.
Приступая к работе
Прежде чем мы углубимся в различные методы увеличения, есть одна проблема, которую мы должны рассмотреть заранее.
Где мы увеличиваем данные в нашем конвейере ML?
Ответ может показаться вполне очевидным; мы делаем увеличение, прежде чем мы передадим данные в модель правильно? Да, но у вас есть два варианта. Один из вариантов состоит в том, чтобы выполнить все необходимые преобразования заранее, существенно увеличив Размер вашего набора данных. Другой вариант состоит в том, чтобы выполнить эти преобразования в мини-пакете, непосредственно перед подачей его в модель машинного обучения.
Первый вариант известен как в автономном режиме увеличение. Этот метод является предпочтительным для относительно небольших наборов данных, как вы бы в конечном итоге увеличивать Размер данных с коэффициентом, равным числу преобразований выполнения (например, листать все мои изображения, я хотел бы увеличить размер моего набора данных с коэффициентом 2).
Второй вариант известен как онлайн увеличение, или аугментация на лету. Этот метод является предпочтительным для больших наборов данных, поскольку Вы не можете позволить себе взрывное увеличение размера. Вместо этого можно выполнять преобразования для мини-пакетов, которые будут передаваться в модель. Некоторые платформы машинного обучения поддерживают расширение сети, которое может быть ускорено на GPU.
Популярные Методы Увеличения
В этом разделе мы представляем некоторые основные, но мощные методы увеличения, которые широко используются. Прежде чем мы рассмотрим эти методы, для простоты, давайте сделаем одно предположение. Предположение, что мы не должны рассматривать то, что лежит за пределами изображения границы. Мы будем использовать следующие методы, чтобы наше предположение было допустимым.
Что произойдет, если мы используем технику, которая заставляет нас угадать, что лежит за границей изображения? В этом случае, мы должны интерполировать какую-то информацию. Мы подробно обсудим это после того, как рассмотрим типы увеличения.
Для каждого из этих методов мы также указываем фактор, по которому Размер вашего набора данных будет увеличен (aka. Фактор Увеличения Данных).
1. Сальто
Вы можете переворачивать изображения по горизонтали и по вертикали. Некоторые фреймворки не предоставляют функции для вертикальных сальто. Но вертикальный флип эквивалентен вращению изображения на 180 градусов, а затем выполняет горизонтальный флип. Ниже приведены примеры для перевернутых изображений.

Слева мы имеем исходное изображение, за которым следует изображение, перевернутое по горизонтали, а затем изображение перевернуто по вертикали.
Вы можете выполнять сальто с помощью любой из следующих команд из ваших любимых пакетов. Фактор увеличения данных = от 2 до 4х
# NumPy.'img' = одно изображение. flip_1 = НП.fliplr (img
# TensorFlow. 'x' = заполнитель для изображения. форма = [высота, ширина, каналы] х = ТФ.заполнитель (dtype = tf.float32, форма = форма) flip_2 = ТФ.изображение.flip_up_down(х) flip_3 = ТФ.изображение.flip_left_right(х) flip_4 = ТФ.изображение.random_flip_up_down(х) flip_5 = ТФ.изображение.random_flip_left_right (x
2. Вращение
Одна из ключевых особенностей этой операции заключается в том, что размеры изображения могут не сохраняться после поворота. Если ваше изображение представляет собой квадрат, его вращение под прямым углом сохранит размер изображения. Если это прямоугольник, его вращение на 180 градусов сохранит Размер. Поворот изображения под более тонкими углами также изменит окончательный размер изображения. Мы посмотрим, как мы можем справиться с этой проблемой в следующем разделе. Ниже приведены примеры квадратных изображений, повернутых под прямым углом.

Изображения поворачиваются на 90 градусов по часовой стрелке относительно предыдущего, как мы двигаемся слева направо.
Вы можете выполнять ротацию с помощью любой из следующих команд из ваших любимых пакетов. Фактор увеличения данных = от 2 до 4х
# Заполнителей: 'х' = единый образ, 'г' = пакетной обработки изображений # "к" обозначает число 90 градусов против часовой стрелки вращения формы = [высота, ширина, каналы] х = ТФ.заполнитель (dtype = tf.float32, форма = форма) rot_90 = ТФ.изображение.rot90(имг к=1) rot_180 = ТФ.изображение.rot90 (img, k=2
# Вращаться под любым углом . В приведенном ниже примере, 'углы' в радианах формы = [партия, высота, ширина, 3] г = ТФ.заполнитель (dtype = tf.float32, форма = форма) rot_tf_180 = ТФ.контриб.изображение.поворот (y, углы = 3.1415
# Scikit-Image. 'angle' = Градусы. 'компания IMG' = Входное изображение # подробные сведения о 'режиме', проверка интерполяции разделе ниже. гниль = skimage.трансформировать.поворот (img, угол = 45, режим = 'reflect'
3. Масштаб
Изображение можно масштабировать наружу или внутрь. При масштабировании вовне Размер конечного изображения будет больше, чем размер исходного изображения. Большинство фреймворков вырезают раздел из нового изображения, размер которого равен исходному изображению. Мы будем иметь дело с масштабированием внутрь в следующем разделе, поскольку это уменьшает размер изображения, заставляя нас делать предположения о том, что лежит за границей. Ниже приведены примеры или изображения масштабируются.

Слева мы имеем исходное изображение, изображение масштабируется на 10%, а изображение масштабируется на 20
Масштабирование можно выполнить с помощью следующих команд, используя scikit-image. Фактор Увеличения Данных = Произвольный.
# Scikit Image. 'компания IMG' = входной сигнал изображения, 'шкала' = масштабный коэффициент # подробные сведения о 'режиме', проверка интерполяции разделе ниже. scale_out = skimage.трансформировать.масштабирование(имг шкалы=2.0, режим='константа') scale_in = skimage.трансформировать.масштабирование (img, scale = 0.5, mode = 'constant'
# Не забудьте обрезать изображения до оригинального размера (для # scale_out
4. Урожай
В отличие от масштабирования, мы просто случайным образом выберем раздел из исходного изображения. Затем мы изменим Размер этого раздела до исходного размера изображения. Этот метод широко известен как случайное обрезание. Ниже приведены примеры случайного обрезания. Если присмотреться, то можно заметить разницу между этим методом и масштабированием.

Слева у нас есть исходное изображение, квадратное сечение, обрезанное сверху слева, а затем квадратное сечение, обрезанное снизу справа. Размер обрезанных разделов был изменен до исходного размера изображения.
Вы можете выполнить случайные посевы, используя любую следующую команду для TensorFlow. Фактор Увеличения Данных = Произвольный.
# TensorFlow. 'x' = заполнитель для изображения. original_size = [высота, ширина, каналы] х = ТФ.заполнитель (dtype = tf.float32, shape = original_size
# Используйте следующие команды для выполнения случайных культур crop_size = [new_height, new_width, каналы] семя = НП.Случайный.randint(1234) х = ТФ.random_crop(х, Размер = crop_size, семена = семена) выход = ТФ.Изображения.resize_images (x, size = original_size
5. Перевод
Перевод просто включает в себя перемещение изображения по направлению X или Y (или оба). В следующем примере мы предполагаем, что изображение имеет черный фон за пределами своей границы и переводится соответствующим образом. Этот метод наращивания является очень полезным, так как большинство объектов могут быть расположены в почти любом месте на изображении. Это заставляет ваш сверточная нейронная сеть искать везде.
Слева у нас есть исходное изображение, изображение, переведенное вправо, и изображение, переведенное вверх.
Переводы в TensorFlow можно выполнять с помощью следующих команд. Фактор Увеличения Данных = Произвольный.
# pad_left, pad_right, pad_top, pad_bottom обозначают пиксель # смещение. Установить один из них на желаемое значение и остальные 0 форма = [партия, высота, ширина, каналы] х = ТФ.заполнитель (dtype = tf.float32, shape = shape
# Мы используем две функции, чтобы получить желаемое увеличение
x = tf.изображение.pad_to_bounding_box(х, pad_top, pad_left, высота + pad_bottom + pad_top, Ширина + pad_right + pad_left)
выход = tf.изображение.crop_to_bounding_box(х, pad_bottom, pad_right, высота, ширина)
6. гауссовский шум
Чрезмерная подгонка обычно происходит, когда ваша нейронная сеть пытается узнать высокочастотные особенности (шаблоны, которые происходят много), которые могут быть не полезны. Гауссовский шум, который имеет нулевое среднее значение, по существу имеет точки данных во всех частотах, эффективно искажая высокочастотные объекты. Это также означает, что компоненты более низкой частоты (обычно, ваши предполагаемые данные) также искажены, но ваша нейронная сеть может научиться смотреть на это. Добавление правильного количества шума может повысить способность к обучению.
Тонизированная версия этого-шум соли и перца, который представляет себя как случайные черные и белые пиксели, распространяющиеся по изображению. Это похоже на эффект, создаваемый путем добавления гауссовского шума к изображению, но может иметь более низкий уровень искажения информации.

Слева мы имеем исходное изображение, изображение с добавленным гауссовским шумом, изображение с добавленным солью и перцовым шумом
Вы можете добавить гауссовский шум к вашему изображению, используя следующую команду, на TensorFlow. Фактор увеличения данных = 2х.
# TensorFlow. 'x' = заполнитель для изображения. форма = [высота, ширина, каналы] х = ТФ.заполнитель (dtype = tf.float32, shape = shape
# Добавление Гауссовского шума шум = ТФ.random_normal (shape=tf.формы(х), значит,=0.0, со стандартным отклонением=1.0, dtype=ТФ.float32) выход = ТФ.добавить (x, шум
Усовершенствованные Методы Увеличения
Реальный мир, природные данные все равно могут существовать в различных условиях , которые невозможно учесть на выше простыми методами. Например, давайте возьмем задачу идентификации ландшафта на фотографии. Пейзаж мог быть чем угодно: мерзлыми тундрами, лугами, лесами и так далее. Звучит как довольно прямолинейная задача классификации правильно? Вы были бы правы, за исключением одной вещи. Мы упускаем из виду важную особенность в фотографиях, которая повлияет на производительность-сезон, в котором была сделана фотография.
Если наша нейронная сеть не понимает того, что определенные ландшафты могут существовать в различных условиях (снег, сырость, яркий и т.д.).), он может с любопытством обозначать замерзшие озера как ледники или влажные поля как болота.
Один из способов смягчить эту ситуацию-добавить больше фотографий, чтобы мы учитывали все сезонные изменения. Но это трудная задача. Расширяя нашу концепцию увеличения данных, представьте, как здорово было бы искусственно генерировать эффекты, такие как разные сезоны?
Условные Ганы на помощь!
Не вдаваясь в детали gory, условные GANs могут преобразовать изображение из одного домена в изображение в другой домен. Если вы думаете, что это звучит слишком расплывчато, это не так; это буквально как мощный эта нейросеть! Ниже приведен пример условного Ганс, используемый для преобразования фотографии летних пейзажей на зимние пейзажи.

Смены времен года с помощью CycleGAN (Источник: https://junyanz.github.io/CycleGAN/)
Вышеуказанный метод является надежным, но вычислительно интенсивным. Более дешевой альтернативой будет то, что называется невральной стиль передачи. Он захватывает текстуру / атмосферу / внешний вид одного изображения (он же “стиль”) и смешивает его с содержанием другого. Используя эту мощную технику, мы создаем эффект, похожий на эффект нашего условного GAN (на самом деле, этот метод был введен до того, как были изобретены cgan!).
Единственным недостатком этого метода является то, что результат, как правило, выглядит более художественным, а не реалистичным. Тем не менее, есть некоторые достижения, такие как глубокий фото Стиль передачи, показано ниже, которые имеют впечатляющие результаты.

Глубокая Передача Стиля Фотографии. Обратите внимание, как мы могли бы создать желаемый эффект на наш набор данных. (Источник: https://arxiv.org/abs/1703.07511)
Мы не исследовали эти методы в большой глубине по мере того как мы не связаны с их внутренней работой. Мы можем использовать существующие обученные модели, наряду с магией передачи обучения, чтобы использовать его для увеличения.
Краткая записка об интерполяции
Что делать, если вы хотите перевести изображение, которое не имеет черный фон? Что, если вы хотите, чтобы масштабировать внутрь? Или вращаться под более тонкими углами? После выполнения этих преобразований нам необходимо сохранить Размер исходного изображения. Так как наше изображение не имеет никакой информации о вещах за его пределами, нам нужно сделать некоторые предположения. Обычно пространство за границей изображения считается константой 0 в каждой точке. Поэтому, когда вы делаете эти преобразования, вы получаете черную область, где изображение не определено.

Слева-изображение, повернутое на 45 градусов против часовой стрелки, изображение, переведенное вправо, и изображение, масштабированное внутрь.
Но это ли правильное предположение? В реальной ситуации, это в основном нет. Обработка изображений и фреймворки ML имеют несколько стандартных способов, с помощью которых вы можете решить, как заполнить неизвестное пространство. Они определяются следующим образом.

Слева мы имеем режимы константы, ребра, отражения, симметричные и обертывание.
1. Постоянный
Простейшим методом интерполяции является заполнение неизвестной области некоторым постоянным значением. Это может не работать для естественных изображений, но может работать для изображений, сделанных на монохроматическом фоне
2. Край
Значения ребер изображения расширяются после границы. Этот метод может работать для мягких переводов.
3. Отражать
Значения пикселов изображения отражаются вдоль границы изображения. Этот метод полезен для непрерывного или естественного фона, содержащего деревья, горы и т. д.
4. Симметричный
Этот метод похож на reflect, за исключением того, что на границе отражения сделана копия краевых пикселей. Обычно, reflect и симметричные могут использоваться взаимозаменяемо, но различия будут видны при работе с очень маленькими изображениями или узорами.
5. Упаковка
Изображение просто повторяется за его пределами, как будто оно покрыто плиткой. Этот метод не так широко используется, как остальные, поскольку он не имеет смысла для многих сценариев.
Кроме того, вы можете создавать свои собственные методы для работы с неопределенным пространством, но обычно эти методы просто отлично подходят для большинства проблем классификации.
Итак, если я использую все эти методы, мой алгоритм ML будет надежным, верно?
Если вы используете его в правильном пути, тогда да! Как правильно вы спросите? Ну, иногда не все методы увеличения имеют смысл для набора данных. Еще раз рассмотрим пример нашего автомобиля. Ниже приведены некоторые способы изменения изображения.

Первое изображение (слева) - оригинал, второе-горизонтально, третье-на 180 градусов, а последнее-на 90 градусов (по часовой стрелке).
Конечно же, это фотографии одного и того же автомобиля, но ваше конечное приложение может никогда не увидеть автомобили, представленные в этих направлениях.
Например, если вы просто собираетесь классифицировать случайные автомобили на дороге, только второе изображение будет иметь смысл быть на наборе данных. Но, если у вас есть страховая компания, которая занимается автомобильными авариями, и вы хотите идентифицировать модели перевернутых, сломанных автомобилей, а также, третий образ имеет смысл. Последнее изображение может не иметь смысла для обоих вышеперечисленных сценариев.
Суть в том, что при использовании аугментации методики, мы должны убедиться, чтобы не увеличивать ненужных данных.
Это действительно стоит усилий?
Вы, вероятно, ожидаете некоторых результатов, чтобы мотивировать вас пройти лишнюю милю. Достаточно честно, у меня это тоже есть. Докажу, что аугментация действительно работает, используя игрушечный пример. Вы можете повторить этот эксперимент для проверки.
Давайте создадим две нейронные сети для классификации данных по одному из четырех классов: кошка, Лев, тигр или леопард. Уловка, одно не будет использовать увеличение данных, тогда как другое будет. Вы можете скачать массив данных здесь ссылку.
Если вы извлекли набор данных, Вы заметите, что в классе только 50 изображений для обучения и тестирования. Очевидно, мы не можем использовать дополнение для одного из классификаторов. Чтобы сделать разрез более справедливым, мы используем переноса обучения , чтобы придать модели больше шансов с скудные количества данных.

Четыре класса в нашем наборе данных.
Для той, которая не имеет расширения, давайте использовать сеть VGG19. Я написал TensorFlow реализации здесь, который основан на этой реализации. После того, как вы склонировали мой РЕПО, вы можете получить набор данных из здесь, и vgg19.npy (используется для перевода обучающегося) из здесь. Теперь можно запустить модель для проверки производительности.
Я бы согласился, хотя, написание дополнительного кода для дополнения данных действительно немного усилий. Итак, для создания нашей второй модели, я обратился к Nanonets. Они внутренне используют обучение передачи и увеличение данных для того чтобы обеспечить самые лучшие результаты используя минимальные данные. Все, что вам нужно сделать, это загрузить данные на их сайте, и подождите, пока он обучался в своих серверах (обычно около 30 минут). Что вы знаете, это идеально подходит для нашего эксперимента сравнения.
После завершения обучения можно запросить вызовы их API для вычисления точности теста. Извлеките мой РЕПО для фрагмента кода образца (не забудьте вставить идентификатор модели в фрагмент кода).
Результаты VGG19 (без увеличения)- 76% тест на точность (высокая) Nanonets (с увеличением) - 94.5% точность испытания
Впечатляет не так ли. Факт что большинств модели выполняют хорошо с больше данных. Поэтому, чтобы предоставить конкретное доказательство, я упомянул таблицу ниже. Он показывает частоту ошибок популярных нейронных сетей в наборах данных Cifar 10 (C10) и Cifar 100 (C100). C10 + и C100 + столбцы частоты ошибок с увеличением данных.
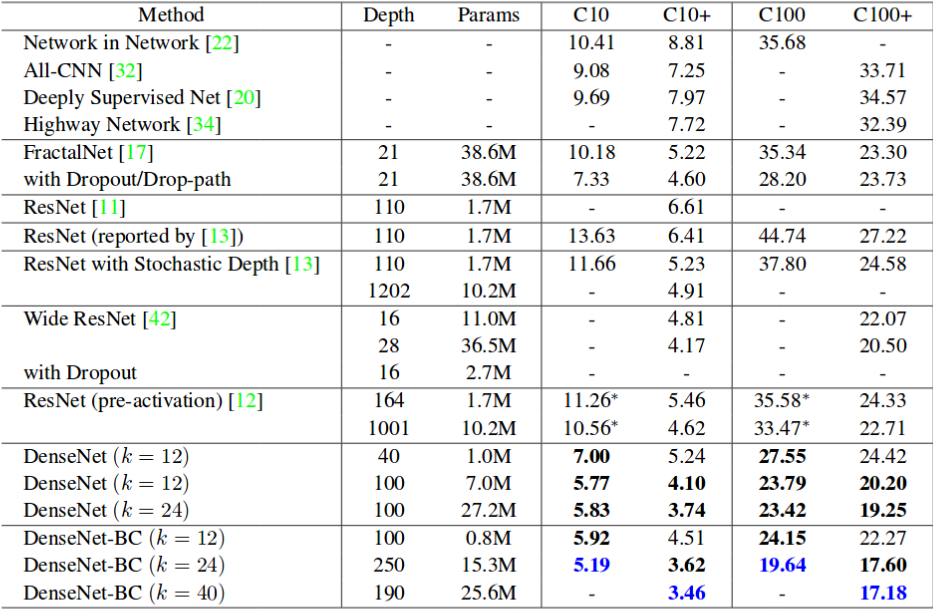
Частота ошибок популярных нейронных сетей в наборах данных Cifar 10 и Cifar 100. (Источник: DenseNet)
Спасибо, что прочитали эту статью! Нажмите кнопку хлопать, если вы сделали! Надеюсь, это прольет свет на увеличение данных. Если у вас есть какие-либо вопросы, вы могли бы ударил меня в социальных сетях или отправить мне по электронной почте (bharathrajn98@gmail.com).
Телеграм: t.me/ainewsline
Источник: medium.com