Истинная реализация нейросети с нуля. Часть 2. Распознавание цифр
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-04-02 13:04

Dispute about eternal
Сердечно приветствую всех Хабравчан! С момента выхода первой части "Истинной реализации" (рекомендую ознакомиться) прошло достаточно много времени. Как внятных обучающих статей не было, так и нет, поэтому я решил подарить Вам возможность узнать от А до Я, как написать программу для распознавания цифр, в связи с тем, что мои знания в этой области заметно возросли. Как и в прошлый раз, предупреждаю, что данная статья ориентирована на тех, кто понимает основы работы нейронных сетей, но не понимает, как создать их «низкоуровневую», истинную реализацию. Приглашаю под кат ознакомиться с сим творением тех, кому надоели убогие реализации XOR, общая теория, использование Tensor Flow и др. Действующие лица: Шарпей, прошлогодняя Визуальная Студия, самодельный Набор Данных, Воплощение чистого разума и Ваш покорный слуга…
ДАТАСЕТ В КУСТАРНЫХ УСЛОВИЯХ
Итак, выбор задачи машинного обучения сделан: распознавание образов, коим будет служить цифра на изображении 3 на 5 пикселей. Поэтому первым очевидным шагом будет создание набора данных пусть и в домашних условиях. Немного поиграв с воображением, я нарисовал на бумаге обучающую выборку на 100 элементов и тестовую на 10, а затем перенёс это в цифровой вид с помощью фотошопа. На GIF'ке показаны все элементы обучающей выборки по порядку. Получился эдакий MNIST на минималках.

Going through the whole mothafvckn training set
МОДЕЛЬ
А теперь время создавать "искусственный интеллект". По традиции показываю схему многослойного перцептрона с указанием некоторых его параметров.
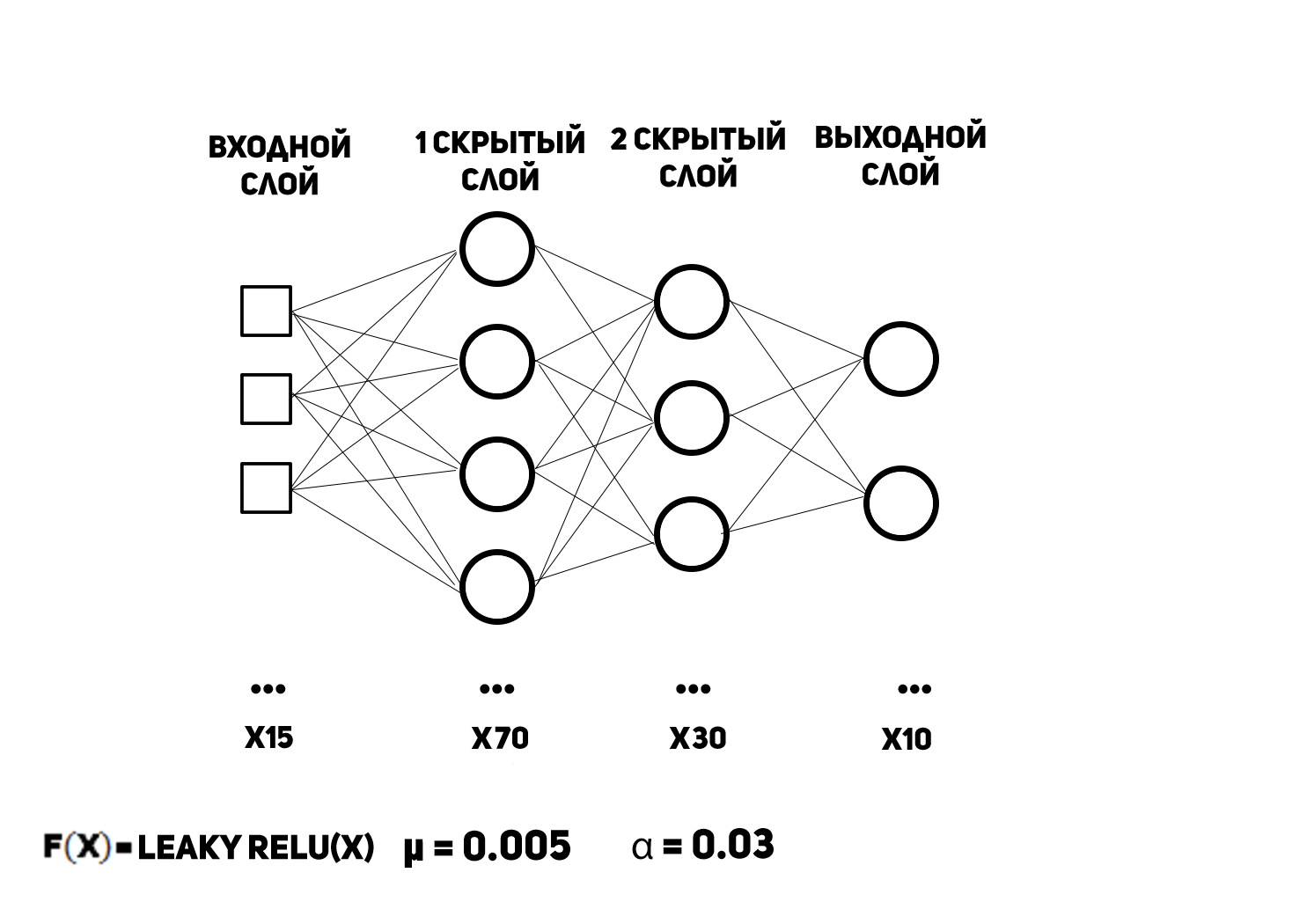
Естественно входов 15, так как пикселей в изображении столько же. Выходной вектор данных представляет собой набор вероятностей принадлежности цифры к конкретному классу, то есть номер нейрона с максимальным выходом (при отсчёте от нуля) будет цифрой, нарисованной на картинке. Для такого формата данных в выходном слое используется функция активации, гордо именуемая softmax’ом. На вход она принимает вектор, на выходе отдаёт вектор, а её производная вообще матрица, но это НЕ ВАЖНО. Почему? Потому что есть пруфлинк (смотри 3 страницу), с которым рекомендую ознакомиться. Функция активации нейронов скрытого слоя, как видно из рисунка выше, есть текучий выпрямленный линейный блок (leaky rectified linear unit). Про неё хочется поговорить, немного больше, так как она чуть ли не самая лучшая функция активации вообще. Задаётся она такой формулой:
И выглядит следующим образом:

Это наталкивает на некоторые мысли.
That is how Xzibit pimped Identity activation function
Собственно говоря, она хороша по ряду причин:
- отсутствие перенасыщения нейронов при обучении;
- лёгкая вычисляемость для компьютера;
- максимальная схожесть поведения с биологическим нейроном;
- факт, что персептрон с ней сходится быстрее;
- в отличие от предка ReLU не "убивает" нейроны во время обучения.
КОД
Вот, дорогие хабрадрузья, Вы и дотерпели до десерта. А теперь программируем! Точнее я вам буду разбирать по косточкам исходники перцептрона на C# 7. Пространство имён для него называется demoapp.Model, и, почему имя именно такое, Вы узнаете чуть позже.
ModelEnums.cs
namespace demoapp.Model { enum MemoryMode//режимы работы памяти { GET, SET } enum NeuronType//тип нейрона { Hidden, Output } enum NetworkMode//режимы работы сети { Train,//обучение Test,//тестирование Demo//демонстрация } }В этом файле лежат несколько перечислений: первое для обращения к XML файлам для записи/чтения весов, второе для определения типа вычислений внутри нейрона в зависимости от типа слоя, к которому он принадлежит, третье для переопределения работы сети.
Neuron.cs
using static System.Math; namespace demoapp.Model { class Neuron { public Neuron(double[] inputs, double[] weights, NeuronType type) { _type = type; _weights = weights; _inputs = inputs; } private NeuronType _type;//тип нейрона private double[] _weights;//его веса private double[] _inputs;//его входы private double _output;//его выход private double _derivative; //константы для функции активации private double a = 0.01d; public double[] Weights { get => _weights; set => _weights = value; } public double[] Inputs { get => _inputs; set => _inputs = value; } public double Output { get => _output; } public double Derivative { get => _derivative; } public void Activator(double[] i, double[] w)//нелинейные преобразования { double sum = w[0];//аффиное преобразование через смещение(нулевой вес) for (int l = 0; l < i.Length; ++l) sum += i[l] * w[l + 1];//линейные преобразования switch (_type) { case NeuronType.Hidden://для нейронов скрытого слоя _output = LeakyReLU(sum); _derivative = LeakyReLU_Derivativator(sum); break; case NeuronType.Output://для нейронов выходного слоя _output = Exp(sum); break; } } private double LeakyReLU(double sum) => (sum >= 0) ? sum : a * sum; private double LeakyReLU_Derivativator(double sum) => (sum >= 0) ? 1 : a; } }Самый важный класс, так как он реализует вычислительную единицу сети, за счёт которой происходит вся "магия". Нейрон создан по модели МакКаллока-Питтса, с включением смещений для афинных преобразований внутри функции активации. Если нейрон находится в выходном слое, то в качестве выхода ищется экспоненциальная функция от сумматора. Это сделано для реализации softmax функции, которая считается уже в самом слое.
InputLayer.cs
namespace demoapp.Model { class InputLayer { public InputLayer(NetworkMode nm) { System.Drawing.Bitmap bitmap; switch (nm) { case NetworkMode.Train: bitmap = Properties.Resources.trainset; for (int y = 0; y < bitmap.Height / 5; ++y) for (int x = 0; x < bitmap.Width / 3; ++x) { _trainset[x + y * (bitmap.Width / 3)].Item2 = (byte)y; _trainset[x + y * (bitmap.Width / 3)].Item1 = new double[3 * 5]; for (int m = 0; m < 5; ++m) for (int n = 0; n < 3; ++n) { _trainset[x + y * (bitmap.Width / 3)].Item1[n + 3 * m] = (bitmap.GetPixel(n + 3 * x, m + 5 * y).R + bitmap.GetPixel(n + 3 * x, m + 5 * y).G + bitmap.GetPixel(n + 3 * x, m + 5 * y).B) / (765.0d); } } //перетасовка обучающей выборки методом Фишера-Йетса for (int n = Trainset.Length - 1; n >= 1; --n) { int j = random.Next(n + 1); (double[], byte) temp = _trainset[n]; _trainset[n] = _trainset[j]; _trainset[j] = temp; } break; case NetworkMode.Test: bitmap = Properties.Resources.testset; for (int y = 0; y < bitmap.Height / 5; ++y) for (int x = 0; x < bitmap.Width / 3; ++x) { _testset[x + y * (bitmap.Width / 3)] = new double[3 * 5]; for (int m = 0; m < 5; ++m) for (int n = 0; n < 3; ++n) { _trainset[x + y * (bitmap.Width / 3)].Item1[n + 3 * m] = (bitmap.GetPixel(n + 3 * x, m + 5 * y).R + bitmap.GetPixel(n + 3 * x, m + 5 * y).G + bitmap.GetPixel(n + 3 * x, m + 5 * y).B) / (765.0d); } } break; } } private System.Random random = new System.Random(); private (double[], byte)[] _trainset = new(double[], byte)[100];//100 изображений в обучающей выборке public (double[], byte)[] Trainset { get => _trainset; } private double[][] _testset = new double[10][];//10 изображений в тестовой выборке public double[][] Testset { get => _testset; } } }Данный код считывает пиксели изображений с обучающей и тестовой выборками. Перемешивание обучающей выборки происходит для повышения качества обучения, так как изначально примеры расположены по порядку от 0 до 9.
Layer.cs
using System.Xml; namespace demoapp.Model { abstract class Layer//модификаторы protected стоят для внутрииерархического использования членов класса {//type используется для связи с одноимённым полю слоя файлом памяти protected Layer(int non, int nopn, NeuronType nt, string type) {//увидите это в WeightInitialize numofneurons = non; numofprevneurons = nopn; Neurons = new Neuron[non]; double[,] Weights = WeightInitialize(MemoryMode.GET, type); lastdeltaweights = Weights; for (int i = 0; i < non; ++i) { double[] temp_weights = new double[nopn + 1]; for (int j = 0; j < nopn + 1; ++j) temp_weights[j] = Weights[i, j]; Neurons[i] = new Neuron(null, temp_weights, nt);//про подачу null на входы ниже } } protected int numofneurons;//число нейронов текущего слоя protected int numofprevneurons;//число нейронов предыдущего слоя protected const double learningrate = 0.005d;//скорость обучения protected const double momentum = 0.03d;//момент инерции protected double[,] lastdeltaweights;//веса предыдущей итерации обучения Neuron[] _neurons;//массив нейронов текущего слоя public Neuron[] Neurons { get => _neurons; set => _neurons = value; } public double[] Data//я подал null на входы нейронов, так как {//сначала нужно будет преобразовать информацию set//(видео, изображения, etc.) {//а загружать input'ы нейронов слоя надо не сразу, for (int i = 0; i < Neurons.Length; ++i) { Neurons[i].Inputs = value; Neurons[i].Activator(Neurons[i].Inputs, Neurons[i].Weights); } }//а только после вычисления выходов предыдущего слоя } public double[,] WeightInitialize(MemoryMode mm, string type) { double[,] _weights = new double[numofneurons, numofprevneurons + 1]; XmlDocument memory_doc = new XmlDocument(); memory_doc.Load(System.IO.Path.Combine("Resources", $"{type}_memory.xml")); XmlElement memory_el = memory_doc.DocumentElement; switch (mm) { case MemoryMode.GET: for (int l = 0; l < _weights.GetLength(0); ++l) for (int k = 0; k < _weights.GetLength(1); ++k) _weights[l, k] = double.Parse(memory_el.ChildNodes.Item(k + _weights.GetLength(1) * l).InnerText.Replace(',', '.'), System.Globalization.CultureInfo.InvariantCulture);//parsing stuff break; case MemoryMode.SET: for (int l = 0; l < numofneurons; ++l) for (int k = 0; k < numofprevneurons + 1; ++k) memory_el.ChildNodes.Item(k + (numofprevneurons + 1) * l).InnerText = Neurons[l].Weights[k].ToString(); break; } memory_doc.Save(System.IO.Path.Combine("Resources", $"{type}_memory.xml")); return _weights; } abstract public void Recognize(Network net, Layer nextLayer);//для прямых проходов abstract public double[] BackwardPass(double[] stuff);//и обратных } }Этот класс занимается инициализацией слоёв сети. С момента написания предыдущей статьи практически не изменился.
HiddenLayer.cs
namespace demoapp.Model { class HiddenLayer : Layer { public HiddenLayer(int non, int nopn, NeuronType nt, string type) : base(non, nopn, nt, type) { } public override void Recognize(Network net, Layer nextLayer) { double[] hidden_out = new double[Neurons.Length]; for (int i = 0; i < Neurons.Length; ++i) hidden_out[i] = Neurons[i].Output; nextLayer.Data = hidden_out; } public override double[] BackwardPass(double[] gr_sums) { double[] gr_sum = new double[numofprevneurons]; for (int j = 0; j < gr_sum.Length; ++j) { double sum = 0; for (int k = 0; k < Neurons.Length; ++k) sum += Neurons[k].Weights[j] * Neurons[k].Derivative * gr_sums[k];//через градиентные суммы и производную gr_sum[j] = sum; } for (int i = 0; i < numofneurons; ++i) for (int n = 0; n < numofprevneurons + 1; ++n) { double deltaw = (n == 0) ? (momentum * lastdeltaweights[i, 0] + learningrate * Neurons[i].Derivative * gr_sums[i]) : (momentum * lastdeltaweights[i, n] + learningrate * Neurons[i].Inputs[n - 1] * Neurons[i].Derivative * gr_sums[i]); lastdeltaweights[i, n] = deltaw; Neurons[i].Weights[n] += deltaw;//коррекция весов } return gr_sum; } } }Относительно предыдущего проекта нововведением является включение момента инерции в коррекцию весов. Также в связи с разницей на единицу размеров массивов входов и весов нейрона, вызванной появлением смещений, написано разделение обновления синапса и смещения через тернарный оператор.
OutputLayer.cs
namespace demoapp.Model { class OutputLayer : Layer { public OutputLayer(int non, int nopn, NeuronType nt, string type) : base(non, nopn, nt, type) { } public override void Recognize(Network net, Layer nextLayer) { double e_sum = 0; for (int i = 0; i < Neurons.Length; ++i) e_sum += Neurons[i].Output; for (int i = 0; i < Neurons.Length; ++i) net.fact[i] = Neurons[i].Output / e_sum; } public override double[] BackwardPass(double[] errors) { double[] gr_sum = new double[numofprevneurons + 1]; for (int j = 0; j < gr_sum.Length; ++j)//вычисление градиентных сумм выходного слоя { double sum = 0; for (int k = 0; k < Neurons.Length; ++k) sum += Neurons[k].Weights[j] * errors[k]; gr_sum[j] = sum; } for (int i = 0; i < numofneurons; ++i) for (int n = 0; n < numofprevneurons + 1; ++n) { double deltaw = (n == 0) ? (momentum * lastdeltaweights[i, 0] + learningrate * errors[i]) : (momentum * lastdeltaweights[i, n] + learningrate * Neurons[i].Inputs[n - 1] * errors[i]); lastdeltaweights[i, n] = deltaw; Neurons[i].Weights[n] += deltaw;//коррекция весов } return gr_sum; } } }Из листинга видно, что softmax считается в методе Recognize, причём достаточно изящно за счёт того, что значения экспоненциальных функций были уже посчитаны в нейронах. Также видно особенность вычисления градиента нейронов, которая заключается в его простоте, так как он равен разнице желаемого отклика и действительного. Это вызвано использованием softmax в качестве функции активации нейронов выходного слоя.
Network.cs
namespace demoapp.Model { class Network { public Network(NetworkMode nm) => input_layer = new InputLayer(nm); //все слои сети private InputLayer input_layer = null; public HiddenLayer hidden_layer1 = new HiddenLayer(70, 15, NeuronType.Hidden, nameof(hidden_layer1)); public HiddenLayer hidden_layer2 = new HiddenLayer(30, 70, NeuronType.Hidden, nameof(hidden_layer2)); public OutputLayer output_layer = new OutputLayer(10, 30, NeuronType.Output, nameof(output_layer)); //массив для хранения выхода сети public double[] fact = new double[10]; //непосредственно обучение public void Train(Network net)//backpropagation method { int epoches = 1200; for (int k = 0; k < epoches; ++k) { for (int i = 0; i < net.input_layer.Trainset.Length; ++i) { //прямой проход ForwardPass(net, net.input_layer.Trainset[i].Item1); //вычисление ошибки по итерации double[] errors = new double[net.fact.Length]; for (int x = 0; x < errors.Length; ++x) { errors[x] = (x == net.input_layer.Trainset[i].Item2) ? -(net.fact[x] - 1.0d) : -net.fact[x]; } //обратный проход и коррекция весов double[] temp_gsums1 = net.output_layer.BackwardPass(errors); double[] temp_gsums2 = net.hidden_layer2.BackwardPass(temp_gsums1); net.hidden_layer1.BackwardPass(temp_gsums2); } } //загрузка скорректированных весов в "память" net.hidden_layer1.WeightInitialize(MemoryMode.SET, nameof(hidden_layer1)); net.hidden_layer2.WeightInitialize(MemoryMode.SET, nameof(hidden_layer2)); net.output_layer.WeightInitialize(MemoryMode.SET, nameof(output_layer)); } //тестирование сети public void Test(Network net) { for (int i = 0; i < net.input_layer.Testset.Length; ++i) ForwardPass(net, net.input_layer.Testset[i]); } public void ForwardPass(Network net, double[] netInput) { net.hidden_layer1.Data = netInput; net.hidden_layer1.Recognize(null, net.hidden_layer2); net.hidden_layer2.Recognize(null, net.output_layer); net.output_layer.Recognize(net, null); } } }Класс — "конструктор" сети, так как собирает все слои воедино и занимается её обучением и тестированием. На этот раз обучение останавливается по достижению финальной эпохи. Кстати, на вход конструктора сети подаётся режим её работы для того, чтобы определить: инициализировать входной слой или нет, так как инициализация не требуется для демонстрационного режима работы.
Собираем все компоненты все вместе
Изначально я тренировал сеть в консольном приложении для отладки некоторых её параметров, затем для демонстрации работы накидал простенькое MVP WinForms приложение с возможностью рисования своей цифры, где использовал полученные веса, записанные в XML. Весь код персептрона для красоты поделил по принципу "один файл == один класс" и поместил в папку Model, отсюда название namespace'a — demoapp.Model. В итоге получил такую няшность:
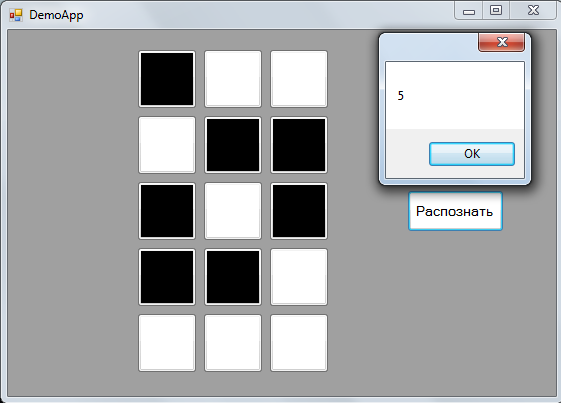
В MessageBox выводится порядковый номер нейрона выходного слоя с максимальным значением выхода следующей строчкой с помощью методов LINQ в компоненте View приложения:
public double[] NetOutput { set => MessageBox.Show(value.ToList().IndexOf(value.Max()).ToString()); }Итог
Сегодня Вы благодаря мне разобрались с ещё одним "Hello World" от мира машинного обучения на самом низком уровне реализации. Это был интересный опыт как для меня, так и, надеюсь, для вас. В следующей статье к этому малышу я прикручу OpenCL, чтоб всё вообще летало! Так что спасибо за внимание! Ждите следующую статью из образовательного цикла "Истинная реализация нейросети с нуля".
P.S.
Для тех, кто хочет больше общения с данным кодом, оставляю ссылку на Github.
P.P.S.
Объявляю конкурс на внимательность читателя. Тот, кто напишет в комментариях какую критическую ошибку я допустил при программировании нейронной сети из прошлой статьи (хоть она и заработала, но то было чистое везение), получит приятную плюшку.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru