10 строк для диагностики болезни Паркинсона при помощи XGBoost
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-04-22 14:00

В статье на примере диагностики болезни Паркинсона рассматривается применение популярной библиотеки машинного обучения XGBoost.
XGBoost (сокращение от EXtreme Gradient Boosting) – популярная библиотека машинного обучения, реализующая модель градиентного бустинга, представляющего альтернативу регрессионным методам и нейронным сетям. Метод заключается в создании ансамбля последовательно уточняющих друг друга деревьев решений. Пример таких деревьев с сайта библиотеки представлен ниже на иллюстрации.
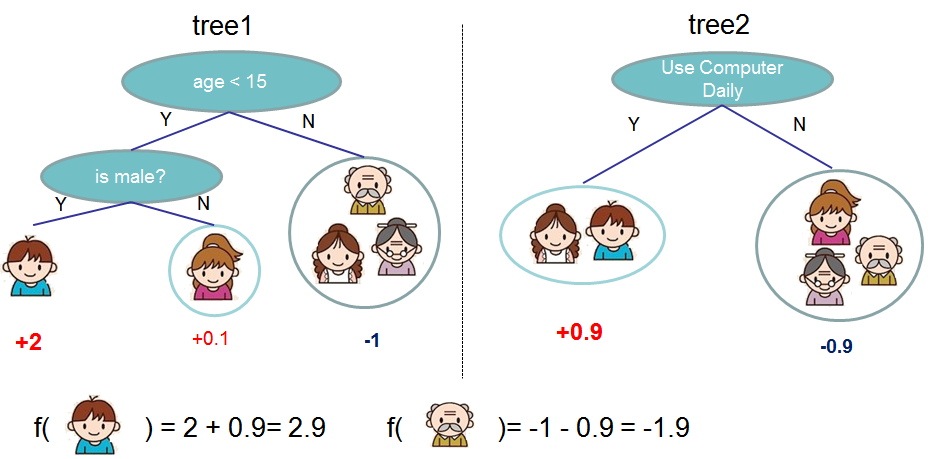
Возьмем задачу с обнаружением болезни Паркинсона: у нас есть несколько показателей, которые мы можем проанализировать, и в конечном итоге диагностировать, есть ли у пациента болезнь, то есть провести классификацию пациентов. Это классическая задача для XGBoost.
Чтение данных
Начнем со сбора данных. Соответствующий датасет для болезни Паркинсона можно найти по ссылке (зеркало на GitHub). Нам нужен файл parkinsons.data. Разметка этого data-файла аналогична CSV, поэтому его легко распарсить при помощи pandas:
Python
| 1 | df=pd.read_csv('parkinsons.data') |
Теперь выделим признаки и метки. Все столбцы в файле числовые, за исключением первого столбца name. Столбец с метками состоит из нулей (отсутствие болезни) и единиц (наличие), соответственно это столбец status:
| 1 2 | features=df.loc[:,df.columns!='status'].values[:,1:] labels=df.loc[:,'status'].values |
Скейлинг данных
Далее необходимо нормировать признаки так, чтобы конечные значения находились в интервале от -1 до 1. Для этого применим MinMaxScaler из библиотеки sklearn:
| 1 2 | scaler=MinMaxScaler((-1,1)) X=scaler.fit_transform(features) |
Разбиение на обучающую и тестовую выборки
Теперь разобьем данные на обучающую и тестовую выборки так, чтобы избежать переобучения. Датасет довольно большой, выделим 14% под тест, используя из библиотеки sklearn функцию train_test_split:
| 1 | X_r,X_s,Y_r,Y_s=train_test_split(X,labels,test_size=0.14) |
Создание и обучение модели XGBoost
Установить библиотеку XGBoost можно стандартным образом при помощи pip install xgboost. Создадим модель классификатора и обучим его на данных обучающей выборки.
| 1 2 | model=XGBClassifier() model.fit(X_r,Y_r) |
Метод быстрый, и обучение модели займет не больше нескольких секунд.
Оценка результата моделирования
Для оценки результата воспользуемся функцией accuracy_score:
| 1 2 | Y_hat=[round(yhat)foryhat inmodel.predict(X_test)] print(accuracy_score(Y_test,Y_hat)) |
Точность предсказания на тестовой выборке оказывается весьма высокой, выше 95%. Это хороший результат: в оригинальной публикации 2007 года точность классификации составила 91.8 ± 2.0%, а в работах 2016 года 96.4% при использовании метода опорных векторов и 97% в настроенной модели ускоренной логистической регрессии.
Посмотреть полный код и поиграть с данными можно в Jupyter-блокноте Train.ipynb здесь. Если вы хотите лучше разобраться в деталях реализации XGBoost, ознакомьтесь с этой публикацией.
Телеграм: t.me/ainewsline
Источник: proglib.io