Взгляд на основные тенденции в машинном обучении
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-03-24 13:00

Разбираемся, как за последние 5 лет изменились технологии и подходы к работе в машинном обучении на примере исследования Andrej Karpathy.
Руководитель отдела машинного обучения в Tesla, Andrej Karpathy, решил выяснить, как развиваются тенденции ML в последние годы. Для этого он воспользовался базой данных документов о машинном обучении за последние пять лет (около 28 тысяч) и проанализировал их. Своими выводами Андрей поделился на Medium.
Особенности архива документов
Рассмотрим для начала распределение общего числа загруженных документов по всем категориям (cs.AI, cs.LG, cs.CV, cs.CL, cs.NE, stat.ML) в течение времени. Мы получим следующее:
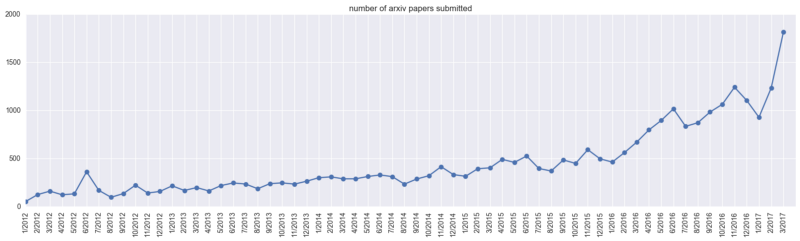
Видно, что в марте 2017 было загружено почти 2000 документов. Пики, которые появляются на графике, вероятно, обусловлены датами конференций, связанных с машинным обучением (NIPS/ICML, например).
Общее число бумаг послужит знаменателем. Мы можем посмотреть, какая часть документов содержит интересные нам ключевые слова.
Основы глубокого обучения
Для начала определим наиболее часто используемые в Deep Learning фреймворки. Для этого найдем бумаги, которые содержат упоминания о фреймворках в любом месте работы (даже если это список используемой литературы).
Для марта 2017 получается следующая картина:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | %ofpapersframeworkhasbeenaroundfor(months) ------------------------------------------------------------ 9.1tensorflow16 7.1caffe37 4.6theano54 3.3torch37 2.5keras19 1.7matconvnet26 1.2lasagne23 0.5chainer16 0.3mxnet17 0.3cntk13 0.2pytorch1 0.1deeplearning4j14 |
Таким образом, 10% всех документов, загруженных в этот период содержат упоминания TensorFlow. Конечно, не в каждой статье будет упоминаться используемое окружение, но если предположить, что в документах такие упоминания встречается с некоторой фиксированной вероятностью, получится, что около 40% членов сообщества машинного обучения использует TensorFlow.
А вот картина того, как некоторые из наиболее популярных фреймворков эволюционировали с течением времени:
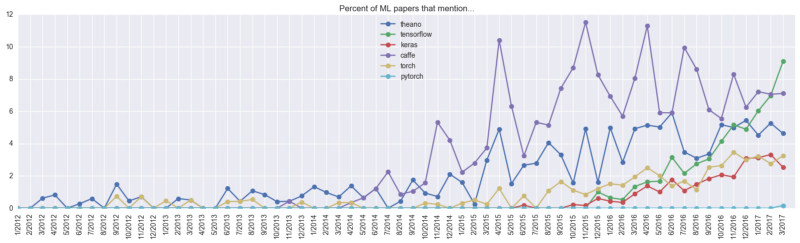
Можно заметить, что рост популярности Theano замедлился. Caffe быстро взлетел в 2014 году, но уступил в последние годы по популярности TensorFlow. Torch и PyTorch медленно, но верно набирают популярность.
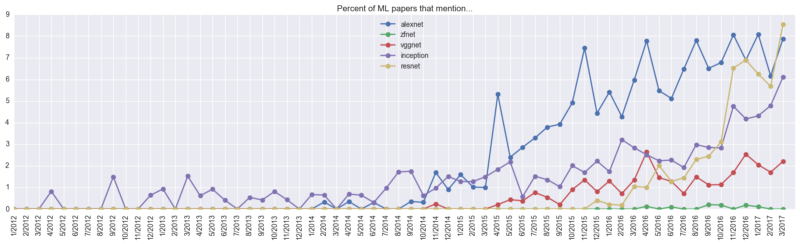
Модели ConvNet
В этой категории можно видеть всплеск интереса к ResNets (остаточным сетям) – упоминания о них встречаются в 9% всех документов:
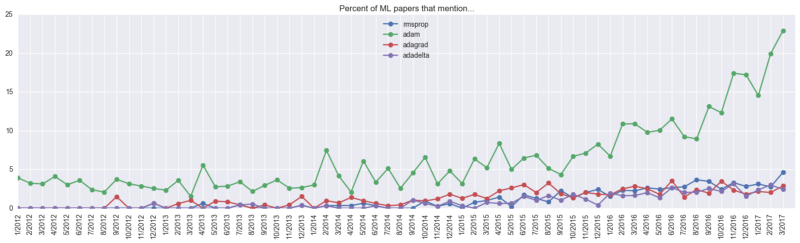
Алгоритмы оптимизации
Среди алгоритмов оптимизации Adam занимает внушительную долю в 23%. Фактическую долю алгоритма трудно определить, но, вероятно, она выше 23 процентов: не во всех документах упоминаются используемые алгоритмы оптимизации. Автор исследования полагает, что не упомянутая активность алгоритма составляет приблизительно 5% дополнительно.
Исследователи
Также любопытно взглянуть на упоминания имен известных исследователей в машинном обучении:
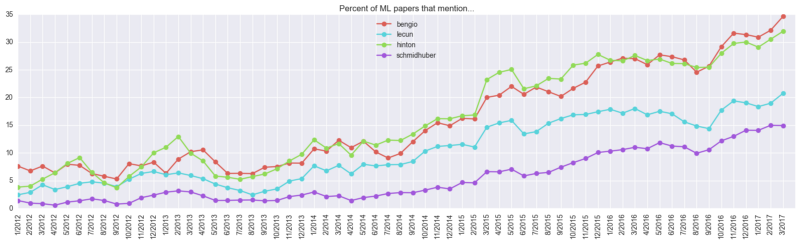
Несколько замечаний: фамилия Bengio упоминается в 35% всех документов, но есть два человека с этой фамилией (Samy и Yoshua). А вот Джефф Хинтон – один, и он упоминается в целых 30% работ.
Популярные и непопулярные ключевые слова в машинном обучении
Наконец, рассмотрим самые «горячие» и самые непопулярные слова, встречающиеся в исследованиях машинного обучения.
Топ популярных
Для определения популярности слова автор использовал отношение максимального количества использования этого слова в прошлом году к количеству его упоминаний до 2016 года. Таким образом, получается список наиболее горячих слов:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | 8.17394726486resnet 6.76767676768tensorflow 5.21818181818gans 5.0098386462residual networks 4.34787878788adam 2.95181818182batch normalization 2.61663993305fcn 2.47812783318vgg16 2.03636363636style transfer 1.99958217686gated 1.99057177616deep reinforcement 1.98428686543lstm 1.93700787402nmt 1.90606060606inception 1.8962962963siamese 1.88976377953character level 1.87533998187region proposal 1.81670721817distillation 1.81400378481tree search 1.78578069795torch 1.77685950413policy gradient 1.77370153867encoder decoder 1.74685427385gru 1.72430399325word2vec 1.71884293052relu activation 1.71459655485visual question 1.70471560525image generation |
Видно, что хотя до 2016 года упоминания ResNet составляли всего 1,044 процента от всех документов, в марте 2017 его доля составила 8,53 процента. Отсюда такая высокая позиция (8.53 / 1.044 ~ = 8.17). Топ показывает, что основные новинки пользуются популярностью у исследователей.
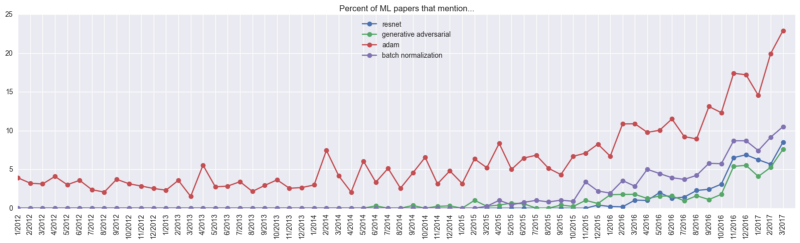
Топ непопулярных
Давайте взглянем на обратный топ. Что в прошлом году использовалось меньше всего:
1 2 3 4 5 6 7 8 | 0.0462375339982fractal 0.112222705524learning bayesian 0.123531424661ibp 0.138351983723texture analysis 0.152810895084bayesian network 0.170535340862differential evolution 0.227932960894wavelet transform 0.24482875551dirichlet process |
Автор отмечает, что не совсем понятно в каком контексте используется «фрактал» – по всей видимости, имеется в виду байесовская оценка решения.
Больше материалов по machine learning:
Телеграм: t.me/ainewsline
Источник: proglib.io