Про вероятности
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-03-19 13:49

(source)
Иногда мне приходится рассказывать другим людям как работает машинное обучение и, в частности, нейронные сети. Обычно я начинаю с градиентного спуска и линейной регрессии, постепенно переходя к многослойным перцептронам, автокодировщикам и свёрточным сетям. Все понимающе кивают головой, но в какой-то момент кто-нибудь прозорливый обязательно спрашивает:
А почему так важно, чтобы переменные в линейной регрессии были независимы?
или
А почему для изображений используются именно свёрточные сети, а не обычные полносвязные?
"О, это просто", — хочу ответить я. — "потому что если бы переменные были зависимыми, то нам пришлось бы моделировать условное распределение вероятностей между ними" или "потому что в небольшой локальной области гораздо проще выучить совместное распределение пикселей". Но вот проблема: мои слушатели ещё ничего не знают про распределения вероятностей и случайные переменные, поэтому приходится выкручиваться другими способами, объясняя сложнее, но с меньшим количеством понятий и терминов. А что делать, если попросят рассказать про батч нормализацию или генеративные модели, так вообще ума не приложу.
Так давайте не будем мучить себя и других и просто вспомним основные понятия теории вероятностей.
Случайные переменные
Представим, что у нас есть анкеты людей, где указаны их возраст, рост, пол и количество детей:
| age | height | gender | children |
|---|---|---|---|
| 32 | 175 | 1 | 2 |
| 28 | 180 | 1 | 1 |
| 17 | 164 | 0 | 0 |
| ... | ... | .... | .... |
Каждая строчка в такой таблице — это объект. Каждая ячейка — значение переменной, характеризующей этот объект. Например, возраст первого человека — 32 года, а рост второго — 180см. А что, если мы хотим описать некоторую переменную сразу для всех наших объектов, т.е. взять целую колонку? В этом случае у нас будет не одно конкретное значение, а сразу несколько, каждое со своей частотой встречаемости. Список возможных значений + соответсвующая вероятность и называется случайной переменной (random variable, r.v.).
Дискретные и непрерывные случайные переменные
Чтобы это отложилось в голове, я повторю ещё раз: случайная переменная полностью задаётся распределением вероятностей своих значений. Есть 2 основных типа случайных переменных: дискретные (discrete) и непрерывные (continuous).
Дискретные переменные имеют конечное множество чётко разделимых значений. Обычно я изображаю их как-нибудь так (probability mass function, pmf):
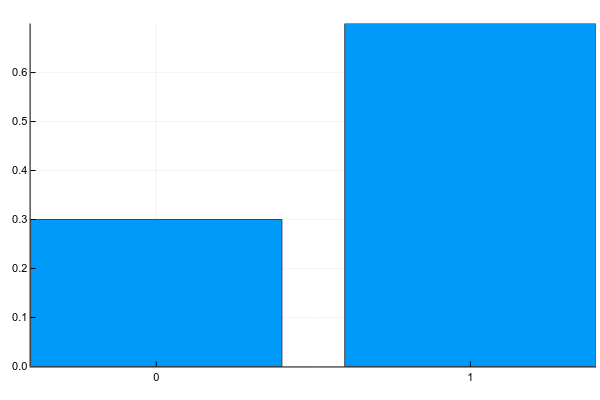
Pkg.add("Plots") using Plots plotly() plot(["0","1"], [0.3, 0.7], linetype=:bar, legend=false)А текстом это обычно записывается так (g — gender):
Т.е. вероятность того, что случайно взятый человек из нашей выборки окажется женщиной () равна 0.3, а мужчиной () — 0.7, что эквивалентно тому, что в выборке было 30% женщин и 70% мужчин.
К дискретным же переменным относятся количество детей у человека, частота встречаемости слов в тексте, количество просмотров фильма и т.д. Результат классификации на конечное число классов, кстати, — это тоже дискретная случайная переменная.
Непрерывные переменные могут принимать любое значение в определённом интервале. Например, даже если мы записываем, что рост человека — 175см, т.е. округляем до 1 сантиметра, на самом деле он может быть 175.8231см. Изображают непрерывные переменные обычно с помощью кривой плотоности вероятности (probability density function, pdf):
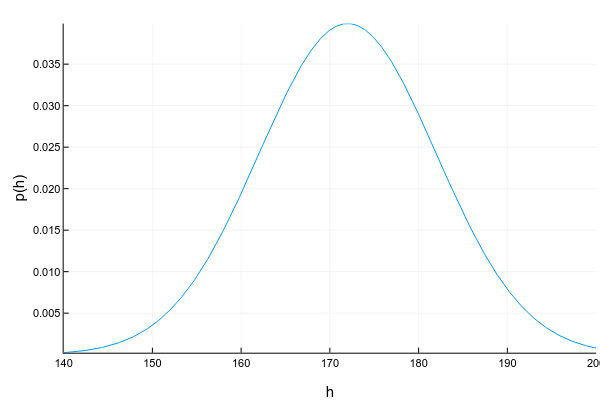
Pkg.add("Distributions") using Distributions xs = 140:0.1:200 ys = [pdf(Normal(172, 10), x) for x in xs] plot(xs, ys; xlabel="h", ylabel="p(h)", legend=false, show=true)График плотности вероятности — штука хитрая: в отличие от графика массы вероятности для дискретных переменных, где высота каждой колонки показывает непосредственно вероятность получить такое значение, плотность вероятности показывает относительное количество вероятности вокруг некоторой точки. Саму же вероятность в этом случае можно посчитать только для интервала. Например, в этом примере вероятность, что случайно взятый человек из нашей выборки будет иметь рост от 160 до 170см равна примерно 0.3.
d = Normal(172, 10) prob = cdf(d, 170) - cdf(d, 160)Вопрос: может ли плотность вероятности в какой-то точке быть больше единицы? Ответ — да, конечно, главное, чтобы общая площадь под графиком (или, говоря математически, интеграл плотности вероятности) был равен единице.
Ещё одна трудность с непрерывными переменными состоит в том, что их плотность вероятности не всегда возможно красиво описать. Для дискретных переменных у нас просто была таблица значение -> вероятность. Для непрерывных это уже не прокатит, поскольку значений у них, вообще говоря, бесконечное множество. Поэтому обычно стараются аппроксимировать набор данных каким-нибудь хорошо изученным параметрическим распределением. Например, график выше — это пример т.н. нормального распределения. Плотность вероятности для него задаётся формулой:
где (мат. ожидание, mean) и (дисперсия, variance) — параметры распределения. Т.е. имея всего 2 числа мы можем полностью описать распределение, посчитать его плотность вероятности в любой точке или суммарную веростность между двумя значениями. К сожалению, далеко не для любого набора данных найдётся распределение, которое сможет его красиво описать. Есть много способов бороться с этим (взять хотя бы смесь нормальных распределений), но это уже совсем другая тема.
Другие примеры непрерывного распределения: возраст человека, интенсивность пикселя на изображении, время ответа от сервера и т.д.
Совместное, маргинальное и условное распределения
Обычно мы рассматриваем свойства объекта не по одному, а в комбинации с другими, и здесь появляется понятие совместного распределения (joint probability) нескольких переменных. Для двух дискретных переменных мы можем изобразить его в виде таблицы (g — gender, c — # of children):
| c=0 | c=1 | c=2 | |
|---|---|---|---|
| g=0 | 0.1 | 0.1 | 0.1 |
| g=1 | 0.2 | 0.4 | 0.1 |
Согласно этому распределению, вероятность встретить в нашем наборе данных женщину с 2-мя детьми равна , а бездетного мужчину — .
Для двух непрерывных переменных, например, роста и возраста, нам снова придётся задать аналитическую функцию распределения , аппроксимировав его,
например, многомерным нормальным. Таблицей это не запишешь, зато можно нарисовать:
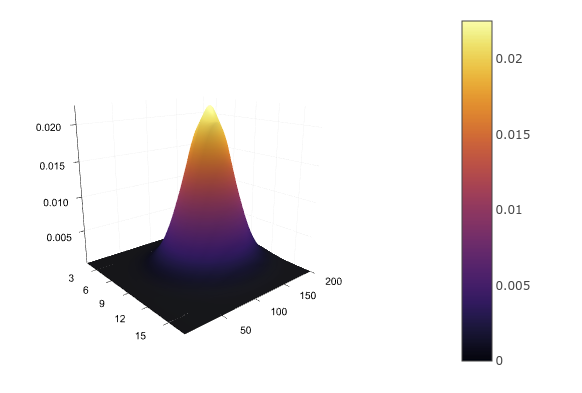
d = MvNormal([172.0, 30.0], [10 0; 0 5]) xs = 160:0.1:180 ys = 22:1:38 zs = [pdf(d, [x, y]) for x in xs, y in ys] surface(zs)Имея совместное распределение, мы можем найти распределение каждой переменной по отдельности, просто суммировав (в случае дискретных) или интегрировав (в случае непрерывных) остальные переменные:
Это можно представить в виде суммирования по каждой строке или столбцу таблицы и вынесением результат на поля таблицы:
| c=0 | c=1 | c=2 | ||
|---|---|---|---|---|
| g=0 | 0.1 | 0.1 | 0.1 | 0.3 |
| g=1 | 0.2 | 0.4 | 0.1 | 0.7 |
Так мы снова получаем и . Процесс вынесения на поля (margin) даёт название и самому получившемуся распределению — маргинальное (marginal probability).
А что, если мы уже знаем значение одной из переменных? Например, мы видим, что перед нами мужчина и хотим получить распределение вероятностей количества его детей? Таблица совместной вероятности и тут нам поможет: поскольку мы уже точно знаем, что перед нами мужчина, т.е. , мы можем выбросить из рассмотрения все остальные варианты и рассматривать только одну строчку:
| c=0 | c=1 | c=2 | |
|---|---|---|---|
| g=1 | 0.2 | 0.4 | 0.1 |
Поскольку вероятности так или иначе должны суммироваться в единицу, получившиеся значения нужно нормализовать, после чего получится:
Распределение одной переменной при известном значении другой называется условным (conditional probability).
Правило цепи
А соединяются все эти вероятности одной просто формулой, которая называется правилом цепи (chain rule, не путать с правилом цепи в дифференцировании):
Формула эта симметричная, поэтому так тоже можно:
Интерпретация правила очень простая: если — вероятность того, что я пойду на красный свет, а — вероятность того, что человек, переходящий на красный свет, будет сбит, то совместная вероятность пойти на красный свет и быть сбитым как раз и равна произведению вероятностей этих двух событий. Но вообще лучше ходите на зелёный.
Зависимые и независимые переменные
Как уже говорилось, если у нас есть таблица совместного распределения, то мы знаем про систему всё: можно вычислить маргинальную веростность любой переменной, можно условное распределение одной переменной при известной другой и т.д. К сожалению, на практике составить такую таблицу (или просчитать параметры непрерывного распределения) в большинстве случаев невозможно. Например, если мы захотим посчитать совместное распределение встречаемости 1000 слов, то нам понадобится таблица из
107150860718626732094842504906000181056140481170553360744375038837035105112493612
249319837881569585812759467291755314682518714528569231404359845775746985748039345
677748242309854210746050623711418779541821530464749835819412673987675591655439460
77062914571196477686542167660429831652624386837205668069376
(чуть больше 1e301) ячеек. Для сравнения, количество атомов в наблюдаемой вселенной равно примерно 1e81. Пожалуй, покупкой дополнительной планки памяти тут не обойдёшься.
Но есть одна приятная деталь: не все переменные зависят друг от друга. Вероятность того, пойдёт ли завтра дождь, вряд ли зависит от того, перехожу ли я дорогу на красный свет. Для независимых переменных условное распределение одной от другой равно просто маргинальному распределению:
По-честному, совместная вероятность 1000 слов записывается так:
А вот если мы "наивно" предположим, что слова не зависят друг от друга, то формула превратится в:
А чтобы сохранить вероятности для 1000 слов нужна таблица всего с 1000 ячеек, что вполне приемлемо.
Почему тогда не считать все переменные независимыми? Увы, так мы потеряем массу информации. Представим, что мы хотим посчитать вероятность того, что пациент болен гриппом в зависимости от двух переменных: боли в горле и повышенной температуры. Отдельно боль в горле может говорить как о болезни, так и том, что пациент только что громко пел. Отдельно повышенная температура может говорить как о болезни, так и о том, что человек только что вернулся с пробежки. А вот если мы одновременно наблюдаем и температуру, и боль в горле, то это уже серьёзная причина выписать пациенту больничный.
Логарифм
Очень часто в литературе можно увидеть, что используется не просто вероятность, а её логарифм. Зачем? Всё довольно прозаично:
- Логарифм — монотонно возрастающая функция, т.е. для любых и если , то и .
- Логарифм произведения равен сумме логарифмов: .
В примере со словами вероятность встретить любое слово , как правило, сильно меньше единицы. Если мы попробуем перемножить много маленьких вероятностей на компьютере с органиченной точностью вычислений, догадываетесь что будет? Ага, очень быстро наши вероятности округляться к нулю. А вот если мы сложим много отдельных логарифмов, то выйти за пределы точности вычислений будет практически невозможно.
Условная вероятность как функция
Если после всех этих примеров у вас сложилось впечатление, что условная вероятность всегда вычисляется подсчётом количества раз, которое встретилось некоторое значение, то спешу развеять это заблуждение: в общем случае условная вероятность — это некоторая функция одной случайной переменной от другой:
где — это некоторый шум. Виды шума — это тоже отдельная тема, в которую мы сейчас влезать не будем, а вот на функции остановимся поподробней. В примерах с дискретными переменными выше в качестве функции мы использовали простой подсчёт встречаемости. Это само по себе хорошо работает во многих случаях, например, в наивном байесовском классификаторе для текста или поведения пользователей. Чуть более сложная модель — линейная регрессия:
Здесь тоже делается предположение о том, что переменные независимы друг от друга, но распределение уже моделируется с помощью линейной функции, параметры которой нужно найти.
Многослойный перцептрон — это тоже функция, но благодаря промежуточным слоям, на которые влияют все входные переменные сразу, MLP позволяет моделировать зависимость выходной переменной от комбинации входных, а не только от каждой из них по отдельности (вспомните пример с болью в горле и температурой).
Свёрточная сеть работает с распределением пикселей в локальной области, покрываемой размером фильтра. Рекуррентные сети моделируют условное распределение следующего состояния от предыдущего и входных данных, а также выходной переменной от текущего состояния. Ну, в общем, вы поняли идею.
Теорема Байеса и умножение непрерывных переменных
Помните правило сети?
Если убрать левую часть, то получим простое и очевидное равенство:
А если теперь перенесём направо, то получим знаменитую формулу Байеса:
Итересный факт: русское произношение "байес" в английском звучит как слово "bias", т.е. "смещение". А вот фамилия учёного "Bayes" читается как "бэйс" или "бэйес" (лучше послушать в Yandex Translate).
Формула настолько избитая, что каждая её часть имеет своё название:
- называется априорным распределением (prior). Это то, что мы знаем ещё до того, как увидели конкретный объект, например, общее количество людей, вовремя выплативших кредит.
- носит название правдоподобия (likelihood). Это вероятность увидеть такой объект (описанный переменной ) при таком значении выходной переменной . Например, вероятность того, что у человека, отдавшего кредит, двое детей.
- — маргинальное правдоподобие, вероятность вообще увидеть такой объект. Оно одинаково для всех , так что его чаще всего не считают, а просто максимизируют числитель формулы Байеса.
- — апостериорное распределение (posterior). Это распределение вероятностей переменной после того, как мы увидели объект. Например, вероятность того, что человек с двумя детьми отдаст кредит вовремя.
Байесовская статистика — штука жутко интересная, но влезать в неё сейчас мы не будем. Единственный вопрос, который хотелось бы затронуть, — это перемножение двух распределений непрерывных переменных, которое у нас встречается, например, в числителе формулы Байеса, да и вообще в каждой второй формуле над непрерывными переменными.
Допустим, что у нас есть два распределения и :
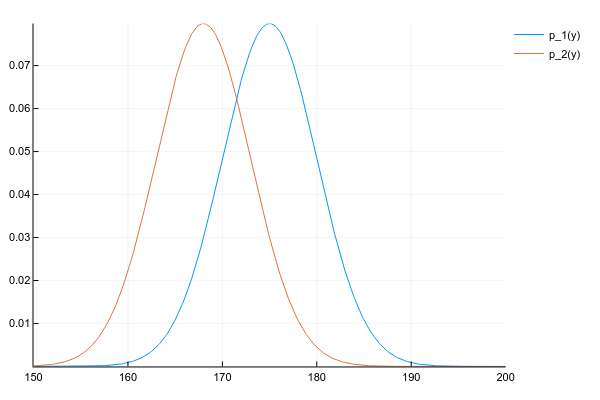
d1 = Normal(175, 5) d2 = Normal(168, 5) space = 150:0.1:200 y1 = [pdf(d1, y) for y in space] y2 = [pdf(d2, y) for y in space] plot(space, y1, label="p_1(y)") plot!(space, y2, label="p_2(y)")И мы хотим получить их произведение:
Мы знаем плотность вероятности обоих распределений в каждой точке, поэтому, по-честному и в общем случае, нам нужно перемножить плотности в каждой точке. Но, если мы вели себя хорошо, то и у нас заданы параметрами, например, для нормального распределения 2-мя числами — матожиданием и дисперсией, а для их произведения придётся считать вероятность в каждой точке?
К счастью, произведение многих известных распределений даёт другое известное распределение с легко вычислимыми параметрами. Ключевое слово здесь — conjugate prior.
Как бы мы не вычисляли, произведение двух нормальных распределений даёт ещё одно нормальное распределение (правда, ненормализованное):
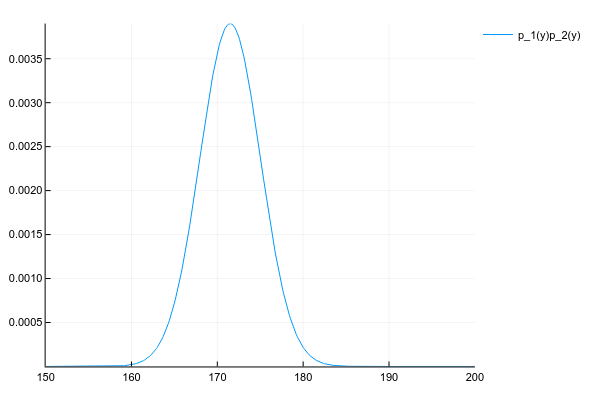
# честно перемножаем плотности вероятности в каждой точке # неэффективно, но работает для любых распределений plot(space, y1 .* y2, label="p_1(y)p_2(y)")Ну и просто для сравнения распределение смеси 3х нормальных распределений:

plot(space, [pdf(Normal(130, 5), x) for x in space] .+ [pdf(Normal(150, 20), x) for x in space] .+ [pdf(Normal(190, 3), x) for x in space])Вопросы
Раз уж это туториал и кто-нибудь наверняка захочет запомнить то, что здесь было написано, вот несколько вопросов для закрепления материала.
Пусть рост человека — нормально распределённая случайная переменная с параметрами и . Какова вероятность встретить человека ростом ровно 178см?
Правильными ответами можно считать "0", "бесконечно мала" или "не определена". А всё потому что вероятность непрерывной переменной считается на некотором интервале. Для точки интервал — это её ширина, в зависимости от того, где вы учили математику, длину точки можно считать нулём, бесконечно малой или вообще не определённой.
Пусть — количество детей у заёмщика кредита (3 возможными значения), — признак того, отдал ли человек кредит (2 возможных значения). Мы используем формулу Байеса для предсказания, отдаст ли конкретный клиент с 1 ребёнком кредит. Сколько возможных значений может принимать априорное и апостериорное распределения, а также правдоподобие и маргинальное правдоподобие?
Таблица совместного распредления двух переменных в данном случае небольшая и имеет вид:
| c=0 | c=1 | c=2 | |
|---|---|---|---|
| s=0 | p(s=0,c=0) | p(s=0,c=1) | p(s=0,c=2) |
| s=1 | p(s=1,c=0) | p(s=1,c=1) | p(s=1,c=2) |
где — признак успешно отданного кредита.
Формула Байеса в данном случае имеет вид:
Если все значения известны, то:
- — это маргинальная вероятность увидеть человека с одним ребёнком, считается как сумма по колонке и является просто числом.
- — априорная/маргинальная вероятность того, что случайно взятый человек, про которого мы ничего не знаем, отдаст кредит. Может иметь 2 значения, соответствующих сумме по первой и по второй строке таблицы.
- — правдоподобие, условное распределение количества детей в зависимости от успешности кредита. Может показаться, что раз уж это распределение количества детей, то возможных значений должно быть 3, но это не так: мы уже точно знаем, что к нам пришёл человек с одним ребёнком, поэтому рассматриваем только одну колонку таблицы. А вот успешность кредита пока под вопросом, поэтому возможны 2 варианта — 2 строки таблицы.
- — апостериорное распределение, где мы знаем , но рассматриваем 2 возможных варианта .
Нейронные сети, оптимизирующие расстояние между двумя расспределениями и , зачастую используют в качестве оптимизационной цели кросс-энтропию (cross entropy) или расстояние Кульбака-Лейблера (Kullback-Leibler divergence). Последнее определяется как:
— это мат. ожидание по , а почему в основной части — — используется деление, а не просто разница между плотностями двух функций ?
Другими словами, это и есть разница между плотностями, но в логарифмическом пространстве, которе является вычислительно более стабильным.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru