Небольшая библиотека для применения ИИ в Telegram чат-ботах
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-03-19 09:55
Добрый день! На волне всеобщего интереса к чат-ботам в частности и системам диалогового интеллекта вообще я какое-то время занимался связанными с этой темой проектами. Сегодня я хотел бы выложить в опенсорс одну из написанных библиотек. Оговорюсь, что в первую очередь я специализируюсь на алгоритмических аспектах разработки и поэтому буду рад конструктивной критике решений кодерского характера от более сведущих в этом вопросе специалистов.
 Библиотека посвящена построению интерфейса между алгоритмом, возвращающим ответ на текстовый запрос и API мессенджера Telegram. Предназначена для гибкого применения алгоритмов машинного обучения. Кстати, если более сведущие, чем я, специалисты могут предложить удачный вариант, унифицирующий интерфейсы различных возможных каналов связи (мессенджеры, веб-виджеты и т. д.) с единой точкой входа в функцию ответа, буду рад обсудить его в комментариях. Лично мне, в свое время, пришлось воспользоваться модулем самостоятельно написанным на Flask и дававшим доступ к алгоритму посредством http-запросов. Для взаимодействия с каждым пользовательским интерфейсом (Telegram, Facebook и т д) приходилось писать отдельную программу, занимавшуюся связью с ним, переводом запроса в унифицированный формат, понятный написанному на Flask API, и, наконец, переводом полученного ответа обратно в формат, понятный пользовательскому интерфейсу. Такая конструкция выглядит несколько неуклюже, так что, повторюсь, буду рад в комментариях обсудить этот вопрос с более опытными в данной теме коллегами.
Библиотека посвящена построению интерфейса между алгоритмом, возвращающим ответ на текстовый запрос и API мессенджера Telegram. Предназначена для гибкого применения алгоритмов машинного обучения. Кстати, если более сведущие, чем я, специалисты могут предложить удачный вариант, унифицирующий интерфейсы различных возможных каналов связи (мессенджеры, веб-виджеты и т. д.) с единой точкой входа в функцию ответа, буду рад обсудить его в комментариях. Лично мне, в свое время, пришлось воспользоваться модулем самостоятельно написанным на Flask и дававшим доступ к алгоритму посредством http-запросов. Для взаимодействия с каждым пользовательским интерфейсом (Telegram, Facebook и т д) приходилось писать отдельную программу, занимавшуюся связью с ним, переводом запроса в унифицированный формат, понятный написанному на Flask API, и, наконец, переводом полученного ответа обратно в формат, понятный пользовательскому интерфейсу. Такая конструкция выглядит несколько неуклюже, так что, повторюсь, буду рад в комментариях обсудить этот вопрос с более опытными в данной теме коллегами.
Основная функция, вызываемая извне при запуске библиотеки —
Генерация мета-модели и конечного ответа разнесены в две разные функции из соображений большего удобства настройки, валидации и тестирования мета-модели и в то же время простоты написания и тестирования по сути UX части, занимающейся переводом выходного значения мета-модели в удобный для восприятия пользователем формат.
Основная функция, вызываемая из скрипта, использующего библиотеку. Подгружает кеш-файл, запускает в параллельном потоке функцию, обновляющую данные, опрашивает и отправляет ответ в Telegram и сервис, занимающийся мониторингом состояния бота.
Получает последнее сообщения от пользователя бота.
Обрабатывает полученное сообщение и конвертирует в вид, удобный для дальнейшей обработки.
Функция, отвечающая за отправку сообщения в чат Telegram. По историческим причинам ключевой аргумент message может иметь тип str (для простых единичных сообщений), list (для цепочек сообщений) или dict (для сообщений, содержащих встроенную клавиатуру).
Функция, отвечающая за логирование диалога.
Функция генерирующая по данным о сообщении, номеру чата, токену и разметке ответа (как правило, содержащем информацию о встроенной клавиатуре) запрос к Telegram API.
Обновляет данные из сторонних источников
Обновляет содержимое кеш-файла. Полезна на случай, если при очередном запуске программы (например после креша или при деплое новой версии) сервис с данными недоступен.
Проверяет, не пора ли обновить данные со сторонних API.
Функция, запускаемая в параллельном потоке и занимающаяся обновлением данных сторонних API. Пришлось вспомнить основы многопоточного программирования, так как некоторые API могут отвечать на запрос в течении десятков секунд и на это время основная программа подвисала и не отвечала на запросы пользователей.
Библиотека предназначена в первую очередь для взаимодействия с алгоритмами машинного обучения, однако их обсуждение выходит далеко за рамки этой статьи. Для того, чтобы показать как она работет, напишем две простых функции и используем их в качестве генератора примера модели и интерпретатора вывода.
Пример скрипта, использующего библиотеку.
Токен для авторизации бота в Telegram. Его нужно заменить на выданный BotFather-ом для конкретного бота.
Токен для оповещения скрипта, контролирующего, что бот работает. Можно заменить случайной строкой если эта функция не нужна.
Тривиальная замена класса, отвечающего за логику обработки входящих сообщений. Когда-нибудь тут случится сложный ИИ, но, увы, пока нет. По крайней мере не в этой статье. А желающие почитать о том, как быстро написать алгоритм машинного обучения и выкатить его в продакшн могут сделать это тут
Функция, генерирующая модель.
Функция, отвечающая за логику формирования ответа по результату применения модели. В нашем простом примере ответ однозначно соответствует одному из возможных смыслов сообщений пользователя, указанных в функции predict() класса HelloWorldMetaModel.
Пример функции, привлекающей внешние изменяющиеся данные.
Пример работы (картинка кликабельна):
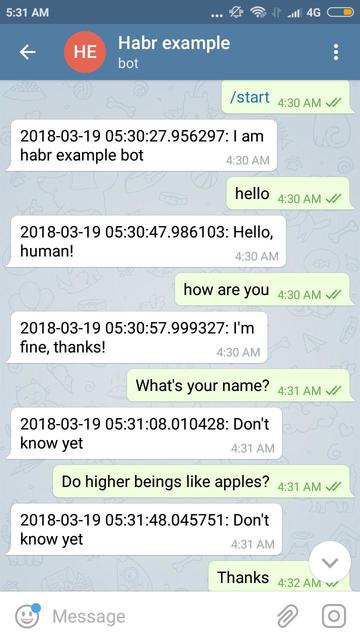
Код на гитхабе тут.
Код на битбакете здесь.
Запускать просто через
Глоссарий
(Обученная) модель машинного обучения — функция, берущая на вход массив чисел фиксированной длины (для математиков — точку в n-мерном пространстве) и возвращающая идентификатор класса (при решении задачи классификации) или число (при решении задачи регрессии).
[1] Мета-модель — обобщение понятия модели машинного обучения. Отличается тем, что принимает на вход объект произвольной природы (напр. массив кодирующий картинку, строку, описание пользователя веб-сайта и т д) и дает на выход объект произвольной природы (как правило идентификатор класса, число, словарь или строку). Абстракция полезна для инкапсуляции пайплайна машинного обучения, как правило включающего в себя препроцессинг, применение модели и постпроцессинг в единую сущность (терминология автора).
Основная функция, вызываемая извне при запуске библиотеки —
main_loop_webhooks(), принимает на вход функцию генерирующую мета-модель [1], функцию генерирующую ответ по результату применения модели, настройки обновлений (например, регулярных обновлений прогноза погоды или цен на те или иные товары), списка ресурсов в определенном формате (в настоящее время используется для отправления ответов в Telegram и регулярного оповещения внешнего скрипта о том, что бот функционирует и не упал).Генерация мета-модели и конечного ответа разнесены в две разные функции из соображений большего удобства настройки, валидации и тестирования мета-модели и в то же время простоты написания и тестирования по сути UX части, занимающейся переводом выходного значения мета-модели в удобный для восприятия пользователем формат.
Скрытый текст
Кратко обсудим функции, содержащиеся в библиотеке. # Author: Andrei Grinenko <andrey.grinenko@gmail.com> # License: BSD 3 clause import os import json import time import urllib.request import urllib.parse import threading import traceback import datetime def get_safe_response_data(url): try: response = urllib.request.urlopen(url, timeout=1) response_data = json.loads(response.read()) return response_data except KeyboardInterrupt: raise except: time.sleep(3) return {} def clear_updates(token, offset): urllib.request.urlopen('https://api.telegram.org/bot' + token + '/getupdates?offset=' + str(offset + 1)) def write_message(message, chat_id, token): if type(message) == str: http_request = to_request(message, chat_id, token) response = urllib.request.urlopen(http_request) # including keyboard, new format elif type(message) == dict: text = message['text'] reply_markup = message['reply_markup'] http_request = to_request(text, chat_id, token, reply_markup) response = urllib.request.urlopen(http_request) # type(mesage) == list else: for str_message in message: write_message(str_message, chat_id, token) def write_log(**kwargs): file_name = kwargs.get('file_name', './data/log.txt') current_datetime = datetime.datetime.now() kwargs.update({'current_datetime': current_datetime}) with open(file_name, 'a') as output_stream: try: output_stream.write(to_beautified_log_line(**kwargs)) except: print(kwargs) print(traceback.print_exc()) output_stream.write(to_simple_log_line(**kwargs)) def to_request(message, chat_id, token, reply_markup={}): message_ = urllib.parse.quote(message) return ('https://api.telegram.org/bot' + token + '/sendmessage?' + 'chat_id=' + str(chat_id) + '&parse_mode=Markdown' + '&text=' + message_ + '&reply_markup=' + json.dumps(reply_markup)) def to_request_old(message, chat_id, token, reply_markup={}): return to_request(message, chat_id, token, reply_markup) def get_last_message_data(token): try: response = urllib.request.urlopen('https://api.telegram.org/bot' + token + '/getupdates') text_response = response.read().decode('utf-8') json_response = json.loads(text_response) return json_response except KeyboardInterrupt: raise except: traceback.print_exc() time.sleep(3) return None def update_data(updates_settings): result = dict() for key in updates_settings['data']: result[key] = updates_settings['data'][key]() return result # Updates cash file with new data just obtained from sources def update_cash_file(new_data, cash_file_name): """ new_data: dict of dicts and values """ if os.path.isfile(cash_file_name): with open(cash_file_name) as input_stream: cash_file_data = json.loads(input_stream.read()) else: cash_file_data = {} for key in new_data: if type(new_data[key]) == dict: if not key in cash_file_data: cash_file_data[key] = dict() for subkey in new_data[key]: cash_file_data[key][subkey] = new_data[key][subkey] else: cash_file_data[key] = new_data[key] with open(cash_file_name, 'w') as output_stream: output_stream.write(json.dumps(cash_file_data)) def to_simple_log_line(**kwargs): channel = kwargs.get('channel', None) chat_id = kwargs.get('chat_id', None) message_text = kwargs['message_text'] username = kwargs.get('username', None) first_name = kwargs.get('first_name', None) last_name = kwargs.get('last_name', None) response = kwargs['response'] current_datetime = kwargs.get('current_datetime', None) datetime_output = (str(current_datetime.year) + '-' + str(current_datetime.month) + '-' + str(current_datetime.day) + '/' + str(current_datetime.hour) + ':' + str(current_datetime.minute)) output_data = {'datetime':datetime_output, 'channel':channel, 'chat_id':chat_id, 'message_text':message_text, 'username':username, 'first_name':first_name, 'last_name':last_name, 'response':response} return str(output_data) + ' ' def to_beautified_log_line(**kwargs): channel = kwargs.get('channel', None) chat_id = kwargs.get('chat_id', None) message_text = kwargs['message_text'] username = kwargs.get('username', None) first_name = kwargs.get('first_name', None) last_name = kwargs.get('last_name', None) response = kwargs['response'] current_datetime = kwargs.get('current_datetime', datetime.datetime(2000, 1, 1, 0, 0)) datetime_output = (str(current_datetime.year) + '-' + str(current_datetime.month) + '-' + str(current_datetime.day) + '/' + str(current_datetime.hour) + ':' + str(current_datetime.minute))# .encode('utf-8') username_data = str(username)# .encode('utf-8') first_name_data = str(first_name)# .encode('utf-8') last_name_data = str(last_name)# .encode('utf-8') response_data = str(response)# .encode('utf-8') output_data = {'datetime':datetime_output, 'channel':str(channel), # .encode('utf-8'), 'chat_id':str(chat_id), 'message_text':message_text, # .encode('utf-8'), 'username':username_data, 'first_name':first_name_data, 'last_name':last_name_data, 'response':response_data} return json.dumps(output_data, ensure_ascii=False) + ' ' def message_to_input(message_data): input_data = dict() try: input_data['message_text'] = message_data['result'][-1]['message']['text'] except: input_data['message_text'] = None try: input_data['update_id'] = message_data['result'][-1]['update_id'] except: input_data['update_id'] = None try: input_data['chat_id'] = message_data['result'][-1]['message']['chat']['id'] except: input_data['chat_id'] = None try: input_data['username'] = message_data['result'][-1]['message']['chat']['username'] except: input_data['username'] = None try: input_data['first_name'] = message_data['result'][-1]['message']['chat']['first_name'] except: input_data['first_name'] = None try: input_data['last_name'] = message_data['result'][-1]['message']['chat']['last_name'] except: input_data['last_name'] = None return input_data def is_update_time(new_datetime, last_update_datetime, updates_settings): if updates_settings['frequency'] == None: return False else: return new_datetime - last_update_datetime > updates_settings['frequency'] def update_data_thread_function(updates_settings, cash_file_name): global updating_data last_update_datetime = datetime.datetime.now() - datetime.timedelta(weeks=10) while True: new_datetime = datetime.datetime.now() if is_update_time(new_datetime, last_update_datetime, updates_settings): print('Updating data at datetime: {}', new_datetime) last_update_datetime = datetime.datetime.now() try: new_data = update_data(updates_settings) if cash_file_name: update_cash_file(new_data, cash_file_name) updating_data = json.load(open(cash_file_name)) else: updating_data = new_data except: traceback.print_exc() time.sleep(3) continue time.sleep(10) def main_loop_webhooks(generate_model_func, generate_response_func, updates_settings={'frequency':None, 'data':{}}, **kwargs): """ updates_settings format: {frequency: datetime.timedelta, data: {first_field: first_function, second_field: second_function, ...}} kwargs: cash_file_name: str, cash file name for cashing updates data, None for no file name """ cash_file_name = kwargs.get('cash_file_name', None) log_file_name = kwargs.get('log_file_name', None) list_of_sources = kwargs['list_of_sources'] # .get('list_of_sources', []) model = generate_model_func() print('Model trained') global updating_data if os.path.isfile(cash_file_name): updating_data = json.load(open(cash_file_name)) else: updating_data = {} update_data_thread = threading.Thread(target=update_data_thread_function, args=(updates_settings, cash_file_name)) update_data_thread.start() current_update_id = 0 activity_status = None last_ping_time = datetime.datetime.now() while True: for source in list_of_sources: current_datetime = datetime.datetime.now() if source['node'] == 'https://api.telegram.org/' and activity_status != 'waiting': try: message_data = get_last_message_data(source['id']['token']) except KeyboardInterrupt: raise except: traceback.print_exc() time.sleep(3) continue input_data = message_to_input(message_data) try: if input_data['update_id'] != None: clear_updates(source['id']['token'], input_data['update_id']) except: traceback.print_exc() if (input_data['update_id'] != None and input_data['message_text'] != None and (current_update_id == None or input_data['update_id'] > current_update_id)): current_update_id = input_data['update_id'] analizing_data = {'message_text':input_data['message_text'], 'username':input_data['username'], 'first_name':input_data['first_name'], 'last_name':input_data['last_name'], 'recipient':{'channel':'telegram', 'token':source['id']['token'], 'chat_id':input_data['chat_id']}} user_id = {'channel':analizing_data['recipient']['channel'], 'chat_id':analizing_data['recipient']['chat_id']} try: response = generate_response_func(input_data['message_text'], model, user_id, updating_data) except: response = u'Sorry, can't reply' traceback.print_exc() write_attempts_number = 5 write_attempts_counter = 0 while write_attempts_counter < write_attempts_number: try: write_message(response, analizing_data['recipient']['chat_id'], analizing_data['recipient']['token']) write_attempts_counter = write_attempts_number # Success! except: if write_attempts_counter == 1: traceback.print_exc() write_attempts_counter += 1 time.sleep(3) write_log(file_name=log_file_name, message_text=analizing_data['message_text'], response=response, channel=analizing_data['recipient']['channel'], chat_id=analizing_data['recipient']['chat_id'], username=analizing_data['username'], first_name=analizing_data['first_name'], last_name=analizing_data['last_name']) else: current_time = datetime.datetime.now() if current_time - last_ping_time > datetime.timedelta(seconds=10): last_ping_time = current_time response_data = get_safe_response_data(source['node'] + 'ping' + source['id']['token'] + '/getupdates') if response_data.get('sysmsg') == 'ping': activity_status = response_data.get('status') analizing_data = {'node':source['node'], 'recipient':source['id'], 'ping':True} http_address = (analizing_data['node'] + 'ping' + analizing_data['recipient']['token'] + '/sendmessage') try: urllib.request.urlopen(http_address, timeout=1) except: pass main_loop_webhook(generate_model_func, generate_response_func, updates_settings, **kwargs) Основная функция, вызываемая из скрипта, использующего библиотеку. Подгружает кеш-файл, запускает в параллельном потоке функцию, обновляющую данные, опрашивает и отправляет ответ в Telegram и сервис, занимающийся мониторингом состояния бота.
get_last_message_data(token) Получает последнее сообщения от пользователя бота.
message_to_input(message_data) Обрабатывает полученное сообщение и конвертирует в вид, удобный для дальнейшей обработки.
write_message(message, chat_id, token) Функция, отвечающая за отправку сообщения в чат Telegram. По историческим причинам ключевой аргумент message может иметь тип str (для простых единичных сообщений), list (для цепочек сообщений) или dict (для сообщений, содержащих встроенную клавиатуру).
write_log(**kwargs) Функция, отвечающая за логирование диалога.
to_request(message, chat_id, token, reply_markup) Функция генерирующая по данным о сообщении, номеру чата, токену и разметке ответа (как правило, содержащем информацию о встроенной клавиатуре) запрос к Telegram API.
update_data(updates_settings) Обновляет данные из сторонних источников
update_cash_file(new_data, cash_file_name) Обновляет содержимое кеш-файла. Полезна на случай, если при очередном запуске программы (например после креша или при деплое новой версии) сервис с данными недоступен.
is_update_time(new_datetime, last_update_datetime, updates_settings) Проверяет, не пора ли обновить данные со сторонних API.
update_data_thread_function(updates_settings, cash_file_name) Функция, запускаемая в параллельном потоке и занимающаяся обновлением данных сторонних API. Пришлось вспомнить основы многопоточного программирования, так как некоторые API могут отвечать на запрос в течении десятков секунд и на это время основная программа подвисала и не отвечала на запросы пользователей.
Библиотека предназначена в первую очередь для взаимодействия с алгоритмами машинного обучения, однако их обсуждение выходит далеко за рамки этой статьи. Для того, чтобы показать как она работет, напишем две простых функции и используем их в качестве генератора примера модели и интерпретатора вывода.
Пример скрипта, использующего библиотеку.
Скрытый текст
# Author: Andrei Grinenko <andrey.grinenko@gmail.com> # License: BSD 3 clause import sys import datetime import web3 TOKEN = '123456789:abcdefghijklmnopqrstuvwxyzABCDEFGHI' REGISTER_TOKEN = '12:abcdef' class HelloWorldMetaModel(object): def __init__(self): pass def predict(self, instance): if instance == '/start': return 'start' elif instance in ['hi', 'hello']: return 'hello' elif instance == 'how are you': return 'how_are_you' else: return 'unknown' def generate_meta_model(): return HelloWorldMetaModel() def generate_response(instance, model, user_id, updating_data): current_datetime = updating_data['datetime'] meaning = model.predict(instance) if meaning == 'start': reply = current_datetime + ': ' + 'I am habr example bot' elif meaning == 'hello': reply = current_datetime + ': ' + 'Hello, human!' elif meaning == 'how_are_you': reply = current_datetime + ': ' + 'I'm fine, thanks!' else: reply = current_datetime + ': ' + 'Don't know yet' # TODO Add datetime return reply def update_datetime(): return str(datetime.datetime.now()) if __name__ == '__main__': web3.main_loop_webhooks( generate_model_func=generate_meta_model, generate_response_func=generate_response, updates_settings={'frequency':datetime.timedelta(seconds=5), 'data':{'datetime':update_datetime}}, list_of_sources=[{'node':'https://api.telegram.org/', 'id':{'token':TOKEN}}, # {'node':'http://123.456.78.90/', # 'id':{'token':REGISTER_TOKEN}} ], cash_file_name='./cash_file.txt', log_file_name='./log.txt') TOKEN = '123456789:abcdefghijklmnopqrstuvwxyzABCDEFGHI' Токен для авторизации бота в Telegram. Его нужно заменить на выданный BotFather-ом для конкретного бота.
REGISTER_TOKEN = '12:abcdef' Токен для оповещения скрипта, контролирующего, что бот работает. Можно заменить случайной строкой если эта функция не нужна.
class HelloWorldMetaModel(object) Тривиальная замена класса, отвечающего за логику обработки входящих сообщений. Когда-нибудь тут случится сложный ИИ, но, увы, пока нет. По крайней мере не в этой статье. А желающие почитать о том, как быстро написать алгоритм машинного обучения и выкатить его в продакшн могут сделать это тут
generate_meta_model() Функция, генерирующая модель.
generate_response(instance, model, user_id, updating_data) Функция, отвечающая за логику формирования ответа по результату применения модели. В нашем простом примере ответ однозначно соответствует одному из возможных смыслов сообщений пользователя, указанных в функции predict() класса HelloWorldMetaModel.
update_datetime() Пример функции, привлекающей внешние изменяющиеся данные.
Пример работы (картинка кликабельна):
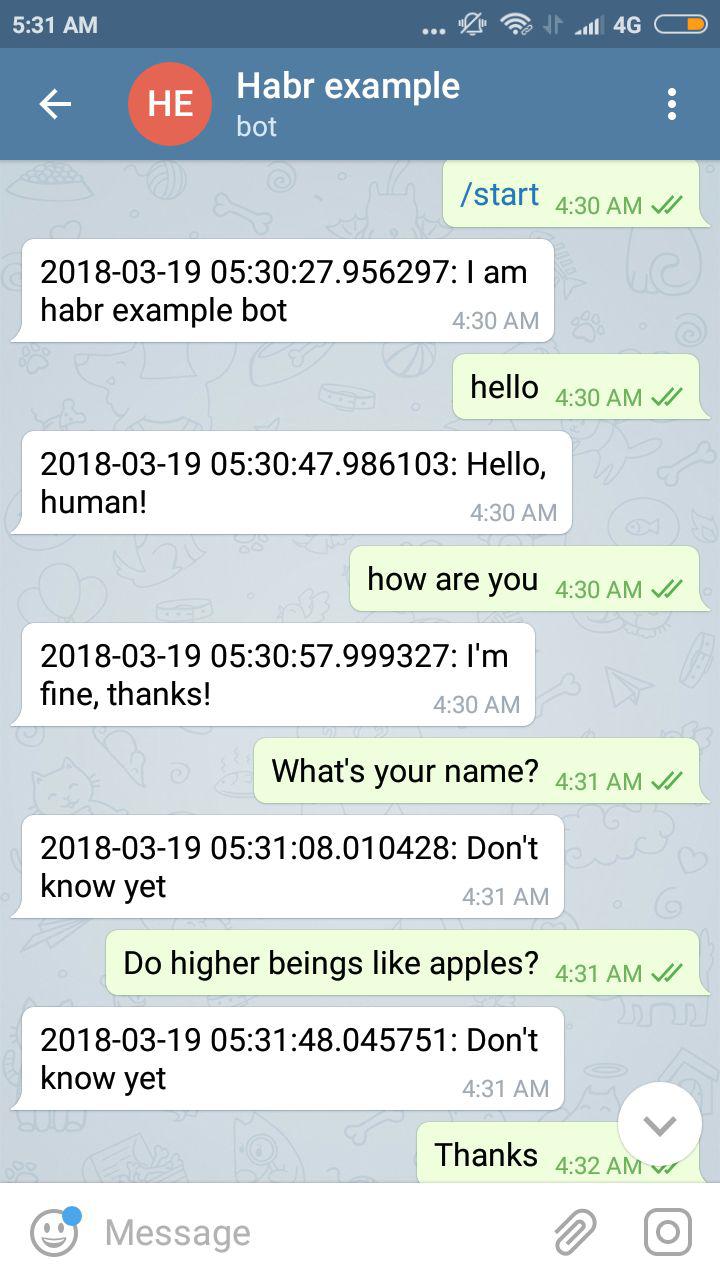
Код на гитхабе тут.
Код на битбакете здесь.
Запускать просто через
python3 example.py, предварительно изменив значение константы TOKEN.Глоссарий
(Обученная) модель машинного обучения — функция, берущая на вход массив чисел фиксированной длины (для математиков — точку в n-мерном пространстве) и возвращающая идентификатор класса (при решении задачи классификации) или число (при решении задачи регрессии).
[1] Мета-модель — обобщение понятия модели машинного обучения. Отличается тем, что принимает на вход объект произвольной природы (напр. массив кодирующий картинку, строку, описание пользователя веб-сайта и т д) и дает на выход объект произвольной природы (как правило идентификатор класса, число, словарь или строку). Абстракция полезна для инкапсуляции пайплайна машинного обучения, как правило включающего в себя препроцессинг, применение модели и постпроцессинг в единую сущность (терминология автора).
Телеграм: t.me/ainewsline
Источник: habrahabr.ru