Мульти-классификация Google-запросов с использованием нейросети на Python
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-03-11 18:46
Сегодня я бы хотел поговорить об одном из способов классификации поисковых запросов, по отдельным категориям с помощью нейронной сети на Keras. Предметной областью запросов была выбрана сфера автомобилей.
За основу был взят датасет размером ~32000 поисковых запросов, размеченных по 14ти классам: Автоистория, Автострахование, ВУ (водительское удостоверение), Жалобы, Запись в ГИБДД, Запись в МАДИ, Запись на медкомиссию, Нарушения и штрафы, Обращения в МАДИ и АМПП, ПТС, Регистрация, Статус регистрации, Такси, Эвакуация.
Сам датасет (.csv файл) выглядит вот так:
запрос;класс
авто история;Автоистория
автоистория Автоистория
бесплатно проверить арест регистрацию авто;Автоистория
пробить авто;Автоистория
пробить авто номеру;Автоистория
пробить автомобиль;Автоистория
пробить автомобиль бесплатно;Автоистория
пробить автомобиль бесплатно регистрации;Автоистория
пробить автомобиль бесплатно номеру;Автоистория
И так далее…
Подготовка датасета
Прежде чем строить модель нейросети необходимо подготовить датасет, а именно удалить все стоп-слова, спец-символы. Так, как в запросах типа «пробить камри 2.4 по вин номеру онлайн» цифры не несут смысловой нагрузки, будем удалять и их.
Стоп-слова берем из пакета NLTK. Также, проапдейтим список стоп-слов символами.
Вот, что должно получиться в итоге:
stop = set(stopwords.words('russian')) stop.update(['.', ',', '"', "'", '?', '!', ':', ';', '(', ')', '[', ']', '{', '}','#','№']) def clean_csv(df): for index,row in df.iterrows(): row['запрос'] = remove_stop_words(row['запрос']).rstrip().lower()Запрос, который будет поступать на вход для классификации также нужно подготавливать. Напишем, функцию, которая будет «очищать» запрос
def remove_stop_words(query): str = '' for i in wordpunct_tokenize(query): if i not in stop and not i.isdigit(): str = str + i + ' ' return strФормализация данных
Нельзя просто взять и запихнуть в нейросеть обычные слова, да ещё и на русском! Прежде чем начать обучение сети, мы трансформируем наши запросы в матрицы последовательностей (sequences), а классы должны быть представлены в виде вектора размером N, где N — количество классов. Для трансформации данных нам понадобится библиотека Tokenizer, которая сопоставляя каждому слову отдельный индекс, может преобразовывать запросы (предложения) в массивы
индексов. Но поскольку длины запросов могут быть разные, то и длины массивов окажутся разными, что неприемлемо для нейронной сети. Чтобы решить эту проблему, необходимо трансформировать запрос в двумерный массив последовательностей равной длины, как и обговаривалось ранее. С выходными данными (вектор классов) дело обстоит чуть попроще. В векторе классов будут содержаться либо единички либо нолики, что свидетельствует принадлежности запроса соответствующему классу.
Итак, смотрим, что получилось:
#считываем из CSV df = pd.read_csv('cleaned_dataset.csv',delimiter=';',encoding = "utf-8").astype(str) num_classes = len(df['класс'].drop_duplicates()) X_raw = df['запрос'].values Y_raw = df['класс'].values #трансформируем текст запросов в матрицы tokenizer = Tokenizer(num_words=max_words) tokenizer.fit_on_texts(X_raw) x_train = tokenizer.texts_to_matrix(X_raw) #трансформируем классы encoder = LabelEncoder() encoder.fit(Y_raw) encoded_Y = encoder.transform(Y_raw) y_train = keras.utils.to_categorical(encoded_Y, num_classes)Построение и компиляция модели
Проинициализируем модель, добавив несколько слоёв, затем скомпилируем её, указав что функция потерь (loss) будет «categorical_crossentropy» так, как у нас более 2х классов (не бинарная). Затем, обучим и сохраним модель в файл. Смотрите код ниже:
model = Sequential() model.add(Dense(512, input_shape=(max_words,))) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes)) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1) model.save('classifier.h5') Кстати говоря, точность (accuracy) при обучении составила 97%, что довольно таки неплохой результат.
Тестирование модели
Теперь напишем небольшой скрипт для командной строки который принимает на вход аргумент — поисковый запрос, а на выходе выдает класс, к которому вероятнее всего принадлежит запрос по мнению модели, созданной нами ранее. Не буду вдаваться в подробности кода в данном разделе, все исходники смотрите на GITHUB. Перейдем к делу, а именно запустим скрипт в командной строке и начнем вбивать запросы:
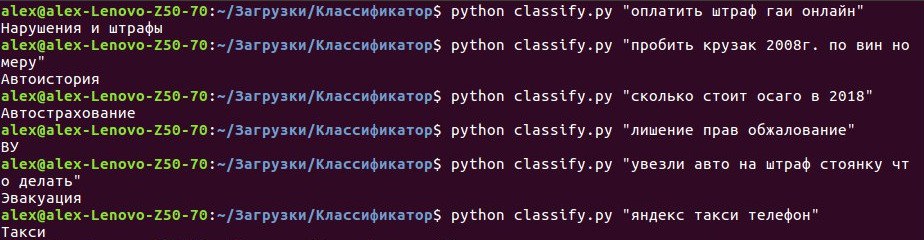 Рисунок 1 — Пример использования классификатора
Рисунок 1 — Пример использования классификатора
Результат вполне очевидный — классификатор точно распознает любые вводимые нами запросы, а значит, что вся работа была проделана не зря!
Выводы и заключение
Нейронная сеть справилась с поставленной задачей на отлично и это видно не вооруженным взглядом. Примером практического применения данной модели можно считать сферу госуслуг, где граждане подают всевозможные заявления, жалобы и т.д. Автоматизировав прием всех этих «бумажек» с помощью интеллектуальной классификации можно существенно ускорить работу всех госорганов.
Ваши предложения по практическому применению, а так же мнение о статье жду в комментах!
Телеграм: t.me/ainewsline
Источник: habrahabr.ru