Интеллектуальная обработка текстов
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-03-22 05:38
Работы, связанные с естественным языком, — это одна из ключевых задач для создания искусственного интеллекта. Их сложность долгое время сильно недооценивали. Одной из причин для раннего оптимизма в области естественного языка были пионерские работы Ноама Хомского о порождающих грамматиках. В своей книге «Синтаксические структуры» и других работах Хомский предложил идею, которая сейчас кажется совершенно обычной, но тогда произвела революцию: он преобразовал предложение на естественном языке в дерево, которое показывает, в каких отношениях находятся разные слова в предложении.
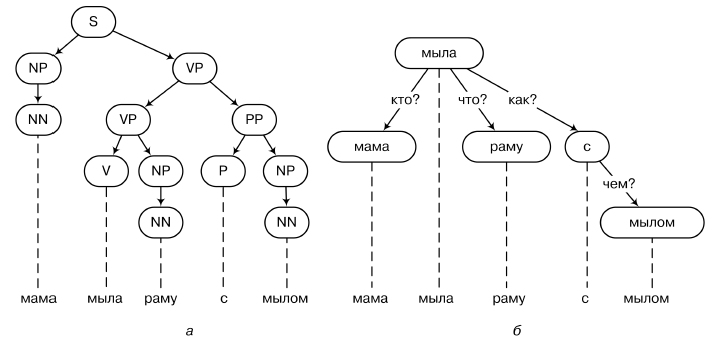
Пример дерева синтаксического разбора показан на рисунке выше (а — синтаксический анализ на основе структуры непосредственных составляющих; б — на основе грамматики зависимостей). Порождающая грамматика — это набор правил вида S ? NP V P или V P ? V NP, которыми можно порождать такие деревья. На деревьях синтаксического разбора можно строить довольно строгие конструкции, пытаться определять, например, логику естественного языка, с настоящими аксиомами и правилами вывода.
Сейчас такой подход к синтаксическому анализу называется анализом на основе структуры
непосредственных составляющих, или фразово-структурных грамматик (phrasestructure based parsing). Хомский, конечно, выдвигал попутно и другие гипотезы — в частности, одной из центральных его идей была идея «универсальной грамматики» человеческого языка, которая, по крайней мере частично, закладывается на генетическом уровне, еще до рождения ребенка, — но для нас сейчас важна именно эта новая связь между естественным языком и математикой, которая со временем превратила лингвистику в одну из самых «точных» из гуманитарных наук.
Для искусственного интеллекта этот лингвистический прорыв поначалу выглядел как индульгенция на безудержный оптимизм: казалось, что раз уж естественный язык можно представить в виде таких строгих математических конструкций, то скоро мы сможем окончательно его формализовать, формализацию перенести в компьютер, и тот вскоре сможет с нами разговаривать. Однако на практике эта программа встретила, мягко скажем, существенные трудности: оказалось, что естественный язык — штука не такая уж формальная, как раньше казалось, а главное, он в огромной степени зависит от неявных предположений, которые формализовать уже совсем нелегко. Более того, оказывается, что для понимания естественного языка зачастую нужно не просто правильным образом «распарсить» такой все же достаточно хорошо определенный формальный объект, как последовательность букв или слов, но еще и иметь некий «здравый смысл», представление об окружающем мире, а с этим у компьютеров пока что совсем плохо.
Простой и понятный пример такой сверхсложной задачи — это разрешение анафоры (anaphora resolution), то есть понимание того, к чему относится то или иное местоимение в тексте. Сравните два предложения: «Мама вымыла раму, и теперь она блестит» и «Мама вымыла раму, и теперь она устала». Структурно они абсолютно одинаковы. Но представьте себе, сколько всего нужно знать и понимать компьютеру, чтобы правильно определить, к чему относится местоимение «она» в каждой из этих фраз!
И это не какой-то специально придуманный извращенный пример, а повседневная реальность нашего с вами языка; мы постоянно делаем отсылки к тому, что люди понимают «естественным образом»… но для компьютерной модели это совершенно нелогично! Именно «здравый смысл» (commonsense reasoning) — это главный камень преткновения для современной обработки естественного языка. Кстати, специалисты по обработке естественных языков уже давно пытаются специально работать в этом направлении; более десяти лет проводится ежегодный семинар о «здравом смысле», International Symposium on Logical Formalization on Commonsense Reasoning, а в последнее время начал проводиться и конкурс решения задач на здравый смысл, названный Winograd Schema Challenge в честь Терри Винограда.
Задания там примерно такие: «Кубок не помещался в чемодан, потому что он был слишком велик; что именно было слишком велико, чемодан или кубок?»
Так что, хотя люди работают над интеллектуальной обработкой текстов и даже делают значительные успехи, компьютеры разговаривать еще не научились. Да и с пониманием письменного текста пока беда, хотя с помощью глубокого обучения и над распознаванием и синтезом речи тоже работают. Но прежде чем мы начнем применять нейронные сети к естественному языку, нужно обсудить еще один вопрос, который у читателя наверняка уже возник: а что, собственно, значит «понимать текст»? Занятия машинным обучением приучили нас к тому, что в первую очередь нужно определить задачу, целевую функцию, которую мы хотим оптимизировать. Как оптимизировать «понимание»?
Конечно же, интеллектуальная обработка текстов — это не одна задача, а очень много, и все из них так или иначе подвластны человеку и связаны со «святым Граалем» понимания текста. Давайте перечислим и кратко прокомментируем основные легко квантифицируемые задачи обработки текстов; о некоторых из них речь пойдет дальше в этой главе; постараемся идти от простого к сложному и условно разделим их на три класса.
1. Задачи первого класса можно условно назвать синтаксическими; здесь задачи, как правило, очень хорошо определены и представляют собой задачи классификации или задачи порождения дискретных объектов, и решаются многие из них сейчас уже довольно неплохо, например:
(i) частеречная разметка (part-of-speech tagging): разметить в заданном тексте слова по частям речи (существительное, глагол, прилагательное...) и, возможно, по морфологическим признакам (род, падеж...);
(ii) морфологическая сегментация (morphological segmentation): разделить слова в заданном тексте на морфемы, то есть синтаксические единицы вроде приставок, суффиксов и окончаний; для некоторых языков (например, английского) это не очень актуально, но в русском языке морфологии очень много;
(iii) другой вариант задачи о морфологии отдельных слов — стемминг (stemming), в котором требуется выделить основы слов, или лемматизация (lemmatization), в которой слово нужно привести к базовой форме (например, форме единственного числа мужского рода);
(iv) выделение границ предложения (sentence boundary disambiguation): разбить заданный текст на предложения; может показаться, что они разделяются точками и другими знаками препинания и начинаются с большой буквы, но вспомните, например, о том, как «в 1995 г. Т. Виноград стал научным руководителем Л. Пейджа», и вы поймете, что задача непростая; а в языках вроде китайского весьма нетривиальной становится даже задача пословной сегментации (word segmentation), потому что поток иероглифов без пробелов может делиться на слова по-разному;
(v) распознавание именованных сущностей (named entity recognition): найти в тексте собственные имена людей, географических и прочих объектов, разметив их по типам сущностей (имена, топонимы и т. п.);
(vi) разрешение смысла слов (word sense disambiguation): выбрать, какой из омонимов, какой из разных смыслов одного и того же слова используется в данном отрывке текста;
(vii) синтаксический парсинг (syntactic parsing): по заданному предложению (и, возможно, его контексту) построить синтаксическое дерево, прямо по Хомскому;
(viii) разрешение кореференций (coreference resolution): определить, к каким объектам или другим частям текста относятся те или иные слова и обороты; частный случай этой задачи — то самое разрешение анафоры, которое мы обсуждали выше.
2. Второй класс — это задачи, которые в общем случае требуют понимания текста, но по форме все еще представляют собой хорошо определенные задачи с правильными ответами (например, задачи классификации), для которых легко придумать не вызывающие сомнений метрики качества. К таким задачам относятся, в частности:
(i) языковые модели (language models): по заданному отрывку текста предсказать следующее слово или символ; эта задача очень важна, например, для распознавания речи (см. чуть ниже);
(ii) информационный поиск (information retrieval), центральная задача, которую решают Google и «Яндекс»: по заданному запросу и огромному множеству документов найти среди них наиболее релевантные данному запросу;
(iii) анализ тональности (sentiment analysis): определить по тексту его тональность, то есть позитивное ли отношение несет этот текст или негативное; анализ тональности используется в онлайн-торговле для анализа отзывов пользователей, в финансах и трейдинге для анализа статей в прессе, отчетов компаний и тому подобных текстов и т. д.;
(iv) выделение отношений или фактов (relationship extraction, fact extraction): выделить из текста хорошо определенные отношения или факты об упоминающихся там сущностях; например, кто с кем находится в родственных отношениях, в каком году основана упоминающаяся в тексте компания и т. д.;
(v) ответы на вопросы (question answering): дать ответ на заданный вопрос; в зависимости от постановки это может быть или чистая классификация (выбор из вариантов ответа, как в тесте), или классификация с очень большим числом классов (ответы на фактологические вопросы вроде «кто?» или «в каком году?»), или даже порождение текста (если отвечать на вопросы нужно в рамках естественного диалога).
3. И наконец, к третьему классу отнесем задачи, в которых требуется не только понять уже написанный текст, но и породить новый. Здесь метрики качества уже не всегда очевидны, и мы обсудим этот вопрос ниже. К таким задачам относятся, например:
(i) собственно порождение текста (text generation);
(ii) автоматическое реферирование (automatic summarization): по тексту породить его краткое содержание, abstract, так сказать; это можно рассмотреть как задачу классификации, если просить модель выбрать из текста готовые предложения, лучше всего отражающие общий смысл, а можно как задачу порождения, если краткое содержание нужно написать с нуля;
(iii) машинный перевод (machine translation): по тексту на одном языке породить соответствующий текст на другом языке;
(iv) диалоговые модели (dialog and conversational models): поддержать разговор с человеком; первые чат-боты начали появляться еще в 1970-е го-ды, а сегодня это большая индустрия; и хотя вести полноценный диалог и проходить тест Тьюринга пока не удается, диалоговые модели уже вовсю работают (например, первая линия «онлайн-консультантов» на разных торговых сайтах — это почти всегда чат-боты).
Важной проблемой для моделей последнего класса является оценка качества. Можно иметь набор параллельных переводов, которые мы считаем хорошими, но как оценить новый перевод, сделанный моделью? Или, еще интереснее, как оценить ответ диалоговой модели в разговоре? Один возможный ответ на этот вопрос — BLEU (Bilingual Evaluation Understudy) [48], класс метрик, разработанных для машинного перевода, но применяющихся и для других задач. BLEU — это модификация точности (precision) совпадения ответа модели и «правильного ответа», перевзвешенной так, чтобы не давать идеальную оценку ответу из одного правильного слова. Для всего тестового корпуса BLEU считается так:
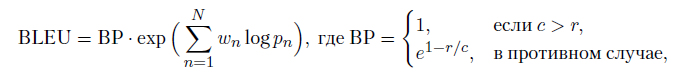
где r — общая длина правильного ответа, c — длина ответа модели, pn — модифицированная точность, а wn — положительные веса, в сумме дающие единицу. Есть и другие подобные метрики: METEOR [298] — гармоническое среднее точности и полноты по униграммам, TER (translation edit rate) [513] подсчитывает относительное число исправлений, которые нужно внести в выход модели, чтобы получить эталонный выход, ROUGE [326] подсчитывает долю пересечения множеств n-грамм слов в эталоне и в полученном тексте, а LEPOR [204] и вовсе сочетает несколько разных метрик с разными весами, которые тоже можно обучить (многие авторы этих статей — французы, вот и аббревиатуры получились франкоязычные). Однако любопытно, что, хотя метрики вроде BLEU и METEOR до сих пор повсеместно используются, на самом деле совершенно не факт, что это самый лучший выбор. Во-первых, BLEU имеет дискретный набор значений, так что напрямую ее оптимизировать градиентным спуском не получится. Но еще интереснее, что в работе [232] приводятся очень удивительные результаты использования разных подобных метрик качества в контексте оценки ответов модели в диалоге. Там подсчитываются корреляции (как обычные, так и ранговые) человеческих оценок качества ответов и оценок по разным метрикам… и оказывается, что эти корреляции практически всегда близки к нулю, а иногда и вовсе отрицательны! Наилучший вариант BLEU сумел достичь корреляции с человеческими оценками около 0,35 на одном датасете, а на другом и вовсе 0,12 (попробуйте-ка опубликовать научный результат с такой корреляцией!). Более того, столь плохие результаты не означают, что правильного ответа не существует вовсе: оценки разных людей всегда имели корреляцию друг с другом на уровне 0,95 и выше, так что «золотой стандарт» оценки качества безусловно существует, но как его формализовать, мы пока что совсем не понимаем. Эта критика уже привела к новым конструкциям автоматически обучаемых метрик качества [537], и мы надеемся, что появятся и новые результаты в этом направлении. Тем не менее, пока легко применимых альтернатив метрикам типа BLEU нет, и обычно используются именно они. Кроме того, есть еще широкий класс задач, связанных с текстом, но принимающих на вход не последовательность символов, а вход другой природы. Например, без понимания языка практически невозможно научиться идеально распознавать речь: хотя кажется, что распознавание речи — это всего лишь задача классификации фонем по звуку, в реальности человек пропускает очень много звуков и достраивает значительную часть того, что слышит, исходя из своего понимания языка. Еще в 1990-е годы системы распознавания речи достигли человеческого уровня в распознавании отдельных фонем: если усадить людей к магнитофону, дать им послушать звуки без контекста и попросить отличить «а» от «о», результаты будут вовсе не выдающиеся; поэтому чтобы, например, записывать то, что вам диктуют, вам нужно хорошо знать язык, на котором это происходит. Другой класс — задачи распознавания рукописного или напечатанного текста. Ко многим из этих задач мы еще вернемся в дальнейшем. Однако основное содержание этой главы заключается не в решении какой-то конкретной задачи обработки естественного языка, а в том, чтобы рассказать о конструкциях, на которых основаны практически все современные нейросетевые подходы к таким задачам — о распределенных представлениях слов.
Приведен отрывок из книги Сергея Николенко, Артура Кадурина и Екатерины Архангельской «Глубокое обучение»
Пример дерева синтаксического разбора показан на рисунке выше (а — синтаксический анализ на основе структуры непосредственных составляющих; б — на основе грамматики зависимостей). Порождающая грамматика — это набор правил вида S ? NP V P или V P ? V NP, которыми можно порождать такие деревья. На деревьях синтаксического разбора можно строить довольно строгие конструкции, пытаться определять, например, логику естественного языка, с настоящими аксиомами и правилами вывода.
Сейчас такой подход к синтаксическому анализу называется анализом на основе структуры
непосредственных составляющих, или фразово-структурных грамматик (phrasestructure based parsing). Хомский, конечно, выдвигал попутно и другие гипотезы — в частности, одной из центральных его идей была идея «универсальной грамматики» человеческого языка, которая, по крайней мере частично, закладывается на генетическом уровне, еще до рождения ребенка, — но для нас сейчас важна именно эта новая связь между естественным языком и математикой, которая со временем превратила лингвистику в одну из самых «точных» из гуманитарных наук.
Для искусственного интеллекта этот лингвистический прорыв поначалу выглядел как индульгенция на безудержный оптимизм: казалось, что раз уж естественный язык можно представить в виде таких строгих математических конструкций, то скоро мы сможем окончательно его формализовать, формализацию перенести в компьютер, и тот вскоре сможет с нами разговаривать. Однако на практике эта программа встретила, мягко скажем, существенные трудности: оказалось, что естественный язык — штука не такая уж формальная, как раньше казалось, а главное, он в огромной степени зависит от неявных предположений, которые формализовать уже совсем нелегко. Более того, оказывается, что для понимания естественного языка зачастую нужно не просто правильным образом «распарсить» такой все же достаточно хорошо определенный формальный объект, как последовательность букв или слов, но еще и иметь некий «здравый смысл», представление об окружающем мире, а с этим у компьютеров пока что совсем плохо.
Простой и понятный пример такой сверхсложной задачи — это разрешение анафоры (anaphora resolution), то есть понимание того, к чему относится то или иное местоимение в тексте. Сравните два предложения: «Мама вымыла раму, и теперь она блестит» и «Мама вымыла раму, и теперь она устала». Структурно они абсолютно одинаковы. Но представьте себе, сколько всего нужно знать и понимать компьютеру, чтобы правильно определить, к чему относится местоимение «она» в каждой из этих фраз!
И это не какой-то специально придуманный извращенный пример, а повседневная реальность нашего с вами языка; мы постоянно делаем отсылки к тому, что люди понимают «естественным образом»… но для компьютерной модели это совершенно нелогично! Именно «здравый смысл» (commonsense reasoning) — это главный камень преткновения для современной обработки естественного языка. Кстати, специалисты по обработке естественных языков уже давно пытаются специально работать в этом направлении; более десяти лет проводится ежегодный семинар о «здравом смысле», International Symposium on Logical Formalization on Commonsense Reasoning, а в последнее время начал проводиться и конкурс решения задач на здравый смысл, названный Winograd Schema Challenge в честь Терри Винограда.
Задания там примерно такие: «Кубок не помещался в чемодан, потому что он был слишком велик; что именно было слишком велико, чемодан или кубок?»
Так что, хотя люди работают над интеллектуальной обработкой текстов и даже делают значительные успехи, компьютеры разговаривать еще не научились. Да и с пониманием письменного текста пока беда, хотя с помощью глубокого обучения и над распознаванием и синтезом речи тоже работают. Но прежде чем мы начнем применять нейронные сети к естественному языку, нужно обсудить еще один вопрос, который у читателя наверняка уже возник: а что, собственно, значит «понимать текст»? Занятия машинным обучением приучили нас к тому, что в первую очередь нужно определить задачу, целевую функцию, которую мы хотим оптимизировать. Как оптимизировать «понимание»?
Конечно же, интеллектуальная обработка текстов — это не одна задача, а очень много, и все из них так или иначе подвластны человеку и связаны со «святым Граалем» понимания текста. Давайте перечислим и кратко прокомментируем основные легко квантифицируемые задачи обработки текстов; о некоторых из них речь пойдет дальше в этой главе; постараемся идти от простого к сложному и условно разделим их на три класса.
1. Задачи первого класса можно условно назвать синтаксическими; здесь задачи, как правило, очень хорошо определены и представляют собой задачи классификации или задачи порождения дискретных объектов, и решаются многие из них сейчас уже довольно неплохо, например:
(i) частеречная разметка (part-of-speech tagging): разметить в заданном тексте слова по частям речи (существительное, глагол, прилагательное...) и, возможно, по морфологическим признакам (род, падеж...);
(ii) морфологическая сегментация (morphological segmentation): разделить слова в заданном тексте на морфемы, то есть синтаксические единицы вроде приставок, суффиксов и окончаний; для некоторых языков (например, английского) это не очень актуально, но в русском языке морфологии очень много;
(iii) другой вариант задачи о морфологии отдельных слов — стемминг (stemming), в котором требуется выделить основы слов, или лемматизация (lemmatization), в которой слово нужно привести к базовой форме (например, форме единственного числа мужского рода);
(iv) выделение границ предложения (sentence boundary disambiguation): разбить заданный текст на предложения; может показаться, что они разделяются точками и другими знаками препинания и начинаются с большой буквы, но вспомните, например, о том, как «в 1995 г. Т. Виноград стал научным руководителем Л. Пейджа», и вы поймете, что задача непростая; а в языках вроде китайского весьма нетривиальной становится даже задача пословной сегментации (word segmentation), потому что поток иероглифов без пробелов может делиться на слова по-разному;
(v) распознавание именованных сущностей (named entity recognition): найти в тексте собственные имена людей, географических и прочих объектов, разметив их по типам сущностей (имена, топонимы и т. п.);
(vi) разрешение смысла слов (word sense disambiguation): выбрать, какой из омонимов, какой из разных смыслов одного и того же слова используется в данном отрывке текста;
(vii) синтаксический парсинг (syntactic parsing): по заданному предложению (и, возможно, его контексту) построить синтаксическое дерево, прямо по Хомскому;
(viii) разрешение кореференций (coreference resolution): определить, к каким объектам или другим частям текста относятся те или иные слова и обороты; частный случай этой задачи — то самое разрешение анафоры, которое мы обсуждали выше.
2. Второй класс — это задачи, которые в общем случае требуют понимания текста, но по форме все еще представляют собой хорошо определенные задачи с правильными ответами (например, задачи классификации), для которых легко придумать не вызывающие сомнений метрики качества. К таким задачам относятся, в частности:
(i) языковые модели (language models): по заданному отрывку текста предсказать следующее слово или символ; эта задача очень важна, например, для распознавания речи (см. чуть ниже);
(ii) информационный поиск (information retrieval), центральная задача, которую решают Google и «Яндекс»: по заданному запросу и огромному множеству документов найти среди них наиболее релевантные данному запросу;
(iii) анализ тональности (sentiment analysis): определить по тексту его тональность, то есть позитивное ли отношение несет этот текст или негативное; анализ тональности используется в онлайн-торговле для анализа отзывов пользователей, в финансах и трейдинге для анализа статей в прессе, отчетов компаний и тому подобных текстов и т. д.;
(iv) выделение отношений или фактов (relationship extraction, fact extraction): выделить из текста хорошо определенные отношения или факты об упоминающихся там сущностях; например, кто с кем находится в родственных отношениях, в каком году основана упоминающаяся в тексте компания и т. д.;
(v) ответы на вопросы (question answering): дать ответ на заданный вопрос; в зависимости от постановки это может быть или чистая классификация (выбор из вариантов ответа, как в тесте), или классификация с очень большим числом классов (ответы на фактологические вопросы вроде «кто?» или «в каком году?»), или даже порождение текста (если отвечать на вопросы нужно в рамках естественного диалога).
3. И наконец, к третьему классу отнесем задачи, в которых требуется не только понять уже написанный текст, но и породить новый. Здесь метрики качества уже не всегда очевидны, и мы обсудим этот вопрос ниже. К таким задачам относятся, например:
(i) собственно порождение текста (text generation);
(ii) автоматическое реферирование (automatic summarization): по тексту породить его краткое содержание, abstract, так сказать; это можно рассмотреть как задачу классификации, если просить модель выбрать из текста готовые предложения, лучше всего отражающие общий смысл, а можно как задачу порождения, если краткое содержание нужно написать с нуля;
(iii) машинный перевод (machine translation): по тексту на одном языке породить соответствующий текст на другом языке;
(iv) диалоговые модели (dialog and conversational models): поддержать разговор с человеком; первые чат-боты начали появляться еще в 1970-е го-ды, а сегодня это большая индустрия; и хотя вести полноценный диалог и проходить тест Тьюринга пока не удается, диалоговые модели уже вовсю работают (например, первая линия «онлайн-консультантов» на разных торговых сайтах — это почти всегда чат-боты).
Важной проблемой для моделей последнего класса является оценка качества. Можно иметь набор параллельных переводов, которые мы считаем хорошими, но как оценить новый перевод, сделанный моделью? Или, еще интереснее, как оценить ответ диалоговой модели в разговоре? Один возможный ответ на этот вопрос — BLEU (Bilingual Evaluation Understudy) [48], класс метрик, разработанных для машинного перевода, но применяющихся и для других задач. BLEU — это модификация точности (precision) совпадения ответа модели и «правильного ответа», перевзвешенной так, чтобы не давать идеальную оценку ответу из одного правильного слова. Для всего тестового корпуса BLEU считается так:
Приведен отрывок из книги Сергея Николенко, Артура Кадурина и Екатерины Архангельской «Глубокое обучение»
Телеграм: t.me/ainewsline
Источник: habrahabr.ru