Могут ли нейронные сети читать мысли
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-03-01 19:02
свёрточные нейронные сети, машинное обучение новости, работа головного мозга, Нейроинтерфейс

Могут ли нейронные сети прочесть мысли человека, какую роль в этом играет функциональная магнитно-резонансная томография и почему вместо бутылочной крышки нейросеть видит карликового пуделя, рассказывает научный руководитель компании Neuromation, научный сотрудник Санкт-Петербургского отделения Математического института имени В.А. Стеклова (ПОМИ) РАН Сергей Николенко.
Недавно в новости попали японские исследователи из ATR Computational Neuroscience Labs в Киото и из Университета Киото. Их статья под названием «Глубокие нейронные сети для реконструкции изображений по активности человеческого мозга» (Shen et al., 2017), по сути, утверждает, что они разработали модель машинного обучения, которая может прочесть ваши мысли (примеры реконструированных из мыслей картинок показаны выше). Что все это значит? Может, пора уже привыкать думать только правильные мысли? Чтобы понять, что на самом деле означает эта новость, придется начать с кратких пояснений.
Как читать мысли глубоких нейросетей
У нейронных сетей всегда была одна большая проблема — непрозрачность: конечный результат увидеть можно, но очень трудно понять, что же там внутри происходит. Это проблема относится ко всем архитектурам, но давайте сейчас сосредоточимся на сверточных нейронных сетях (convolutional neural networks, CNN), которые постоянно используются для обработки изображений и вообще данных с пространственной структурой.
Очень грубо говоря, CNN — это многослойные (глубокие) нейронные сети, в которых каждый слой обрабатывает свой вход маленькими окнами, извлекая локальные признаки. Последовательно, уровень за уровнем, локальные признаки обобщаются и становятся глобальными: признаки на высоких уровнях сети «видят» гораздо большую часть изображения, чем на низких. Вот как это работает в очень простой CNN (картинку я взял из вот этого текста, который рекомендую прочесть полностью):
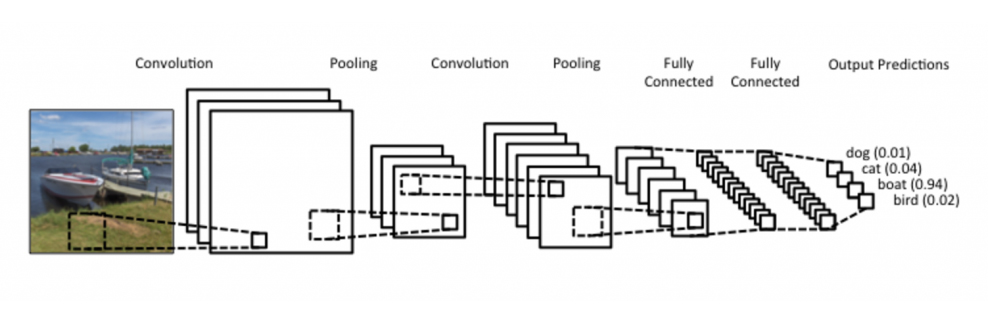
WILDML
В конце концов, через несколько (иногда несколько сотен) слоев мы получаем глобальные признаки, которые уже «смотрят» на все исходное изображение целиком, и уже их на последних слоях сети мы комбинируем так, чтобы получить метки классов (распознать, кошечка это, собачка или моторная лодка). Но как нам понять, что конкретно распознают эти признаки? Можем ли мы их интерпретировать?
Один возможный способ это понять — посмотреть на картинки, которые активируют конкретные нейроны в этой нейросети. Можно надеяться, что у этих картинок будет что-то общее. Эту идею развили, в частности, в знаменитой работе «Визуализация и понимание сверточных сетей». Вот посмотрите: на картинке ниже показаны окна из реальных изображений (справа), которые дают самые большие активации разным нейронам на одном из высоких уровней сверточной сети, а слева показаны пиксели, которые участвуют в этих активациях. Видно, что такой выбор картинок, подходящих под конкретные признаки, действительно позволяет многие нейроны неплохо интерпретировать:

Rob Fergus
Затем появилась другая простая, но очень интересная идея, которая тоже неплохо работает для интерпретации признаков. Весь процесс обучения модели устроен так: мы берем данные (скажем, размеченные изображения) и подгоняем веса модели так, чтобы модель как можно лучше эти данные описывала. Изображения при этом остаются фиксированными, а меняются веса сети, параметры тех самых сверточных слоев, о которых мы говорили выше.
Но можно попробовать наоборот: давайте зафиксируем сеть и изменим изображение так, чтобы сеть на нем выдавала то, что нам надо!
Для целей интерпретации нейронных сетей эта идея была развита, например, в работе «Интерпретация нейронных сетей при помощи глубокой визуализации». Результаты оптимизации картинок под конкретные цели очень похожи на знаменитые «deep dreams», и это, конечно, не случайно. Вот, например, картинки, специально оптимизированные с целью как можно сильнее активировать те или иные классы:

Jason Yosinski
Немного узнаваемо, но довольно странно выглядит, правда? Похожие эффекты мы увидим и в картинках из «чтения мыслей».
Другое важное применение той же идеи — антагонистические примеры (adversarial examples) для сверточных сетей: раз уж мы научились подгонять картинки под нейронную сеть, а не наоборот, давайте попробуем подогнать картинки так, чтобы обмануть сеть. Так можно получить примеры наподобие вот этого:

Jason Yosinski
Слева на этой картинке — самое обычное изображение, и оно вполне корректно распознается как крышка от бутылки. А справа — «антагонистическое» изображение: разницу между ними трудно заметить, даже когда они стоят рядом, но та же самая сеть, которая картинку слева распознавала как крышку, картинку справа уверенно распознает как… карликового пуделя.
На самом деле картинка справа получилась из картинки слева добавлением специального шума, очень маленьких изменений, которые выглядят абсолютно случайными, но на самом деле все направляют сеть в одну и ту же сторону — в сторону карликового пуделя. Это делается как раз при помощи оптимизации картинок под сеть, в данном случае — под один из ее выходов.
Кстати, эти примеры показывают, что современным сверточным сетям еще есть над чем поработать, прежде чем задача компьютерного зрения будет окончательно решена. Хотя все мы знаем примеры оптических иллюзий, которые работают и для людей, все-таки вряд ли можно подобрать двумерную картинку бутылочной крышки, которую человек распознает как карликового пуделя. Но подгонку картинок под заданную нейросеть можно использовать и во благо — и с чтением мыслей как раз так и получилось...
Как же читать человеческие мысли?
Что же все-таки сделали японские исследователи в статье (Shen et al., 2017)? Во-первых, они получили фМРТ мозга человека, который смотрит на некоторое изображение, и выделили из него признаки. Функциональная магнитно-резонансная томография (фМРТ) — это тип медицинских снимков, в которых активность мозга анализируется на основе изменений в токе крови: когда нейроны в некоторой области мозга активны, приток крови увеличивается, и это можно измерить. фМРТ называется функциональным, потому что отмечает изменения в притоке крови во времени, и в итоге получается как бы «видеосъемка» активности мозга. Советую вот это объясняющее видео о сути работы фМРТ. А пример получающегося датасета можно увидеть здесь:
Поскольку мы измеряем ток крови, а не непосредственно активность нейронов, пространственное разрешение фМРТ не идеально: мы не можем спуститься на уровень отдельных нейронов, но все-таки можем различить довольно маленькие участки мозга — размер вокселя (трехмерного пикселя) в фМРТ получается порядка одного миллиметра. Давно было известно, что по фМРТ можно понять некоторую общую информацию о том, что человек в сканере думает: эмоции, базовую мотивацию, входы какого рода мозг сейчас обрабатывает (речь, музыку, видео) и т. д., но работа (Shen et al., 2017) продвигает эту идею гораздо дальше.
Авторы попытались буквально реконструировать изображения, на которые смотрят люди в фМРТ-сканерах. Для этого они обучили глубокую нейронную сеть на результатах фМРТ, а затем попытались совместить признаки нового изображения с признаками фМРТ человека. Иными словами, они делали как раз то, что мы обсуждали выше: подгоняли картинку под заданные признаки, сгенерированные нейронной сетью. Разница только в том, что признаки теперь заданы не нужным выходом или признаком, а результатом работы другой сети (тоже, конечно, сверточной) на данных фМРТ. На этом видео можно увидеть, как сеть постепенно подгоняет картинку под заданный паттерн фМРТ:
Качество реконструкции радикально улучшилось, когда авторы добавили еще одну нейронную сеть, глубокую порождающую сеть (deep generator network, DGN), которая следит за тем, чтобы картинки выглядели «естественными» (говоря более технически, она добавляет априорное распределение, которое присваивает больший вес естественно выглядящим картинкам). Это тоже важная идея в машинном обучении: часто мы с вами можем что-то понять в данных только потому, что заранее знаем, чего от них можно ожидать. Моделям искусственного интеллекта это тоже нужно, им нужна априорная информация, «интуиция» о том, какие входы бывают, а какие — нет.
А архитектура выглядит довольно логично. Задача оптимизации здесь состоит в том, чтобы найти картинку, которая наилучшим образом подходит и под глубокую порождающую сеть, которая делает картинку «естественной», и под глубокую сеть, которая делает ее подходящей для признаков фМРТ:
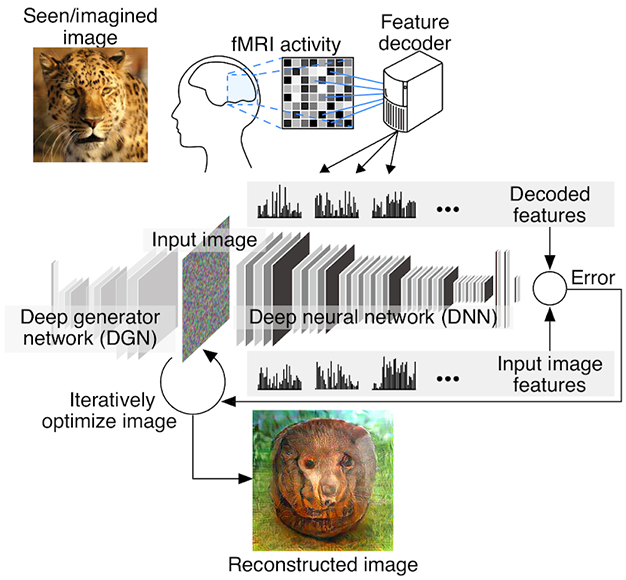
Guohua Shen
Если эти результаты удастся реплицировать и развить дальше, получится несомненный прорыв в нейронауках. Можно даже помечтать о том, как парализованные люди смогут общаться с нами через фМРТ-аппараты, концентрируясь на том, что они хотят сказать. И хотя в работе (Shen et al., 2017) результаты реконструкции, конечно, получаются гораздо хуже, когда люди всего лишь представляют себе некоторую форму, а не прямо смотрят на нее, иногда даже с воображаемыми формами результаты получаются неплохие:

Guohua Shen
Ну так что, может нейронная сеть прочитать ваши мысли? Нет, на самом деле не совсем. Надо сначала лечь в большой и страшный фМРТ-аппарат, потом тщательно сконцентрироваться на одном неподвижном изображении. И даже в лучшем случае результат получается примерно такой, чем-то безусловно похожий, но не то чтобы узнаваемый:

Guohua Shen
Но все равно это большой шаг вперед. Может быть, когда-нибудь.
Автор — Сергей Николенко
Телеграм: t.me/ainewsline
Источник: indicator.ru