Python: ИИ для “Четыре в ряд” с алгоритмом AlphaZero
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-02-26 11:51

В этой статье мы рассмотрим применение алгоритма AlphaZero для создания ИИ игры «Четыре в ряд» с самообучением и Deep Learning.
AlphaGo - AlphaGo Zero - AlphaZero
В марте 2016 программа AlphaGo обыграла одного из сильнейших в мире игроков Go со счётом 4:1 в серии, которую смотрели более 200 миллионов человек. Программа изучила человеческую стратегию игры Go – подвиг, который ранее считался невозможным, или, по крайней мере, в течение десятилетия от достижения.

Это было выдающимся достижением. Однако 18 октября 2017 года DeepMind сделал огромный скачок вперёд.
В статье “Mastering the Game of Go without Human Knowledge” был представлен новый вариант алгоритма AlphaGo Zero, который обыграл своего предшественника со счётом 100:0. Результат был достигнут только за счёт самообучения: алгоритм начинал с “tabula rasa” (пустого состояния) и постепенно находил алгоритмы, которые обыгрывали предыдущие.
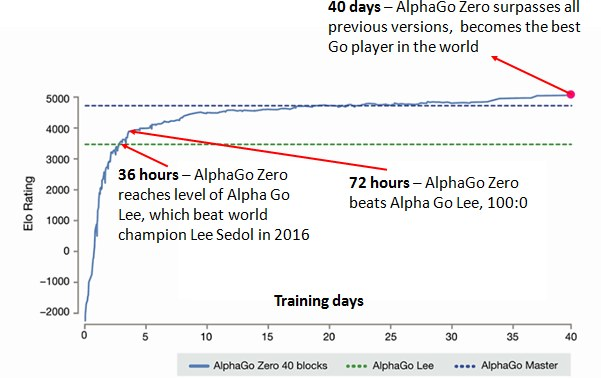
Всего через 48 дней, 5 декабря 2017, DeepMind выпустил ещё одну статью: «Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm», в которой рассказывалось о том, как AlphaGo Zero может превзойти всемирные программы-чемпионы StockFish и Elmo в шахматах и сёги. Весь процесс обучения от первой игры до уровня лучшей компьютерной программой в мире занял менее суток.
Так появился AlphaZero – общий алгоритм для того, чтобы преуспеть в чём-либо быстро, без каких-либо предварительных знаний о человеческой экспертной стратегии.
В этом достижении есть две удивительные вещи:
- AlphaZero требует нулевого опыта в качестве входных данных.
Это означает, что основная методология AlphaGo Zero может быть применена к любой игре с идеальной информацией (состояние игры известно обоим игрокам в любое время), потому что никакие предварительные экспертизы не требуются вне правил игры. Именно так DeepMind переделал алгоритм AlphaGo Zero под шахматы и сёги всего через 48 дней после публикации статьи. Всё, что нужно было, – изменить файл, описывающий механику игры и настройку гипер-параметров, относящихся к нейронной сети и поиску дерева Монте-Карло. - Алгоритм невероятно элегантен.
Если бы AlphaZero использовал сверхсложные алгоритмы, понятные только нескольким людям в мире, это всё равно было бы невероятным достижением. Что делает его необычным, так это то, что многие идеи в статье гораздо менее сложны, чем предыдущие. В его основе лежит следующая простая мантра для обучения:
«Мысленно перебирайте возможные сценарии, отдавая приоритет перспективным путям, а также учитывая, как другие будут реагировать на ваши действия и продолжать исследовать неизвестное. Попав в незнакомое положение, оцените, насколько благоприятным вы его считаете. Пройдитесь по предыдущим шагам, чтобы понять, что именно привело вас в текущее положение. После того, как вы закончили перебирать возможные ходы, действуйте такими методами, которые вы изучили лучше всего. В конце партии вернитесь и найдите те моменты, когда вы недооценили важность будущих позиций. Обновите своё понимание игры соответствующим образом.»
Разве это не похоже на то, как вы учитесь играть в игры? Когда вы делаете плохой ход, это происходит либо потому, что вы недооценили важность будущих позиций, либо потому, что вы неправильно оценили вероятность того, что ваш противник сыграет определённый ход. Это именно те два аспекта игрового процесса, которым обучается AlphaZero.
Как создать свой собственный AlphaZero
Прежде всего, просмотрите заметку по AlphaGo Zero для лучшего понимания того, как он работает. Также эта статья объясняет принцип работы AlphaZero более детально.
Работаем с кодом
Скопируйте этот Git репозиторий.
Чтобы начать процесс обучения, запустите две верхние панели в run.ipynb Jupyter notebook. После того, как создастся достаточное количество игровых позиций, нейронная сеть начнёт обучение. С помощью самообучения и тренировок, алгоритм будет постепенно улучшаться при прогнозировании следующих шагов из любой позиции. Это приводит к лучшему принятию решений и улучшению общей игры.
Теперь разберём код более детально и покажем, что искусственный интеллект прогрессирует со временем.
Четыре в ряд
Игра, в которую наш алгоритм будет играть — это четыре в ряд. Не так сложно, как Go, но всё же существует 4.531.985.219.092 игровые позиции.

Цель игры проста — расположить раньше противника подряд по горизонтали, вертикали или диагонали четыре фишки своего цвета.
Краткое описание ключевых файлов:
game.py
Этот файл содержит правила игры для “Четыре в ряд”. Каждому квадрату присваивается число от 0 до 41, как показано ниже.
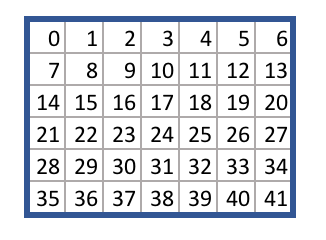
Game.py описывает логику перехода из одного игрового состояния в другое. Например, учитывая то, что поле чистое и то, что фишка ставится на квадрат 38, метод takeAction возвращает новое состояние игры.
Вы можете заменить game.py любым файлом, который соответствует тому же API, и алгоритм будет изучать стратегию посредством самообучения на основе правил, которые вы описали в файле.
run.ipynb
Содержит код, запускающий процесс обучения. Он загружает правила игры, затем перебирает основной цикл алгоритма, состоящий из трёх этапов:
- Игра с самим собой
- Переподготовка нейронной сети
- Оценка нейронной сети
В этом цикле задействованы два агента: best_player и current_player.
Best_player содержит наиболее эффективную нейронную сеть и используется для генерирования воспоминаний о своей игре. Нейронная сеть current_player перенимает эти воспоминания, а затем играет против best_player. Если последний проигрывает, то его нейронная сеть перенимает модель current_player, и цикл начинается снова.
agent.py
Содержит класс агента (игрока в игре). Каждый игрок инициализируется со своей собственной нейронной сетью и деревом Монте-Карло.
Метод simulate запускает процесс поиска дерева Монте-Карло. Агент перемещается к конечному узлу дерева, оценивает узел, затем отбрасывает значение этого узла вверх по дереву.
Метод act повторяет моделирование несколько раз, чтобы понять, какой переход из текущей позиции наиболее благоприятен. Затем он возвращает выбранное действие в игру, чтобы сделать ход.
Метод replay переучивает нейронную сеть, используя воспоминания из прошлых игр.
model.py
Файл содержит класс Residual_CNN, который определяет способ создания экземпляра нейронной сети.
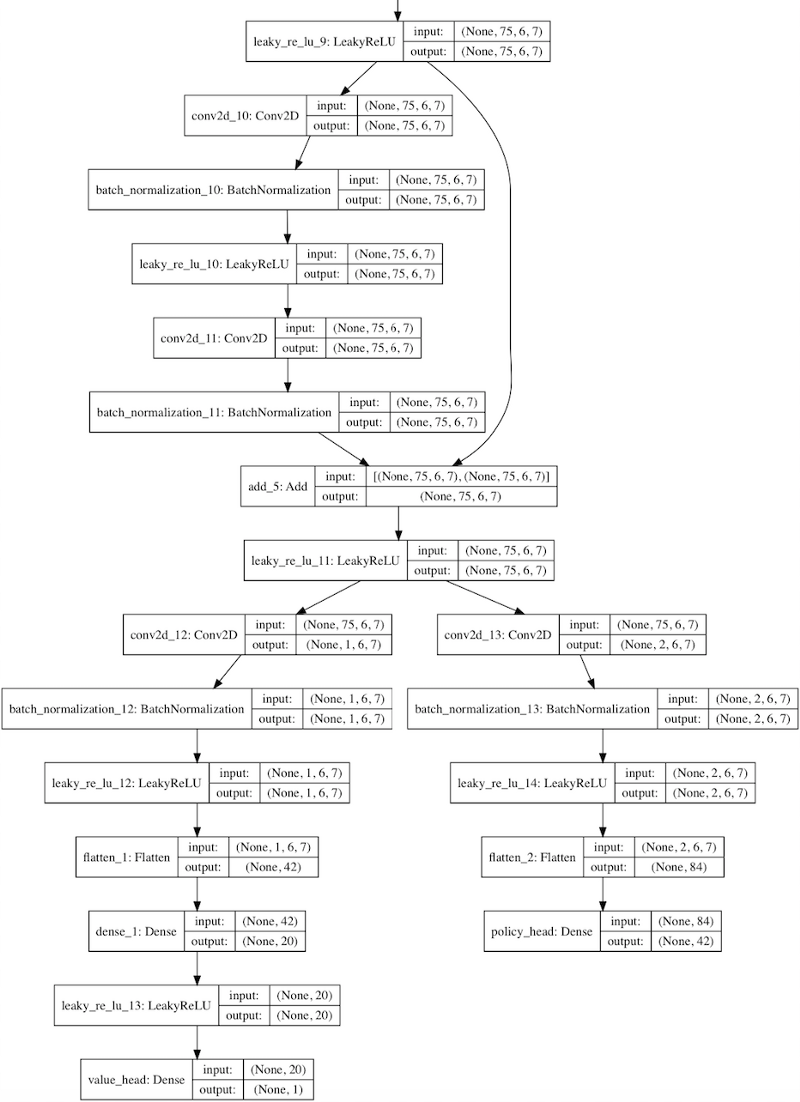
Он использует сжатую версию архитектуры нейронной сети AlphaGoZero — т. е. сверточной слой, за которым следуют многие остаточные слои. Глубину и количество сверточных фильтров можно указать в файле конфигурации.
Библиотека Kerras используется для создания нейронной сети с помощью Tensorflow.
Для просмотра отдельных свёрточных фильтров и плотно соединённых слоёв выполните следующие действия в run.ipynb:
|
1 |
current_player.model.viewLayers() |
MCTS.py
Содержит классы Node, Edge и MCTS, составляющие дерево поиска Монте-Карло. Класс MCTS содержит упомянутые выше методы moveToLeaf и backFill. Экземпляры класса Edge хранят статистику каждого потенциального перемещения.
config.py
Здесь вы устанавливаете ключевые параметры, влияющие на алгоритм.

Корректировка этих переменных повлияет на время работы, точность нейронной сети и общий успех алгоритма. Вышеуказанные параметры создают идеального игрока “Четыре в ряд”, но обучаться этот игрок будет очень долго. Чтобы ускорить алгоритм, попробуйте использовать следующие параметры:

funcs.py
Содержит функции playMatches и playMatchesBetweenVersions, которые играют матчи между двумя агентами. Чтобы сыграть против вашего ИИ, запустите следующий код:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from game import Game from funcs import playMatchesBetweenVersions import loggers aslg env=Game() playMatchesBetweenVersions( env ,1# the run version number where the computer player is located ,-1# the version number of the first player (-1 for human) ,12# the version number of the second player (-1 for human) ,10# how many games to play ,lg.logger_tourney# where to log the game to ,0# which player to go first - 0 for random ) |
initialise.py
При запуске алгоритма все файлы сохраняются в папке run, в корневом каталоге. Чтобы перезапустить алгоритм с конкретной контрольной точки, переместите папку run в папку run_archive, прикрепив номер выполнения к имени папки. Затем введите номер выполнения, номер версии модели и номер версии памяти в файл initialise.py.
memory.py
Экземпляр класса Memory хранит воспоминания предыдущих игр, которые использует алгоритм для перенастройки нейронной сети current_player.
settings.py
Расположение папок run и run_archive.
loggers.py
Логи хранятся в папке логов в папке run. Чтобы начать вести логи, поменяйте значение logger_disabled на false внутри этого файла. Просмотр логов поможет вам понять, как работает ваш алгоритм. Вот пример логов из файла logger.mcts:

Аналогично из файла logger.tourney вы можете увидеть вероятности, прикреплённые к каждому ходу, на этапе оценки:
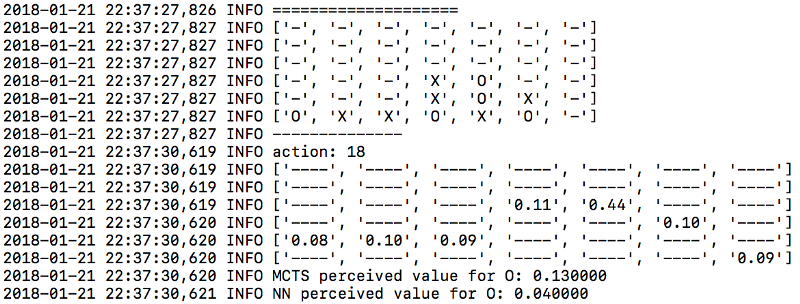
Результаты
Обучение в течение нескольких дней привело к следующему графику потерь:
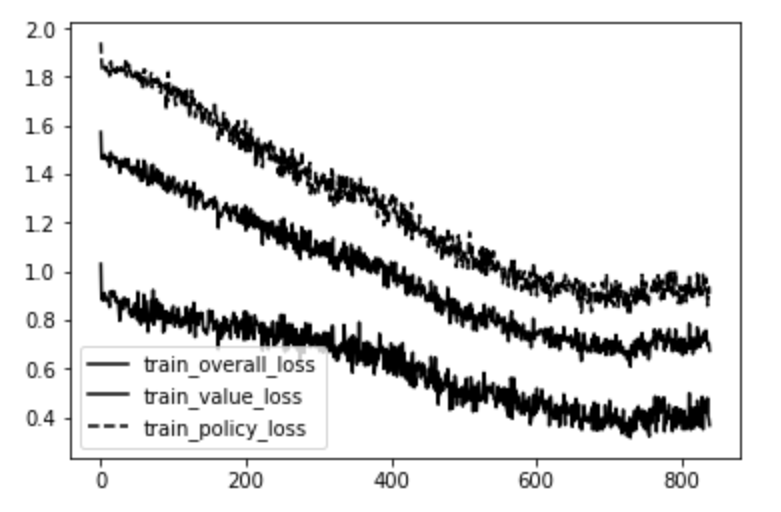
Верхняя строка — это ошибка в главе политики (кросс-энтропия вероятностей перемещения MCTS, на выходе из нейронной сети). Нижняя строка — это ошибка в заголовке значения (средняя квадратичная ошибка между фактическим значением игры и нейронной сетью предсказывает значение). Линия посередине — среднее из двух.
Очевидно, что нейронная сеть становится лучше, предсказывая значение каждого состояния игры и вероятные последующие шаги. Чтобы показать, как это приводит к более сильной игре, автор провел лигу между 17 игроками, начиная от 1-й итерации нейронной сети до 49-й. Каждая пара играла дважды, причем у обоих игроков был шанс сыграть первым.
Вот финальная таблица:
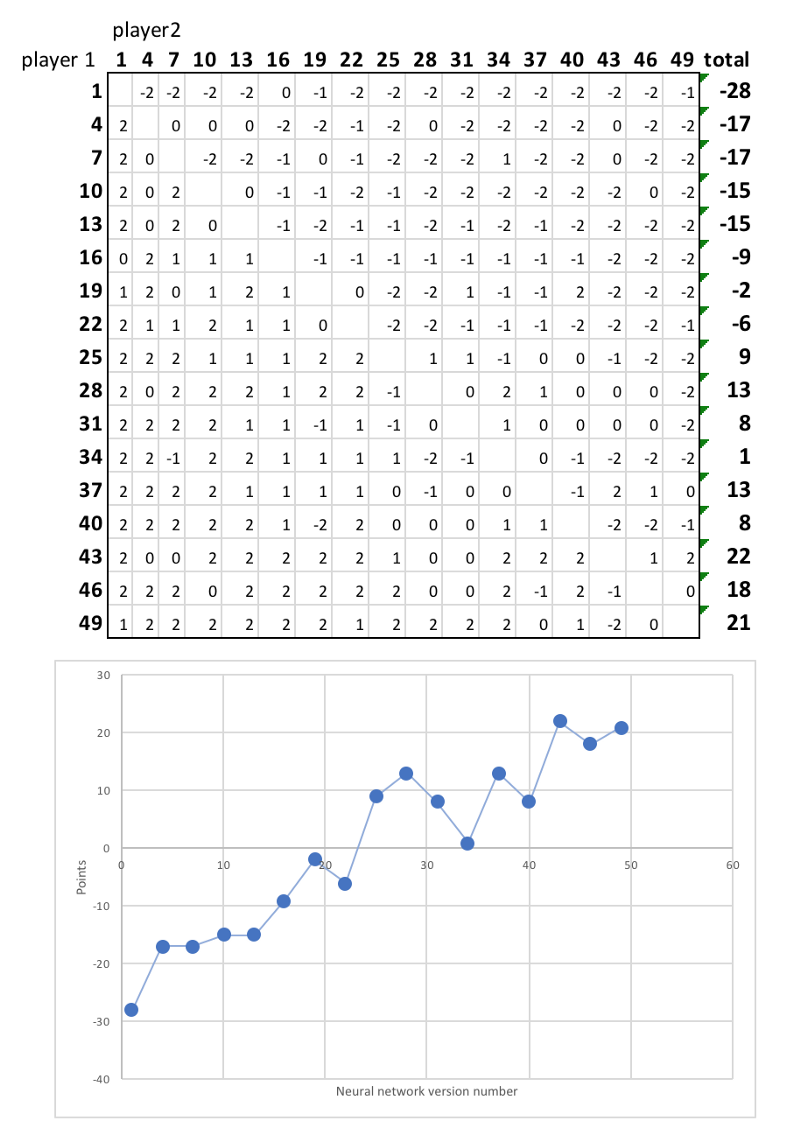
Очевидно, что более поздние версии нейронной сети превосходят более ранние версии, выигрывая большую часть игр. Со временем игроки будут совершенствоваться, изучая все более сложные стратегии.
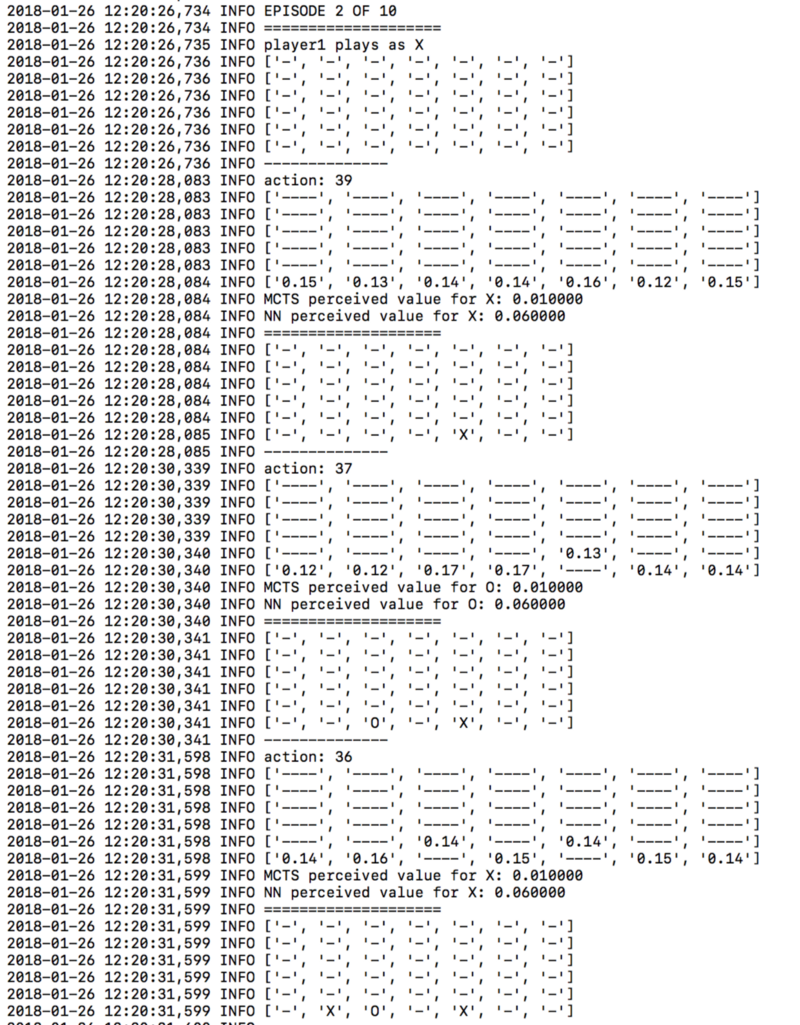
Например, одна четкая стратегия, которую нейронная сеть предпочитает с течением времени — это захват центрального столбца на ранней стадии. Обратите внимание на разницу между первой версией алгоритма и скажем, 30-й версией.
Первая версия нейронной сети:
Тридцатая версия:
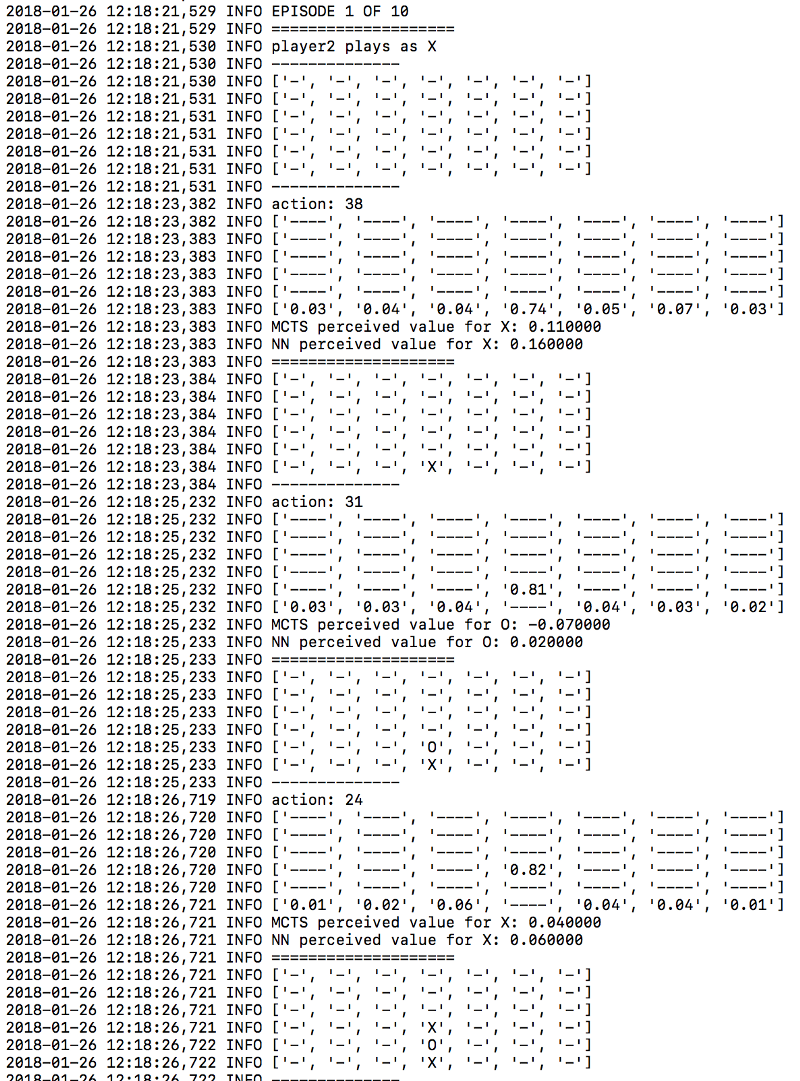
Это хорошая стратегия, так как для многих комбинаций требуется центральная колонка. Занимать центр нужно на ранних этапах, чтобы ваш оппонент не смог воспользоваться этим. Эта стратегия была изучена нейронной сетью без какого-либо вмешательства со стороны человека.
Заключение
Таким образом, мы доказали, что алгоритм AlphaZero является высокоэффективным. Его можно использовать для любых игр, в которых текущее положение известно всем участникам. Достаточно переработать файл game.py, описав логику игры. Надеемся, что из статьи вы вынесли полезный для себя материал.
Материалы по теме:
Телеграм: t.me/ainewsline
Источник: proglib.io