Классификация объектов в режиме реального времени
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-02-27 23:30
искусственный интеллект примеры, теория распознавания образов, машинное обучение новости

Распознавание изображений очень широко используется в машинном обучении. В этой области существует множество различных решений, однако потребностям нашего проекта ни оно из них не удовлетворяло. Нам понадобилось полностью локальное решение, которое способно работать на крошечном компьютере и передавать результаты распознавания на облачный сервис. В этой статье описывается наш подход к созданию решения для распознавания изображений с помощью TensorFlow.
Yolo
YOLO — это передовая система обнаружения объектов в реальном времени. На официальном сайте вы можете найти SSD300, SSD500, YOLOv2 и Tiny YOLO, которые прошли обучение с двумя различными наборами данных: VOC 2007+2012 и COCO. Еще больше вариантов конфигураций и наборов данных для машинного обучения вы можете найти в Интернете (например, YOLO9k). Благодаря широкому диапазону доступных вариантов можно выбрать версию, наиболее подходящую для ваших нужд. Например, Tiny YOLO — это самый «компактный» вариант, который может работать быстро даже на смартфонах или Raspberry Pi. Последний вариант нам понравился, и мы использовали его в нашем проекте.
DarkNet и TensorFlow
Модель Yolo была разработана для нейронной сети на основе DarkNet, для нас же некоторые особенности этого решения не подходят. DarkNet хранит обученные коэффициенты (веса) в формате, который может быть распознан с помощью различных методов на различных платформах. Эта проблема может быть камнем преткновения, потому что вам может понадобиться обучить модель на сверхмощном оборудовании, а затем использовать ее на другом оборудование. DarkNet написан на C и не имеет другого программного интерфейса, поэтому, если требования платформы или собственные предпочтения заставят вас обратиться к другому языку программирования, вам придется дополнительно поработать над его интеграцией. Также он распространяется только в формате исходного кода, и процесс компиляции на некоторых платформах может быть весьма проблематичным.
С другой стороны, у нас есть TensorFlow, удобная и гибкая вычислительная система, которая может использоваться на большинстве платформ. TensorFlow предоставляет API для Python, C ++, Java, Go и других языков программирования, поддерживаемых сообществом. Фреймворк с конфигурацией по умолчанию может быть установлен одним кликом мыши, но если вы хотите большего (например, поддержки конкретных инструкций процессора), можно легко провести компиляцию из источника с автоматическим определением аппаратного обеспечения. Запуск TensorFlow на графическом процессоре также довольно прост. Все, что вам нужно — это NVIDIA CUDA и tenorflow-gpu, специальный пакет с поддержкой графического процессора. Огромное преимущество TensorFlow — его масштабируемость. Он может использовать как несколько графических процессоров для повышения производительности, так и кластеризацию для распределенной обработки данных.
Мы решили взять лучшее из обоих миров и адаптировать модель YOLO для TensorFlow.
Адаптивный Yolo для TensorFlow
Итак, наша задача состояла в том, чтобы перенести модель YOLO на TensorFlow. Мы хотели избежать любых сторонних зависимостей и использовать YOLO напрямую с TensorFlow. Сначала нам нужно было перенести структуру модели, единственный способ сделать это — повторить модель послойно. К счастью для нас, есть много конвертеров с открытым исходным кодом, которые могут это сделать. Для наших целей наиболее подходящим решением оказался DarkFlow. Мы добавили простую функцию к DarkFlow, которая позволяет нам сохранять контрольные точки TensorFlow в метаданные, ее код можно посмотреть здесь. Вы можете сделать это вручную, но если хотите попробовать разные модели, проще автоматизировать этот процесс.
Выбранная нами модель YOLO имеет строгий размер массива входных данных 608x608 пикселей. Нам нужен был какой-то интерфейс, который может принимать любое изображение, нормализовать его и подавать в нейронную сеть. И мы этот интерфейс разработали. Для нормализации он использует TensorFlow, который работает гораздо быстрее, чем другие опробованные нами решения (нативный Python, numpy, openCV).
Последний слой модели YOLO возвращает функции, требующие преобразования в данные определенной формы, которые может прочитать человек. Мы добавили некоторые операции после последнего слоя, чтобы получить координаты зоны обнаружения.
В итоге мы разработали Python модуль, который может восстановить модель из файла, нормализовать входные данные и затем обработать функции из модели, чтобы получить ограничивающие поля для прогнозируемых классов.
Обучение модели
Для наших целей мы решили использовать предварительно обученную модель. Обученные коэффициенты доступны на официальном сайте YOLO. Следующей задачей было импортировать веса DarkNet в TensorFlow, это было сделано следующим образом:
- Считывание данных слоя в файле конфигурации DarkNet;
- Считывание обученных коэффициентов из файла весов DarkNet в соответствии со структурой слоя;
- Подготовка слоя TensorFlow на основе данных слоя DarkNet;
- Добавление связей в новом слое;
- Повторение для каждого слоя.
Для этого мы использовали DarkFlow.
Архитектура модели и поток данных

Обычно с каждой итерацией классификатор делает предположение относительно того, какой тип объекта находится в окне. Он выполняет тысячи прогнозов для каждого изображения. Это тормозит процесс, вследствие чего работа по распознаванию идет довольно медленно.
Самое большое преимущество модели YOLO, собственно, отражено в названии — You Only Look Once. Эта модель накладывает на изображение сетку, разделяя его на ячейки. Каждая ячейка пытается предсказать координаты зоны обнаружения с оценкой уверенности для этих полей и вероятностью классов. Затем оценка уверенности для каждой зоны обнаружения умножается на вероятность класса, чтобы получить окончательную оценку.
 Иллюстрация с сайта YOLO.
Иллюстрация с сайта YOLO.
Реализация
В нашем GitHub-репозитории вы можете найти демо-проект, который представляет собой предварительно обученную модель TensorFlow YOLO2. Данная модель может распознать 80 классов. Для ее запуска вам нужно установить дополнительные зависимости, необходимые для демонстрационных целей (для интерфейса модели требуется только TensorFlow). После установки просто запустите python eval.py, и он будет захватывать видеопоток с вашей веб-камеры, оценивать его и отображать результаты в простом окне со своими прогнозами. Процесс оценки — покадровый — и может занять некоторое время в зависимости от оборудования, на котором он запущен. На Raspberry Pi для оценки одного кадра может потребоваться несколько секунд.
Вы можете указать видеофайл для этого скрипта, передав аргумент --video наподобие этого: python eval.py --video="/path_to_video_file/". Также может быть передан URL видео (протестировано на YouTube): python eval.py --video=”https://www.youtube.com/watch?v=hfeNyZV6Dsk”.
Скрипт будет пропускать кадры с камеры во время оценки и принимать следующий доступный кадр, когда предыдущий этап оценки завершен. Для записанного видео он не пропускает никаких кадров. Для большинства задач вполне можно пропускать некоторые кадры, чтобы обеспечить работу процесса в реальном времени.
Интеграция с IoT
Конечно, было бы неплохо интегрировать в этот проект службу IoT, а также настроить доставку результатов распознавания туда, где к ним смогут получить доступ и другие службы.
Существует еще один демо-скрипт — python daemon.py, который будет запускать простой сервер, отображающий видеопоток с веб-камеры с прогнозами на
http://127.0.0.1:8000/events/
.

Он также запускает клиент DeviceHive. Конфигурация доступна на
http://127.0.0.1:8000/
.

Это позволяет отправлять всю прогнозируемую информацию в DeviceHive в виде уведомлений.
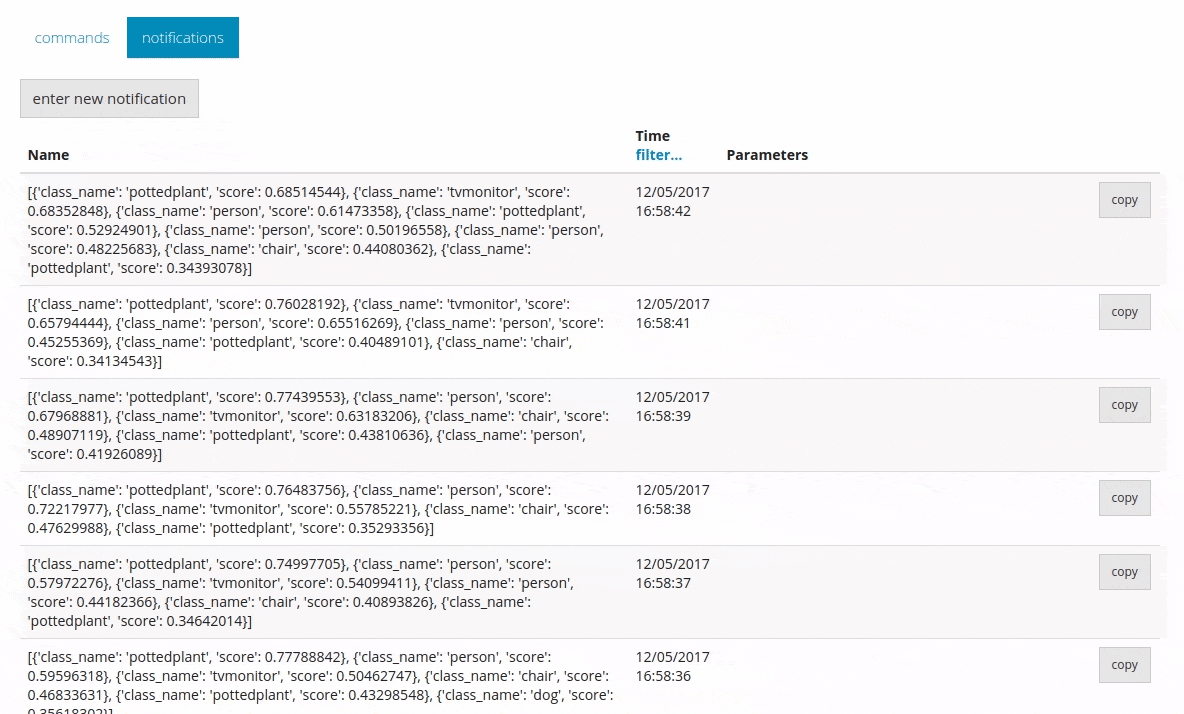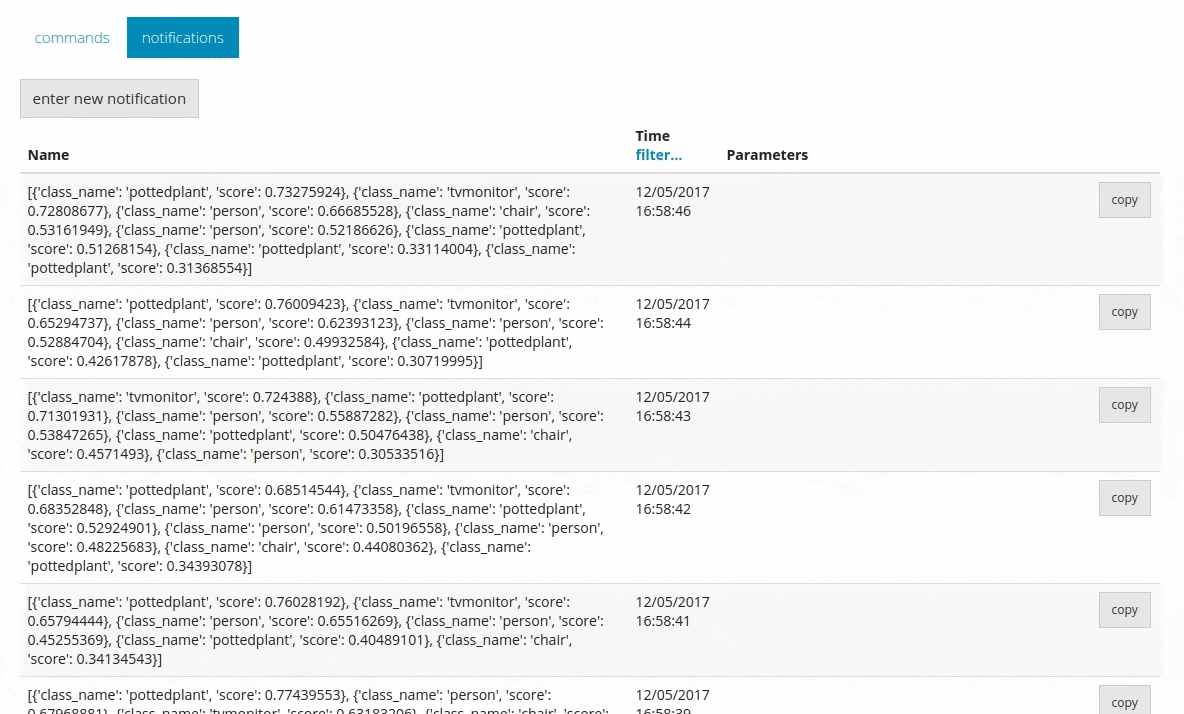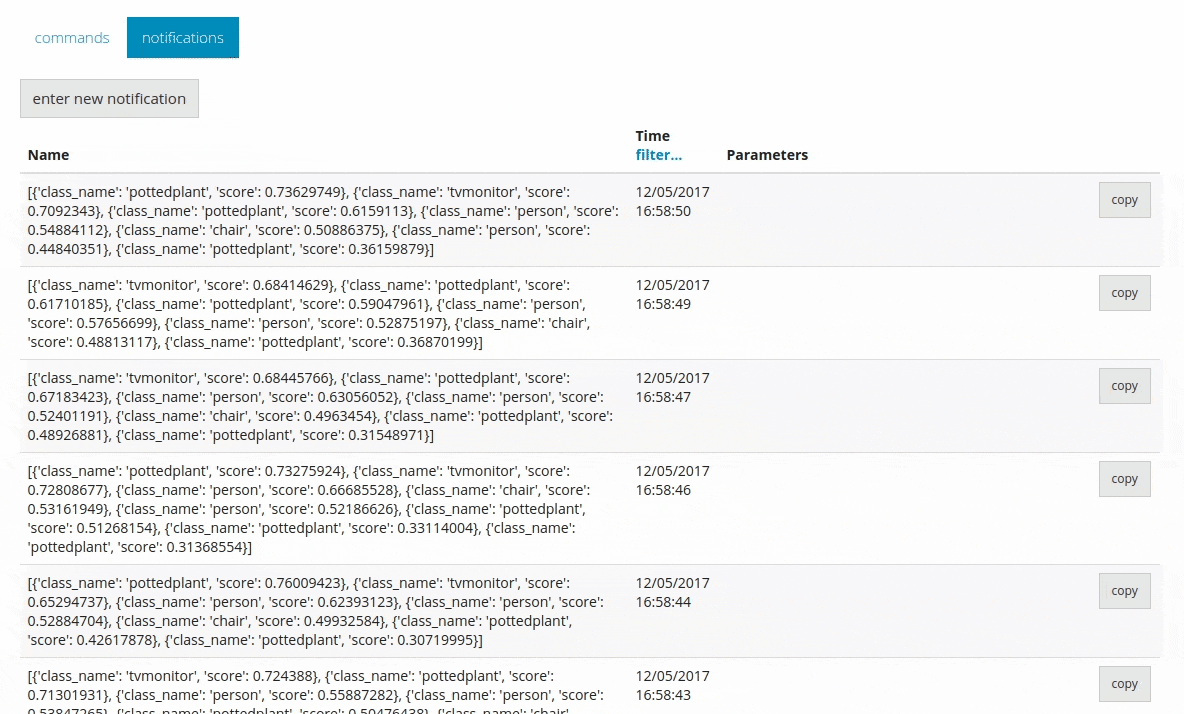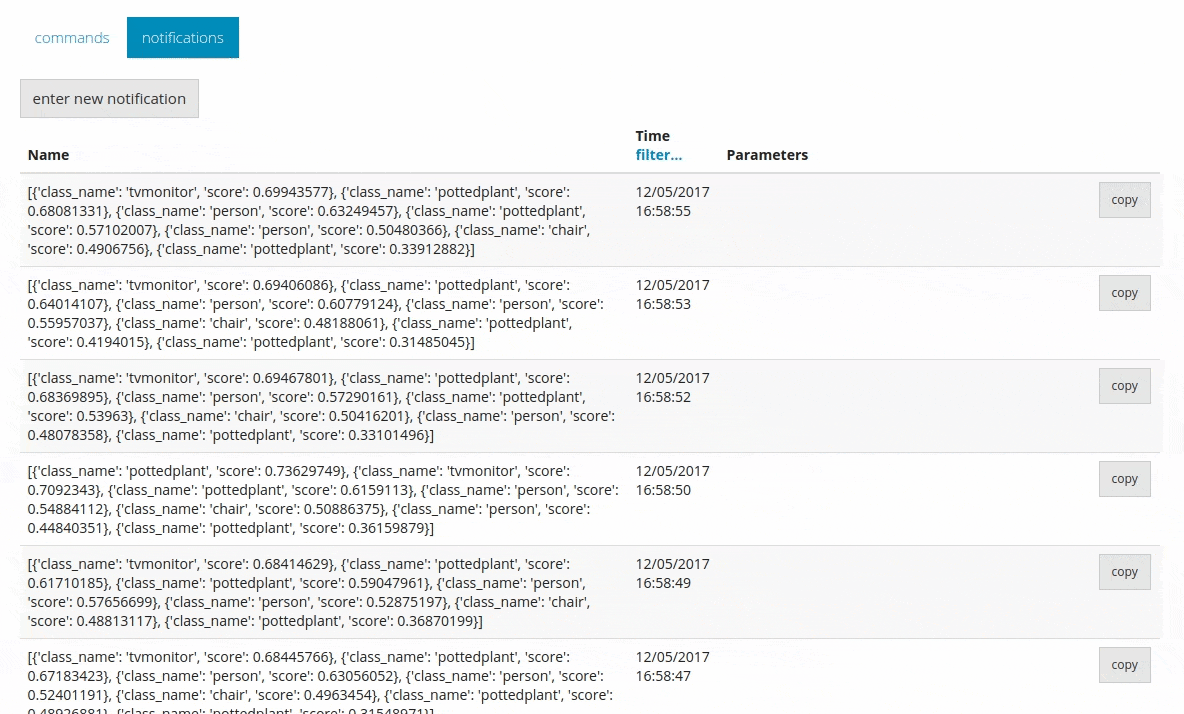
Вывод
Как видите, есть множество готовых проектов с открытым исходным кодом практически для любых случаев, нужно просто уметь правильно их использовать. Разумеется, необходимы определенные изменения, но внедрить их намного проще, чем создать новую модель с нуля. Огромное преимущество таких инструментов — их кроссплатформенность. Мы можем разработать решение на настольном ПК, а затем использовать тот же код на встраиваемых системах с операционной системой Linux и ARM-архитектурой. Мы очень надеемся, что наш проект поможет вам в создании собственного изящного решения.
P. S. За время разработки проекта и подготовки статьи к печати OpenCV обзавелся поддержкой YOLO внутри себя. Возможно, для некоторых случаев это решение будет более предпочтительным.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru