Распознавание жестов движений на Android используя Tensorflow
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-01-17 20:44
машинное обучение python, методы распознавания образов, реализация искусственного интеллекта

Введение
В сегодняшние дни есть много разных способов взаимодействия со смартфонами: тач-скрин, аппаратные кнопки, сканер отпечатков пальцев, видео камера (например система распознавания лиц), D-PAD, кнопки на гарнитуре, и так далее. Но что насчет использования жестов движений?
Например быстрое перемещение телефона вправо или влево держа его в руке может очень точно отражать намерение перейти на следующую или предыдущую песню в плей-листе. Или же вы можете быстро перевернуть телефон верх ногами и потом назад для обновления контента приложения. Внедрение такого взаимодействия выглядит многообещающим и буквально добавляет новое измерение в UX. Эта статья описывает как реализовать подобное используя машинное обучение и библиотеку Tensorflow для Android.
Описание
Давайте определимся с конечной целью. Хотелось бы чтоб смартфон распознавал быстрые движения влево и вправо.
Также хотелось бы чтоб реализация была в Android библиотеке и ее можно было легко интегрировать в любое другое приложение.
Жесты могут быть записаны на смартфоне используя несколько датчиков: акселерометр, гироскоп, магнитометр, и другие. Позже набор записанных жестов может быть использован в алгоритмах машинного обучения для распознавания.
Для записи данных будет разработано специальное приложение под Android. Препроцессинг и обучение будет производится на ПК в среде Jupyter Notebook используя язык Python и библиотеку TensorFlow. Распознавание жестов будет реализовано в демонстрационном приложении с использованием результатов обучения. В конце, мы разработаем готовую к использования Android библиотеку для распознавания жестов, которая может быть легко интегрирована в другие приложения.
Наш план реализации:
- Собрать данные на телефоне
- Разработать и обучить нейронную сеть
- Экспортировать нейронную сеть на смартфон
- Разработать тестовое приложение для Android
- Разработать Android библиотеку
Реализация
Подготовка данных
Для начала давайте определимся какие датчики и какой тип данных могут описать наши жесты. Похоже для точного описания этих жестов должны быть использованы и акселерометр и гироскоп.
Акселерометр очевидно измеряет ускорение и соответственно, перемещение:
 Акселерометр имеет интересные нюанс — он измеряет не только ускорение непосредственно телефона, но также и ускорение свободного падения которое приблизительно равно 9.8 м/с2. Это значит что величина вектора ускорения лежащего на на столе телефона будет равна 9.8. Такие значения не могут быть использованы напрямую и должны быть вычтены из значения вектора ускорения свободного падения. Это непростая задача потому что она требует совместной обработки данных магнетометра и акселерометра. К счастью, Android имеет специальный датчик «Линейный Акселерометр» который производит необходимые расчеты и возвращает корректные значения.
Акселерометр имеет интересные нюанс — он измеряет не только ускорение непосредственно телефона, но также и ускорение свободного падения которое приблизительно равно 9.8 м/с2. Это значит что величина вектора ускорения лежащего на на столе телефона будет равна 9.8. Такие значения не могут быть использованы напрямую и должны быть вычтены из значения вектора ускорения свободного падения. Это непростая задача потому что она требует совместной обработки данных магнетометра и акселерометра. К счастью, Android имеет специальный датчик «Линейный Акселерометр» который производит необходимые расчеты и возвращает корректные значения.
Гироскоп, с другой стороны, измеряет вращение:
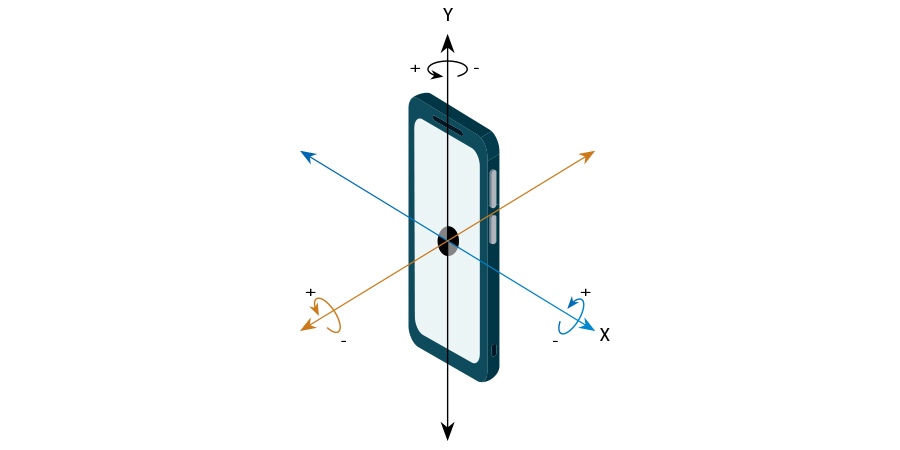 Попробуем определить, какие значения будут коррелировать с нашими жестами. Очевидно, что в акселерометре (имеется ввиду линейный акселерометр) значения X и Y будут в достаточно большой степени описывать жесты. Значение же Z акселерометра вряд ли будет зависеть от наших жестов.
Попробуем определить, какие значения будут коррелировать с нашими жестами. Очевидно, что в акселерометре (имеется ввиду линейный акселерометр) значения X и Y будут в достаточно большой степени описывать жесты. Значение же Z акселерометра вряд ли будет зависеть от наших жестов.
Что касается датчика гироскопа, кажется, что жесты слегка влияют на ось Z. Однако для упрощения реализации я предлагаю не включать его в расчет. В этом случае наш детектор жестов распознает перемещение телефона не только в руке, но и вдоль горизонтальной линии — например, на столе. Но это не слишком большая проблема.
Таким образом, нам необходимо разработать Android-приложение, которое может записывать данные акселерометра.
Я разработал такое приложение. Вот скриншот записанного жеста «вправо»:
 Как вы видите, оси X и Y очень сильно реагируют на жест. Ось Z также реагирует, но, как мы решили, она не будет включена в обработку.
Как вы видите, оси X и Y очень сильно реагируют на жест. Ось Z также реагирует, но, как мы решили, она не будет включена в обработку.
Вот жест «влево»:
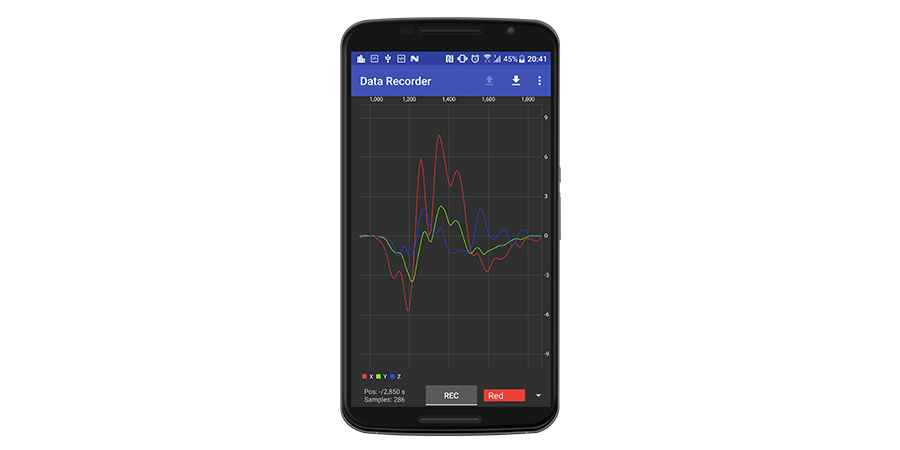 Обратите внимание, что значения X почти противоположны значениям из предыдущего жеста.
Обратите внимание, что значения X почти противоположны значениям из предыдущего жеста.
Еще одна вещь, которую нужно упомянуть, — это частота дискретизации данных. Она отражает то, как часто данные обновляются и напрямую влияет на объем данных за интервал времени.
Еще одна вещь, которую следует учитывать — это продолжительность жестов. Это значение, как и многие другие, следует выбирать эмпирически. Я установил, что продолжительность жестов длится не более 1 секунды, но, чтобы сделать значение более подходящим для расчетов, я округлил его до 1.28 секунды.
Выбранная частота обновления данных составляет 128 точек на 1.28 секунды, что дает задержку в 10 миллисекунд (1.28 / 128). Это значения должно быть передано в метод registerListener.
Идея состоит в том, чтобы обучить нейронную сеть распознаванию таких сигналов в потоке данных с акселерометра.
Итак, дальше нам нужно записать в файлы много семплов жестов. Конечно, один и тот же тип жестов (вправо или влево) должен быть помечен одним и тем-же же тегом. Трудно сказать заранее, сколько образцов необходимо для обучения сети, но это может быть определено в результате обучения.
Тапнув где либо на графике, вы выделите семпл — т.е. участок графика длинной 128 точек:
 Теперь кнопка «сохранить» будет активной. Нажатие по ней автоматически сохранит семпл в файле в рабочем каталоге в файл с именем вида «{label}_{timestamp}.log» Рабочий каталог может быть выбран в меню приложения.
Теперь кнопка «сохранить» будет активной. Нажатие по ней автоматически сохранит семпл в файле в рабочем каталоге в файл с именем вида «{label}_{timestamp}.log» Рабочий каталог может быть выбран в меню приложения.
Также обратите внимание, что после сохранения текущего семпла, следующий будет выбран автоматически. Следующий жест выбирается с использованием очень простого алгоритма: найти первую запись абсолютное значение X которой больше 3, затем перемотать назад 20 точек.
Такая автоматизация позволяет нам быстро сохранить много семплов. Я записал по 500 семплов на жест. Сохраненные данные должны быть скопированы на ПК для дальнейшей обработки. (Обработка и обучение прямо на телефоне выглядит интересно, но TensorFlow для Android в настоящее время не поддерживает обучение).
На снимке, представленном ранее, диапазон данных составляет примерно ±6. Однако, если вы сильнее махнете телефоном, он может достичь ±10. Данные лучше нормализовать так, чтоб диапазон был ±1, что намного лучше соответствует формату данных нейронной сети. Для этого я просто разделил все данные на константу — в моем случае 9.
Следующим шагом, который нужно выполнить перед началом обучения, это фильтрация данных для устранения высокочастотных колебаний. Такие колебания не имеют отношения к нашим жестам.
Существует много способов фильтрации данных. Один из них — фильтр Скользящее среднее. Вот пример того, как он работает:
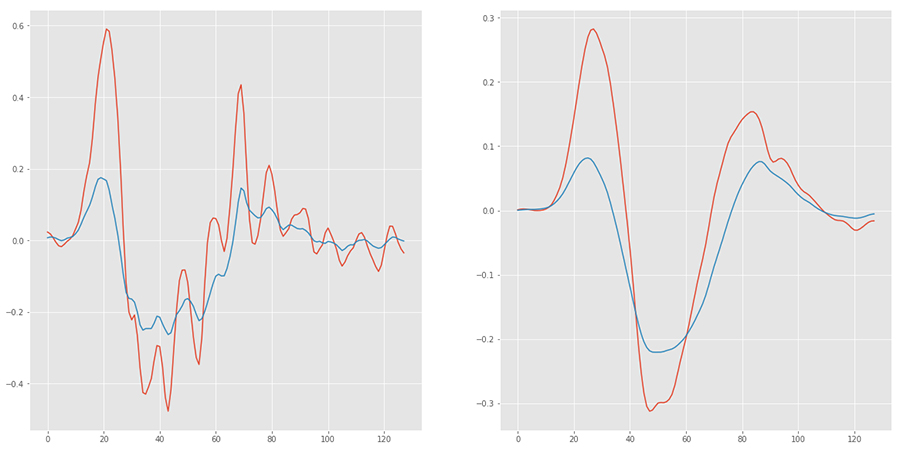 Обратите внимание, что максимальные значения X данных теперь составляют половину оригинала. Поскольку мы будем выполнять такую же фильтрацию данных в режиме реального времени во время распознавания, это не должно быть проблемой.
Обратите внимание, что максимальные значения X данных теперь составляют половину оригинала. Поскольку мы будем выполнять такую же фильтрацию данных в режиме реального времени во время распознавания, это не должно быть проблемой.
Последним шагом для улучшения обучения является аугментация данных. Этот процесс расширяет исходный набор данных, выполняя некоторые манипуляции. В нашем случае я просто переместил данные влево и вправо на несколько точек:
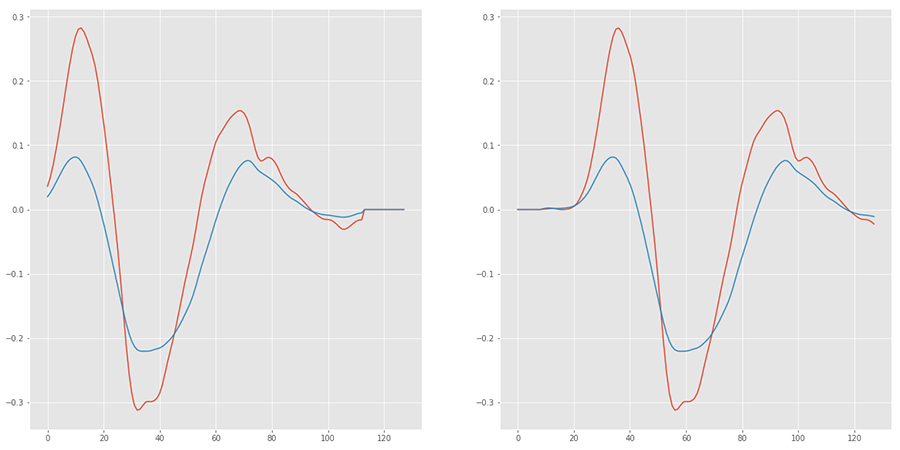
Проектирование нейронной сети
Проектирование нейронной сети — не простая задача и требует некоторого опыта и интуиции. С другой стороны, нейронные сети хорошо изучены для некоторых типов задач, и вы можете просто приспособить существующую сеть. Наша задача очень похожа на задачу классификации изображений; вход можно рассматривать как изображение с высотой 1 пиксель (и это так и есть — первая операция преобразует входные двумерных данных [128 столбцов x 2 канала] в трехмерные данные [1 строка x 128 колонок x 2 канала]).
Таким образом, вход нейронной сети это массив [128, 2].
Выход нейронной сети представляет собой вектор с длиной, равной числу меток. В нашем случае это [2] числа с плавающим типом данных двойной точности.
Ниже приведена схема нейронной сети:
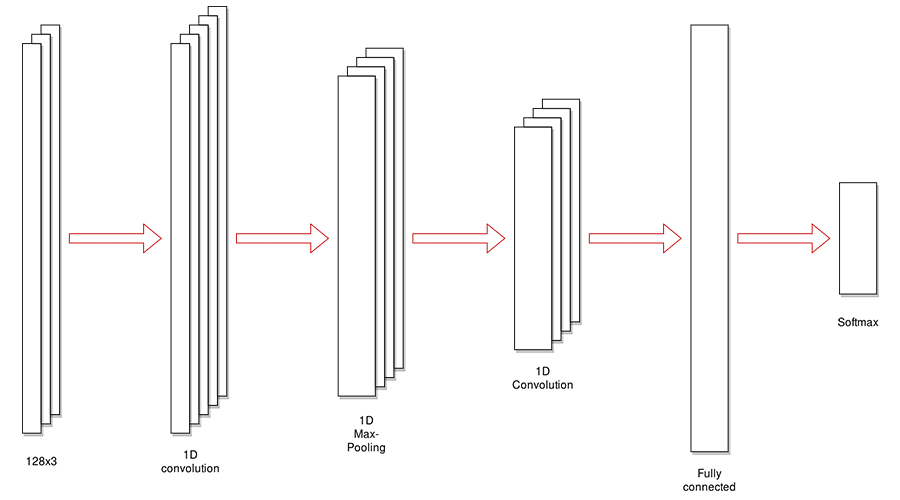 И подробная схема, полученная в TensorBoard:
И подробная схема, полученная в TensorBoard:
 Эта схема содержит некоторые вспомогательные узлы, необходимые только для обучения. Позже я покажу чистую, оптимизированную картину.
Эта схема содержит некоторые вспомогательные узлы, необходимые только для обучения. Позже я покажу чистую, оптимизированную картину.
Обучение
Обучение будет проводиться на ПК в среде Jupyter Notebook с использованием Python и библиотеки TensorFlow. Notebook можно запустить в среде Conda, используя следующий файл конфигурации. Вот некоторые гипер-параметры обучения:
Оптимизатор: Adam Количество эпох обучения: 3 Скорость обучения (learning rate): 0.0001 Набор данных разделен на обучающие и проверочные в соотношении 7 к 3.
Качество обучения можно контролировать с помощью значений точности обучения и тестирования. Точность обучения должна приближаться, но не достигать 1. Слишком низкое значение будет указывать на плохое и неточное распознавание, а слишком высокое значение приведет к переобучению модели и может привести к некоторым артефактам во время распознавания, например, распознавание с ненулевым значением для данных без жестов. Хорошая точность тестирования является доказательством того, что обученная модель может распознавать данные которых раньше никогда не видела.
Протокол обучения:
('Epoch: ', 0, ' Training Loss: ', 0.054878365, ' Training Accuracy: ', 0.99829739) ('Epoch: ', 1, ' Training Loss: ', 0.0045060506, ' Training Accuracy: ', 0.99971622) ('Epoch: ', 2, ' Training Loss: ', 0.00088313385, ' Training Accuracy: ', 0.99981081) ('Testing Accuracy:', 0.99954832) Граф TensorFlow и связанные с ним данные можно сохранить в файлы, используя следующие методы:
saver = tf.train.Saver() with tf.Session() as session: session.run(tf.global_variables_initializer()) # save the graph tf.train.write_graph(session.graph_def, '.', 'session.pb', False) for epoch in range(training_epochs): # train saver.save(session, './session.ckpt') Полный код можно найти здесь.
Экспорт нейронной сети
Как сохранить данные TensorFlow было показано в предыдущем разделе. Граф сохраняется в файле session.pb, а данные обучения (веса и т.д.) сохраняются в нескольких файлах «session.ckpt». Эти файлы могут быть достаточно большими:
session.ckpt.data-00000-of-00001 3385232 session.ckpt.index 895 session.ckpt.meta 65920 session.pb 47732 Граф и данные обучения можно заморозить и преобразовать в один файл, подходящий для работы на мобильном устройстве.
Чтобы заморозить его, скопируйте файл tensorflow/python/tools/freeze_graph.py в каталог скрипта и выполните следующую команду:
python freeze_graph.py --input_graph=session.pb --input_binary=True --input_checkpoint=session.ckpt --output_graph=frozen.pb --output_node_names=labels_output где output_graph выходной файл, а output_node_names — имя выходного узла. Это значение указывается в коде Python.
Полученный файл меньше предыдущих, но все еще достаточно большой:
frozen.pb 1130835
Вот как выглядит эта модель в TensorBoard:
 Чтобы получить такое изображение, скопируйте файл tensorflow/python/tools/import_pb_to_tensorboard.py в каталог скрипта и запустите:
Чтобы получить такое изображение, скопируйте файл tensorflow/python/tools/import_pb_to_tensorboard.py в каталог скрипта и запустите:python import_pb_to_tensorboard.py --model_dir=frozen.pb --log_dir=tmp где frozen.pb — файл модели.
Теперь запустите TensorBoard:
tensorboard --logdir=tmp Существует несколько способов оптимизации модели для мобильной среды. Чтобы запустить описанные далее команды, вам необходимо скомпилировать TensorFlow из исходников:
1. Удаление неиспользуемых узлов и общая оптимизация. Выполните:
bazel build tensorflow/tools/graph_transforms:transform_graph bazel-bin/tensorflow/tools/graph_transforms/transform_graph --in_graph=mydata/frozen.pb --out_graph=mydata/frozen_optimized.pb --inputs='x_input' --outputs='labels_output' --transforms='strip_unused_nodes(type=float, shape="128,2") remove_nodes(op=Identity, op=CheckNumerics) round_weights(num_steps=256) fold_constants(ignore_errors=true) fold_batch_norms fold_old_batch_norms' Результат:
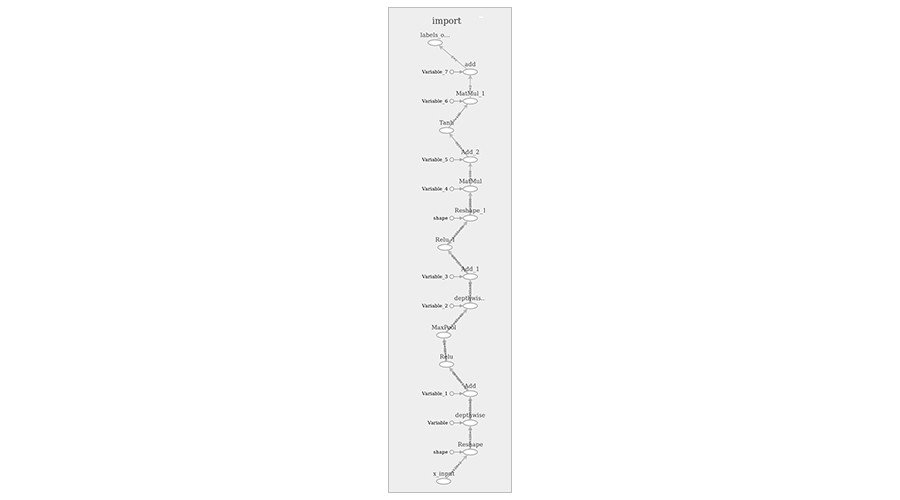 2. Квантование (конвертирование формата данных с плавающей запятой в 8-битный целочисленный формат). Выполните:
2. Квантование (конвертирование формата данных с плавающей запятой в 8-битный целочисленный формат). Выполните:bazel-bin/tensorflow/tools/graph_transforms/transform_graph --in_graph=mydata/frozen_optimized.pb --out_graph=mydata/frozen_optimized_quant.pb --inputs='x_input' --outputs='labels_output' --transforms='quantize_weights strip_unused_nodes' В результате выходной файл имеет размер 287129 байт по сравнению с исходным 3,5 МБ. Этот файл можно использовать в TensorFlw для Android.
Демонстрационное приложение для Android
Чтобы выполнить распознавание сигналов в приложении Android, необходимо подключить библиотеку TensorFlow для Android в проект. Добавьте библиотеку к зависимостям gradle:
dependencies { implementation 'org.tensorflow:tensorflow-android:1.4.0' } Теперь вы можете получить доступ к API TensorFlow через класс TensorFlowInferenceInterface. Сначала поместите файл «frozen_optimized_quant.pb» в каталог «assets» вашего приложения (т.е. «app/src/main/assets») и загрузите его в коде (например, при запуске Activity, однако, как обычно, лучше производить любые операции ввода/вывода в фоновом потоке):
inferenceInterface = new TensorFlowInferenceInterface(getAssets(), “file:///android_asset/frozen_optimized_quant.pb”); Обратите внимание, как указан файл модели.
Наконец, можно выполнить распознавание:
float[] data = new float[128 * 2]; String[] labels = new String[]{"Right", "Left"}; float[] outputScores = new float[labels.length]; // populate data array with accelerometer data inferenceInterface.feed("x_input", data, new long[] {1, 128, 2}); inferenceInterface.run(new String[]{“labels_output”}); inferenceInterface.fetch("labels_output", outputScores); Данные поступают на вход нашего «черного ящика» в виде одномерного массива, содержащего последовательные данные X и Y акселерометра, то есть формат данных [x1, y1, x2, y2, x3, y3, ..., x128, y128].
На выходе мы имеем два числа с плавающей запятой в диапазоне 0...1, значения которых — это соответствие входных данных жестам «влево» или «вправо». Обратите внимание, что сумма этих значений равна 1. Таким образом, например, если входной сигнал не совпадает ни с левым, ни с правым жестом, то выход будет близок к [0,5, 0,5]. Для упрощения лучше преобразовать эти значения в абсолютные значения 0...1, используя простую математику.
Кроме того, не забываем выполнить фильтрацию и нормализацию данных перед запуском распознавания.
Вот скриншот окна тестирования демонстрационного приложения:
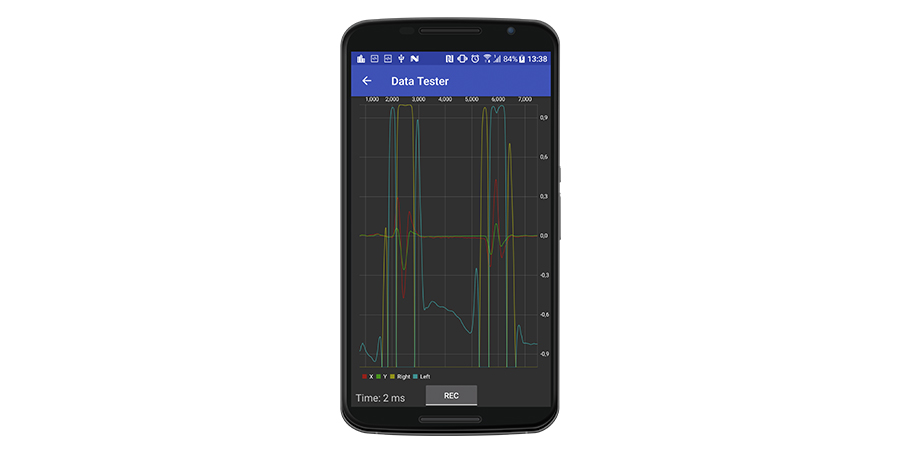 где красные и зеленые линии представляют собой предварительно обработанный сигнал в режиме реального времени. Желтые и голубые линии относятся к «исправленным» «правым» и «левым» жестам соответственно. «Время» — это время обработки одного семпла, и оно довольно низкое, что позволяет выполнять распознавание в реальном времени (два миллисекунды означают, что обработка может выполняться со скоростью 500 Гц, мы же настроили акселерометр на обновление со скоростью 100 Гц).
где красные и зеленые линии представляют собой предварительно обработанный сигнал в режиме реального времени. Желтые и голубые линии относятся к «исправленным» «правым» и «левым» жестам соответственно. «Время» — это время обработки одного семпла, и оно довольно низкое, что позволяет выполнять распознавание в реальном времени (два миллисекунды означают, что обработка может выполняться со скоростью 500 Гц, мы же настроили акселерометр на обновление со скоростью 100 Гц).Как вы можете видеть, есть некоторые нюансы. Во-первых, существуют некоторые ненулевые значения распознавания даже для «пустого» сигнала. Во-вторых, каждый жест имеет длительное «истинное» распознавание в центре со значением, близким к 1.0, и небольшим противоположным распознаванием по краям.
Похоже, для выполнения точного фактического распознавания жестов требуется дополнительная обработка.
Библиотека под Android
Я реализовал распознавание с помощью TensorFlow вместе с дополнительной обработкой выходных данных в отдельной библиотеке под Android. Библиотека и демонстрационное приложение находятся здесь.
Чтобы использовать библиотеку в своем приложении, добавьте зависимость на библиотеку в файл gradle:
repositories { maven { url "https://dl.bintray.com/rii/maven/" } } dependencies { ... implementation 'uk.co.lemberg:motiondetectionlib:1.0.0' } создайте MotionDetector слушатель:
private final MotionDetector.Listener gestureListener = new MotionDetector.Listener() { @Override public void onGestureRecognized(MotionDetector.GestureType gestureType) { Log.d(TAG, "Gesture detected: " + gestureType); } }; и включите распознавание:
MotionDetector motionDetector = new MotionDetector(context, gestureListener); motionDetector.start(); Заключение
Мы прошли все этапы разработки и внедрения распознавания жестов движения в приложении Android, используя библиотеку TensorFlow: сбор и предварительную обработку данных, разработку и обучение нейронной сети, а также разработку тестового приложения и готовой к использованию библиотеки для Android. Описанный подход может использоваться для любых других задач распознавания или классификации. Полученная библиотека может быть интегрирована в любое другое приложение для Android, чтобы сделать возможным управление ним с помощью жестов движения.
Надеюсь, вы нашли эту статью полезной, вы также можете посмотреть видео обзор ниже.
Если у вас есть идея проекта, но не знаете, с чего начать, мы всегда здесь, чтобы Вам помочь.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru