Итоги развития компьютерного зрения за один год
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2018-01-06 18:22
техническое зрение, теория программирования, архитектура нейронных сетей, методы распознавания образов
Этот фрагмент взят из недавней публикации, которую составила наша научно-исследовательская группа в области компьютерного зрения. В ближайшие месяцы мы опубликуем работы на разные темы исследований в области Искусственного Интеллекта ?—? о его экономических, технологических и социальных приложениях — с целью предоставить образовательные ресурсы для тех, кто желает больше узнать об этой удивительной технологии и её текущем состоянии. Наш проект надеется внести свой вклад в растущую массу работ, которые обеспечивают всех исследователей информацией о самых современных разработках ИИ.
Введение
Компьютерным зрением обычно называют научную дисциплину, которая даёт машинам способность видеть, или более красочно, позволяя машинам визуально анализировать своё окружение и стимулы в нём. Этот процесс обычно включает в себя оценку одного или нескольких изображений или видео. Британская ассоциация машинного зрения (BMVA) определяет компьютерное зрение как «автоматическое извлечение, анализ и понимание полезной информации из изображения или их последовательности».
Термин понимание интересно выделяется на фоне механического определения зрения — и демонстрирует одновременно и значимость, и сложность области компьютерного зрения. Истинное понимание нашего окружения достигается не только через визуальное представление. На самом деле визуальные сигналы проходят через оптический нерв в первичную зрительную кору и осмысливаются мозгом в сильно стилизованном смысле. Интерпретация этой сенсорной информации охватывает почти всю совокупность наших естественных встроенных программ и субъективного опыта, то есть как эволюция запрограммировала нас на выживание и что мы узнали о мире в течение жизни.
В этом отношении зрение относится только к передаче изображений для интерпретации; а компьютинг указывает на то, что изображения больше походят на мысли или сознание, опираясь на множество способностей мозга. Поэтому многие верят, что компьютерное зрение, истинное понимание визуального окружения и его контекста, прокладывает путь к будущим вариациям Сильного Искусственного Интеллекта благодаря совершенному освоению работы в междоменных областях.
Но не хватайтесь за оружие, потому что мы ещё практически не вышли из зачаточной стадии развития этой потрясающей области. Эта статья должна просто пролить немного света на самые значительные достижения компьютерного зрения в 2016 году. И возможно попытаться вписать некоторые из этих достижений в здравую смесь ожидаемых краткосрочных общественных взаимодействий и, где это применимо, гипотетических прогнозов завершения нашей жизни в том виде, какой мы её знаем.
Хотя наши работы всегда написаны максимально доступным образом, разделы в этой конкретной статье могут показаться немного неясными из-за предмета обсуждения. Мы везде предлагаем определения на примитивном уровне, но они дают только поверхностное понимание ключевых концепций. Концентрируясь на работах 2016 года, мы часто делаем пропуски ради краткости изложения.
Одно из таких очевидных упущений относится к функциональности свёрточных нейронных сетей (CNN), которые повсеместно применяются в области компьютерного зрения. Успех AlexNet в 2012 году, архитектуры CNN, которая ошеломила конкурентов в конкурсе ImageNet, стала свидетельством революции, которая де-факто произошла в этой области. Впоследствии многочисленные исследователи начали использовать системы на основе CNN, а свёрточные нейросети стали традиционной технологией в компьютерном зрении.
Прошло более четырёх лет, а варианты CNN по-прежнему составляют основную массу новых нейросетевых архитектур для задач компьютерного зрения. Исследователи переделывают их как кубики конструктора. Это реальное доказательство мощи как open source научных публикаций, так и глубинного обучения. Однако объяснение свёрточных нейросетей легко растянется на несколько статей, так что лучше оставить его для тех, кто более глубоко разбирается в предмете и имеет желание объяснить сложные вещи понятным языком.
Для обычных читателей, которые желают быстро вникнуть в тему перед продолжением этой статьи, рекомендуем первые два источника из перечисленных ниже. Если вы желаете ещё более погрузиться в предмет, то для этого мы приводим ещё и другие источники:
- «Что глубокая нейронная сеть думает о твоём селфи» от Андрея Карпаты — одна из лучших статей, которая помогает людям понять применение и функциональность свёрточных нейросетей.
- Quora: «Что такое свёрточная нейросеть?» — здесь полно отличных ссылок и объяснений. Особенно подходит для тех, у кого не было предварительного понимания в этой области.
- CS231n: «Свёрточные нейросети для визуального распознавания» от Стенфордского университета — отличный ресурс для более глубокого изучения темы.
- «Глубокое обучение» (Goodfellow, Bengio & Courville, 2016) даёт подробное объяснение функций свёрточных нейросетей и функциональности в главе 9. Авторы любезно опубликовали этот учебник бесплатно в формате HTML.
Для более полного понимания нейросетей и глубокого обучения в целом мы рекомендуем:
- «Нейросети и глубокое обучение» (Nielsen, 2017) — бесплатный онлайновый учебник, который обеспечивает действительно интуитивное понимание всех сложностей нейросетей и глубокого обучения. Даже чтение первой части должно во многом осветить для новичков тему предмета этой статьи.
В целом эта статья разрозненна и скачкообразна, отражая восхищение авторов и дух того, каким образом её предполагается использовать, раздел за разделом. Информация поделена на части в соответствии с нашими собственными эвристиками и суждениями, необходимый компромисс из-за междоменного влияния такого большого количества научных работ.
Надеемся, что читатели извлекут пользу из нашего обобщения информации, и она позволит им усовершенствовать свои знания, независимо от предыдущего багажа.
От лица всех участников,
The M Tank
Классификация/локализация
Задача классификации по отношению к изображениям обычно заключается в присвоении метки целому изображению, например, «кот». С учётом этого локализация может означать определение, где находится объект на этом изображении. Обычно тот обозначается неким ограничивающим прямоугольником вокруг объекта. Нынешние методы классификации на ImageNet уже превосходят группы специально обученных людей по точности классификации объектов.
Рис. 1: Задачи компьютерного зрения
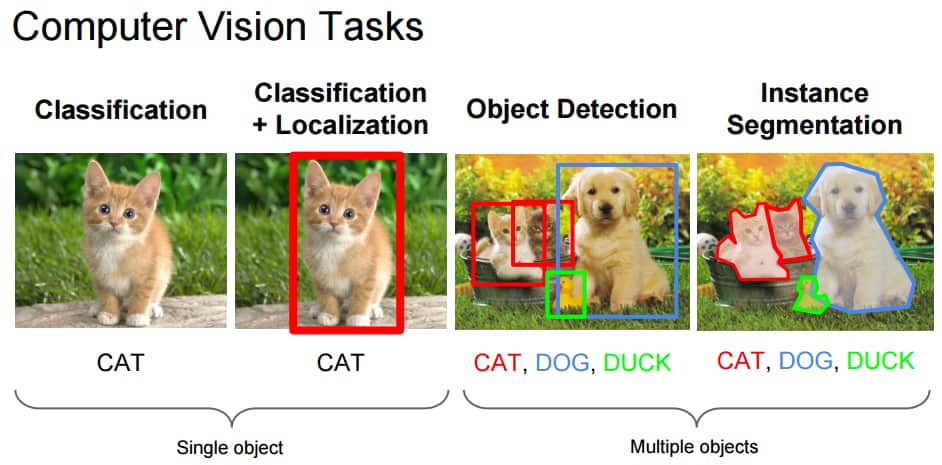
Источник: Fei-Fei Li, Andrej Karpathy & Justin Johnson (2016) cs231n, лекция 8 —?слайд 8, пространственная локализация и обнаружение (01/02/2016), pdf
Однако увеличение количества классов, вероятно, обеспечит новые метрики для измерения прогресса в ближайшем будущем. В частности, Франсуа Шолле, создатель Keras, применил новые методы, в том числе популярную архитектуру Xception, к внутреннему набору данных Google с более чем 350 млн изображений с множественными метками, содержащими 17 000 классов.
Рис. 2: Результаты классификации/локализации с конкурса ILSVRC (2010–2016)
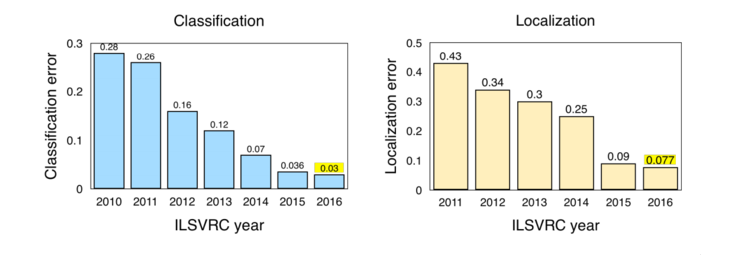
Примечание: Конкурс ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Улучшение результатов после 2011–2012 гг связано с появлением AlexNet. См. обзор требований конкурса в отношении классификации и локализации
Источник: Jia Deng (2016). Локализация объектов ILSVRC2016: введение, результаты. Слайд 2, pdf
Интересные выдержки с ImageNet LSVRC (2016):
- Классификация сцены обозначает задачу присвоения меток изображению с определённым классом сцены, таким как «оранжерея», «стадион», «собор» и т.д. В рамках ImageNet в прошлом году прошёл конкурс по классификации сцен на выборке из набора данных Places2: 8 млн изображений для обучения с 365 категориями сцен.
Победил Hikvision с результатом 9% ошибок топ-5. Система сконструирована из набора глубоких нейросетей в стиле Inception и не-таких-глубоких остаточных сетей. - Trimps-Soushen выиграл в задаче классификации ImageNet с ошибкой классификации 2,99% топ-5 и ошибкой локализации 7,71%. Разработчики составили систему из нескольких моделей (усреднив результаты моделей Inception, Inception-Resnet, ResNet и Wide Residual Networks), а в локализации по меткам победил Faster R-CNN. Набор данных был распределён между 1000 классов изображений с 1,2 млн изображений для обучения. Набор данных для тестирования содержал ещё 100 тыс. изображений, которые нейросети раньше не видели.
- Нейросеть ResNeXt от Facebook финишировала с небольшим отрывом на втором месте с ошибкой классификации 3,03% топ-5. Здесь использовалась новая архитектура, расширяющая оригинальную архитектуру ResNet.
Обнаружение объектов
Как можно догадаться, процесс обнаружения объектов делает именно то, что должен делать — обнаруживает объекты на изображениях. Определение обнаружения объектов от ILSVRC 2016 включает в себя выдачу ограничивающих рамок и меток для отдельных объектов. Это отличается от задачи классификации/локализации, поскольку здесь классификация и локализация применяются ко многим объектам, а не к одному доминирующему объекту.
Рис. 3: Обнаружение объектов, где лицо является единственным классом

Примечание: Картинка представляет собой пример обнаружения лиц как обнаружения объектов одного класса. Авторы называют одной из неизменных проблем в этой области обнаружение маленьких объектов. Используя маленькие лица как тестовый класс, они исследовали роль инвариантности размеров, разрешений изображения и контекстуальных обоснований.
Источник: Hu, Ramanan (2016, p. 1)
Одной из главных тенденций 2016 года в области обнаружения объектов стал переход к более быстрым и эффективным системам обнаружения. Это видно по таким подходам как YOLO, SSD и R-FCN в качестве шага к совместным вычислениям на всём изображении целиком. Этим они отличаются от ресурсоёмких подсетей, связанных с техниками Fast/Faster R-CNN. Такую методику обычно называют «тренировкой/обучением от начала до конца» (end-to-end training/learning).
По сути идея состоит в том, чтобы избежать применения отдельных алгоритмов для каждой из подпроблем в изоляции друг от друга, поскольку обычно это повышает время обучения и снижает точность нейросети. Говорится, что такая адаптация нейросетей для работы от начала до конца обычно происходит после работы первоначальных подсетей и, таким образом, представляет собой ретроспективную оптимизацию. Однако техники Fast/Faster R-CNN остаются высокоэффективными и по-прежнему широко используются для обнаружения объектов.
- SSD: Single Shot MultiBox Detector использует единую нейронную сеть, которая выполняет все необходимые вычисления и устраняет необходимость в ресурсоёмких методах предыдущего поколения. Он демонстрирует «75,1% mAP, превосходя сравнимую самую современную модель Faster R-CNN».
- Одной из самых впечатляющих разработок 2016 года можно назвать систему, метко названную YOLO9000: Better, Faster, Stronger, в которой используются системы обнаружения YOLOv2 и YOLO9000 (YOLO означает You Only Look Once). YOLOv2 — это сильно улучшенная модель YOLO от середины 2015 года, и она способна показать лучшие результаты на видео с очень высокой частотой кадров (до 90 FPS на изображениях низкого разрешения при использовании обычного GTX Titan X). Вдобавок к повышению скорости, система превосходит Faster RCNN с ResNet и SSD на определённых наборах данных для определения объектов.
YOLO9000 реализует совмещённый метод обучения для обнаружения и классификации объектов, расширяющий его возможности предсказания за пределы доступных размеченных данных обнаружения. Другими словами, он способен обнаруживать объекты, которые никогда не встречались в размеченных данных. Модель YOLO9000 обеспечивает обнаружение объектов в реальном времени среди более 9000 категорий, что нивелирует разницу в размере наборов данных для классификации и обнаружения. Дополнительные подробности, предобученные модели и видеодемонстрацию см. здесь.
Обнаружение объектов YOLOv2 работает на кадрах фильма с Джеймсом Бондом
- Система Feature Pyramid Networks for Object Detection разработана в научно-исследовательском подразделении FAIR (Facebook Artificial Intelligence Research). В ней применяется «врождённая многомасштабная пирамидальная иерархия глубоких свёрточных нейросетей для конструирования пирамид признаков с минимальными дополнительными затратами». Это означает сохранение мощных репрезентаций без потери скорости и дополнительных затрат памяти. Разработчики добились рекордных показателей на наборе данных COCO (Common Objects in Context). В сочетании с базовой системой Faster R-CNN она превосходит результаты победителей 2016 года.
- R-FCN: Object Detection via Region-based Fully Convolutional Networks. Ещё один метод, в котором разработчики отказались от применения ресурсоёмких подсетей для отдельных регионов изображения сотни раз на каждой картинке. Здесь детектор по регионам полностью свёрточный и производит совместные вычисления на всём изображении целиком. «При тестировании скорость работы составила 170 мс на одно изображение, что в 2,5–20 раз быстрее, чем у Faster R-CNN», — пишут авторы.
Рис. 4: Компромисс между точностью и размером объектов при обнаружении объектов на разных архитектурах

Примечание: По вертикальной оси отложен показатель mAP (mean Average Precision), а по горизонтальной оси — разнообразие мета-архитектур для каждого блока извлечения признаков (VGG, MobileNet… Inception ResNet V2). Вдобавок, малый, средний и большой mAP показывают среднюю точность для малых, средних и крупных объектов, соответственно. По существу, точность зависит от размера объекта, мета-архитектуры и блока извлечения признаков. При этом «размер изображения зафиксирован на 300 пикселях». Хотя модель Faster R-CNN относительно неплохо показала себя в данном примере, важно отметить, что эта мета-архитектура значительно медленнее, чем более современные подходы, такие как R-FCN.
Источник: Huang et al. (2016, p. 9)
В вышеупомянутой научной статье представлено подробное сравнение производительности R-FCN, SSD и Faster R-CNN. Из-за сложностей точного сравнения техник машинного обучения мы хотели бы указать на достоинства создания стандартизированного подхода, описанного авторами. Они рассматривают эти архитектуры как «мета-архитектуры», потому что их можно сочетать с разными блоками извлечения признаков, такими как ResNet или Inception.
Авторы изучают компромиссы между точностью и скоростью работы в разных мета-архитектурах, блоках извлечения признаков и разрешениях. Например, выбор блока извлечения признаков сильно изменяет результаты работы на различных мета-архитектурах.
В научных статьях с описанием SqueezeDet и PVANet ещё раз подчёркивается необходимость компромисса между тенденцией повышения скорости работы приложением со снижением потребляемых вычислительных ресурсов — и сохранением точности, которая требуется для коммерческих приложений реального времени, особенно в приложениях беспилотного автотранспорта. Хотя китайская компания DeepGlint показывала хороший пример обнаружения объектов в реальном времени в потоке с камеры видеонаблюдения.
Определение объектов, отслеживание объектов и распознавание лиц в системе DeepGlint
Результаты ILSVRC и COCO Detection Challenge
COCO (Common Objects in Context) — ещё один популярный набор данных изображений. Однако он относительно меньше по размеру и тщательнее курируется, чем альтернативы вроде ImageNet. Он нацелен на распознавание объектов с более широким контекстом понимания сцены. Организаторы проводят ежегодный конкурс на обнаружение объектов, сегментацию и ключевые точки. Вот результаты с конкурсов ILSVRC и COCO на обнаружение объектов:
- ImageNet LSVRC, обнаружение объектов на изображениях (DET): Система CUImage показала 66% meanAP. Выиграла в 109 из 200 категорий объектов.
- ImageNet LSVRC, обнаружение объектов на видео (VID): NUIST 80,8% meanAP
- ImageNet LSVRC, обнаружение объектов на видео с отслеживанием: CUvideo 55,8% meanAP
- COCO 2016, обнаружение объектов (ограничивающие рамки): G-RMI (Google) 41,5% AP (абсолютный прирост в 4,2 п.п. по сравнению с победителем 2015 года — MSRAVC)
В обзоре результатов, показанных системами обнаружения объектов 2016 года, ImageNet пишет, что MSRAVC 2015 установила очень высокую планку по производительности (первое появление сетей ResNet на этом соревновании). Производительность систем улучшилась во всех классах. В обоих конкурсах сильно улучшилась локализация. Достигнуто значительное улучшение на объектах маленького размера.
Рис. 5: Результаты систем обнаружения на изображениях в конкурсе ILSVRC (2013–2016)
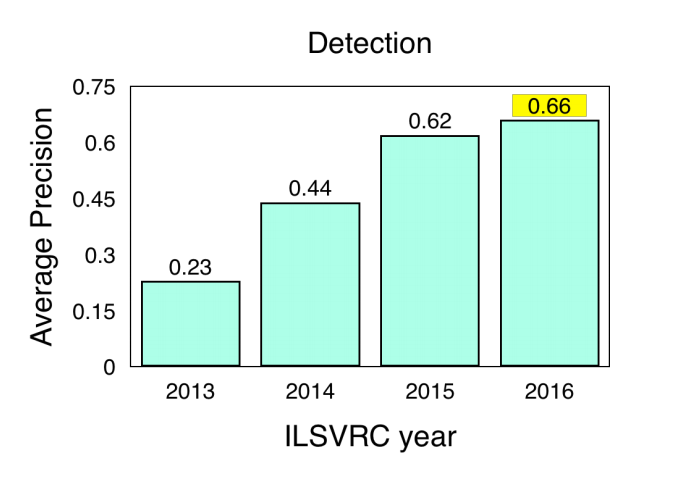
Примечание: Результаты систем обнаружения на изображениях в конкурсе ILSVRC (2013–2016). Источник: ImageNet 2016, онлайновая презентация, слайд 2, pdf
Отслеживание объектов
Относится к процессу отслеживания конкретного интересующего объекта или нескольких объектов, на заданной сцене. Традиционно этот процесс применяется в видеоприложениях и системах взаимодействия с реальным миром, где наблюдения производятся после обнаружения исходного объекта. Например, процесс критически важен для систем беспилотного транспорта.
- «Полностью свёрточные сиамские сети для отслеживания объектов» сочетает базовый алгоритм отслеживания с сиамской сетью, обученной от начала до конца, которая достигает рекордных показателей в своей области и работает покадрово со скоростью, превышающей необходимую для работы приложений реального времени. Эта научная статья пытается преодолеть недостаток функциональной насыщенности, доступный моделям отслеживания из традиционных методов онлайнового обучения.
- «Обучение глубоких регрессионных сетей отслеживанию объектов на 100 FPS» — ещё одна статья, авторы которой пытается преодолеть существующие проблемы с помощью онлайновых методов обучения. Авторы разработали трекер, который применяет сеть с механизмом прогнозирования событий (feed-forward network) для усвоения общих взаимоотношений в связи с движением объекта, его внешним видом и ориентацией. Это позволяет эффективно отслеживать новые объекты без онлайнового обучения. Показывает рекордный результат в стандартном бенчмарке отслеживания, в то же время позволяя «отслеживать общие объекты на 100 FPS».
Видео работы GOTURN (Generic Object Tracking Using Regression Networks)
- Работа «Глубокие признаки движения для визуального отслеживания» сочетает вручную написанные признаки, глубокие признаки RGB/внешнего вида (из CNN), а также глубокие признаки движения (обученные на оптическом потоке изображений), чтобы достичь рекордных показателей. Хотя глубокие признаки движения являются обычным делом в системах распознавания действий и классификации видео, авторы заявляют, что они впервые используются для визуального отслеживания. Статья получила награду как лучшая статья на конференции ICPR 2016, в секции «Компьютерное зрение и зрение роботов».
«Эта статья представляет собой исследование влияния глубоких признаков движения во фреймворке отслеживания через обнаружение. Далее мы показываем, что дополнительную информацию содержат написанные вручную признаки, глубокие признаки RGB и глубокие признаки движения. Насколько нам известно, мы первые предлагаем совместить информацию о внешнем виде с глубокими признаками движения для визуального отслеживания. Всесторонние эксперименты явно полагают, что наш смешанный подход с глубокими признаками движения превосходит стандартные методы, которые полагаются только на информацию о внешнем виде». - Статья «Виртуальные миры как промежуточное звено для анализа отслеживания множественных объектов» посвящена проблеме отсутствия присущей реальному миру изменчивости в существующих бенчмарках и наборах данных для отслеживания видео. Статья предлагает новый метод клонирования реального мира с помощью генерации с нуля насыщенных, виртуальных, синтетических, фотореалистичных сред с полным покрытием метками. Этот подход решает некоторые проблемы стерильности, которые присутствуют в существующих наборах данных. Сгенерированные изображения автоматически размечаются точными метками, что позволяет использовать их для разнообразных приложений, помимо обнаружения и отслеживания объектов.
- «Глобальное оптимальное отслеживание объектов с полностью свёрточными сетями». Здесь обсуждаются разнообразие объектов и помехи как две корневые причины ограничений в системах отслеживания объектов. «Предлагаемый нами метод решает проблему разнообразия внешнего вида объектов при помощи полностью свёрточной сети, а также работает с проблемой помех путём динамического программирования».
Телеграм: t.me/ainewsline
Источник: habrahabr.ru