ИИ учит язык: зачем нужен хакатон по машинному переводу
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-12-22 14:52

18 декабря стартовал отборочный тур для участия в хакатоне DeepHack.Babel от Лаборатории нейронных систем и глубокого обучения МФТИ. Акцент будет сделан на нейросетевой машинный перевод, набирающий популярность в исследовательском сообществе и уже использующийся в коммерческих продуктах. Причем обучить систему машинного перевода нужно будет, вопреки общепринятой практике, на непараллельных данных — то есть, в терминах машинного обучения, без привлечения учителя. Если вы еще размышляете над регистрацией, рассказываем, зачем это нужно.
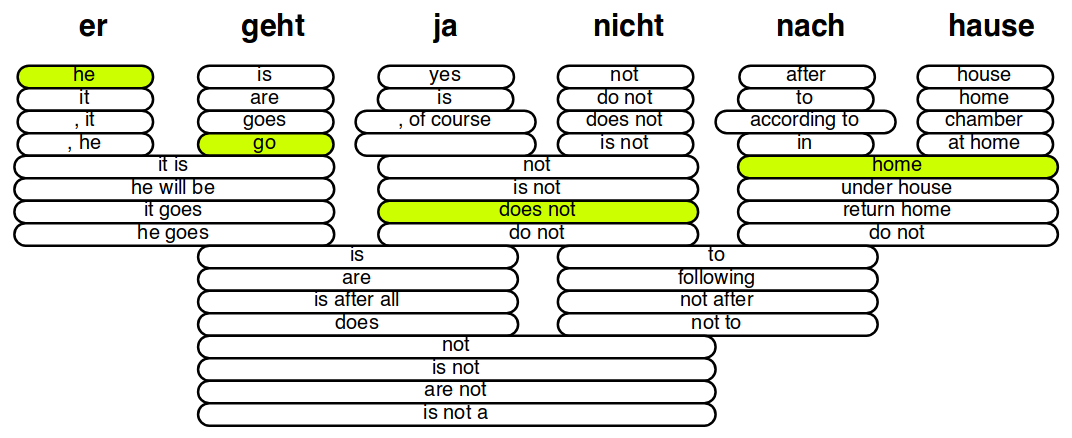
Варианты перевода отдельных слов и фраз предложения «er geht ja nicht nach hause» («он не идет домой») на английский. Качество вариантов определяется взвешенной суммой значений признаков, таких, например, как вероятности p(e|f) и p(f|e), где e и f — исходная и целевая фразы. Кроме подходящих переводов требуется еще выбрать порядок фраз. Иллюстрация взята из презентации Philipp Koehn.
Здесь вступал в дело второй компонент системы машинного перевода — вероятностная модель языка. Ее классический вариант — модель языка на n-граммах — так же, как и таблица перевода, основана на совместной встречаемости слов, но на этот раз речь идет о вероятности встретить слово после определенного префикса (n предыдущих слов). Чем больше такая вероятность для каждого из слов сгенерированного предложения (то есть, чем меньше мы «удивляем» модель языка выбором слов), тем натуральнее оно звучит и тем больше вероятность того, что это и есть правильный перевод. Такая техника, несмотря на кажущуюся ограниченность, позволила достичь очень высокого качества перевода – не в последнюю очередь из-за того, что вероятностная модель языка обучается только на одноязычном (а не на параллельном) корпусе, поэтому ее можно обучить на очень большом объеме данных, и она будет хорошо информирована о том, как можно говорить, а как нельзя.
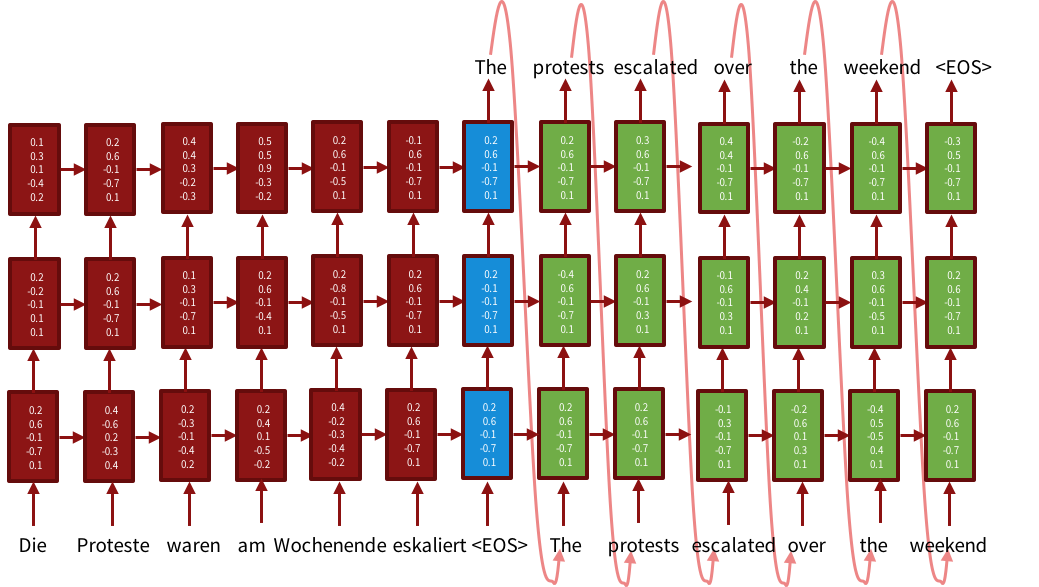
Схема работы трехслойной модели encoder-decoder. Энкодер (красная часть) генерирует представление предложения: на каждом шаге комбинирует новое входное слово с представлением для слов, прочитанных ранее. Синяя часть — представление всего предложения целиком. Декодер (зеленая часть) выдает слово на выходном языке на основе представления исходного предложения и предыдущего сгенерированного слова. Иллюстрация взята из тьюториала по нейросетевому машинному переводу на ACL-2016.
На каждом шаге такая нейросеть комбинирует новое входное слово (точнее, его векторное представление) с информацией о предыдущих словах. Параметры нейросети определяют, сколько нужно «забыть», а сколько «запомнить» на каждом шаге, таким образом, представление всего предложения содержит самую важную информацию из него. Архитектура encoder-decoder уже стала классической, прочитать ее описание можно, например, в [1].
На самом деле, стандартный вариант этой системы работает не совсем так, как предполагается, поэтому для хорошего качества перевода необходимы дополнительные ухищрения. Например, рекуррентная сеть с обычными ячейками подвержена взрывающимся или затухающим градиентам (то есть градиенты сходятся к нулю или очень большим значениям и больше не меняются, что делает невозможным обучение сети) — для этого были предложены нейроны другой структуры — LSTM [2] и GRU [3], на каждом шаге решающие, какую информацию нужно «забыть», а какую передать дальше. При чтении длинных предложений система забывает, с чего они начались — в этом случае помогает использование двунаправленных сетей, читающих предложение одновременно с начала и с конца, как это было сделано в [4]. Кроме этого, оказалось полезно по аналогии со статистическими системами явно проводить соответствия между отдельными словами в исходном предложении и его переводе — для этого был применен механизм внимания, уже использовавшийся в других задачах (применение внимания к машинному переводу описано, например, в [4] и [5], короткое и простое описание внимания — в этом посте). Он состоит в том, что при декодировании (генерации перевода) система получает информацию о том, какое именно слово исходного предложения она должна перевести на данном шаге.
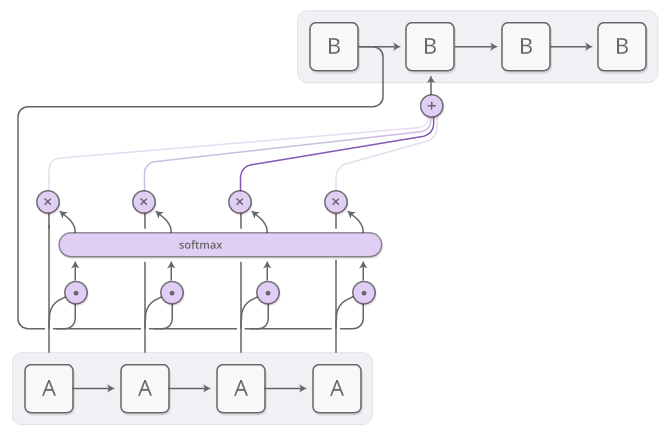 Механизм внимания в архитектуре encoder-decoder. Текущее состояние декодера (В) перемножается с каждым из состояний энкодера (А) — так мы определяем, какое из входных слов наиболее актуально для декодера в данный момент (вместо умножения может использоваться другая операция для определения сходства). Затем результат этого перемножения преобразуется в вероятностное распределение функцией softmax — она возвращает вес каждого входного слова для декодера. Комбинации взвешенных состояний энкодера подаются в декодер. Иллюстрация взята из поста Chris Olah.
Механизм внимания в архитектуре encoder-decoder. Текущее состояние декодера (В) перемножается с каждым из состояний энкодера (А) — так мы определяем, какое из входных слов наиболее актуально для декодера в данный момент (вместо умножения может использоваться другая операция для определения сходства). Затем результат этого перемножения преобразуется в вероятностное распределение функцией softmax — она возвращает вес каждого входного слова для декодера. Комбинации взвешенных состояний энкодера подаются в декодер. Иллюстрация взята из поста Chris Olah.
С использованием всех этих дополнительных техник машинный перевод на нейросетях уверенно побеждает статистические системы: например, на последнем соревновании систем машинного перевода нейросетевые модели стали первыми почти во всех парах языков. Однако в отошедших в прошлое статистических моделях есть черта, которую пока не удалось перенести на нейросети — это возможность использовать большое количество непараллельных данных (то есть тех, для которых нет перевода на другой язык).
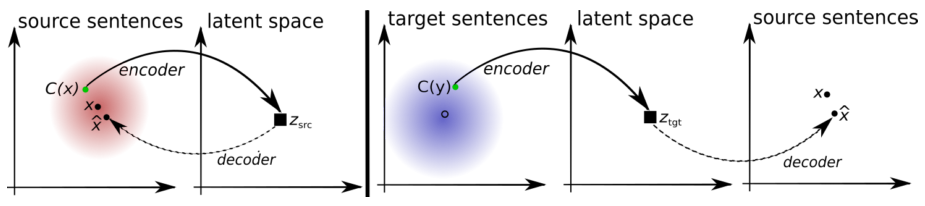 Принцип работы системы машинного перевода без параллельных данных. Автоэнкодер (слева): модель обучается восстанавливать предложение из искаженной версии. x — предложение, C(x) — его искаженная версия, x? — реконструкция. Переводчик (справа): модель обучается переводить предложение на другой язык. На вход ей подается искаженный перевод, порожденный версией модели с предыдущей итерации. Первая версия модели — лексикон (словарь), обученный также без использования параллельных данных. Комбинация двух моделей достигает качества перевода, сравнимого с системами, обученными на параллельных данных. Иллюстрация взята из статьи [9].
Принцип работы системы машинного перевода без параллельных данных. Автоэнкодер (слева): модель обучается восстанавливать предложение из искаженной версии. x — предложение, C(x) — его искаженная версия, x? — реконструкция. Переводчик (справа): модель обучается переводить предложение на другой язык. На вход ей подается искаженный перевод, порожденный версией модели с предыдущей итерации. Первая версия модели — лексикон (словарь), обученный также без использования параллельных данных. Комбинация двух моделей достигает качества перевода, сравнимого с системами, обученными на параллельных данных. Иллюстрация взята из статьи [9].
Что было раньше
До недавнего времени (до того, как нейронные сети стали популярны) системы машинного перевода по сути представляли собой таблицы вариантов перевода: для каждого слова или фразы исходного языка было обозначено некоторое количество возможных переводов на целевой язык. Эти переводы выделялись из большого количества параллельных текстов (текстов на двух языках, являющихся точными переводами друг друга) путем анализа частоты совместной встречаемости слов и выражений. Чтобы перевести строку, надо было скомбинировать переводы для отдельных слов и фраз в предложения и выбрать самый правдоподобный вариант: Варианты перевода отдельных слов и фраз предложения «er geht ja nicht nach hause» («он не идет домой») на английский. Качество вариантов определяется взвешенной суммой значений признаков, таких, например, как вероятности p(e|f) и p(f|e), где e и f — исходная и целевая фразы. Кроме подходящих переводов требуется еще выбрать порядок фраз. Иллюстрация взята из презентации Philipp Koehn.
Здесь вступал в дело второй компонент системы машинного перевода — вероятностная модель языка. Ее классический вариант — модель языка на n-граммах — так же, как и таблица перевода, основана на совместной встречаемости слов, но на этот раз речь идет о вероятности встретить слово после определенного префикса (n предыдущих слов). Чем больше такая вероятность для каждого из слов сгенерированного предложения (то есть, чем меньше мы «удивляем» модель языка выбором слов), тем натуральнее оно звучит и тем больше вероятность того, что это и есть правильный перевод. Такая техника, несмотря на кажущуюся ограниченность, позволила достичь очень высокого качества перевода – не в последнюю очередь из-за того, что вероятностная модель языка обучается только на одноязычном (а не на параллельном) корпусе, поэтому ее можно обучить на очень большом объеме данных, и она будет хорошо информирована о том, как можно говорить, а как нельзя.
Что изменилось с приходом нейронных сетей
Нейронные сети изменили подход к машинному переводу. Теперь перевод производится путем «кодирования» всего предложения в векторное представление (содержащее общий смысл этого предложения в не зависимой от языка форме) и последующего «декодирования» этого представления в слова на целевом языке. Преобразования эти часто производятся с помощью рекуррентных нейронных сетей, которые предназначены как раз для обработки последовательностей объектов (в нашем случае – последовательностей слов). Схема работы трехслойной модели encoder-decoder. Энкодер (красная часть) генерирует представление предложения: на каждом шаге комбинирует новое входное слово с представлением для слов, прочитанных ранее. Синяя часть — представление всего предложения целиком. Декодер (зеленая часть) выдает слово на выходном языке на основе представления исходного предложения и предыдущего сгенерированного слова. Иллюстрация взята из тьюториала по нейросетевому машинному переводу на ACL-2016.
На каждом шаге такая нейросеть комбинирует новое входное слово (точнее, его векторное представление) с информацией о предыдущих словах. Параметры нейросети определяют, сколько нужно «забыть», а сколько «запомнить» на каждом шаге, таким образом, представление всего предложения содержит самую важную информацию из него. Архитектура encoder-decoder уже стала классической, прочитать ее описание можно, например, в [1].
На самом деле, стандартный вариант этой системы работает не совсем так, как предполагается, поэтому для хорошего качества перевода необходимы дополнительные ухищрения. Например, рекуррентная сеть с обычными ячейками подвержена взрывающимся или затухающим градиентам (то есть градиенты сходятся к нулю или очень большим значениям и больше не меняются, что делает невозможным обучение сети) — для этого были предложены нейроны другой структуры — LSTM [2] и GRU [3], на каждом шаге решающие, какую информацию нужно «забыть», а какую передать дальше. При чтении длинных предложений система забывает, с чего они начались — в этом случае помогает использование двунаправленных сетей, читающих предложение одновременно с начала и с конца, как это было сделано в [4]. Кроме этого, оказалось полезно по аналогии со статистическими системами явно проводить соответствия между отдельными словами в исходном предложении и его переводе — для этого был применен механизм внимания, уже использовавшийся в других задачах (применение внимания к машинному переводу описано, например, в [4] и [5], короткое и простое описание внимания — в этом посте). Он состоит в том, что при декодировании (генерации перевода) система получает информацию о том, какое именно слово исходного предложения она должна перевести на данном шаге.
С использованием всех этих дополнительных техник машинный перевод на нейросетях уверенно побеждает статистические системы: например, на последнем соревновании систем машинного перевода нейросетевые модели стали первыми почти во всех парах языков. Однако в отошедших в прошлое статистических моделях есть черта, которую пока не удалось перенести на нейросети — это возможность использовать большое количество непараллельных данных (то есть тех, для которых нет перевода на другой язык).
Зачем использовать непараллельные данные
Можно спросить, зачем использовать непараллельные данные, если нейросетевые системы и без них довольно хороши? Дело в том, что для хорошего качества требуется очень большой объем данных, который не всегда доступен. Известно, что нейронные сети требовательны к количеству обучающих данных. Легко проверить, что на очень маленьком наборе данных любой классический метод (например, Support Vector Machines) обойдет нейронную сеть. В машинном переводе для некоторых самых востребованных пар языков (английский ? основные европейские языки, английский ? китайский, английский ? русский) данных достаточно, и нейросетевые архитектуры для таких пар языков показывают очень высокие результаты. Но там, где параллельных данных меньше нескольких миллионов предложений, нейросети бесполезны. Таких богатых параллельными данными пар языков крайне мало, однако одноязычные тексты доступны для очень многих языков, причем в огромном количестве: новости, блоги, социальные сети, труды правительственных организаций — новый контент генерируется постоянно. Все эти тексты могли бы быть использованы для улучшения качества нейросетевого машинного перевода так же, как они помогали улучшить статистические системы — но, к сожалению, такие техники еще не разработаны. Точнее, есть несколько примеров обучения нейросетевой системы перевода на одноязычных текстах: в [6] описана комбинация архитектуры encoder-decoder с вероятностной моделью языка, в [7] отсутствующий перевод для одноязычного корпуса генерируется самой моделью. Все эти методы улучшают качество перевода, однако использование одноязычных корпусов в нейросетевых системах машинного перевода еще не стало общепринятой практикой: еще не ясно, каким именно образом использовать при обучении непараллельные тексты, не выяснено, какой из подходов лучше подходит, есть ли различия в его использовании для разных пар языков, разных архитектур и пр. И именно эти вопросы мы попытаемся решить на нашем хакатоне DeepHack.Babel.Непараллельные данные и DeepHack.Babel
Мы попытаемся провести контролируемые эксперименты: участникам будет дан очень маленький набор параллельных данных, будет предложено обучить на нем нейросетевой машинный переводчик, а потом улучшить его качество с помощью одноязычных данных. Все участники будут в равных условиях: одинаковые данные, одинаковые ограничения на размер и время обучения моделей – так мы сможем выяснить, какие из реализованных участниками методов работают лучше и приблизиться к пониманию того, как улучшить качество перевода для нераспространенных пар языков. Мы проведем эксперименты на нескольких парах языков разной степени сложности, чтобы проверить, насколько универсальны разные решения. Кроме того, мы подойдем вплотную к еще более амбициозной задаче, которая казалась неосуществимой средствами статистического перевода: перевод без параллельных данных. Технология обучения перевода на параллельных текстах уже известна и отработана, хотя многие связанные с ней вопросы еще не разрешены. Сравнимые корпуса (пары текстов с общей темой и похожим содержанием) тоже активно используются в машинном переводе [8] — это дает возможность использовать такие ресурсы, как Википедия (соответствующие статьи в разных языках там не совпадают дословно, но описывают одни и те же объекты). Но что делать, если нет вообще никакой информации о том, соответствуют тексты друг другу или нет? Например, при анализе двух корпусов новостей за определенный год на разных языках мы можем быть уверены, что обсуждались одни и те же события — значит, для большинства слов одного корпуса в другом корпусе найдется перевод — но установить соответствия между предложениями или хотя бы между текстами мы без дополнительной информации не можем. Возможно ли использовать такие данные? Хоть это и кажется фантастикой, в научной литературе уже есть несколько примеров того, что это возможно — например, в недавней публикации [9] описывается такая система, построенная на denoising автоэнкодерах. Участники хакатона смогут воспроизвести эти методы и попробовать обойти системы, обученные на параллельных текстах. Принцип работы системы машинного перевода без параллельных данных. Автоэнкодер (слева): модель обучается восстанавливать предложение из искаженной версии. x — предложение, C(x) — его искаженная версия, x? — реконструкция. Переводчик (справа): модель обучается переводить предложение на другой язык. На вход ей подается искаженный перевод, порожденный версией модели с предыдущей итерации. Первая версия модели — лексикон (словарь), обученный также без использования параллельных данных. Комбинация двух моделей достигает качества перевода, сравнимого с системами, обученными на параллельных данных. Иллюстрация взята из статьи [9].Как принять участие
Заявки на отборочный тур хакатона будут приниматься до 8 января. Задание отборочного тура — обучить систему машинного перевода с английского на немецкий язык. Здесь никаких ограничений на данные и методы пока нет: участники могут пользоваться любыми корпусами и предобученными моделями и выбрать архитектуру системы на свой вкус. Однако следует помнить, что тестироваться система будет на наборе предложений по IT-тематике — это предполагает использование данных из соответствующих источников. И, хоть ограничений на архитектуру нет, предполагается, что при выполнении отборочного задания участники познакомятся с нейросетевыми моделями перевода, чтобы лучше справиться с основным заданием хакатона. 50 человек, чьи системы покажут лучшее качество перевода (которое будет измерено метрикой BLEU [10]), смогут принять участие в хакатоне. Тем же, кто не пройдет отбор, не стоит расстраиваться — они могут посетить хакатон в качестве слушателей: каждый день будут проходить лекции специалистов по машинному переводу, машинному обучению и обработке текстов, открытые для всех желающих.Библиография
- Sequence to Sequence Learning with Neural Networks. I.Sutskever, O.Vinyals, Q.V.Le.
- LSTM: A Search Space Odyssey. K.Greff, R.K.Srivastava, J.Koutn?k, B.R.Steunebrink, J.Schmidhuber.
- Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. K.Cho, B.v.Merrienboer, C.Gulcehre, D.Bahdanau, F.Bougares, H.Schwenk, Y.Bengio.
- Neural Machine Translation by Jointly Learning to Align and Translate. D.Bahdanau, K.Cho, Y.Bengio.
- Effective Approaches to Attention-based Neural Machine Translation. M.-T.Luong, H.Pham, C.D.Manning.
- On Using Monolingual Corpora in Neural Machine Translation. C.Gulcehre, O.Firat, K.Xu, K.Cho, L.Barrault, H.-C.Lin, F.Bougares, H.Schwenk, Y.Bengio.
- Improving Neural Machine Translation Models with Monolingual Data. R.Sennrich, B.Haddow, A.Birch.
- Inducing Bilingual Lexica From Non-Parallel Data With Earth Mover’s Distance Regularization. M.Zhang, Y.Liu, H.Luan, Y.Liu, M.Sun.
- Unsupervised Machine Translation Using Monolingual Corpora Only. G.Lample, L.Denoyer, M.Ranzato.
- BLEU: a method for automatic evaluation of machine translation. K.Papineni, S.Roukos, T.Ward, W.-J.Zhu.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru