Раскрашиваем чёрно-белую фотографию с помощью нейросети из 100 строк кода
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-11-15 10:51

Перевод статьи Colorizing B&W Photos with Neural Networks.
Не так давно Амир Авни с помощью нейросетей затроллил на Reddit ветку /r/Colorization, где собираются люди, увлекающиеся раскрашиванием вручную в Photoshop исторических чёрно-белых изображений. Все были изумлены качеством работы нейросети. То, на что уходит до месяца работы вручную, можно сделать за несколько секунд.
Давайте воспроизведем и задокументируем процесс обработки изображений Амира. Для начала посмотрите на некоторые достижения и неудачи (в самом низу — последняя версия).

Исходные чёрно-белые фотографии взяты с Unsplash.
Сегодня чёрно-белые фотографии обычно раскрашивают вручную в Photoshop. Посмотрите это видео, чтобы получить представление об огромной трудоёмкости такой работы:
На раскрашивание одного изображения может уйти месяц. Приходится исследовать много исторических материалов, относящихся к тому времени. На одно только лицо накладывается до 20 слоёв розовых, зелёных и синих теней, чтобы получился правильный оттенок. Это статья для начинающих. Если вам не знакома терминология глубокого обучения нейросетей, то можете почитать предыдущие статьи (1, 2) и посмотреть лекцию Андрея Карпатого.
В этой статье вы узнаете, как за три этапа построить собственную нейросеть для раскрашивания изображений.
В первой части мы разберёмся с основной логикой. Построим каркас нейросети из 40 строк, это будет «альфа»-версия раскрашивающего бота. В этом коде мало таинственного, он поможет вам ознакомиться с синтаксисом.
На следующем этапе мы сделаем обобщающую (generalize) нейросеть — «бета»-версию. Она уже сможет раскрашивать изображения, которые ей не знакомы.
В «окончательной» версии мы объединим нашу нейросеть с классификатором. Для этого возьмём Inception Resnet V2, обученный на 1,2 млн изображений. А нейросеть обучим раскрашиванию на изображениях с Unsplash.
Если не терпится, то вот Jupyter Notebook с альфа-версией бота. Также можете посмотреть три версии на FloydHub и GitHub, и ещё код, использованный во всех экспериментах, которые проводились на облачных видеокартах сервиса FloydHub.
 Цветные изображения состоят из трёх слоёв: красного, зелёного и синего. Допустим, нужно разложить по трём каналам картинку с зелёным листиком на белом фоне. Вы можете подумать, что листик будет представлен только в зелёном слое. Но, как видите, он есть во всех трёх слоях, потому что слои определяют не только цвет, но и яркость.
Цветные изображения состоят из трёх слоёв: красного, зелёного и синего. Допустим, нужно разложить по трём каналам картинку с зелёным листиком на белом фоне. Вы можете подумать, что листик будет представлен только в зелёном слое. Но, как видите, он есть во всех трёх слоях, потому что слои определяют не только цвет, но и яркость.  К примеру, чтобы получить белый цвет, нам нужно получить равное распределение всех цветов. Если добавить одинаковое количество красного и синего, то зелёный станет ярче. То есть в цветном изображении с помощью трёх слоёв кодируется цвет и контрастность.
К примеру, чтобы получить белый цвет, нам нужно получить равное распределение всех цветов. Если добавить одинаковое количество красного и синего, то зелёный станет ярче. То есть в цветном изображении с помощью трёх слоёв кодируется цвет и контрастность.
 Как и в чёрно-белом изображении, пиксели каждого слоя цветного изображения содержат значение от 0 до 255. Ноль означает, что у этого пикселя в данном слое нет цвета. Если во всех трёх каналах стоят нули, то в результате на картинке получается чёрный пиксель.
Как и в чёрно-белом изображении, пиксели каждого слоя цветного изображения содержат значение от 0 до 255. Ноль означает, что у этого пикселя в данном слое нет цвета. Если во всех трёх каналах стоят нули, то в результате на картинке получается чёрный пиксель.
Как вы знаете, нейросеть устанавливает взаимосвязь между входным и выходным значениями. В нашем случае нейросеть должна найти связующие черты между чёрно-белыми и цветными изображениями. То есть мы ищем свойства, по которым можно сопоставить значения из чёрно-белой сетки со значениями из трёх цветных.

f() — нейросеть, [B&W] — входные данные, [R],[G],[B] — выходные данные.

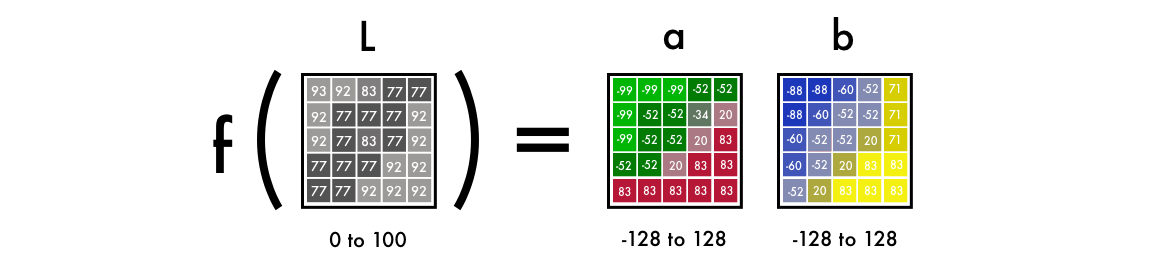
Как видите, изображение в пространстве Lab содержит один слой градаций серого, а три цветных слоя упакованы в два. Поэтому мы можем использовать в окончательном изображении исходный чёрно-белый вариант. Осталось вычислить ещё два канала.
 Научный факт: 94% рецепторов сетчатки нашего глаза отвечают за определение яркости. И только 6% рецепторов распознают цвета. Поэтому для вас чёрно-белое изображение выглядит гораздо отчётливее цветных слоёв. Это ещё одна причина, по которой мы будем использовать эту картинку в окончательном варианте.
Научный факт: 94% рецепторов сетчатки нашего глаза отвечают за определение яркости. И только 6% рецепторов распознают цвета. Поэтому для вас чёрно-белое изображение выглядит гораздо отчётливее цветных слоёв. Это ещё одна причина, по которой мы будем использовать эту картинку в окончательном варианте.
 Для получения двух слоёв из одного слоя, воспользуемся свёрточными фильтрами. Их можно представить как синее и красное стекло в 3D-очках. Фильтры определяют, что мы увидим на картинке. Они могут подчёркивать или скрывать какую-то часть изображения, чтобы наш глаз извлек нужную информацию. Нейросеть тоже может с помощью фильтра создать новое изображение или свести несколько фильтров в одну картинку.
Для получения двух слоёв из одного слоя, воспользуемся свёрточными фильтрами. Их можно представить как синее и красное стекло в 3D-очках. Фильтры определяют, что мы увидим на картинке. Они могут подчёркивать или скрывать какую-то часть изображения, чтобы наш глаз извлек нужную информацию. Нейросеть тоже может с помощью фильтра создать новое изображение или свести несколько фильтров в одну картинку.
В свёрточных нейросетях каждый фильтр автоматически подстраивается, чтобы легче было получить нужные выходные данные. Мы наложим сотни фильтров, а затем сведём их воедино и получим слои a и b.
Прежде чем переходить к подробностям работы кода, давайте его запустим.
Затем откройте папку и инициализируйте FloydHub.
В вашем браузере откроется веб-панель FloydHub. Вам предложат создать новый FloydHub-проект под названием colornet. Когда вы его создадите, возвращайтесь в терминал и выполните ту же команду инициализации.
Запускаем задачу:
Несколько пояснений:
Если вы можете подключить видеокарты к выполнению задачи, то добавьте в команду флаг
Перейдите в Jupyter Notebook. На сайте FloydHub во вкладке Jobs кликните на ссылку Jupyter Notebook и найдите файл:
Откройте файл и на всех ячейках нажмите Shift+Enter.
Постепенно увеличивайте значение периодов (epoch value), чтобы понять, как учится нейросеть.
Начните с epochs=1, затем увеличивайте до 10, 100, 500, 1000 и 3000. Это значение показывает, сколько раз нейросеть обучается на изображении. Как только вы обучите нейросеть, то найдёте файл img_result.png в главной папке.
FloydHub-команда для запуска этой сети:
 Мы в одном диапазоне сопоставляем (map) вычисленные значения с реальными, тем самым сравнивая их друг с другом. Границы диапазона от —1 до 1. Для сопоставления вычисленных значений мы используем функцию активации tanh (гиперболическая тангенциальная). Если применить её к какому-нибудь значению, то функция вернёт значение в диапазоне от —1 до 1.
Мы в одном диапазоне сопоставляем (map) вычисленные значения с реальными, тем самым сравнивая их друг с другом. Границы диапазона от —1 до 1. Для сопоставления вычисленных значений мы используем функцию активации tanh (гиперболическая тангенциальная). Если применить её к какому-нибудь значению, то функция вернёт значение в диапазоне от —1 до 1.
Реальные значения цветов меняются от —128 до 128. В пространстве Lab это диапазон по умолчанию. Если каждое значение разделить на 128, то все они окажутся в границах от —1 до 1. Такая «нормализация» позволяет сравнивать погрешность нашего вычисления.
После вычисления результирующей погрешности нейросеть обновляет фильтры, чтобы скорректировать результат следующей итерации. Вся процедура повторяется циклически, пока погрешность не станет минимальной.
Давайте разберёмся с синтаксисом этого кода:
1.0/255 означает, что мы используем 24-битное цветовое пространство RGB. То есть для каждого цветового канала мы используем значения в диапазоне от 0 до 255. Это даёт нам 16,7 миллиона цветов.
Но поскольку человеческий глаз может распознавать лишь от 2 до 10 млн цветов, то использовать более широкое цветовое пространство не имеет смысла.
Цветовое пространство Lab использует другой диапазон. Цветовой спектр ab варьируется от —128 до 128. Если поделить все значения выходного слоя на 128, то они уложатся в дипазон от —1 до 1, и тогда можно будет сопоставить эти значения с теми, что вычислила наша нейросеть.
После того, как с помощью функции
После обучения нейросети выполняем последнее вычисление, которое преобразуем в картинку.
Здесь мы подаём на вход чёрно-белое изображение и прогоняем его через обученную нейросеть. Берём все выходные значения от —1 до 1 и умножаем их на 128. Так мы получаем корректные цвета в системе Lab.
Создаём чёрный RGB-холст, заполнив все три слоя нулями. Затем копируем чёрно-белый слой из тестового изображения и добавляем два цветных слоя. Получившийся массив значений пикселей преобразуем в изображение.
Вместо использования Imagenet мы создали на FloydHub публичный датасет с более качественными изображениями. Они взяты с Unsplash?—?сайта, где выкладываются снимки профессиональных фотографов. В датасете 9500 обучающих изображений и 500 проверочных.

 Пусть эти девять пикселей находятся с краю ноздри женщины. Как вы понимаете, правильно выбрать цвет здесь почти невозможно, так что придётся разбивать решение задачи на этапы.
Пусть эти девять пикселей находятся с краю ноздри женщины. Как вы понимаете, правильно выбрать цвет здесь почти невозможно, так что придётся разбивать решение задачи на этапы.
Во-первых, ищем простые характерные структуры: диагональные линии, только чёрные пиксели и так далее. В каждом квадратике из 9 пикселей мы ищем одну и ту же структуру и удаляем всё, что ей не соответствует. В результате мы создали 64 новых изображения из 64 наших минифильтров.

Количество обработанных фильтрами изображений на каждом этапе.
Если снова просмотрим изображения, то обнаружим те же маленькие повторяющиеся структуры, которые мы уже определили. Чтобы лучше проанализировать изображение, уменьшим его размер вдвое.

Уменьшаем размер в три этапа.
У нас ещё остался фильтр 3х3, которым нужно просканировать каждое изображение. Но если мы применим наши более простые фильтры к новым квадратам из девяти пикселей, то можно обнаружить более сложные структуры. Например, полукруг, маленькая точка или линия. Мы снова раз за разом находим на картинке одну и ту же повторяющуюся структуру. На этот раз генерируем 128 новых обработанных фильтрами изображений.
Через пару этапов обработанные фильтрами изображения станут выглядеть так:
 Повторимся: вы начинаете с поиска простых свойств, например, краёв. По мере обработки слои объединяются в структуры, затем в более сложные черты, и в конце концов получается лицо. Подробнее объясняется в этом видео:
Повторимся: вы начинаете с поиска простых свойств, например, краёв. По мере обработки слои объединяются в структуры, затем в более сложные черты, и в конце концов получается лицо. Подробнее объясняется в этом видео:
Описанный процесс очень похож на алгоритмы компьютерного зрения. Здесь мы используем так называемую свёрточную нейросеть, которая комбинирует несколько обработанных изображений, чтобы понять содержимое всей картинки.
Из-за однообразия обучающих данных нейросеть старается понять различия между теми или иными объектами. Она пока не может вычислить более точные цветовые оттенки, этим мы займёмся при создании полной версии нейросети.
Вот код бета-версии:
FloydHub-команда для запуска бета-версии нейросети:
 Также наша нейросеть отличается от прочих слоями повышения дискретизации (upsampling) и сохранением соотношения сторон изображения. Классифицирующие сети заботятся только об итоговой классификации, поэтому постепенно уменьшают размер и качество картинки по мере её прогона через нейросеть.
Также наша нейросеть отличается от прочих слоями повышения дискретизации (upsampling) и сохранением соотношения сторон изображения. Классифицирующие сети заботятся только об итоговой классификации, поэтому постепенно уменьшают размер и качество картинки по мере её прогона через нейросеть.
Раскрашивающие нейросети не меняют соотношение сторон изображения. Для этого с помощью параметра
Чтобы удвоить размер картинки, раскрашивающая нейросеть использует слой повышения дискретизации.
Этот цикл
С помощью ImageDataGenerator можно включить генератор изображений. Тогда каждое изображение будет отличаться от предыдущих, что ускорит обучение нейросети. Настройка
Применим эти настройки к картинкам в папке Xtrain и сгенерируем новые изображения. Затем извлечём чёрно-белый слой для
Чем мощнее ваша видеокарта, тем больше картинок вы сможете в ней обрабатывать одновременно. Например, описанная система умеет обрабатывать 50-100 изображений. Значение параметра steps_per_epoch получено делением количества обучающих изображений на размер серии (batch size).
Например: если у нас 100 картинок, а размер серии равен 50, то получим 2 этапа в период. Количество периодов определяет, сколько раз вы будете обучать нейросеть на всех картинках. Если у вас 10 тыс. картинок и 21 период, то это займёт около 11 часов на видеокарте Tesla K80.
Входные данные одновременно проходят через кодировщик и через самый мощный современный классификатор —? Inception ResNet v2. Это нейросеть, обученная на 1,2 млн изображений. Мы извлекаем слой классификации и объединяем его с выходными данными кодировщика.
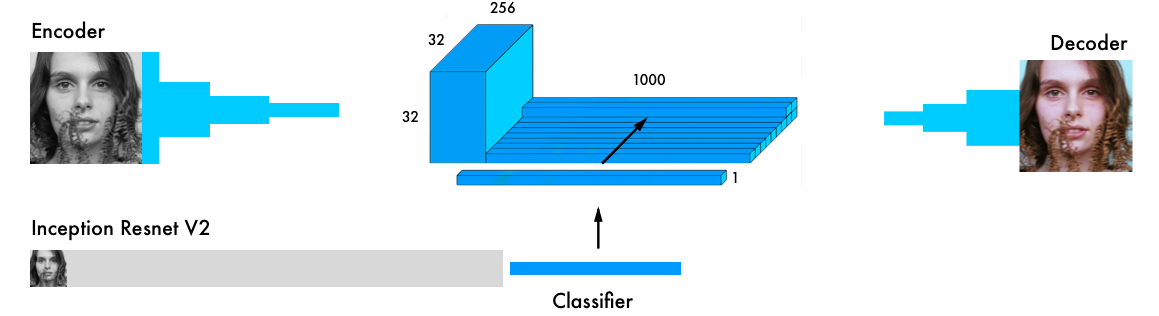
Более подробное визуальное пояснение: https://github.com/baldassarreFe/deep-koalarization.
Если перенести обучение из классификатора в раскрашивающую сеть, то она сможет понять, что изображено на картинке, а значит и сопоставлять представление объекта со схемой раскрашивания.
Вот некоторые проверочные изображения, для обучения сети использовалось только 20 картинок.
 Большинство фотографий раскрашено криво. Но благодаря большому проверочному набору (2500 изображений) есть и несколько приличных. Обучение сети на более крупной выборке даёт более стабильные результаты, но всё равно большинство картинок получились коричневыми. Вот полный список проведённых экспериментов и проверочных изображений.
Большинство фотографий раскрашено криво. Но благодаря большому проверочному набору (2500 изображений) есть и несколько приличных. Обучение сети на более крупной выборке даёт более стабильные результаты, но всё равно большинство картинок получились коричневыми. Вот полный список проведённых экспериментов и проверочных изображений.
Самые распространённые архитектуры из различных исследовательских работ:
Цветовые пространства: Lab, YUV, HSV и LUV (подробнее здесь и здесь)
Потери: средняя квадратическая ошибка, классификация, взвешенная классификация (ссылка).
Мы выбрали архитектуру со «слоем слияния» (пятая в списке), потому что она давала лучшие результаты. Также в ней проще разобраться и легче её воспроизвести в Keras. Хотя это не самая сильная архитектура, но для начала сгодится.
Структура нашей нейросети позаимствована из работы Федерико Бальдасарре и его коллег, и адаптирована для работы с Keras. Примечание: в этом коде вместо последовательной модели Keras используется функциональный API. [Документация]
FloydHub-команда для запуска полной версии нейросети:
Для начала скачаем нейросеть Inception ResNet v2 и загрузим значения весов. Раз мы параллельно будем использовать две модели, то нужно определить, какие именно. Это делается в Tensorflow, бэкенде Keras.
Создадим серию (batch) из подправленных изображений. Переведём их в ч/б и прогоним через модель Inception ResNet.
Сначала нужно изменить размер картинок, чтобы скормить их модели. Затем с помощью препроцессора приведём пиксели и значения цветом к нужному формату. И наконец прогоним изображения через сеть Inception и извлечём итоговой слой модели.
Вернёмся к генератору. Для каждой серии сгенерируем по 20 изображений описанного ниже формата. На Tesla K80 GPU ушло около часа. При использовании такой модели эта видеокарта может генерировать до 50 изображений за раз без каких-либо проблем с памятью.
Это соответствует формату нашей модели colornet.
В слое слияния мы сначала слой с 1000 категорий (1000 category layer) умножаем на 1024 (32 * 32). Так мы получаем из модели Inception 1024 ряда итогового слоя. Сетка 32 х 32 переводится из двухмерного в трёхмерное представление, с 1000 столбцов категорий (category pillars). Затем столбцы связываются с выходными данными модели кодировщика. Применяем свёрточную сеть с 254 фильтрами и ядром 1х1 к окончательным результатам слоя слияния.
Можете раскрасить свои чёрно-белые изображения с помощью всех трёх описанных версий нейросети на FloydHub.
Не так давно Амир Авни с помощью нейросетей затроллил на Reddit ветку /r/Colorization, где собираются люди, увлекающиеся раскрашиванием вручную в Photoshop исторических чёрно-белых изображений. Все были изумлены качеством работы нейросети. То, на что уходит до месяца работы вручную, можно сделать за несколько секунд.
Давайте воспроизведем и задокументируем процесс обработки изображений Амира. Для начала посмотрите на некоторые достижения и неудачи (в самом низу — последняя версия).
Исходные чёрно-белые фотографии взяты с Unsplash.
Сегодня чёрно-белые фотографии обычно раскрашивают вручную в Photoshop. Посмотрите это видео, чтобы получить представление об огромной трудоёмкости такой работы:
В этой статье вы узнаете, как за три этапа построить собственную нейросеть для раскрашивания изображений.
В первой части мы разберёмся с основной логикой. Построим каркас нейросети из 40 строк, это будет «альфа»-версия раскрашивающего бота. В этом коде мало таинственного, он поможет вам ознакомиться с синтаксисом.
На следующем этапе мы сделаем обобщающую (generalize) нейросеть — «бета»-версию. Она уже сможет раскрашивать изображения, которые ей не знакомы.
В «окончательной» версии мы объединим нашу нейросеть с классификатором. Для этого возьмём Inception Resnet V2, обученный на 1,2 млн изображений. А нейросеть обучим раскрашиванию на изображениях с Unsplash.
Если не терпится, то вот Jupyter Notebook с альфа-версией бота. Также можете посмотреть три версии на FloydHub и GitHub, и ещё код, использованный во всех экспериментах, которые проводились на облачных видеокартах сервиса FloydHub.
Основная логика
В этом разделе мы рассмотрим рендеринг изображения, поговорим о теории цифрового цвета и основной логике нейросети. Чёрно-белые изображения можно представить в виде сетки из пикселей. У каждого пикселя есть значение яркости, лежащее в диапазоне от 0 до 255, от чёрного до белого. К примеру, чтобы получить белый цвет, нам нужно получить равное распределение всех цветов. Если добавить одинаковое количество красного и синего, то зелёный станет ярче. То есть в цветном изображении с помощью трёх слоёв кодируется цвет и контрастность. Как и в чёрно-белом изображении, пиксели каждого слоя цветного изображения содержат значение от 0 до 255. Ноль означает, что у этого пикселя в данном слое нет цвета. Если во всех трёх каналах стоят нули, то в результате на картинке получается чёрный пиксель.Как вы знаете, нейросеть устанавливает взаимосвязь между входным и выходным значениями. В нашем случае нейросеть должна найти связующие черты между чёрно-белыми и цветными изображениями. То есть мы ищем свойства, по которым можно сопоставить значения из чёрно-белой сетки со значениями из трёх цветных.
f() — нейросеть, [B&W] — входные данные, [R],[G],[B] — выходные данные.
Альфа-версия
Сначала сделаем простую версию нейросети, которая будет раскрашивать женское лицо. По мере добавления новых возможностей вы будете знакомиться с основным синтаксисом нашей модели. За 40 строк кода мы перейдём от левой картинки — чёрно-белой — к средней, которая сделана нашей нейросетью. Правая картинка — это оригинальная фотография, из которой мы сделали чёрно-белую. Нейросеть обучалась и тестировалась на одном изображении, об этом мы поговорим в разделе, посвящённом бета-версии. Цветовое пространство
Сначала воспользуемся алгоритмом изменения цветовых каналов с RGB на Lab. L означает светлота (lightness), a и b — декартовы координаты, определяющие положение цвета в диапазоне, соответственно, от зелёного до красного и от синего до жёлтого.Как видите, изображение в пространстве Lab содержит один слой градаций серого, а три цветных слоя упакованы в два. Поэтому мы можем использовать в окончательном изображении исходный чёрно-белый вариант. Осталось вычислить ещё два канала.
Научный факт: 94% рецепторов сетчатки нашего глаза отвечают за определение яркости. И только 6% рецепторов распознают цвета. Поэтому для вас чёрно-белое изображение выглядит гораздо отчётливее цветных слоёв. Это ещё одна причина, по которой мы будем использовать эту картинку в окончательном варианте.Из градаций серого в цвет
В качестве входных данных возьмём слой с градациями серого, и на его основе сгенерируем цветные слои a и b в цветовом пространстве Lab. Его же мы возьмём и в качестве L-слоя окончательной картинки. Для получения двух слоёв из одного слоя, воспользуемся свёрточными фильтрами. Их можно представить как синее и красное стекло в 3D-очках. Фильтры определяют, что мы увидим на картинке. Они могут подчёркивать или скрывать какую-то часть изображения, чтобы наш глаз извлек нужную информацию. Нейросеть тоже может с помощью фильтра создать новое изображение или свести несколько фильтров в одну картинку.В свёрточных нейросетях каждый фильтр автоматически подстраивается, чтобы легче было получить нужные выходные данные. Мы наложим сотни фильтров, а затем сведём их воедино и получим слои a и b.
Прежде чем переходить к подробностям работы кода, давайте его запустим.
Развёртывание кода на FloydHub
Если вы раньше не работали с FloydHub, то можете запустить пока инсталляцию и посмотреть пятиминутное видеоруководство или пошаговые инструкции. FloydHub — лучший и простейший способ глубокого обучения моделей на облачных видеокартах.Альфа-версия
После установки FloydHub введите команду:git clone https://github.com/emilwallner/Coloring-greyscale-images-in-KerasЗатем откройте папку и инициализируйте FloydHub.
cd Coloring-greyscale-images-in-Keras/floydhub
floyd init colornetВ вашем браузере откроется веб-панель FloydHub. Вам предложат создать новый FloydHub-проект под названием colornet. Когда вы его создадите, возвращайтесь в терминал и выполните ту же команду инициализации.
floyd init colornetЗапускаем задачу:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboardНесколько пояснений:
- С помощью этой команды мы смонтировали на FloydHub публичный датасет:
--dataemilwallner/datasets/colornet/2:data
На FloydHub вы можете просматривать и использовать этот и многие другие публичные датасеты. - Включили Tensorboard с помощью команды
--tensorboard - Запустили задачу в режиме Jupyter Notebook с помощью команды
--mode jupyter
Если вы можете подключить видеокарты к выполнению задачи, то добавьте в команду флаг
–gpu. Получится примерно в 50 раз быстрее.Перейдите в Jupyter Notebook. На сайте FloydHub во вкладке Jobs кликните на ссылку Jupyter Notebook и найдите файл:
floydhub/Alpha version/working_floyd_pink_light_full.ipynbОткройте файл и на всех ячейках нажмите Shift+Enter.
Постепенно увеличивайте значение периодов (epoch value), чтобы понять, как учится нейросеть.
model.fit(x=X, y=Y, batch_size=1, epochs=1)Начните с epochs=1, затем увеличивайте до 10, 100, 500, 1000 и 3000. Это значение показывает, сколько раз нейросеть обучается на изображении. Как только вы обучите нейросеть, то найдёте файл img_result.png в главной папке.
# Get images
image = img_to_array(load_img('woman.png'))
image = np.array(image, dtype=float)
# Import map images into the lab colorspace
X = rgb2lab(1.0/255*image)[:,:,0]
Y = rgb2lab(1.0/255*image)[:,:,1:]
Y = Y / 128
X = X.reshape(1, 400, 400, 1)
Y = Y.reshape(1, 400, 400, 2)
model = Sequential()
model.add(InputLayer(input_shape=(None, None, 1)))
# Building the neural network
model = Sequential()
model.add(InputLayer(input_shape=(None, None, 1)))
model.add(Conv2D(8, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(8, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same', strides=2))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(2, (3, 3), activation='tanh', padding='same'))
# Finish model
model.compile(optimizer='rmsprop',loss='mse')
#Train the neural network
model.fit(x=X, y=Y, batch_size=1, epochs=3000)
print(model.evaluate(X, Y, batch_size=1))
# Output colorizations
output = model.predict(X)
output = output * 128
canvas = np.zeros((400, 400, 3))
canvas[:,:,0] = X[0][:,:,0]
canvas[:,:,1:] = output[0]
imsave("img_result.png", lab2rgb(canvas))
imsave("img_gray_scale.png", rgb2gray(lab2rgb(canvas)))FloydHub-команда для запуска этой сети:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboardТехнические пояснения
Напомним, что на входе у нас сетка, представляющая чёрно-белое изображение. А на выходе — две сетки со значениями цветов. Между входными и выходными значениями мы создали связующие фильтры. У нас получилась свёрточная нейросеть. Для обучения сети используются цветные изображения. Мы преобразовали из цветового пространства RGB в Lab. Чёрно-белый слой подаётся на вход, а на выходе получаются два раскрашенных слоя. Реальные значения цветов меняются от —128 до 128. В пространстве Lab это диапазон по умолчанию. Если каждое значение разделить на 128, то все они окажутся в границах от —1 до 1. Такая «нормализация» позволяет сравнивать погрешность нашего вычисления.
После вычисления результирующей погрешности нейросеть обновляет фильтры, чтобы скорректировать результат следующей итерации. Вся процедура повторяется циклически, пока погрешность не станет минимальной.
Давайте разберёмся с синтаксисом этого кода:
X = rgb2lab(1.0/255*image)[:,:,0]
Y = rgb2lab(1.0/255*image)[:,:,1:]1.0/255 означает, что мы используем 24-битное цветовое пространство RGB. То есть для каждого цветового канала мы используем значения в диапазоне от 0 до 255. Это даёт нам 16,7 миллиона цветов.
Но поскольку человеческий глаз может распознавать лишь от 2 до 10 млн цветов, то использовать более широкое цветовое пространство не имеет смысла.
Y = Y / 128Цветовое пространство Lab использует другой диапазон. Цветовой спектр ab варьируется от —128 до 128. Если поделить все значения выходного слоя на 128, то они уложатся в дипазон от —1 до 1, и тогда можно будет сопоставить эти значения с теми, что вычислила наша нейросеть.
После того, как с помощью функции
rgb2lab() преобразовали цветовое пространство, мы с помощью [:,:, 0] выбираем чёрно-белый слой. Это входные данные для нейросети. [:,:, 1: ] выбирает два цветных слоя, красно-зелёный и сине-жёлтый.После обучения нейросети выполняем последнее вычисление, которое преобразуем в картинку.
output = model.predict(X)
output = output * 128Здесь мы подаём на вход чёрно-белое изображение и прогоняем его через обученную нейросеть. Берём все выходные значения от —1 до 1 и умножаем их на 128. Так мы получаем корректные цвета в системе Lab.
canvas = np.zeros((400, 400, 3))
canvas[:,:,0] = X[0][:,:,0]
canvas[:,:,1:] = output[0]Создаём чёрный RGB-холст, заполнив все три слоя нулями. Затем копируем чёрно-белый слой из тестового изображения и добавляем два цветных слоя. Получившийся массив значений пикселей преобразуем в изображение.
Чему мы научились при работе над альфа-версией
- Чтение исследовательских работ — тяжёлый труд. Но стоило обобщить ключевые положения статей, и штудировать их стало проще. Это также помогло включить в эту статью некоторые подробности.
- Нужно начинать с малого. Большинство найденных нами в сети реализаций состояли из 2—10 тыс строк кода. Это сильно мешает получить представление об основной логике. Но если под рукой есть упрощённая, базовая версия, то легче читать и реализацию, и исследовательские работы.
- Не надо лениться разбираться в чужих проектах. Нам пришлось просмотреть несколько десятков проектов по раскрашиванию изображений на Github, чтобы определиться с содержимым своего кода.
- Не всё работает так, как задумано. Возможно, сначала ваша сеть сможет создавать только красный и жёлтый цвета. В первый раз мы для окончательной активации использовали функцию активации Relu. Но она генерирует только положительные значения, и поэтому синий и зелёный спектры ей недоступны. Этот недостаток удалось решить, добавив функцию активации tanh для преобразования значений по оси Y.
- Понимание > скорость. Многие виденные нами реализации исполнялись быстро, но с ними трудно было работать. Поэтому мы решили оптимизировать наш код ради скорости добавления новых возможностей, а не исполнения.
Бета-версия
Предложите альфа-версии раскрасить изображение, на котором она не обучалась, и сразу поймёте, в чём главный недостаток этой версии. Она не справится. Дело в том, что нейросеть запомнила информацию. Она не научилась раскрашивать незнакомое изображение. И мы это исправим в бета-версии — научим нейросеть обобщать. Ниже показано, как бета-версия раскрасила проверочные картинки.Вместо использования Imagenet мы создали на FloydHub публичный датасет с более качественными изображениями. Они взяты с Unsplash?—?сайта, где выкладываются снимки профессиональных фотографов. В датасете 9500 обучающих изображений и 500 проверочных.
Выделитель признаков
Наша нейросеть ищет характеристики, связывающие чёрно-белые изображения с их цветными версиями. Представьте, что вам нужно раскрасить чёрно-белые картинки, но вы можете видеть на экране только девять пикселей одновременно. Вы можете просматривать каждую картинку слева направо и сверху вниз, стараясь вычислить цвет каждого пикселя. Пусть эти девять пикселей находятся с краю ноздри женщины. Как вы понимаете, правильно выбрать цвет здесь почти невозможно, так что придётся разбивать решение задачи на этапы.Во-первых, ищем простые характерные структуры: диагональные линии, только чёрные пиксели и так далее. В каждом квадратике из 9 пикселей мы ищем одну и ту же структуру и удаляем всё, что ей не соответствует. В результате мы создали 64 новых изображения из 64 наших минифильтров.
Количество обработанных фильтрами изображений на каждом этапе.
Если снова просмотрим изображения, то обнаружим те же маленькие повторяющиеся структуры, которые мы уже определили. Чтобы лучше проанализировать изображение, уменьшим его размер вдвое.
Уменьшаем размер в три этапа.
У нас ещё остался фильтр 3х3, которым нужно просканировать каждое изображение. Но если мы применим наши более простые фильтры к новым квадратам из девяти пикселей, то можно обнаружить более сложные структуры. Например, полукруг, маленькая точка или линия. Мы снова раз за разом находим на картинке одну и ту же повторяющуюся структуру. На этот раз генерируем 128 новых обработанных фильтрами изображений.
Через пару этапов обработанные фильтрами изображения станут выглядеть так:
Повторимся: вы начинаете с поиска простых свойств, например, краёв. По мере обработки слои объединяются в структуры, затем в более сложные черты, и в конце концов получается лицо. Подробнее объясняется в этом видео:От извлечения свойств к цвету
Нейросеть действует по принципу проб и ошибок. Сначала она случайным образом назначает цвет каждому пикселю. Затем по каждому пикселю вычисляет ошибки и корректирует фильтры, чтобы в следующей попытке улучшить результаты. Нейросеть подстраивает свои фильтры, отталкиваясь от результатов с самыми большими значениями ошибок. В нашем случае нейросеть решает, нужно ли раскрашивать или нет, и как расположить на картинке разные объекты. Сначала она красит все объекты в коричневый. Этот цвет больше всего похож на все остальные цвета, поэтому с ним при его использовании получаются самые маленькие ошибки.Из-за однообразия обучающих данных нейросеть старается понять различия между теми или иными объектами. Она пока не может вычислить более точные цветовые оттенки, этим мы займёмся при создании полной версии нейросети.
Вот код бета-версии:
# Get images
X = []
for filename in os.listdir('../Train/'):
X.append(img_to_array(load_img('../Train/'+filename)))
X = np.array(X, dtype=float)
# Set up training and test data
split = int(0.95*len(X))
Xtrain = X[:split]
Xtrain = 1.0/255*Xtrain
#Design the neural network
model = Sequential()
model.add(InputLayer(input_shape=(256, 256, 1)))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(512, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(256, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(2, (3, 3), activation='tanh', padding='same'))
model.add(UpSampling2D((2, 2)))
# Finish model
model.compile(optimizer='rmsprop', loss='mse')
# Image transformer
datagen = ImageDataGenerator(
shear_range=0.2,
zoom_range=0.2,
rotation_range=20,
horizontal_flip=True)
# Generate training data
batch_size = 50
def image_a_b_gen(batch_size):
for batch in datagen.flow(Xtrain, batch_size=batch_size):
lab_batch = rgb2lab(batch)
X_batch = lab_batch[:,:,:,0]
Y_batch = lab_batch[:,:,:,1:] / 128
yield (X_batch.reshape(X_batch.shape+(1,)), Y_batch)
# Train model
TensorBoard(log_dir='/output')
model.fit_generator(image_a_b_gen(batch_size), steps_per_epoch=10000, epochs=1)
# Test images
Xtest = rgb2lab(1.0/255*X[split:])[:,:,:,0]
Xtest = Xtest.reshape(Xtest.shape+(1,))
Ytest = rgb2lab(1.0/255*X[split:])[:,:,:,1:]
Ytest = Ytest / 128
print model.evaluate(Xtest, Ytest, batch_size=batch_size)
# Load black and white images
color_me = []
for filename in os.listdir('../Test/'):
color_me.append(img_to_array(load_img('../Test/'+filename)))
color_me = np.array(color_me, dtype=float)
color_me = rgb2lab(1.0/255*color_me)[:,:,:,0]
color_me = color_me.reshape(color_me.shape+(1,))
# Test model
output = model.predict(color_me)
output = output * 128
# Output colorizations
for i in range(len(output)):
cur = np.zeros((256, 256, 3))
cur[:,:,0] = color_me[i][:,:,0]
cur[:,:,1:] = output[i]
imsave("result/img_"+str(i)+".png", lab2rgb(cur))FloydHub-команда для запуска бета-версии нейросети:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboardТехнические пояснения
От других нейросетей, работающих с изображениями, наша отличается тем, что для неё важно расположение пикселей. У раскрашивающих нейросетей размер изображения или соотношение сторон остаётся неизменным. А у сетей других типов изображение искажается по мере приближения к окончательной версии. Слой пулинга с функцией максимума, применяемый в классифицирующих сетях, увеличивает плотность информации, но при этом искажает картинку. Он оценивает только информацию, а не макет изображения. А в раскрашивающих сетях для уменьшения ширины и высоты вдвое мы используем шаг 2 (stride of 2). Плотность информации тоже увеличивается, но картинка не искажается. Также наша нейросеть отличается от прочих слоями повышения дискретизации (upsampling) и сохранением соотношения сторон изображения. Классифицирующие сети заботятся только об итоговой классификации, поэтому постепенно уменьшают размер и качество картинки по мере её прогона через нейросеть.Раскрашивающие нейросети не меняют соотношение сторон изображения. Для этого с помощью параметра
*padding='same'* добавляются белые поля, как на иллюстрации выше. В противном случае каждый свёрточный слой обрезал бы изображения.Чтобы удвоить размер картинки, раскрашивающая нейросеть использует слой повышения дискретизации.
for filename in os.listdir('/Color_300/Train/'):
X.append(img_to_array(load_img('/Color_300/Test'+filename)))Этот цикл
for-loop сначала подсчитывает имена всех файлов в директории, проходит по директории и преобразует все картинки в массивы пикселей, и наконец объединяет их в огромный вектор.datagen = ImageDataGenerator(
shear_range=0.2,
zoom_range=0.2,
rotation_range=20,
horizontal_flip=True)С помощью ImageDataGenerator можно включить генератор изображений. Тогда каждое изображение будет отличаться от предыдущих, что ускорит обучение нейросети. Настройка
shear_range задаёт наклон изображения влево или вправо, также его можно увеличить, повернуть или отразить по горизонтали.batch_size = 50
def image_a_b_gen(batch_size):
for batch in datagen.flow(Xtrain, batch_size=batch_size):
lab_batch = rgb2lab(batch)
X_batch = lab_batch[:,:,:,0]
Y_batch = lab_batch[:,:,:,1:] / 128
yield (X_batch.reshape(X_batch.shape+(1,)), Y_batch)Применим эти настройки к картинкам в папке Xtrain и сгенерируем новые изображения. Затем извлечём чёрно-белый слой для
X_batch и два цвета для двух цветных слоёв.model.fit_generator(image_a_b_gen(batch_size), steps_per_epoch=1, epochs=1000)Чем мощнее ваша видеокарта, тем больше картинок вы сможете в ней обрабатывать одновременно. Например, описанная система умеет обрабатывать 50-100 изображений. Значение параметра steps_per_epoch получено делением количества обучающих изображений на размер серии (batch size).
Например: если у нас 100 картинок, а размер серии равен 50, то получим 2 этапа в период. Количество периодов определяет, сколько раз вы будете обучать нейросеть на всех картинках. Если у вас 10 тыс. картинок и 21 период, то это займёт около 11 часов на видеокарте Tesla K80.
Чему научились
- Сначала побольше экспериментов с небольшими сериями, а потом можно переходить к большим прогонам. У нас были ошибки даже после 20–30 экспериментов. Если что-то выполняется, ещё не значит, что оно работает. Баги в нейросетях как правило менее заметны, чем традиционные ошибки программирования. К примеру, одним из наших самых причудливых багов был Adam hiccup.
- Чем разнообразнее датасет, тем больше коричневого будет в изображениях. Если в вашем датасете очень похожие изображения, то нейросеть будет работать вполне прилично без применения более сложной архитектуры. Но такая нейросеть будет хуже обобщать.
- Формы, формы и ещё раз формы. Размеры картинок должны быть точными и пропорциональными друг другу в течение всей работы нейросети. Сначала мы использовали изображение в 300 пикселей, потом несколько раз уменьшили его вдвое: до 150, 75 и 35,5 пикселей. В последнем варианте потерялось полпикселя, из-за чего пришлось подставлять кучу костылей, пока не дошло, что лучше использовать двойку в степени: 2, 4, 8, 16, 32, 64, 256 и так далее.
- Создание датасетов: a) Отключите файл .DS_Store, иначе он сведёт вас с ума. б) Проявите выдумку. Для скачивания файлов мы воспользовались консольным скриптом в Chrome и расширением. в) Делайте копии исходных файлов, которые вы обрабатываете, и упорядочивайте скрипты для очистки.
Полная версия нейросети
Наша окончательная версия раскрашивающей нейросети содержит четыре компонента. Предыдущую сеть мы разбили на кодировщик и декодировщик, а между ними слой слияния (fusion layer). Если вы не знакомы с классифицирующими нейросетями, то рекомендуем почитать это руководство: http://cs231n.github.io/classification/.Входные данные одновременно проходят через кодировщик и через самый мощный современный классификатор —? Inception ResNet v2. Это нейросеть, обученная на 1,2 млн изображений. Мы извлекаем слой классификации и объединяем его с выходными данными кодировщика.
Более подробное визуальное пояснение: https://github.com/baldassarreFe/deep-koalarization.
Если перенести обучение из классификатора в раскрашивающую сеть, то она сможет понять, что изображено на картинке, а значит и сопоставлять представление объекта со схемой раскрашивания.
Вот некоторые проверочные изображения, для обучения сети использовалось только 20 картинок.
Самые распространённые архитектуры из различных исследовательских работ:
- Вручную добавляем в картинку маленькие цветные точки, чтобы дать сети подсказку (ссылка).
- Находим похожее изображение и переносим с него цвета (подробнее здесь и здесь).
- Слой остаточного кодировщика (residual encoder) и слой классификации объединением (merging classification) (ссылка).
- Объединяем гиперколонок (hypercolumns) из классифицирующей сети (подробнее здесь и здесь).
- Объединяем итоговую классификацию между кодировщиком и декодировщиком (подробнее здесь и здесь).
Цветовые пространства: Lab, YUV, HSV и LUV (подробнее здесь и здесь)
Потери: средняя квадратическая ошибка, классификация, взвешенная классификация (ссылка).
Мы выбрали архитектуру со «слоем слияния» (пятая в списке), потому что она давала лучшие результаты. Также в ней проще разобраться и легче её воспроизвести в Keras. Хотя это не самая сильная архитектура, но для начала сгодится.
Структура нашей нейросети позаимствована из работы Федерико Бальдасарре и его коллег, и адаптирована для работы с Keras. Примечание: в этом коде вместо последовательной модели Keras используется функциональный API. [Документация]
# Get images
X = []
for filename in os.listdir('/data/images/Train/'):
X.append(img_to_array(load_img('/data/images/Train/'+filename)))
X = np.array(X, dtype=float)
Xtrain = 1.0/255*X
#Load weights
inception = InceptionResNetV2(weights=None, include_top=True)
inception.load_weights('/data/inception_resnet_v2_weights_tf_dim_ordering_tf_kernels.h5')
inception.graph = tf.get_default_graph()
embed_input = Input(shape=(1000,))
#Encoder
encoder_input = Input(shape=(256, 256, 1,))
encoder_output = Conv2D(64, (3,3), activation='relu', padding='same', strides=2)(encoder_input)
encoder_output = Conv2D(128, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(128, (3,3), activation='relu', padding='same', strides=2)(encoder_output)
encoder_output = Conv2D(256, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(256, (3,3), activation='relu', padding='same', strides=2)(encoder_output)
encoder_output = Conv2D(512, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(512, (3,3), activation='relu', padding='same')(encoder_output)
encoder_output = Conv2D(256, (3,3), activation='relu', padding='same')(encoder_output)
#Fusion
fusion_output = RepeatVector(32 * 32)(embed_input)
fusion_output = Reshape(([32, 32, 1000]))(fusion_output)
fusion_output = concatenate([encoder_output, fusion_output], axis=3)
fusion_output = Conv2D(256, (1, 1), activation='relu', padding='same')(fusion_output)
#Decoder
decoder_output = Conv2D(128, (3,3), activation='relu', padding='same')(fusion_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
decoder_output = Conv2D(64, (3,3), activation='relu', padding='same')(decoder_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
decoder_output = Conv2D(32, (3,3), activation='relu', padding='same')(decoder_output)
decoder_output = Conv2D(16, (3,3), activation='relu', padding='same')(decoder_output)
decoder_output = Conv2D(2, (3, 3), activation='tanh', padding='same')(decoder_output)
decoder_output = UpSampling2D((2, 2))(decoder_output)
model = Model(inputs=[encoder_input, embed_input], outputs=decoder_output)
#Create embedding
def create_inception_embedding(grayscaled_rgb):
grayscaled_rgb_resized = []
for i in grayscaled_rgb:
i = resize(i, (299, 299, 3), mode='constant')
grayscaled_rgb_resized.append(i)
grayscaled_rgb_resized = np.array(grayscaled_rgb_resized)
grayscaled_rgb_resized = preprocess_input(grayscaled_rgb_resized)
with inception.graph.as_default():
embed = inception.predict(grayscaled_rgb_resized)
return embed
# Image transformer
datagen = ImageDataGenerator(
shear_range=0.4,
zoom_range=0.4,
rotation_range=40,
horizontal_flip=True)
#Generate training data
batch_size = 20
def image_a_b_gen(batch_size):
for batch in datagen.flow(Xtrain, batch_size=batch_size):
grayscaled_rgb = gray2rgb(rgb2gray(batch))
embed = create_inception_embedding(grayscaled_rgb)
lab_batch = rgb2lab(batch)
X_batch = lab_batch[:,:,:,0]
X_batch = X_batch.reshape(X_batch.shape+(1,))
Y_batch = lab_batch[:,:,:,1:] / 128
yield ([X_batch, create_inception_embedding(grayscaled_rgb)], Y_batch)
#Train model
tensorboard = TensorBoard(log_dir="/output")
model.compile(optimizer='adam', loss='mse')
model.fit_generator(image_a_b_gen(batch_size), callbacks=[tensorboard], epochs=1000, steps_per_epoch=20)
#Make a prediction on the unseen images
color_me = []
for filename in os.listdir('../Test/'):
color_me.append(img_to_array(load_img('../Test/'+filename)))
color_me = np.array(color_me, dtype=float)
color_me = 1.0/255*color_me
color_me = gray2rgb(rgb2gray(color_me))
color_me_embed = create_inception_embedding(color_me)
color_me = rgb2lab(color_me)[:,:,:,0]
color_me = color_me.reshape(color_me.shape+(1,))
# Test model
output = model.predict([color_me, color_me_embed])
output = output * 128
# Output colorizations
for i in range(len(output)):
cur = np.zeros((256, 256, 3))
cur[:,:,0] = color_me[i][:,:,0]
cur[:,:,1:] = output[i]
imsave("result/img_"+str(i)+".png", lab2rgb(cur))FloydHub-команда для запуска полной версии нейросети:
floyd run --data emilwallner/datasets/colornet/2:data --mode jupyter --tensorboardТехнические пояснения
Функциональный API Keras замечательно подходит для конкатенации или объединения нескольких моделей.Для начала скачаем нейросеть Inception ResNet v2 и загрузим значения весов. Раз мы параллельно будем использовать две модели, то нужно определить, какие именно. Это делается в Tensorflow, бэкенде Keras.
inception = InceptionResNetV2(weights=None, include_top=True)
inception.load_weights('/data/inception_resnet_v2_weights_tf_dim_ordering_tf_kernels.h5')
inception.graph = tf.get_default_graph()Создадим серию (batch) из подправленных изображений. Переведём их в ч/б и прогоним через модель Inception ResNet.
grayscaled_rgb = gray2rgb(rgb2gray(batch))
embed = create_inception_embedding(grayscaled_rgb)Сначала нужно изменить размер картинок, чтобы скормить их модели. Затем с помощью препроцессора приведём пиксели и значения цветом к нужному формату. И наконец прогоним изображения через сеть Inception и извлечём итоговой слой модели.
def create_inception_embedding(grayscaled_rgb):
grayscaled_rgb_resized = []
for i in grayscaled_rgb:
i = resize(i, (299, 299, 3), mode='constant')
grayscaled_rgb_resized.append(i)
grayscaled_rgb_resized = np.array(grayscaled_rgb_resized)
grayscaled_rgb_resized = preprocess_input(grayscaled_rgb_resized)
with inception.graph.as_default():
embed = inception.predict(grayscaled_rgb_resized)
return embedВернёмся к генератору. Для каждой серии сгенерируем по 20 изображений описанного ниже формата. На Tesla K80 GPU ушло около часа. При использовании такой модели эта видеокарта может генерировать до 50 изображений за раз без каких-либо проблем с памятью.
yield ([X_batch, create_inception_embedding(grayscaled_rgb)], Y_batch)Это соответствует формату нашей модели colornet.
model = Model(inputs=[encoder_input, embed_input], outputs=decoder_output)encoder_inputis передан в модель Encoder, её выходные данные потом объединяются в слое слияния с embed_inputin; выходные данные слияния подаются на вход модели Decoder, которая возвращает итоговые данные — decoder_output.fusion_output = RepeatVector(32 * 32)(embed_input)
fusion_output = Reshape(([32, 32, 1000]))(fusion_output)
fusion_output = concatenate([fusion_output, encoder_output], axis=3)
fusion_output = Conv2D(256, (1, 1), activation='relu')(fusion_output)В слое слияния мы сначала слой с 1000 категорий (1000 category layer) умножаем на 1024 (32 * 32). Так мы получаем из модели Inception 1024 ряда итогового слоя. Сетка 32 х 32 переводится из двухмерного в трёхмерное представление, с 1000 столбцов категорий (category pillars). Затем столбцы связываются с выходными данными модели кодировщика. Применяем свёрточную сеть с 254 фильтрами и ядром 1х1 к окончательным результатам слоя слияния.
Чему научились
- Терминология в исследовательских работах была пугающей. Мы потратили три дня на поиски способа реализации «модели слияния» в Keras. Это звучит так сложно, что просто не хотелось браться за эту задачу, мы старались найти советы, которые облегчат нам работу.
- Вопросы в сети. В Slack-канале Keras не нашлось ни единого комментария, а на Stack Overflow заданные вопросы были удалены. Но начав разбирать проблему публично в поисках простого ответа, нам стало понятнее, как решать эту задачу.
- Рассылка писем. На форумах вас могут проигнорировать, но если обратиться к людям напрямую, они будут отзывчивее. Нас воодушевили обсуждения работы с цветовыми пространствами с исследователями по Skype!
- После затруднений с решением задачи слияния, мы решили сначала написать все компоненты, а потом объединить их друг с другом. Вот несколько экспериментов по разбиению слоя слияния.
- Если казалось, что какой-то компонент должен теперь работать, то уверенности в этом не было. Мы знали, что с основной логикой полный порядок, но не верили, что она будет работать. После чая с лимоном и долгой прогулки решились запустить. На первой же строке нашей модели появилась ошибка. Но спустя четыре дня, несколько сотен багов и несколько тысяч запросов в Google, при работе модели появилось заветное “Epoch 1/22”.
Что дальше
Раскрашивание изображений — это очень интересная задача. Здесь приходится заниматься и наукой, и творчеством. Возможно, эта статья поможет вам сэкономить время. С чего вы могли бы начать:- Реализовать другую заранее обученную модель.
- Попробовать другой датасет.
- Использовать больше картинок, чтобы увеличить точность работы нейросети.
- Написать усилитель (amplifier) для цветового пространства RGB. Создайте аналогичную модель для раскрашивающей сети, которая берёт на вход очень насыщенные цветные изображения, а на выходе получаются картинки с корректными цветами.
- Реализуйте взвешенную классификацию.
- Примените нейросеть к видео. Уделите внимание не точности раскрашивания, а стабильности переходов между отдельными кадрами. Или можете собирать большие изображения из мелких «лоскутков».
Можете раскрасить свои чёрно-белые изображения с помощью всех трёх описанных версий нейросети на FloydHub.
- Для применения альфа-версии просто замените файл woman.jpg на свой файл с тем же названием (размером 400x400 пикселей).
- Для бета-версии и полной версии добавьте свои картинки в папку Test, а потом выполните FloydHub-команду. Или можете загрузить их напрямую в Notebook в папку Test, прямо во время работы. Эти изображения должны быть строго 256x256 пикселей. Все тестовые картинки можете загрузить в цвете, они всё равно будут автоматически преобразованы в чёрно-белые.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru