Машинное обучение в лингвистике
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-11-18 07:20


В одном из эпизодов сериала «Игра престолов» два враждебных друг другу персонажа мерились армиями. Тот, у кого она была малочисленнее, в свое оправдание сказал, что если бы дело было в количестве, то войны бы выигрывали математики. Машинное обучение — это та самая война, в которой побеждают математики.
Проблема данных и малой выборки в теоретическом плане осмыслялась давно. Но на практике данные, которые могли стать основой моделей для машинного обучения, в особенности глубокого обучения, появились совсем недавно. Сегодня мы можем наблюдать настоящий бум в том, что касается применений методов машинного обучения, который произошел за счет трех основных факторов. Один из них заключается в том, что появились подходящие для обучения данные. Их легко получить, посмотреть на них, попробовать обучить на них модель (два другие фактора — это появление подходящих для таких задач быстрых графических процессоров и решение нескольких математических задач, что сняло фундаментальные ограничения методов глубокого обучения).
Малая выборка
Данные, объем которых невелик по сравнению с Big Data, либо небольшая выборка из общей совокупности, которые плохо подходят для моделей машинного обучения
В 1980–1990-х годах началась новая эпоха: стали стремительно распространяться персональные компьютеры, а параллельно с этим активно развивалось машинное обучение. Тогда же стала очевидна проблема недостатка данных и их определенной специфичности. Сегодня возможностей для работы с данными гораздо больше. Любой первокурсник может самостоятельно загрузить библиотеку, прочитать тьюториал, послушать лекции в интернете, скачать датасет и попробовать построить модель. Становится доступно все больше материалов, связанных с глубинным обучением нейронных сетей.
Проблема в том, что машинное обучение — это в определенном смысле демократия. Большинство голосует за то, что им нравится, и, если на это большинство определенным образом воздействовать, оно выберет то, что нужно.
В статистике есть понятие выбросов — отступлений от того, что описывается функцией, которую пытаются найти в процессе машинного обучения. Эти выбросы либо совсем не учитываются, либо очень слабо влияют на общий результат. Одним словом, в машинном обучении данные представляют собой почти общественную структуру, проблемы которой нам хорошо известны. У пользователей социальных сетей можно часто увидеть призывы идти против системы. И если бы данные были живыми, они могли бы вести себя примерно так же. Теоретические размышления такого плана появились давно, но на практике эти явления стали очевидны совсем недавно.
Атаки на модели машинного обучения
Недавно появились сообщения о своеобразных атаках на модели машинного обучения. Это касалось сферы распознавания образов, например дорожных знаков. Допустим, модель была обучена на определенных снимках, изображениях дорожных знаков. Но если в тестовой выборке на некоторые снимки поместить стикеры, создать помехи, которые, может, и незаметны человеческому глазу, модель начнет ошибаться. То же самое и с распознаванием лиц: в интернете можно найти информацию о способах обойти систему видеонаблюдения и распознавания лиц при помощи нанесения специальных узоров на лицо.
В 2017 году сотрудник компании «Яндекс» Григорий Бакунов придумал макияж, с помощью которого можно обмануть систему распознавания лиц.
Но это, конечно, не единственная проблема в машинном обучении. Как правило, в процессе работы обнаруживается, что просто ничего не работает, например, потому, что данные сбалансированы не так, как хотелось бы.
Автоматическая обработка текста и машинное обучение
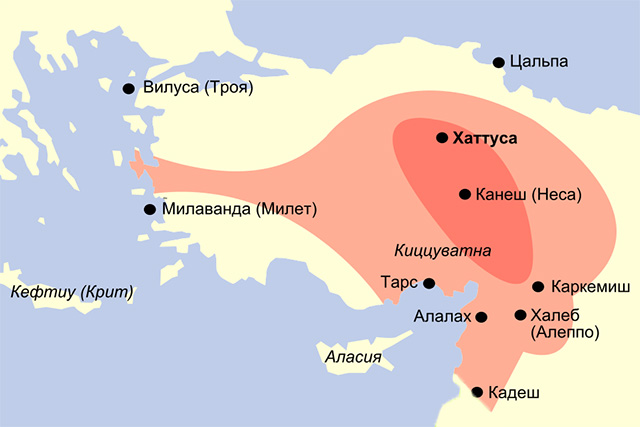
Примеры из обработки текста на фоне таких новостей выглядят менее типичными. Машинное обучение и глубинное обучение работают немного по-разному. Для машинного обучения действительно часто не хватает данных. Недавно мне и моим коллегам довелось работать над системой, которая должна распознавать форму слова в хеттском языке. В этой задаче возникло много разных проблем. В первую очередь хеттский язык использовался очень давно, и его живых носителей сегодня, конечно же, нет. Клинописные памятники — это очень ограниченный материал, который требует долгой специфичной обработки, после которой его можно загрузить в компьютер.
Хеттский язык
Древнейший индоевропейский язык, зафиксированный в письменных памятниках. Был распространен на территории Хеттского царства в Малой Азии. Вымер около X в. до н.э.
Вообще работа с древними и мертвыми языками требует гораздо больших усилий, чем с современными, — по разным причинам. Например, специалисты по греческому, древнерусскому и другими древним языкам относятся к своим данным гораздо строже, чем люди, которые занимаются современной компьютерной лингвистикой. Ведь обычно программисты просто выкачивают из социальных сетей, архива какого-нибудь СМИ несколько миллионов словоупотреблений и работают с ними, не обращая особого внимания на опечатки и ошибки.
Ученые, которые работают с древними текстами, приучены по-другому относиться к своему материалу и требуют, чтобы не было ни одной опечатки. Это особенности научной школы. Та же история была и с хеттскими текстами: приходилось мириться с очень щепетильным отношением эксперта к материалу, которого и так мало. И на этом ограниченном материале модель должна научиться отличать глагол от существительного, прилагательное от предлога. Традиционный подход, который сегодня считается устаревшим, предлагал написать некоторое количество правил, при помощи которых модель могла бы определить форму, флексии слова и так далее.
Машинное обучение подошло к этой задаче по-новому. Но обучать модели на маленьком материале — очень болезненная задача. В таких ситуациях случайным считается результат, при котором модель работает правильно в 50% случаев. Иногда получается чуть лучше. В случае с хеттским языком машина в конце концов запуталась в определении грамматических категорий, которые мало встречались в исходной выборке.
Есть и более удачные примеры, например с языком идиш. У нас был проект, посвященный его графике, — это целая огромная задача. Вообще для лингвистов вопросы, связанные с графикой, являются довольно специфичными: как правило, они все-таки занимаются падежами, частеречными вопросами, стилистикой, конструкцией предложений, а графика считается вторичной формой представления языка, поэтому не очень важной. Но так как компьютерные лингвисты имеют дело в основном с письменными текстами, зафиксированными в графическом виде, то им приходится иметь дело с этим «низменным» материалом. И оказывается, что для идиша он настолько разнообразен, что машина не может так просто с ним справиться.
Есть определенный подход к стандартизации, который предполагает некоторое написание текстов на идише. В течение последних десятилетий было много попыток оцифровать многочисленные старые тексты на этом языке, привести их к какому-то единообразному написанию и применить к ним инструменты компьютерной лингвистики. Оказалось, что в некоторых случаях, опираясь на правила, мы можем транспонировать какой-нибудь старый вариант графемы в ее современное написание. Но в иных случаях у нас нет возможности сделать это при помощи правил. И поэтому потребовалось машинное обучение. С ним получилось немного проще по той причине, что мы работали с буквами, ведь слов в материале оказывается меньше, чем отдельных букв, так как графемы — это более мелкие единицы. Поэтому в итоге точность была несколько больше. Но все-таки это была достаточно специфичная задача, и так срабатывает не всегда.

Идиш — еврейский язык германской группы
Глубинное обучение и языки мира
Для глубинного обучения в области обработки естественного языка хороших примеров пока что гораздо меньше, но они тоже есть. Например, наши студенты недавно научили нейронную сеть правильно расставлять ударения в словах — это грандиозная победа, результаты были очень высокими, более 90%. Но это скорее исключение: чаще оказывается, что завышенные ожидания от нейронных сетей себя не оправдывают.
На глубинное обучение были возложены надежды, связанные с традиционными задачами компьютерной лингвистики. Прежде чем извлекать информацию из текста, определять семантические отношения и модели, с языком нужно провести ряд операций: привести все слова (если они в данном языке грамматически изменяются) к единой форме, определить род, падеж, число (опять же — если они есть в языке). Но бывают языки, для которых эти задачи крайне сложны из-за очень громоздкой системы словоизменения. Работа с такими языками очень сложна для компьютерных лингвистов, поэтому они пока смотрят на них как бы издалека. Таким, например, является грузинский язык, для него долгое время не было даже таких простых инструментов, как определение формы слова.
Предполагалось, что глубинное обучение поможет решить эти проблемы для таких языков, в которых сложно отталкиваться от правил. Такие исследования ведутся для древнеирландского языка, и пока есть надежды, что техника победит природу. Но пока этого не произошло. Также и с идеей создания лемматизатора (то есть такой программы, которая приводила бы слово к его исходной форме) успехи пока среднего масштаба. Это, конечно, лучше, чем ничего, но все-таки не настолько хорошо, чтобы результаты могли стать серьезным инфоповодом.
Древнеирландский язык
Использовался на территории Ирландии, Шотландии, Уэльса и острова Мэн в VI-X веках.
Итак, некоторые классические задачи для простых случаев уже решены, и есть надежда, что и для сложных случаев мы увидим решение этих задач. Иногда проблема заключается в недостаточности выборки, как, например, было с хеттским языком: там просто неоткуда было взять больше текстов. Чтобы получить хороший результат при машинном обучении, нужно очень много текстов, предварительно обработанных экспертом, на которых можно было бы обучить модель. Но если текстов для того же хеттского немного, то эксперт может и сам все разметить — и зачем тогда машинное обучение? Его смысл в таком случае теряется. То есть этот метод не подходит для ограниченных корпусов.
Анализ языка: с учителем и без
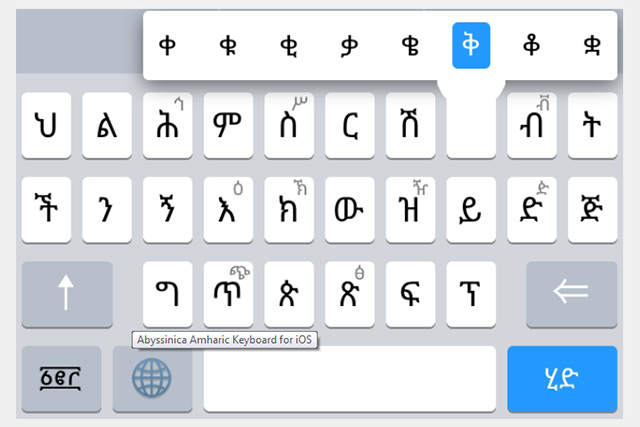
Был еще один интересный эксперимент, связанный с амхарским языком. На этом языке говорят порядка двадцати пяти миллионов человек. Для таких сравнительно крупных языков задачи, связанные с компьютерной морфологической обработкой, в основном решены. А вот амхарский язык пострадал из-за структуры нашего глобального общества. Несмотря на то что это достаточно крупный по числу носителей язык, экономическое положение в регионе его распространения таково, что нет смысла вкладывать деньги в разработку компьютерных инструментов для этого языка. Силами студентов был реализован проект, целью которого являлось взять амхарские тексты и попробовать натренировать на них модель по схеме обучения без учителя. Обычно эта модель не используется для морфологического анализа — а в данном случае речь шла именно о нем, а точнее, о частеречном анализе. В таких случаях обычно все-таки обучают с абстрактным «учителем», то есть экспертом, который заранее размечает обучающую выборку, смотря на которую модель пытается вывести функцию и научиться правильно размечать данные самостоятельно.
Амхарский язык
Государственный язык Эфиопии. Распространен в Эритрее, Сомали, и восточных районах Судана.
В этом эксперименте с амхарским языком тексты не были заранее размечены. Хотя с интернетом в Эфиопии все не очень хорошо, публикации из местных газет все же выкладываются во Всемирную сеть и оказываются доступны для скачивания, поэтому корпус текстов можно собрать. Есть даже амхарская Wikipedia. Эксперты по амхарскому языку в Москве тоже есть, но их мало, и потребовалось бы очень много времени и усилий, чтобы разметить большой массив текстов. Поэтому было решено обойтись малой кровью и попробовать применить обучение без учителя. При использовании этого метода модели на вход подаются какие-то слова, буквы, и теоретически она может установить в них какие-то закономерности, разбить слова на некие классы. Конечно, она не определит, где существительное, а где прилагательное, но классы будут отличаться друг от друга по различным структурным характеристикам. А определять, что это за классы, уже будет человек. Правда, не зная амхарского языка, сделать это не так уж и просто, так как в нем используется не латинская графика и даже не фонематическое письмо (то есть конкретная буква не означает конкретный звук), а слоговое. Для исследователя работать с неизвестным языком — это настоящее испытание. В результате процент попаданий был не очень высокий, хотя на тот момент ничего подобного для амхарского языка сделано не было.
Проблемы разметки данных
Хорошо, когда данные есть, но если они не структурированы, отдельная задача состоит в том, что превратить их во что-то пригодное для машинного обучения. Известно, что в распознавании лиц больших успехов достиг Facebook. За счет чего? Пользователи несколько лет самостоятельно, абсолютно бесплатно размечали для него данные: они отмечали лица на фотографиях и подписывали, кто это. И в какой-то момент оказалось, что у Facebook есть огромное количество готовых, размеченных и обработанных данных. Но, как правило, их не так просто получить.
Эта ситуация как раз очень типична для языков, распространенных в бедных, экономически неблагополучных районах, — вроде амхарского языка — или для малых языков, слабо представленных в интернете, например для языков народов России. На них пользователи в интернете, в социальных сетях, написали довольно мало. И даже для такого небольшого объема данных есть необходимость разметить их вместе с экспертами, с людьми, которые читают на этих языках. Они могут вручную разметить какой-то объем текстов, но для машинного обучения данных нужно очень много. Как говорилось выше, машинное обучение — это демократия. Если 5% населения придет на выборы — разве это выборы? Они не будут отражать реальных настроений общества. Точно так же и с данными: малая выборка может оказаться попросту нерелевантной. Специалистам по любым компьютерным системам хорошо известно: машина будет работать тем лучше, чем больше на этапе подготовки в нее вложено человеческого труда.
Конечно, в последнее время количество данных увеличивается. Но надо сказать, что обработанных данных становится больше только в тех областях, где есть деньги. Например, ImageNet и распознавание изображений вообще очень прибыльная история. А найти деньги для амхарского языка или горномарийского, у которого около двадцати тысяч носителей, гораздо сложнее. Конечно, государство иногда пытается поддерживать малые языки. Но без инвестиций хорошо размеченные данные не получить, и в итоге процент точности будет сопоставим со случайным.
ImageNet
База данных аннотированных изображений, предназначенная для отработки и тестирования методов распознавания образов и компьютерного зрения
Краудсорсинг и обработка текстов
Хорошим решением может быть краудсорсинг. Особенно это касается малых языков, в которых не заинтересованы крупные компании, разве что из имиджевых соображений. Представители башкирского этноса, например, активно развивают деятельность в интернете. У нас был отдельный проект по созданию чат-бота на башкирском языке. А для чат-ботов прежде всего нужны тексты, причем диалогового характера: один участник что-то говорит, другой ему отвечает. Для башкирского языка для этих целей попробовали взять диалоги, переписки из «ВКонтакте». Но этих данных оказалось мало, ведь чат-боты делаются как раз с помощью глубинного обучения, особенно чувствительного к размеру выборки.
В нашем случае данные — это последовательности букв, которые складываются в тексты. Последовательность подается на вход нейронной сети, и последовательность мы должны получать на выходе. Но все-таки в социальных сетях эти диалоги не вполне естественны, и, в конце концов, их мало, они ограниченны и однообразны, так же как и комментарии в записям. Обученный на таких данных чат-бот получается довольно глупым. Кроме того, очевидно, что не все захотят отдавать свои личные переписки даже для таких целей.
Носители башкирского языка могли помочь и иначе, например оценить, насколько хорошо чат-бот говорит по-башкирски, или внести предложения по ответам на определенные запросы. Однако, таких активистов, готовых помочь, оказалось немного. Но все же краудсорсинг, конечно, замечательная идея, и люди, которые не знают, чем занять себя вечером, вполне могут потратить это время на что-то полезное вроде разметки данных для машинного обучения, но на самом деле так не происходит.
Другая проблема заключается в том, что при создании моделей на основе машинного или глубинного обучения исследователи одновременно ставят много разных задач. И те данные, которые при помощи краудсорсинга были размечены для одной задачи, совершенно не годятся для другой. Поэтому краудсорсинг все же неуниверсальная идея.
Перспективы
Более-менее реалистичный сценарий решения этих проблем уже сформировался. Он заключается в том, что есть коммерчески перспективные задачи, в которые вкладываются компании, оплачивают разметку. Например, поисковые компании по каким-то имиджевым причинам могут сделать поиск сайтов на языках малых народов России. Для этих целей привлекают асессоров — тех самых разметчиков, которым платят за то, чтобы они оценивали, например, результаты поиска.
Распознавание образов — это та история, в которую вкладываться выгодно. Лингвистика со своей стороны не всегда может предложить коммерчески перспективные решения. Компьютерные исследования в некоммерческом секторе лингвистики, безусловно, развиваются, но происходит это в основном внутри академических институций за счет грантов, то есть денег научных фондов. Но в обоих случаях это наука, так или иначе мы постигаем и получаем некоторые знания. Но наука в классическом понимании все же существует в основном в университетах, и именно там происходит определенное движение — пусть методом проб и ошибок, но в нужном направлении.
Телеграм: t.me/ainewsline
Источник: postnauka.ru