Классификация на гуманитариев и технарей по комментариям в VK
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-11-17 12:51
компьютерная лингвистика, анализ социальных сетей, реализация нейронной сети
Хочу поделиться своим опытом классификации пользователей социальной сети по их комментариям на два класса по складу ума: гуманитарный или технический. В данной статье не будут использоваться последние достижения глубокого обучения, но будет разобран завершенный проект по классификации текстов: от поиска подходящих данных до предсказаний. В конце будет представлено веб-приложение, в котором вы сможете проверить себя.

Постановка задачи
Задача в нашем случае бинарной классификации ставится так: есть пользователь, есть его комментарии, и по ним необходимо определить класс: гуманитарий или технарь. Для решения этой задачи применим техники машинного обучения и обработки естественного языка. Итоговый результат можно будет использовать, например, для таргетированной рекламы.
Данные
Существующей размеченной выборки нет: эти понятия сложно формализовать, и необходимо будет по каким-то признакам разделить пользователей на два класса.
Решено было собрать свой набор данных на основе комментариев пользователей социальной сети “ВКонтакте”. На публичных страницах люди обычно обсуждают посты или просто общаются, оставляя множество комментариев. Страница паблика/группы должна быть нейтральной тематики для того, чтобы количество гуманитариев и технарей примерно совпадало. Я выбрал публичную страницу, посвященную обсуждению жизни конкретного города. Количество подписчиков – около 300 тысяч, количество публикаций – около 50 тысяч, среднее количество комментариев к публикации – 20.
Получение и разметка данных
Выкачать все комментарии можно с помощью VK Open API, с помощью которого было получено около 3 миллионов комментариев от 130 тысяч пользователей. Этого количества должно с запасом хватить, чтобы обучить почти любую модель машинного обучения, но есть одно “но”: у нас нет разметки этих данных, мы не знаем, кто гуманитарий, а кто технарь. Конечно, можно было бы попытаться написать каждому из пользователей и спросить у них лично, но это сомнительная идея. Придется использовать те знания, которые мы можем получить со страниц пользователей.
Только у 11 тысяч человек из 130 был указан факультет образования. В результате такой фильтрации осталось только 170 тысяч комментариев, что составляет только 6% от исходного объема. Всего различных факультетов оказалось 160. Я разделил все факультеты на гуманитарные, технические и другие (естественные или вовсе не относящиеся к научным, например, музыкальные или художественные). Эти “другие” факультеты были отброшены и не участвовали в эксперименте. Каждому пользователю был присвоен класс в соответствие с факультетом, который был указан у него в профиле.
Возможно не все, кто учатся на гуманитарных факультетах, являются гуманитариями, и то же можно сказать о технических, но на общем фоне таких пользователей должно быть меньшинство. Для подтверждения или опровержения этой теории мною был организован соцопрос на своем факультете. Из 200 человек 62 (то есть 31%) указали, что их склад ума — гуманитарный несмотря на то, что сам факультет технический. Аналогично, на гуманитарном факультете из 150 опрошенных 14 человек (только 9%) признались в том, что они технари в душе. Таким образом, более правильно назвать классификацию по таким данным классификацией по типу полученного высшего образования.
Анализ данных
Пример таблицы с данными по комментариям:

Прежде чем переходить к построению моделей, необходимо провести анализ имеющейся выборки. Это поможет понять, какие признаки нужно учитывать, как они распределены и какие модели лучше использовать. Также это помогает найти выбросы и аномалии в данных, которые не типичны для данной выборки. Их удаление поможет построить модель с большей обобщающей способностью. После разделения пользователей в обоих классах получилось примерно по 4000 человек. Сначала посмотрим на распределение не текстовых признаков пользователей.
Пол
В выборке пользователей мужского пола оказалось 55%. В обществе существует стереотип, что у мужчин более аналитический склад ума, а у женщин — гуманитарный или творческий. По данным выборки построен график, который показывает распределение этого признака отдельно по двум классам.
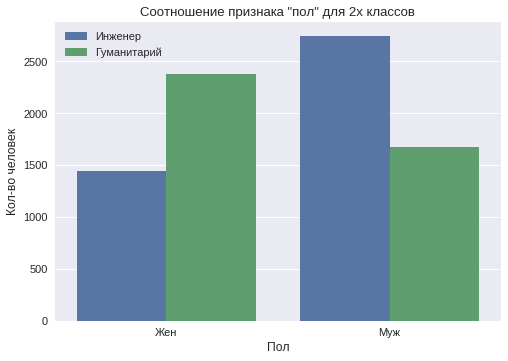
Видно, что среди пользователей мужского пола преобладает класс «технарь», а среди пользователей женского пола — «гуманитарий».
Отношение к алкоголю
Около 1500 пользователей из каждого класса отметили своё отношение к алкоголю и около 1600 — к курению. Конечно, многие не заполняют этот пункт в социальных сетях, лишь у 30% он был указан. Какая-то часть могла указать заведомо ложную информацию, чтобы показать себя в лучшем свете или произвести впечатление на одноклассников. Но общая тенденция в различии двух классов все равно просматривается.
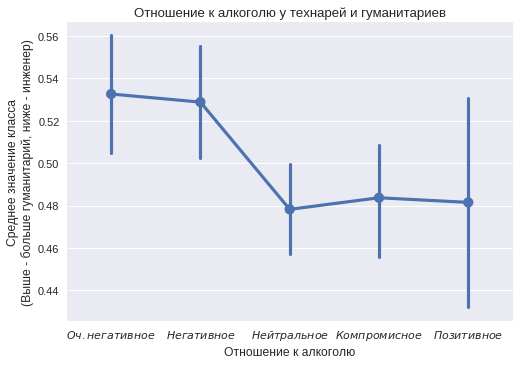
По оси абсцисс расположены категории от «очень негативное» до «позитивное» отношение к алкоголю. Для каждой категории считалось количество человек в обоих классах. На оси ординат обозначена доля гуманитариев в группе. Вертикальной полосой обозначен доверительный интервал. По графику видно, что технари чаще указывают у себя в профиле позитивное отношение к алкоголю. Очень негативное отношение чаще указывают гуманитарии.
Отношение к курению
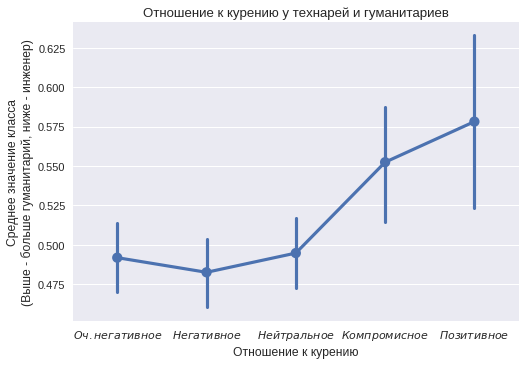
В отношении к курению видна противоположная ситуация. Пользователи из класса «гуманитарий» чаще указывают позитивное отношение к курению. Видно, что не все значения отличаются от статистически значимых (некоторые доверительные интервалы включают значение 0.5, значит нельзя заявлять о различии), но тенденция все равно интересная.
Семейное положение и главное в жизни
По признаку «семейное положение» сильный перекос есть только в двух: «всё сложно» и «в активном поиске». Они оба смещены в сторону «гуманитарий».
По признаку «главное в жизни» — значимое отклонение есть только по одному — «красота и искусство», — и оно в сторону класса «гуманитарий».
Время активности
Построим распределение активности пользователей в разное время суток.
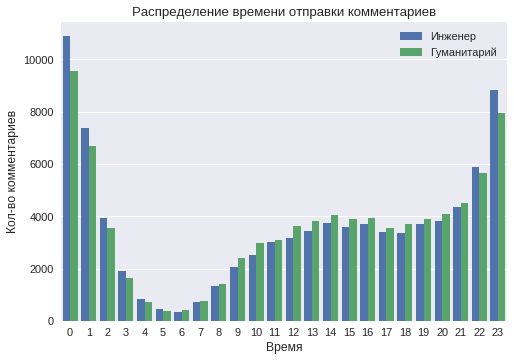
По графику видно, что в ночные часы (с 11 до 2) количество комментариев от класса «технарь» значительно больше. Это говорит о более «ночном» образе жизни пользователей этого класса. Также видно, что наименьшая активность наблюдается в 5-6 часов утра. Тем не менее, начиная с 4-х часов утра, количество комментариев от пользователей класса «гуманитарий» значительно больше, что говорит о более раннем времени подъема.
Примеры комментариев
Перед дальнейшим анализом можно посмотреть сами комментарии. Далее представлены несколько примеров из обеих групп.
Класс «технарь»: «Антон, ты когда-нить на заблокированных колесах останавливался? Какой тормозной путь получается?», «поддержим своих, конечно ) 21-го на Труде )», «Первое фото очень оригинально и весьма красиво!».
Класс «гуманитарий»: «Очень симпотичные котятки', '=)))», «По — моему, делается всё для того, чтобы дети знали, как можно больше о наркотиках.», «я не успеваю за скоростью твоей мысли))))я безнадежен».
Видно, что комментарии написаны на разные темы. Можно постараться найти различия в затрагиваемых тематиках. Слова нужно будет привести к начальной форме, чтобы избежать множества похожих слов, одинаковых по смыслу. Возможно даже простое выделение используемых слов сможет хорошо разделять два класса. Также большое внимание нужно уделить используемым смайлам, эмодзи и пунктуации.
Предобработка данных
Первоначально необходимо удалить из выборки слишком длинные и слишком короткие комментарии. Они могут помешать обобщать моделям. Максимальная длина была ограничена 50-ю словами, а минимальная – 3-мя словами. Далее необходимо избавиться от спама. Сначала были удалены все комментарии, которые включали в себя ссылки на сторонние сайты, их оказалось менее 1%. Затем были удалены сообщения, которые повторялись более 2х раз, а значит были спамом, тоже менее 1%.
В данных было очень много обращений. В комментариях можно обращаться к определённому человеку через ссылку на его страницу. При скачивание через API имена заменяются на id страницы пользователя. Чтобы не засорять модель информацией об id, а также не допустить запоминания конкретных личностей, все обращения были удалены.
Генерация признаков
После анализа и очистки данных в задачах машинного обучения начинается этап построения и отбора признаков. Полезность финальной модели напрямую зависит от количества и качества полученных признаков.
Прежде чем начать работу с текстом, его нужно токенизировать, то есть разбить на слова. Это можно сделать с помощью стемминга или лемматизации. Стемминг – это выделение основы слова, откидывание окончания. Например, слова: “демократия”, «демократический», “демократизация” приводятся к слову «демокр». Лемматизация – это приведение слова к начальной форме. Все три слова из предыдущего примера приводятся к слову “демократия”. В данной задаче лучше сработала лемматизация, выполненная с помощью библиотеки pyMorphy2.
Векторизация текста
Необходимо комментарии трансформировать в векторы, потому что большинство моделей машинного обучения принимают на вход численные векторы. Самый простой подход называется мешок слов: он считает количество вхождений в текст каждого из слов. Перед тем, как получать векторы таким способом, необходимо избавиться от стоп-слов. Это такие слова, которые встречаются очень часто и не несут смысловой нагрузки, например, «иначе», «это», «или» и так далее.
При таком подходе не учитывается порядок слов в предложение. Фразы «не черный кот» и «кот черный не» будут преобразованы к одинаковому вектору, потому что в них одинаковый набор слов. Чтобы решить эту проблему, можно использовать идущие подряд токены – N-граммы.
Такие же векторы признаков можно строить и на уровне символов. Текст разбивается на N-граммы символов, где N обычно берется равное трем. Слово «лесной» разобьётся на: «лес», «есн», «сно», «ной». Этот подход имеет большое преимущество: он более устойчив к новым словам, которых не было в обучающей выборке.
Также для векторизации текста использовался Tf-Idf. Это статистическая мера, используемая для оценки важности слова в контексте документа, являющегося частью коллекции документов или корпуса. Большой вес получают слова с высокой частотой в пределах конкретного документа и с низкой частотой употреблений в других документах. Более подробно на хабре, например здесь.
Последняя опробованная модель векторизации — word2vec. Векторное представление основывается на контекстной близости: слова, встречающиеся в тексте с одним контекстом, в векторном представлении будут иметь близкие координаты. В интернете можно найти уже обученные на больших корпусах модели, которые сопоставляют слову его вектор. Отличные примеры работы word2veс на хабре.
Другие признаки
Другими источниками признаков стали общие характеристики комментария. Они описывают комментарий в целом.
Пунктуационные признаки:
- наличие прямой речи;
- количество запятых, знаков вопроса, восклицательных знаков, многоточий;
- количество смайлов вида «)», «))», «((».
Признаки содержания:
- процент слов, написанных CapsLock-ом;
- процент английских слов;
- наличие большой буквы в начале предложения.
Общие признаки:
- количество слов;
- количество предложений;
- средняя длина слова;
- средняя длина предложения.
Процесс получения предсказаний
Получив вектор признаков, перейдем к обучению моделей. Использование ансамбля нескольких моделей вместо одной предпочтительнее, так как это повышает точность и уменьшает дисперсию предсказаний. Строится несколько моделей, затем они опрашиваются по каждому объекту, который нужно классифицировать, и победитель выбирается по большинству голосов, — принцип простого голосования.
Пользователи были разделены на две части в пропорции 80 к 20. На первой проводилось обучение моделей, на второй – тестирование. Так как классы были сбалансированы, то за метрику была взята точность (accuracy) – это отношение числа верно классифицированных примеров к общему количеству примеров.
Итоговая задача – классифицировать пользователей, но так как классификация осуществляется по текстовым комментариям, то модели будут классифицировать каждый комментарий по отдельности. Чтобы сделать предсказание для пользователя, будем выдавать наиболее частый класс, предсказываемый для его комментариев ансамблем моделей.
Каждая модель будет обучаться на своем подмножестве признаков. Таким образом, модели получаются более устойчивы к выбросам, их предсказания становятся менее коррелированы, и ошибка обобщения (generalization error) минимальна.
Используемые модели
Линейная регрессия – модель, которая линейно взвешивает входные признаки. Линейные модели хорошо подходят для задач с большим количеством разреженных признаков, а векторное представление текста как раз таким и является. Также можно интерпретировать веса перед признаками. Например в случае векторизации с помощью мешка слов, положительный вес перед словом означает, что вероятность принадлежности к первому классу больше.
Многослойная нейронная сеть – модель, которая состоит из нескольких слоев с нейронами. Благодаря неоднократному применению функции активации, нейронная сеть представляет собой нелинейную функцию, что позволяет, теоретически, захватывать более сложные зависимости в данных.
Рекуррентная нейронная сеть – вид нейронной сети, который был специально создан для моделирования и анализа последовательностей (например, слов или символов). С помощью такой модели получается учитывать не только наличие конкретных признаков, но и их порядок.
Предсказания нейронных сетей намного сложнее интерпретировать. Чтобы получить хорошие результаты, нужно перебрать множество гиперпараметров: количество нейронов, количество слоев, величину регуляризации и другие. Для обучения нейронных сетей использовался фреймворк Keras. Более подробно о нейронных сетях можно почитать в серии статей на хабре.
Три модели, которые были перечислены выше, принимают на вход комментарии с различными вариантами векторизации: мешок слов, Tf-Idf, word2vec. Техника мешка слов применялась как на на уровне слов, так и на уровне символов. Как было сказано выше, чем больше разных моделей, тем лучше, поэтому были отобраны несколько вариантов одних и тех же моделей с различными гиперпараметрами.
Последняя модель – градиентный бустинг деревьев. Этот алгоритм показывает хорошие результаты в случае работы с количественными и категориальными признаками. В отличие от предыдущих моделей, она обучалась на общих характеристиках комментария (количество запятых, средняя длина слова и других статистиках). Использовалась библиотека XGBoost.
С помощью валидации были выбраны модели, которые показывали лучшее качество на уровне пользователей. Они и вошли в финальный ансамбль. Также была проанализирована корреляция между предсказаниями моделей.
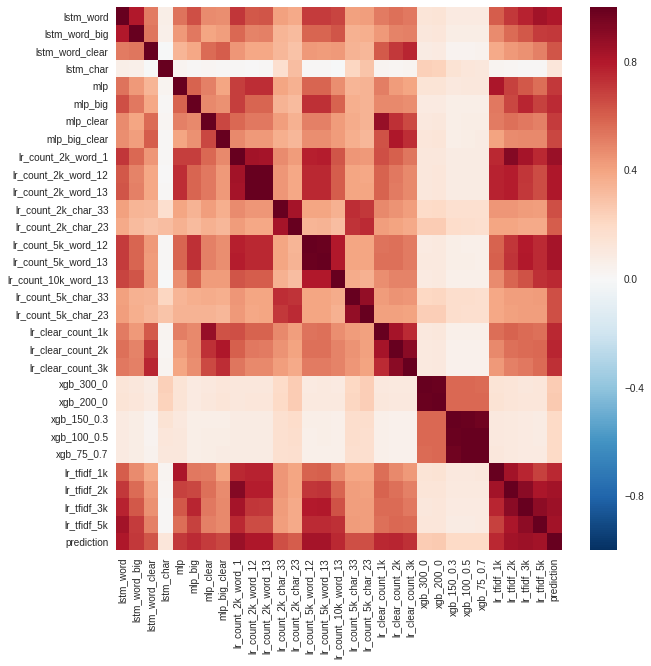
Можно заметить, что сильнее всего отличались предсказания моделей градиентного бустинга (xgb) и рекуррентной сети на уровне символов (lstm_char). Строка prediction — ансамбль всех моделей.
Модели выбирались в ансамбль не только по точности, но и по некоррелированности предсказаний. Если две модели имеют одинаковую точность и очень похожи, — толку от их усреднения не будет.
Результаты
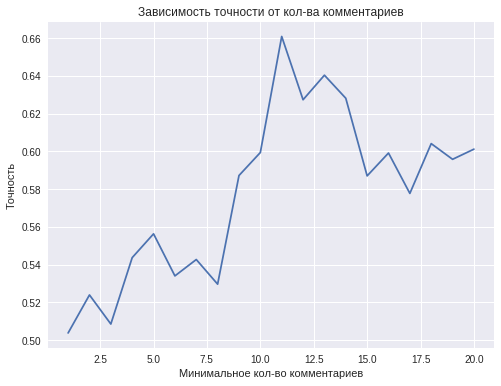
Качество финальной модели зависит от минимального количества комментариев, которое будет использоваться для классификации одного пользователя. В теории, чем больше комментариев, тем лучше.
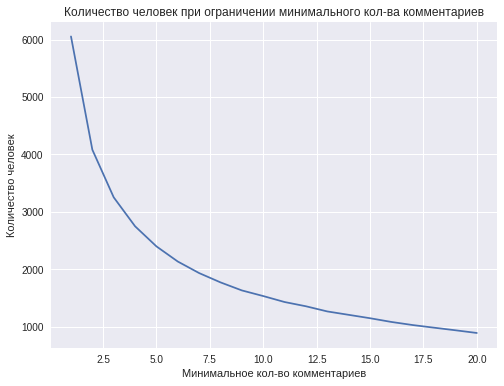
Однако при увеличении минимального количества комментариев от одного человека, уменьшается число человек, имеющих данное или большее кол-во комментариев, т.е. уменьшается размер обучающей выборки. Например, 2 и более комментария имеют примерно 4000 человек, а 10 и более комментариев – менее 1000. Этим объясняется снижение точности классификации при увеличении количества комментариев одного пользователя до 11-ти и больших значениях.
Наилучшая точность, равная 0.66, достигается при использование 11 комментариев от одного человека. Этого результата недостаточно, чтобы говорить об успешном решении поставленной задачи классификации, но все же эта точность превосходит качество предсказаний с помощью бросания монетки. В дальнейшем результаты можно улучшить путем сбора большего количества данных.
Наиболее важными для модели градиентного бустинга, не использующей непосредственно слова комментариев, оказались следующие признаки:
- средняя длина слова;
- количество слов;
- доля английских слов в комментарии;
- использование восклицательного знака.
С помощью библиотеки eli5 визуализируем предсказания линейной модели, работающей поверх представления текста в виде мешка слов:


На уровне символов:


Зеленым подсвечены слова и символы, которые вносят максимальный вклад в предсказанный класс, а красным которые вносят вклад в противоположный класс. y = 1 означает, что модель предсказывает класс гуманитарий, y = 0 — технарь.
Веб-сервис
Для демонстрации работы я развернул модель в качестве веб-сервиса. В качестве бэкенда был использован Flask, простой дизайн сделан с помощью Bootstrap, а для хостинга был взят Heroku. Попробовать на себе можно по адресу www.commentsanalysis.ru.
Важным ограничением стало время формирования одного предсказания. Из-за этого было решено оставить лишь 5 лучших линейных моделей для ансамбля.
На сайте четыре основных блока: краткая инструкция, поле со случайным комментарием, поле для ввода комментария пользователя и поле с результатом классификации. После того, как будет введено не менее 5 комментариев, результат может быть предсказан.
Теперь, когда система разработана и запущена, можно подумать об ее применении. Например, студентов-гуманитариев, учащихся на технических факультетах, можно автоматически переводить на более подходящие им факультеты.
Ссылка на GitHub.
P.S: огромное спасибо olferuk за правку текста.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru