Как мы переписали архитектуру Яндекс.Погоды и сделали глобальный прогноз на картах
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-11-30 10:55
Как говорится, по традиции раз в год мы в Яндекс.Погоде выкатываем что-нибудь новенькое. Сначала это был Метеум – традиционный прогноз погоды с помощью машинного обучения, затем наукастинг – краткосрочный прогноз осадков на основе метеорологических радаров и нейронных сетей. В этом посте я расскажу вам о том, как мы сделали глобальный прогноз погоды и построили на его основе красивые погодные карты.
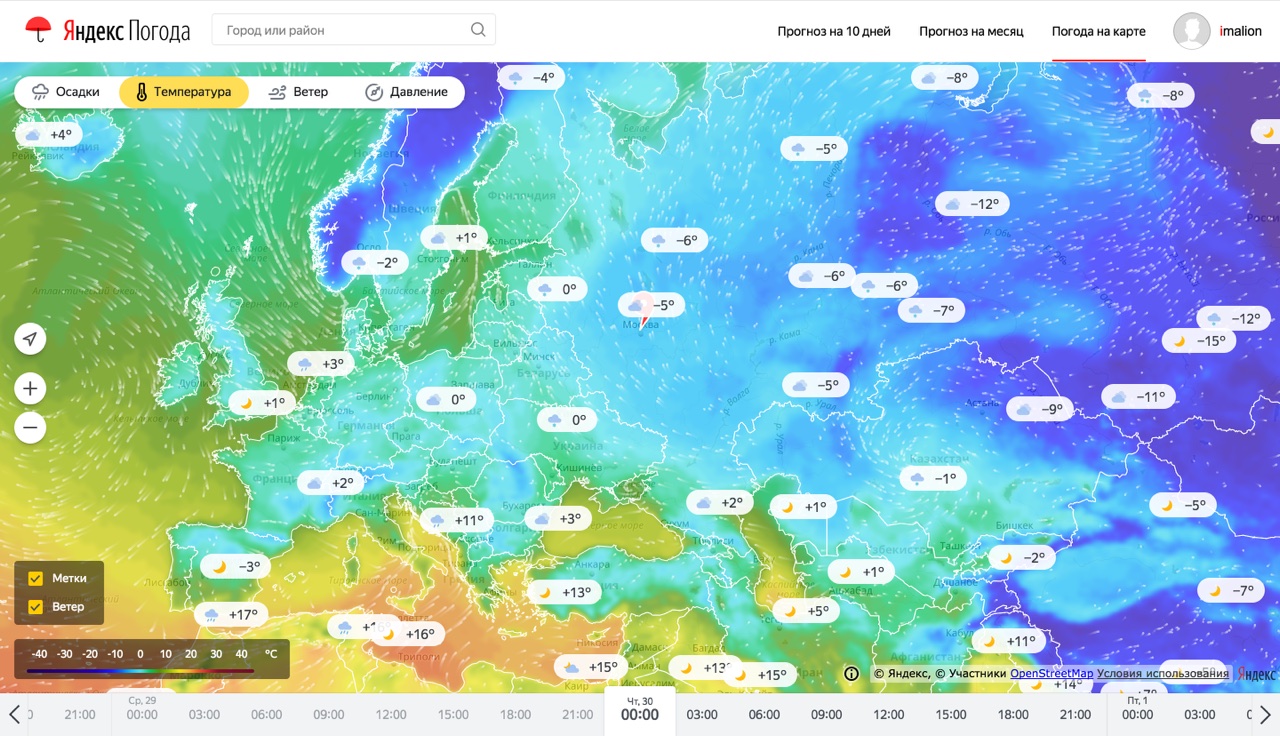
Сперва пару слов про продукт. Погодные карты — способ узнавать погоду, очень популярный на западе и пока что не очень популярный в России. Причиной тому является, собственно, сама погода. Из-за особенностей климата наиболее населенные регионы нашей страны не подвержены внезапным погодным катаклизмам (и это хорошо). Поэтому интерес к погоде у жителей этих регионов скорее бытовой. Так, людям в центральной России важно знать, например, какая погода будет в Москве в выходные или что в четверг в Питере будет дождь. Такую информацию проще всего узнать из таблицы, в которой будет дата, время и набор погодных параметров.
С другой стороны, жителям Восточного Побережья США важнее знать траекторию очередного урагана с красивым женским именем, а фермерам из Дакоты — следить за распространением града по полям, на которых растет кукуруза. Такую информацию гораздо проще узнавать из карты, чем из множества таблиц. Так и получилось, что погодные сервисы в России — это скорее таблицы, а на Западе — скорее карты. Однако, и в России существуют паттерны потребления погоды, когда пользователю нужно знать где именно будет погода, которая ему нужна: это люди, выбирающие место для пикника в выходные, спортсмены, особенно с приставкой "винд" и "кайт" и, наконец, дачники. Именно для этих категорий пользователей мы и сделали свой продукт. А теперь я расскажу о том, что у него под капотом.
Расчет прогноза: персональный и глобальный
Мы сразу решили, что для построения карт наш прогноз должен стать глобальным. Ну хотя бы потому, что карты, покрывающие не весь земной шар, отдают средневековьем. Таким образом, нам нужно было расширить Метеум до глобального покрытия. Однако, предыдущая архитектура системы плохо поддавалась горизонтальному масштабированию.
Краткое содержание предыдущих серий. Как помнит внимательный читатель, в первой реализации Метеума мы рассчитывали прогноз погоды по мере необходимости. Как только пользователь попадал к нам на сайт, мы собирали для его координат список факторов и передавали в обученную модель Матрикснета. За сбор факторов отвечал микросервис, который мы называли vector-api. Микросервис был хорош всем, кроме одного: при добавлении новых факторов и/или при расширении географии покрытия, мы приближались к лимиту памяти физических машин, на которых микросервис работал. Кроме того, само по себе формирование ответа итогового погодного API содержало дорогую по времени и по нагрузке на процессор операцию с применением модели Матрикснета. Оба фактора сильно препятствовали построению глобального прогноза. Плюс к тому, в нашем бэклоге образовалась целая очередь из факторов, которые увеличивали точность прогноза в экспериментах, но не могли поехать в продакшен в связи с ограничениями, описанными выше.
Также мы столкнулись с недостатками выбранной архитектуры для карты осадков, горячо полюбившейся многим пользователям. Для хранения и обработки данных, необходимых для построения информации об осадках, использовалась СУБД PostgreSQL с расширением PostGIS. Во время летних гроз количество запросов в тяжелые ручки в секунду молниеносно превращалось из сотен в десятки тысяч, что влекло за собой высокое потребление процессоров и сетевых каналов серверов баз данных. Эти обстоятельства послужили дополнительным стимулом задуматься о будущем сервиса и применить иной подход в обработке и хранении погодных данных.
Альтернативой расчету погоды в рантайме был предварительный расчет прогнозов для большого набора координат по мере обновления факторов. Мы остановились на глобальной сетке, покрывающей сушу с разрешением 2x2 км, а воду – с разрешением 10x10 км. Сетка разбита на квадратики 3 на 3 градуса – эти квадратики позволяют нам параллельно готовить факторы для модели и обрабатывать результаты. Вот как это выглядит на карте.
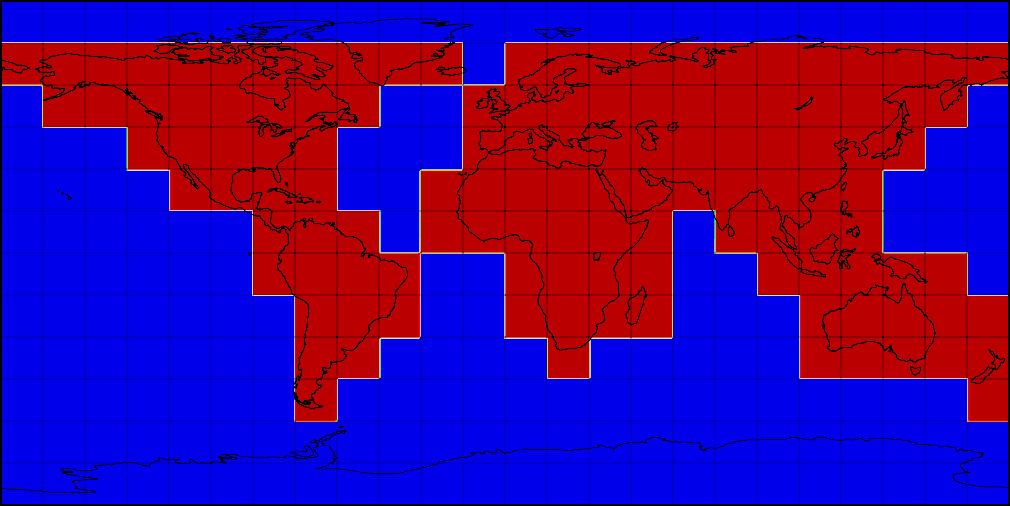
Разбиение областей глобальной регулярной сетки
Процесс подготовки погодных факторов начинается с кластера Meteo. В соответствии с названием, на этом кластере происходит «классическая метеорология». Здесь мы скачиваем данные наблюдений и прогнозы моделей GFS (США), ECMWF (Англия), JMA (Япония), CMC (Канада), EUMETSAT (Франция), Earth Networks (США) и многих других поставщиков. Здесь же происходит расчет погодной модели WRF для наиболее интересных для нас регионов. Метеорологические данные, полученные от партнеров или в результате расчетов, обычно запакованы в форматы GRIB или NetCDF с разными уровнями сжатия. В зависимости от поставщика или способа расчета, эти данные могут покрывать Московскую область или весь мир и весить от 200Мб до 7Гб.
Из метеокластера файлы с прогнозами погоды попадают сначала в MDS (Media Storage, хранилище для больших кусков бинарной информации), а потом в YT — нашу Яндексовую Map-Reduce систему. Работа в YT делится на два этапа, условно названные "подвоз" и "применение". Подвоз — это подготовка факторов для последующего применения обученной модели. Факторы надо корректно переинтерполировать на итоговую сетку, привести к единым единицам измерения и разрезать на квадратики 3 на 3 градуса для параллельной обработки и применения. Сложность процедуры здесь состоит в больших объемах данных и в необходимости проделывать упражнение каждый раз, когда пришли новые данные о прогнозе для какой-либо области.
После того как первая ступень отработала, начинается применение заранее обученных моделей машинного обучения. В первой реализации Метеума мы могли прогнозировать только два основных погодных параметра с помощью машинного обучения: это температура и наличие осадков. Теперь, когда мы перешли на новую схему расчетов, мы можем использовать тот же подход для вычисления остальных параметров погоды. Применение машинного обучения дает ощутимый прирост в точности для новых параметров: давления, скорости ветра и влажности. Ошибка прогнозирования этих параметров на 24 часа вперед падает на величину до 40%. Помимо того, что для многих пользователей важны максимально точные показатели ветра и давления, это улушение позволяет нам более точно рассчитывать еще один популярный параметр — температуру по ощущениям. Он складывается из обычной температуры, скорости ветра и влажности. Еще одним заметным новшеством стал новый способ расчета погодных явлений. Теперь в его основе лежит мультиклассификационная формула — она определяет не только наличие или отсутствие осадков, но также их тип (дождь, снег, град), а еще наличие и балльность облачности.
Все эти модели нужно применить за ограниченное время для каждой точки регулярной сетки. После того, как модели применились, есть еще один слой обработки данных — бизнес-логика. В этом разделе мы приводим переменные, спрогнозированные с помощью машинного обучения, к нужным нам единицам, а также делаем прогноз консистентным. Поскольку прямо сейчас модели ML достаточно мало знают о физике процессов, в основном опираясь на факторы, полученные из метеомоделей, мы можем получить неконсистентное состояние погоды, например "дождь при температуре -10". У нас есть идеи как делать более правильно в этом месте, однако прямо сейчас это решается формальными ограничениями.
Сложность при применении обученных моделей состоит в том, что для каждого прогноза надо выполнить порядка 14 миллиардов операций. Факторов, необходимых для каждого расчёта — сотни, и список этих факторов весьма подвижен: мы постоянно с ними экспериментируем, пробуем новые, добавляем целые группы, выкидываем слабые. Далеко не все факторы берутся напрямую от поставщиков. Мы экспериментируем с факторами-функциями нескольких параметров. Правила формирования такого количества фичей очень сложно поддерживать в виде кода на Python: громоздко, трудно делать ленивые вычисления, трудно анализировать и диагностировать, какие фичи (или исходные данные для фичей) уже не нужны. Поэтому мы изобрели свой аналог LISP. Строго говоря, это не LISP, а уже готовое AST, которое очень похоже на диалект LISP, в котором учтена специфика наших данных. Процессор этого LISP-а мы сделали таким, как нам надо: ленивым и кэширующим. Поэтому мы, во-первых, не вычисляем факторы, которые стали уже не нужны, во-вторых, не вычисляем дважды, то, что нужно дважды. Эти механизмы автоматически распространяются на все расчёты. А благодаря тому, что это формальное AST мы можем: легко анализировать что нужно, а что не нужно; сериализовать и хранить отдельно части логики, писать бизнес-части в логи, формировать большие части логики автоматически (минуя представление в виде кода), версионировать их для проведения экспериментов и так далее. Оверхед же получился совершенно незначительный, так как все операции выполняются сразу над матрицами.

Общая схема поставки данных в API
После расчета прогнозов мы записываем их в специальный формат – ForecastContainer и загружаем эти контейнеры в микросервис отдачи данных из памяти. Дело в том, что на весь мир с нашей сеткой в 0.02 градуса получается около 1 166 400 000 значений с плавающей точкой, а это 34Гб данных только на один параметр. Таких параметров у нас больше 50 – поэтому держать эти данные полностью в памяти одной физической машины не представлялось возможным. Мы начали искать формат, поддерживающий быстрое чтение сжатых данных. Первым кандидатом стал HDF5 – у которого есть функциональность чанкования данных и поддержки буфера распакованных чанков. Вторым кандидатом стал наш --самописный-- проприетарный формат – матрицы float'ов сжатые LZ4 и записанные в Flatbuffer. Результаты тестов показали, что открытие файла с данными для работы занимает в два раза меньше времении у Flatbuffers, чем у HDF5, как и чтение произвольной точки из кеша. В итоге сейчас данные для 50 переменных занимают 52.1Гб.
Так как требования к потреблению памяти и времени ответа были очень высоки еще с постановки задачи, старый микросервис написанный на Python мы решили переписать на C++. И это дало свои результаты: Время ответа сервиса в 99 квантиле упало со 100мс до 10мс.
Перевод сервиса на новую архитектуру бэкендов позволил нам отдавать прогнозы погоды нашим внутренним и внешним партнерам напрямую, минуя кэши и расчеты моделей в рантайме, дал возможность при срочной необходимости с легкостью масштабировать нагрузки с использованием облачных технологий Яндекса.
Итого, новая архитектура позволила нам уменьшить тайминги ответов, держать бОльшие нагрузки и избавиться от рассинхрона данных, отдаваемых разным партнерам. Данные Яндекс.Погоды представлены в большом количестве сервисов Яндекса и не только: главная страница Яндекса, плагин погоды в Яндекс.Браузере, погода на Рамблере и так далее. В результате все они получили возможность отдавать именно те значения, которые в этот момент видят пользователи основной страницы Яндекс.Погоды.
Ближе к людям: тайл-сервер и фронт
Для того, чтобы отрисовать прогнозы на наших новых картах, необходимо достаточно много дополнительной обработки. Сначала мы запускаем MapReduce операции на тех же данных, что отдаются микросервисом и API для формирования данных на весь мир на регулярной широтно-долготной сетке с разрешением в 0.02 градуса. На выходе для каждого параметра: температуры, давления, скорости и направления ветра, а также для каждого горизонта: времени прогноза в будущее или времени факта в прошлое мы получаем матрицы размером 9001*18000.
После этого мы строим проекцию Меркатора по этим данным и нарезаем их на тайлы в соответствии с требованиями API Яндекс.Карт. Здесь мы встречаемся с одной из самых больших сложностей в цепочке подготовки погодных карт: количеством тайлов, которые нужно оперативно обновлять при генерации каждого нового прогноза. Так каждый следующий уровень приближения карты (zoom) требует в 4 раза большего количества тайлов чем предыдущий. Несложно прикинуть, что для всех уровней приближения от 0 вплоть до 8 нужно подготовить
картинок. Всего для каждого из четырёх параметров мы показываем 25 горизонтов, из них прогнозов в будущее 12. Поэтому каждый час требуется обновить 1048560 картинок.По мере готовности картинок мы загружаем их во внутреннее хранилище файлов Яндекса с высокой параллельностью. Как только весь слой карты для всех зумов загрузился, мы подменяем значение индекса, по которому фронт понимает, куда идти за новыми тайлами. Таким образом достигается достаточно высокая скорость появления новых прогнозов на карте и консистентность данных в пределах времени прогноза.
Даже несмотря на серьезную подготовку на бэкенде, отрисовка и анимация погодных карт тоже представляет собой сложную задачу. Рассказать все в одной статье не получится, поэтому здесь мы сделали акцент на самой заметной фиче — отрисовке анимированных частиц, показывающих направление втера.
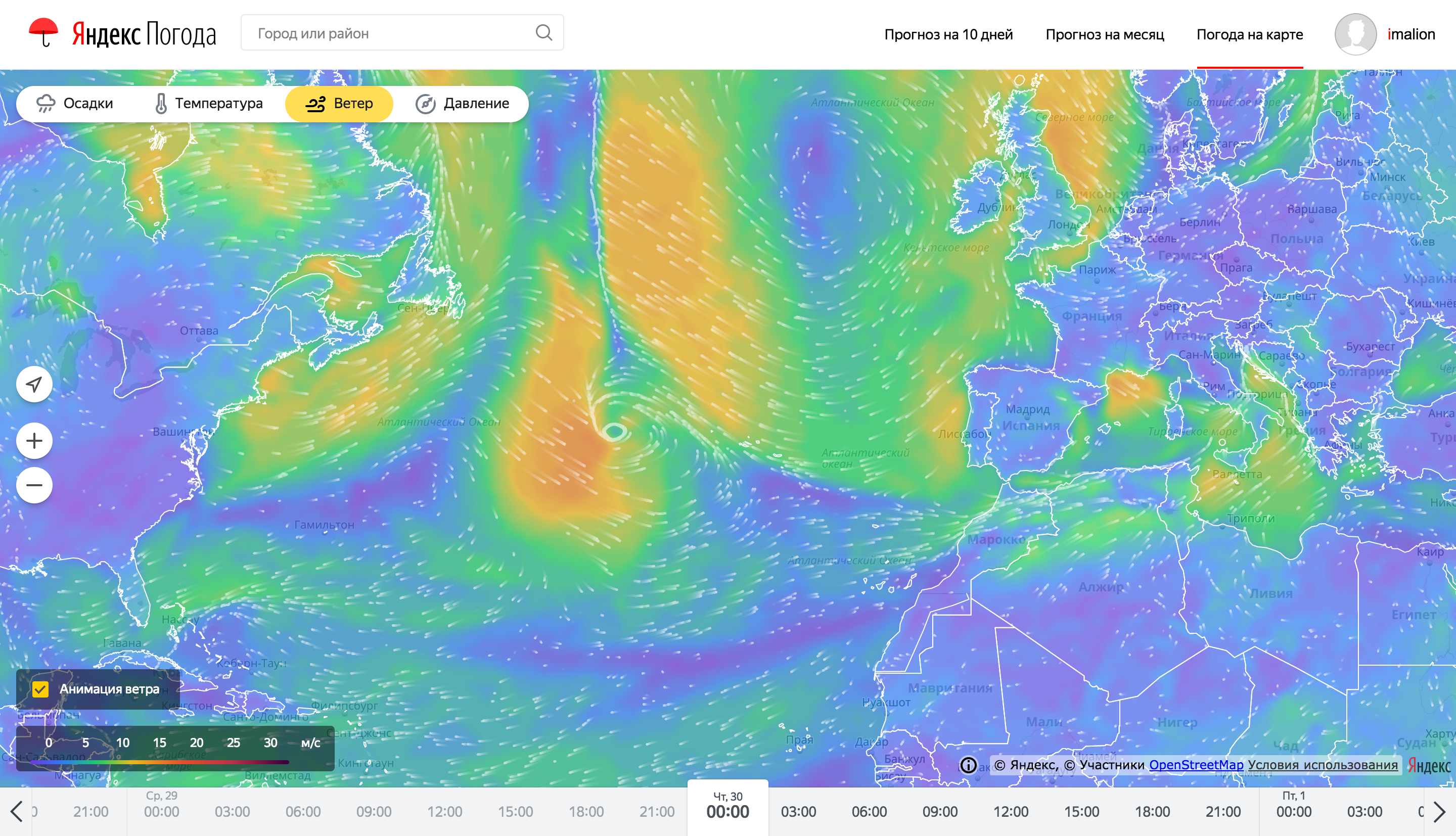
Так выглядят частицы анимации ветра на картах погоды
Для оптимизации потребления ресурсов клиентского устройства, анимация ветра выполнена с использованием WebGL. WebGL позволяет задействовать значительные ресурсы графического адаптера, разгружая процессорный поток выполнения кода, а также оптимизируя расход аккумулятора. Задачей процессора в этом случае становится установка аргументов выполнения шейдерных программ. Для перемещения частиц используется подход хранения положения частицы в 2х цветовых каналах текстуры для каждой оси (x/y). Таких текстур положения две: одна хранит текущее положение частиц, вторая предназначена для сохранения нового состояния.
Процесс отрисовки частиц описан несколькими WebGL программами. Для большей совместимости использована первая версия этого стандарта. В браузере использование WebGL выполняется через соответствующий контекст элемента canvas. Так как графический ускоритель способен выполнять в несколько раз больше параллельных операций через процессор, то перемещение частиц следует выполнять через программу WebGL. Выходной результат выполнения такой программы представляет набор точек в заданном пространстве. Это пространство по умолчанию является видимой областью своего canvas, то есть, экраном пользователя. Однако есть возможность указать целью отрисовки текстуру, используя фреймбуферы.
При старте слоя ветра процессор генерирует начальное положение частиц, создавая типизированный массив элементов в диапазоне 0...255, в количестве (частицы * компоненты) (RGBA). Из этого массива создаются две WebGL текстуры положения. Данные по скорости ветра также записываются в текстуру, чтобы видеокарта имела к ним доступ. Красный и зеленый канал этой текстуры содержат значение параллельной и меридиональной скоростей соответственно, причем значение 127 соответствует отсутствию ветра, значения меньше 127 задают скорость ветра в отрицательном направлении по оси, значения больше — в положительном. С помощью подготовленных текстур происходит отрисовка текущего положения частиц. После отрисовки, одна из текстур положения обновляется, используя вторую текстуру как источник данных по текущему состоянию. Следующие видимые кадры будут сформированы при помощи отрисовки предыдущего снимка положения частиц с увеличенной прозрачностью, поверх которого будет нанесено текущее положение частиц. Таким образом получаются частицы с затухающими хвостами.

Так выглядят частицы анимации ветра в процессе их создания
Как оказалось, текущий алгоритм кодирования положения частиц в пикселях текстуры для качественной визуализации требует поддержки на аппаратном уровне высокой точности вычислений и float-значений в самих текстурах, чего зачастую нет на мобильных устройствах, поэтому алгоритм будет переработан и улучшен.
Заключение и планы
Вот примерно все, что я хотел рассказать вам об архитектуре Яндекс.Погоды. За этот год мы полностью переделали сервис изнутри (об этом рассказано выше) и снаружи (практически все платформы, на которых присутствует Я.Погода были существенно перерисованы). Финалом этих изменений стали интерактивные погодные карты, которые вы можете попробовать на нашем сервисе.
Однако, мы никогда не останавливаемся на достигнутом. В следующем году вас ждет много интересных продуктовых и технологических апдейтов: от сервиса, позволяющего исследовать климат в разных уголках Земли до ответа на вопрос "чем дышит человек". И это, разумеется, далеко не все. Оставайтесь с нами.
Всегда ваша,
Команда Яндекс.Погоды
Телеграм: t.me/ainewsline
Источник: habrahabr.ru