Как мозг бьет дерево, или как мы сделали рекомендательную систему с помощью нейронной сети
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-11-12 13:49
архитектура нейронных сетей, реализация искусственного интеллекта
Как бы вы сделали рекомендательную систему? У многих в голове сразу появилась картина как они импортят и стакают XGBoost CatBoost. Изначально у нас в голове появилась та же картина, но мы решили на волне хайпа сделать это на нейронных сетях, благо времени было много. Опыт их создания, тестирование, результаты и наши мысли описаны далее.
Постановка задачи
Перед нами стояла задача создания модели, выбирающей людей, которым стоит отправить предложение воспользоваться какой-то услугой, предоставляемой компанией. Раньше этим занимался решающий лес. Мы же решили сделать это на “всесильных” нейронных сетях, заодно поняв, как они работают и действительно ли сложны. После изучения предметной области наше внимание остановилось на нескольких архитектурах.
Заинтересовавшие нас архитектуры
Далее, кликнув по названию чего-либо, можно будет попасть на статью, где оно хорошо поясняется.
- CNN
Архитектура, используемая в основном для обработки изображений.
Что это такое, и как работает можно прочесть здесь и здесь.
Мы решили поставить ее как отдельно, так и перед LSTM для сжатия данных и выделения зависимостей на транзакциях (которые были представлены в виде очень разреженных таблиц).
Сама по себе она работала хуже чем в паре с LSTM, про которую написано далее, но существенно ускорила обучение и улучшила качество.
Мы использовали сверточные сети с одномерным ядром conv 1D.
- LSTM
Это популярная архитектура рекуррентной нейронной сети, показавшая себя хорошо в задачах нахождения закономерностей на временных рядах, текстах и классификации, запоминая важные закономерности, забывая неактуальные.
Очень подробно и понятно про ее устройство написано тут.
Мы в своей задаче использовали 2 слоя LSTM, каждая имела 128 нейронов.
Оценивалась работа трех моделей в основе которых лежат описанные выше архитектуры.
- В данной статье приводится сравнение 3-х сетей, мы взяли ту, которая показывала лучший результат (FCN). Авторы утверждают, что данная архитектура является неплохим baseline для классификации временных рядов. Вкратце, она состоит из 3-х блоков, в каждом из которых сначала идет CNN->BN(batch normalization)->ReLU activation. После этого идет global average pooling.
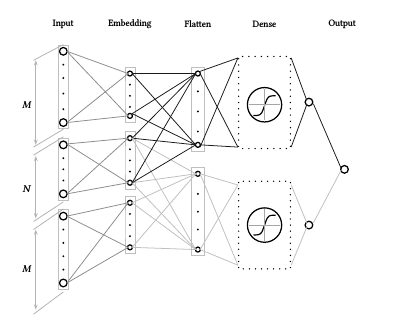
- Архитектура из этой статьи. Типичным подходом в NLP является представление слов в виде вектора (embending), но авторы попробовали кодировать буквы (методом one-hot encoding), получилось довольно неплохо. Мы решили нашу задачу похожим способом. Т.е. у нас слова – это категории, а текст – это история покупок юзера. Сама архитектура имеет следующий вид: (CNN->MaxPooling)x3 -> Flatten -> (Dense->Dropout)x2 -> Softmax.
- После прочтения различных блогов (например этот) пришла идея попробовать следующую архитектуру: Conv1D->Max Pooling->LSTMx2->(Dense->Dropout)x2->Softmax.
Факторизация
Представим себе матрицу, каждая строка — это пользователь, каждый столбец это предмет, который пользователь может оценить. Значения матрицы в позиции (i,j) это оценка i-го пользователя j-му предмету. Теперь с помощью математического аппарата мы представляем эту матрицу в виде произведения двух матриц (юзеры, фичи) (фичи, предметы). Где фичи это какие-то признаки, которые мы выделяем. Теперь скалярно перемножая строку-юзера на столбец-предмет получаем число, показывающее насколько нравится этому юзеру этот предмет.
Библиотеки для факторизации:
lightfm
libfm- Pairwise
- Коллаборативная фильтрация — это метод построения прогнозов, основанный на предположении, что если поведение или оценки чего-либо людей в прошлом были похожи, то они будут похожи и в будущем.
Она может быть основана как на внешнем (explicit) поведении пользователей, когда они сами ставят оценку чему-то (Netflix), так и на неявных (implicit) закономерностях, когда совпадает их поведение, в нашем случае у них похожие транзакционные последовательности.
Подход этой статьи основан на коллаборативной фильтрации и учитывает как явные, так и неявные закономерности. В основе архитектуры стоит нейронная сеть, которая изучает предпочтения пользователей по парам элементов учитывая представления этих предметов, построенные до этого и хранящиеся в строках матриц Us(user x feature), It(item x feature)
по аналогии с матричной факторизацией. При обучении сети для юзера выбирается 2 предмета, на которые он дал свои оценки и соответствующие строки матриц Us и It срезаются, соединяются и подают в сеть. Функция потерь состоит из двух частей: первая отвечает за потери на выходе самой нейронной сети, а вторая отвечает за то, что скалярное произведение векторов, которые подавались на обучение сети, тоже соответствует действительности. Например, мы говорим что item_1 лучше item_2, значит и нейронная сеть на выходе должна дать число больше нуля, и скалярное произведение соответствующих векторов должно быть положительным. Таким образом делается факторизация с помощью этой нейронной сети. Далее мы предполагаем что для каждого пользователя есть линейный порядок на итемах и на основе этого предположения ранжируем все итемы для конкретного пользователя.
Что делали мы? Мы сказали что категория_1 лучше чем категория_2, если пользователь платил по ней чаще и на основе этого предположения использовали эту архитектуру.
Немного о данных
QIWI предоставила нам датасет с историями покупок пользователей, а так же информацию о том, что пользователю рекомендовали купить, и последовал ли он рекомендации в течении 15 дней. Мы пытались по истории покупок предсказать товар, который он скорее всего купит. Нас интересовали только несколько категорий продуктов (всего таких 5). Таким образом, мы смогли мерить привычные всем True Positive, False Positive, True Negative, False Negative и все от них зависящее для интересующих нас категорий.
Также сложность доставляло то, что данные были сильно несбалансированы, почти весь объем транзакций лежал в категориях, которые нас не интересуют.
Ход работы
Здесь мы обсудим поведение моделей и качество на различных тестах.
Мы будем последовательно описывать как различные модели отработали на различных датасетах.
LSTM
В начале мы взяли небольшой объем данных, историю транзакций примерно 12к юзеров и пытались предсказать категорию следующей покупки. И вот как отработали вышеупомянутые архитектуры:
- Ниже привед график работы “голой” LSTM (LSTM->Softmax). В обучении было примерно 9 тысяч юзеров, на тесте — 3700.
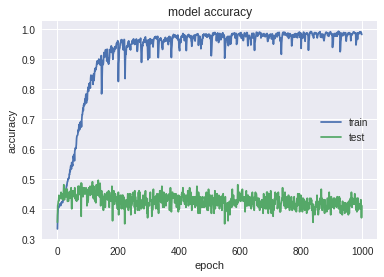
Как видим, она очень сильно переобучается. На тестовых данных получились следующие метрики качества: Accuracy: 0.447; MRR: 0.576. Но увидев, что скор довольно неплохой, подумали, что скорее всего наша модель предсказывает юзеру то, что он в основном покупал. Для этого мы проверили качество работы алгоритма на тех людях, предсказываемая категория которых не присутствует в истории их транзакций (далее special test). Таких людей оказалось не так много в тесте (примерно 500). На них получились следующие результаты: Accuracy: 0.037; MRR: 0.205. На таких людях скор получился заметно хуже.
Но мы не отчаялись, пробовали различные варианты с LSTM, в итоге пришли к такой архитектуре: Conv1D->Max Pooling->LSTM(with rec dropout)x2->(Dense->Dropout)x2->Softmax. Вот как она отработала:
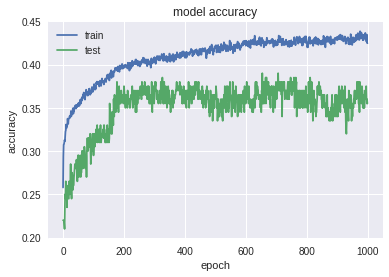
Картинка куда лучше. Сеть не так сильно переобучается. Смотрим на скор на тесте: Accuracy: 0.391; MRR: 0.534. Результат немного хуже чем при работе прошлой сети. Но не будем спешить с выводами и посмотрим на special test: Accuracy: 0.150; MRR: 0.312. Благодаря специальному тесту видим, что данная модель лучше находит закономерности в данных. Запомним данную архитектуру, она нам еще пригодится.
- Далее мы оценивали работу следующих 2-х архитектур, в основе которых лежит CNN.
На тех же данных, что и в предыдущем пункте запустили FCN и Char CNN (об их устройстве говорилось выше). Результаты обучения:
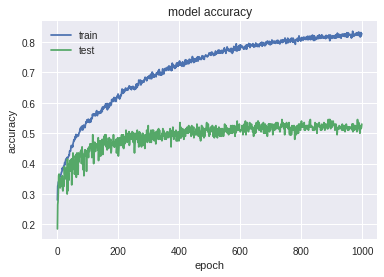
График свидетельствует о переобучении, но не таком сильном как при простой LSTM. На тесте получились такие результаты: Accuracy: 0.529 MRR: 0.668. На специальном тесте: Accuracy: 0.014; MRR: 0.217. Сразу же посмотрим на работу Char CNN, но на меньшем количестве эпох:
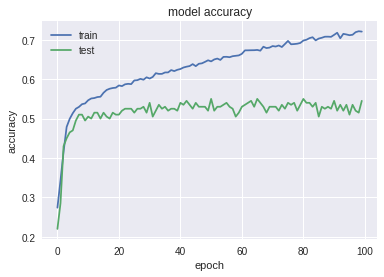
Тут сеть гораздо быстрее переобучается, на тесте дает неплохие результаты, но по специальном тесту видим, что она плохо выучила сложные закономерности:
Test: Accuracy: 0.543; MRR: 0.689;
Special test: Accuracy: 0.0098; MRR: 0.214.
Pairwise
Для начала, мы написали нашу модель согласно статье.
Сделали мы это на Pytorch. Это очень удобный фрэймворк, если вы хотите сделать не совсем обычную нейронную сеть. Недавно вышла статья с его описанием от mail.
В первую очередь мы добились примерно такого-же качества NDCG как авторы на датасете movielens.
После этого мы переделали ее под наши данные. Мы разделили данные на две “временные части”.
На вход нейронной сети мы подавали вектора в которых для каждого человека для каждой категории был процент его платежей в эту категорию от общего. Поэтому данные были довольно емкими, и училась она во много раз быстрее чем LSTM, около 30 минут на видеокарте, против нескольких часов LSTM.
Посмотрим на качество.
На 300 000 пользователей. Метрики померины для всех классов, а не только для тех, которые нас интересуют.
|NDCG@5: 0.46 | Accuracy@3: 0.62|
Эти показатели меняются от выборки (каких пользователей берем), изменения в пределах 7%.
Теперь большой датасет с несколькими миллионами пользователей.
Мы учимся на всех классах, а ранжируем только те, которые нас интересуют.
Ответ считается правильным, если мы предсказали класс в который пользователь потом заплатил.
Картина получается примерно такая:
| Класс 1 (маленький) | Класс 2 | Класс 3 | Класс 4 |
|---|---|---|---|
| почти его не предсказывает | класс больше, но его она все равно почти не предсказывает | Precision = 0.45 Recall = 0.9 | Precision = 0.27 Recall = 0.6 |
Факторизация (lightfm).
Ее мы использовали на 500.000 пользователей также как и в Pairwise, представляя для каждого пользователя для каждой категории процентом платежей в эту категорию.
Все видно из графиков обучения (снизу номер итерации).
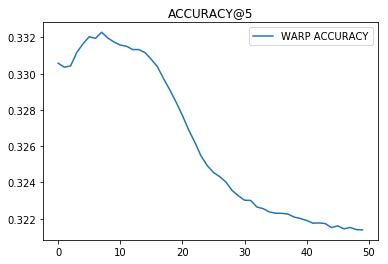

Из предыдущих пунктов можно сделать два вывода:
- Наша задача лучше решается классификацией чем ранжированием.
- Многоклассовый AUC специфичная вещь и нужно всегда смотреть как он считается.
Результаты
После дальнейших тестов, мы решили что CNN + LSTM работает лучше остальных.
Мы взяли большой датасет и посмотрели, как хорошо предсказываются нужные нам 5 классов.
На обучении было 5 млн. юзеров, на тесте — 1.4 млн. юзеров. В целях увеличения скорости обучения (а увеличивать ее было надо), мы не замеряли промежуточное качество классификации, поэтому графика обучения не будет :(.
Нас интересует конверсия (precision). Эта метрика показывает долю людей, которые купили товар данной категории, от общего количества людей, которым была выслана рекомендация данной категории. Понятно, что хорошие показатели этой метрики не означают, что сеть работает хорошо, так как она может рекомендовать очень мало, и достигать высокой конверсии. Давайте посмотрим на True Positive, False Positive, True Negative, False Negative, чтоб увидеть всю картину.
Ниже таблицы с 4 элементами значат следующее:
| True Negative | False Positive |
|---|---|
| False Negative | True Positive |
Num — количество людей, которые реально принадлежат данному классу
Класс 1:
| TN: 1440209 | FP: 1669 |
|---|---|
| FN: 3895 | TP: 1842 |
| precision | recall | f1-score | Num |
|---|---|---|---|
| 0.52 | 0.32 | 0.40 | 5737 |
Класс 2:
| TN: 1275939 | FP: 55822 |
|---|---|
| FN: 43994 | TP: 71860 |
| precision | recall | f1-score | Num |
|---|---|---|---|
| 0.56 | 0.62 | 0.59 | 115854 |
Класс 3:
| TN: 1136065 | FP: 108802 |
|---|---|
| FN: 91882 | TP: 110866 |
| precision | recall | f1-score | Num |
|---|---|---|---|
| 0.50 | 0.55 | 0.52 | 202748 |
Класс 4:
| TN: 1372454 | FP: 18812 |
|---|---|
| FN: 21889 | TP: 34460 |
| precision | recall | f1-score | Num |
|---|---|---|---|
| 0.65 | 0.61 | 0.63 | 56349 |
Класс 5:
| TN: 1371649 | FP: 18816 |
|---|---|
| FN: 22391 | TP: 34759 |
| precision | recall | f1-score | Num |
|---|---|---|---|
| 0.65 | 0.61 | 0.63 | 57150 |
Так как мы смотрим только 5 классов, то нам нужно еще добавить класс “другие”, и их, естественно, намного больше чем остальных.
Класс 6 (другие):
| TN: 18749 | FP: 327257 |
|---|---|
| FN: 2501 | TP: 1099108 |
| precision | recall | f1-score | Num |
|---|---|---|---|
| 0.77 | 1.00 | 0.87 | 1101609 |
Наша сеть очень хорошо предсказывает классы, в которые пользователь заплатит в ближайшие 15 дней, даже те, которые в несколько раз меньше других (например класс 1 в сравнение с 3-м классом).
Сравнение с предыдущим алгоритмом.
Сравнительные тесты на одинаковых данных показали, что наш алгоритм дает в несколько раз большую конверсию чем предыдущий алгоритм, основанный на решающих лесах.
Итог
Из нашей статьи можно сделать несколько выводов.
1) CNN и LSTM можно использовать для рекомендаций на основе временных рядов.
2) Для небольшого числа классов лучше решать задачу классификации, а не ранжирования.
Нейронные сети интересная тема, однако требует много времени и может преподнести неожиданные сюрпризы.
Например, наша первая модель Pairwise на PyTorch первую неделю работала плохо, потому что из-за обилия кода, где-то в функции ошибки мы обрывали распространение градиента.
Напоследок представимся.

Слева направо: Ахмедхан (@Ahan), Николай, Иван (@VProv). Иван и Ахмедхан студенты МФТИ и проходили стажировку, а Николай работает в QIWI.
Спасибо за внимание!
Телеграм: t.me/ainewsline
Источник: habrahabr.ru