10 уроков рекомендательной системы Quora
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-11-01 12:35
it новости, изучение социальных сетей, машинное обучение новости

Как директор по аналитике Retail Rocket, я периодически посещаю различные профильные мероприятия, и в сентябре 2016 года мне посчастливилось побывать на конференции RecSys, посвященной рекомендательным системам, в Бостоне. Было очень много интересных докладов, но мы решили сделать перевод одного из них Lessons Learned from Building Real-Life Recommender Systems. Он очень интересен с позиции того, как Machine Learning применять в production системах. Про сам ML написано множество статей: алгоритмы, практика применения, конкурсы Kaggle. Но вывод алгоритмов в production — это отдельная и большая работа. Скажу по секрету, разработка алгоритма занимает всего 10%-20% времени, а вывод его в бой все 80-90%. Здесь появляется множество ограничений: какие данные где обрабатывать (в онлайне или оффлайне), время обучения модели, время применения модели на серверах в онлайне и т.д. Критически важным аспектом также является выбор оффлайн/онлайн метрик и их корреляция. На этой же конференции мы делали похожий доклад Hypothesis Testing: How to Eliminate Ideas as Soon as Possible, но выбрали вышеупомянутый учебный доклад от Quora, т.к. он менее специфичный и его можно применять за пределами рекомендательных систем.
Справка о компании Quora:
Quora — социальный сервис обмена знаниями в форме вопросов и ответов, основанный в июне 2009 года Адамом д’Анджело и Чарли Чивером (одними из создателей социальной сети Facebook). На сегодняшний день сервис посещают более 450 миллионов человек ежемесячно.
Quora формирует персональную ленту вопросов и ответов, в соответствии с интересами пользователя. Вопросам и ответам можно ставить лайки и дизлайки, пользователи могут «фолловить» других пользователей, таким образом создается своеобразная социальная сеть вокруг различных знаний.
Ксавьер Аматриан (Xavier Amatriain) из Quora делится 10 важными уроками о рекомендательных системах, которые сформировал за много лет работы в индустрии рекомендательных систем.
Введение
Главная миссия Quora — делиться и развивать знания во всем мире. Поэтому нам важно понимать, что такое знания на самом деле. Мы используем механизм вопросов и ответов, чтобы увеличивать объем знаний, и это отличает нас от энциклопедического подхода Википедии, поэтому в нашем сервисе миллионы ответов и тысячи тем.Если спуститься на ступень ниже, можно выделить три главных вещи, о которых мы заботимся: релевантность (relevance), спрос (demand) и качество (quality).
- Релевантность. Это самое главная задача любой рекомендательной системы, очень важно чтобы каждая рекомендация соответствовала интересам конкретного пользователя.
- Спрос. Сколько людей хотят знать ответ на этот вопрос? Если каким-либо вопросом интересуется всего несколько человек, то, возможно, и не стоит тратить усилия на него.
- Качество. Но если речь о большом количестве пользователей, которым интересен определенный вопрос, то стоит обязательно позаботиться о качестве ответов в этом вопросе.
Большая часть информации на Quora текстовая, но больший интерес представляет не работа с текстами, а то, какие действия пользователи могут совершать на сайте.
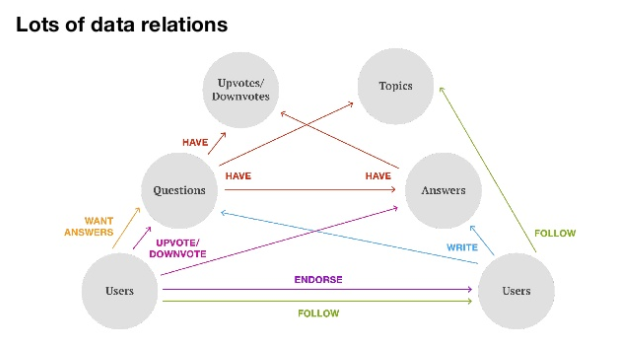 Эта диаграмма показывает разные типы взаимосвязей, которые существуют между разными типами контента, пользователями, их реакциями на контент и т.д.
Эта диаграмма показывает разные типы взаимосвязей, которые существуют между разными типами контента, пользователями, их реакциями на контент и т.д.Поскольку Quora — это своего рода социальная сеть, пользователи могут не только отвечать на вопросы, но и «фоловить» друг друга, а также ставить лайки (upvote) и дизлайки (downvote) вопросам и ответам. Темы (topics), связанные между собой, используются для классификации вопросов и ответов.
Все эти взаимодействия генерируют огромное количество данных, которые влияют на персональные рекомендации.
Среди рекомендаций, которые мы используем на сайте, можно выделить основные типы:
- Ранжирование элементов ленты на главной странице
- Ежедневная email рассылка
- Ранжирование ответов
- Рекомендации тем, потенциально интересных пользователю
- Рекомендации пользователей, ответы которых могут быть интересны
- Тренды
- Автоматическое определение тем вопросов
- Вопросы, связанные с просматриваемым вопросом
 Разные типы рекомендаций формируются совершенно разными алгоритмами на основе разных типов данных.
Разные типы рекомендаций формируются совершенно разными алгоритмами на основе разных типов данных. Поскольку мы решаем задачи, которые сильно отличаются друг от друга, нам приходится использовать множество различных алгоритмов машинного обучения:
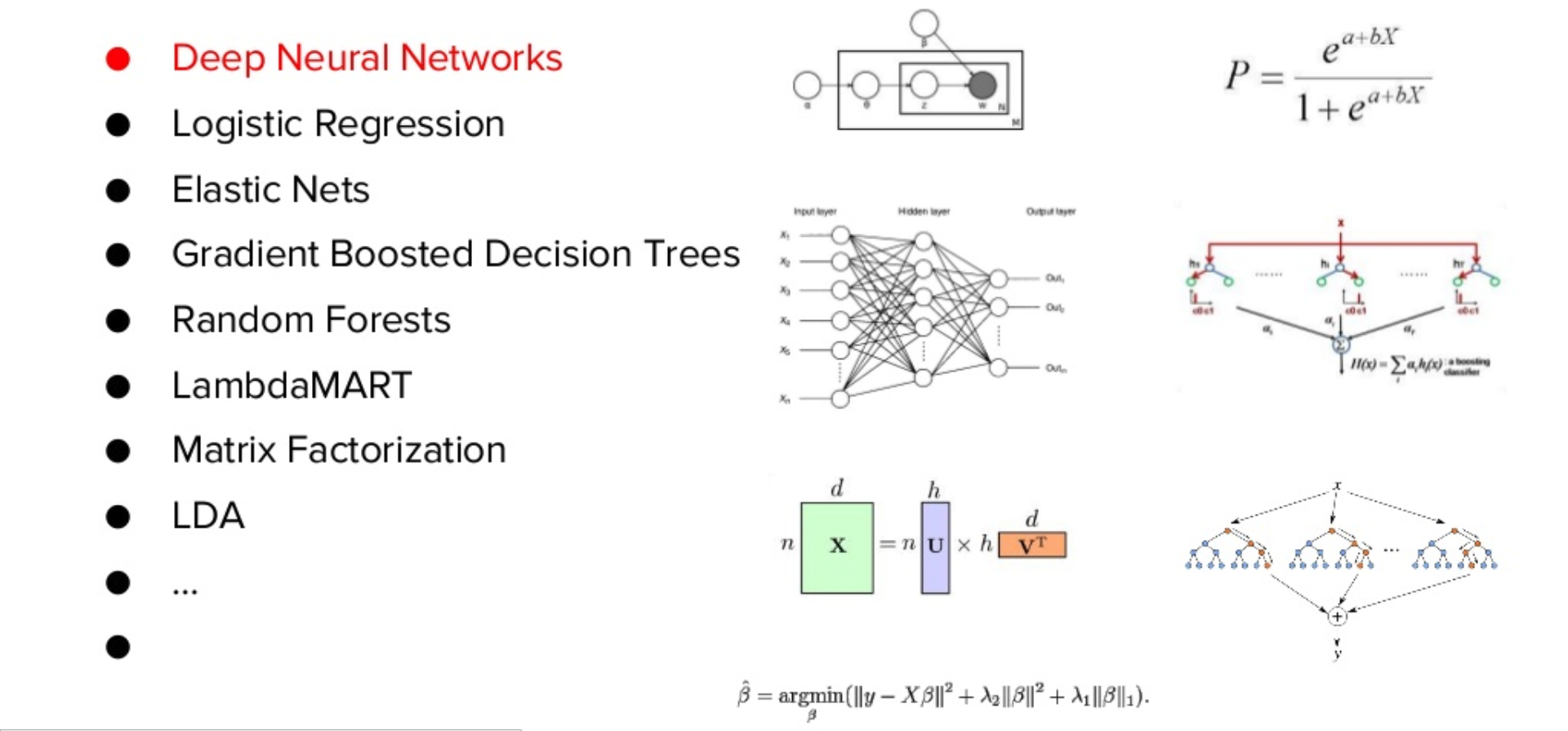
- Deep Neural Networks. Поскольку у нас очень много текстовых данных, с помощью глубоких нейронных сетей мы можем получать из этого текста различные признаки (feature)
- Logistic regression
- Elastic Nets
- Gradient Boosted Decision Trees
- Random Forests
- LambdaMART
- Matrix Factorization
- LDA
- и другие
Мы всегда ищем лучшие методы для решения каждой конкретной задачи, и делаем это не просто, чтобы следовать моде, а для получения максимальной эффективности.
Урок 1. Неявный отклик пользователей почти всегда лучше явного
Еще во время работы в Netflix мой любимый пост был о том, что пятибалльные рейтинги бесполезны, что подтверждает и Youtube. Но почему так происходит?Основная причина в том, что неявных данных (implicit data) гораздо больше они “плотнее”(dense), позволяют гораздо больше узнать о самих пользователях. Проблема явного отклика (explicit feedback) в том, что мы получаем его только от тех, кто согласился нам ее дать. Таким образом, явный отклик больше говорит о демонстративном публичном поведении, чем о реальной реакции пользователя. Поэтому для целевой функции больше подходит неявный отклик (implicit feedback). Он также лучше коррелирует с результатами АБ-тестов.
Но не во всех случаях неявный отклик лучше. Это можно хорошо проиллюстрировать с помощью примера, когда веселая картинка или громкий заголовок привлекают внимание, и пользователь непреднамеренно подходит курсор или даже кликает на подобный блок. Показатели активности в таком случае будут довольно высокими, можно получить много действий, но вряд ли такая тактика коррелирует с долгосрочными целями, поэтому важно уметь комбинировать неявные и явные отклики.
В Quora мы используем как неявные отклики, такие как посещения страниц, клики на вопросы, ответы и профили пользователей, так и различные явные сигналы: лайки, дизлайки, шаринг и т.д. Чтобы подготовить качественные данные для тренировки модели, необходимо научиться комбинировать явные и неявные отклики.
Урок 2. Будьте внимательны к данным, на которых учится ваша система
Второй урок относится к тому, как вы готовите ваши данные, как они поступают в вашу рекомендательную систему и как алгоритм рекомендательной системы будет учиться на них.Даже для тривиальной задачи бинарной классификации бывает не всегда очевидно, какой отклик считать положительным, а какой отрицательным.
В случае с Quora можно найти массу примеров, где очень сложно понять, что является положительным, а что отрицательным ответом. Например, что делать с забавными, но бессмысленными ответами, у которых много лайков? Или что сказать о коротком, но информативном ответе известного эксперта? Стоит ли считать его положительным? Или как расценивать очень длинный информативный ответ, который пользователи не читают и которому не ставят лайки? Таких примеров может быть очень много.
Если говорить о Netflix, то как расценивать фильм, который пользователь посмотрел пять минут и остановился? На первый взгляд, это говорит о том, что фильм не слишком интересный, но что если пользователь просто поставил его на паузу, чтобы досмотреть завтра?
Таким образом, есть множество скрытых поведенческих факторов, которые нужно научится понимать, оценивать и учитывать в обучении рекомендательной системы.
Представьте, что у вас есть более сложная задача — ранжирование, где вы должны проставить разные метки. В этом случае очень много времени тратится на подготовку данных для обучения, но еще больше времени может быть потрачено на разделение положительных и отрицательных примеров. Это может быть довольно сложным и трудоемким процессом, но критически важно для решения задачи.
Урок 3. Ваша система может научиться только тому, чему вы ее учите
Третий урок связан с обучением модели. Кроме данных для обучения модели, важны еще две вещи: ваша целевая функция (например, вероятность прочтения пользователем ответа) и метрика (например, precision или recall). Они образуют то, на чем будет обучаться ваша модель.Например, нам нужно оптимизировать вероятность просмотра в кинотеатре фильма и его высокой оценки пользователем, используя историю предыдущих просмотров и рейтингов, то стоит попробовать NDCG-метрику как финальную, считая положительным результатом фильмы с рейтингом 4 и выше. Это довольно долгий способ, но он приносит действительно хорошие результаты.
После того, как вы определили эти три пункта, можно начинать работу, но учтите, что есть много деталей и подводных камней. Если вы забудете определить хотя бы один из этих аспектов, велик риск, что вы неправильно поставите задачу и будете оптимизировать что-то не связанное с вашей реальной целью.
Что мы делаем в Quora:
- Данные для обучения модели — неявные и явные отклики, которые собираются на сайте
- Целевая функция — это ценность показа вопроса/ответа пользователю и взвешенная сумма всех действий пользователя, которые они (вопросы/ответы) получат. Она должна коррелировать с долгосрочными целями компании. Соответственно, вам нужно решить регрессионную задачу, т.е. соотнести действия пользователя с целевой функцией
- Метрика. Поскольку речь идет о работе с лентой рекомендаций вопросов и ответов, а она представляет из себя просто список элементов, нужно выбрать соответствующую метрику ранжирования, например NDCG, которая будет иметь смысл для решения именно этой задачи.

Урок 4. Объяснения могут быть не менее важны, чем сами рекомендации
Четвертый урок о важности объяснения тех или иных рекомендаций и их влиянии на восприятие. Объяснения дают возможность понять, почему то, что вам рекомендуется, будет вам интересно. Например, Netflix рекомендует фильмы на основе предыдущих просмотров. В случае с Quora пользователям рекомендуются темы, похожие вопросы, люди, которых можно «фолловить», а объяснения помогают понять, почему это будет интересно.
Урок 5. Если нужно выбрать только один алгоритм, делайте ставку на матричную факторизацию
Если вы можете использовать только один алгоритм, то я бы поставил на матричную факторизацию. Я часто получаю вопросы о том, что делать если у стартапа есть только один инженер и нужно построить рекомендательную систему. Мой ответ — матричная факторизация. Главная причина в том, что несмотря на то, что ее можно комбинировать с другими алгоритмами, она дает хороший результат сама по себе. Факторизация в некотором смысле является обучением без учителя, потому что она просто уменьшает размерность, как это делает метод PCA. Но она может использоваться и для задач обучения с учителем. Например, вы можете уменьшить размерность, а затем решить задачу регрессии относительно ваших размеченных данных.
Факторизация в некотором смысле является обучением без учителя, потому что она просто уменьшает размерность, как это делает метод PCA. Но она может использоваться и для задач обучения с учителем. Например, вы можете уменьшить размерность, а затем решить задачу регрессии относительно ваших размеченных данных. Матричная факторизация подходит под разные типы данных, и для разных типов данных можно использовать их различные реализации. Для неявных сигналов (implicit signals) можно использовать ALS или BPR, можно перейти к тензорной факторизации или даже к факторизационным машинам (factorization machines).
Мы в Quora написали свою библиотеку, которую назвали QMF. Это маленькая библиотека, которая реализует основные методы матричной факторизации. Она написана на C++ и может быть легко использована в продакшн.
Урок 6. Все есть ансамбль
Самое интересное лежит в ансамбле алгоритмов. Предположим, что вы начали с факторизации матриц и наняли второго инженера. Ему становится скучно, и это отличный момент, чтобы попробовать другой метод обучения, а потом объединить их в ансамбль.На открытом соревновании Netflix Prize победившая команда использовала ансамбль в качестве последнего шага модели. Команда Bellcor использовала GBDT (Gradient boosted decision trees), чтобы создать ансамбль, а когда объединились с командой BigChaos, использовали нейронные сети как последний слой ансамбля, и таким образом подошли к некоему подобию глубинного обучения (deep learning).
Если у вас есть разные модели, которые делают разные трансформации на разных слоях, вы получаете неограниченные возможности работы с нейронной сетью. Это выглядит почти как самодельная глубинная нейронная сеть. При этом мы не говорим о глубинном обучении в классическом понимании.
Благодаря ансамблям можно объединять различные алгоритмы, используя разные модели, такие как логическая регрессия, или нелинейные методы Random Forest, или даже нейронные сети.
Еще одна интересная вещь заключается в том, что любую модель, входящую в ансамбль, вы превращаете в фичу (feature). Таким образом мы стираем границу между фичами и моделями. Интересно, что вы можете разделить их производство на разных инженеров, а потом их объединить — это приводит к хорошей масштабируемости, а также возможности использования в других моделях.
Урок 7. Для построения рекомендательных систем также важно уметь правильно строить фичи
Чтобы получить оптимальные результаты, необходимо понимать данные (domain knowledge), а именно, что за ними стоит. Если вы не понимаете вашу миссию, а просто берете какую-то матрицу фич, которые вам интересны, какие-то данные, подкручиваете их, оптимизируете целевую функцию для матрицы, то этим вы можете оптимизировать не то, что действительно нужно.В Quora нам необходимо ранжировать ответы и показывать пользователям самые лучшие из них. Но как выбрать «лучшие», чтобы создать правильную систему ранжирования? Оценивая различные аспекты, мы вывели, что хороший ответ должен быть правдивым, информативным (т.е. давать объяснение), полезным длительное время, хорошо отформатированным и т.д.
Довольно сложно заставить нейронную сеть понимать, что такое хороший ответ. Для этого вы должны научиться интерпретировать данные и построить фичи, которые будут связаны с теми аспектами, которые важны, чтобы оптимизировать модель именно под ваши задачи.
В нашем случае нужно иметь фичи, которые связаны с качеством текста, его форматированием, реакцией пользователей и т.д. Некоторые из них сделать легко, другие довольно сложно, для некоторых может понадобиться отдельная модель ML.
Я бы дал выразил свойства хорошей фичи как полезная, «многоразовая», трансформируемая, интерпретируемая и надежная.

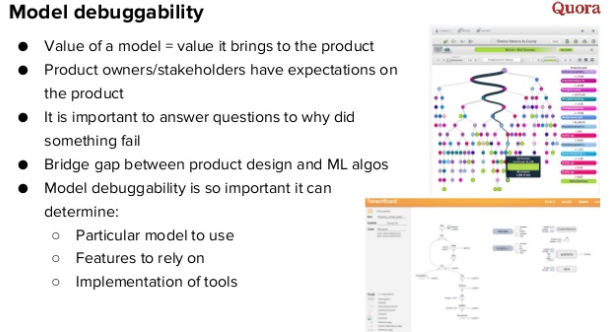
Урок 8. Почему важно уметь отвечать на вопросы
Ценность модели заключается не в ее точности и правильности, а в том, что она привносит в продукт и насколько удовлетворяет ожиданиям менеджеров продукта. Если ваш алгоритм будет расходится с их пониманием, вам необходимо будет отвечать на вопросы, почему здесь рекомендации именно такие. Очень важно иметь возможность отладки модели рекомендаций, а еще лучше визуальную систему отладки.Это позволяет намного быстрее проверять модель, чем если бы она была полностью черным ящиком — в таком случае найти причину плохих рекомендаций практически невозможно.
Например, у любого вопроса/ответа из ленты на Quora мы можем получить все фичи, проанализировать их и понять, почему модель порекомендовала тот или иной вопрос или ответ каждому пользователю.
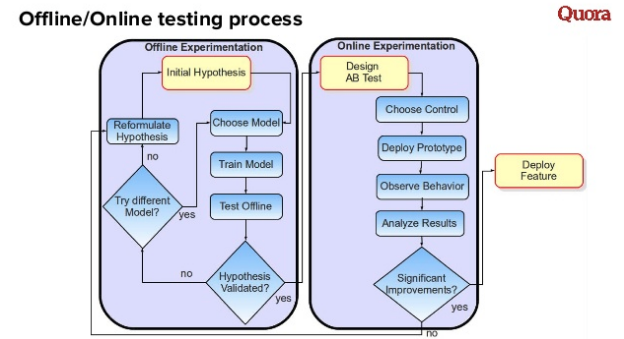
Урок 9. Данные и модель это хорошо, но еще лучше правильный подход к оценке эффективности
Когда мы получили данные и модель, встает следующий вопрос — правильная методика оценки эффективности.Это диаграмма, которая объясняет некий идеальный инновационный процесс при внедрении алгоритмов в рекомендательные системы. Основная идея заключается в том, что существует два процесса.
Первый — это эксперименты в оффлайне, то есть процесс тестирования и тренировки модели. Если модель работает лучше по выбранной метрике, мы считаем ее хорошей и можем запускать второй процесс — онлайн АБ-тестирования. Итог АБ-теста отрицательный? Первый процесс запускается по новой.
Таким образом возникает итеративный процесс, который сделает вашу работу быстрее и лучше.
 При оценке результатов тестов решения должны быть основаны на данных. Зачастую это проще сказать, чем сделать, это должно быть элементом культуры вашей компании.
При оценке результатов тестов решения должны быть основаны на данных. Зачастую это проще сказать, чем сделать, это должно быть элементом культуры вашей компании. Необходимо выбрать общую главную метрику, например, такую как удержание пользователей или другие долгосрочные показатели.
Основная проблема заключается в том, что долгосрочные метрики сложно измерять, поэтому иногда нужно использовать более краткосрочные метрики. Главное, чтобы они коррелировали с вашей главной метрикой!
В оффлайн тестировании, как правило используются стандартные метрики, чтобы измерить, насколько хорошо работает ваша модель. Но критически важно найти способ, чтобы эти метрики коррелировались с онлайн-результатами.
Урок 10. Не нужно использовать распределенную систему для рекомендательной системы
Последний совет будет достаточно противоречивым — вам не нужно использовать распределенную систему для построения рекомендательной системы. Многие идут по простому пути, но исходя из моего опыта работы с данными в различных компаниях, большинство задач можно свободно решить на одной машине. Все можно посчитать на одной машине вместо кластера, если соблюдать определенные требования:
Все можно посчитать на одной машине вместо кластера, если соблюдать определенные требования:- сэмплирование данных
- оффлайн вычисления
- эффективный параллельный код
Если вы не заботитесь относительно затрат, задержек, скорости, возможности отладки и т.д., то вы можете продолжать делать это на распределенном кластере. Можно просто попросить 200 серверов, развернуть на них свой spark-кластер и строить рекомендательную систему. Quora как стартап всегда думает о снижении затрат, потому что за все нам приходится платить самим. Также мы постоянно думаем о том, насколько сложные вещи мы создаем, и насколько легко будет осуществлять отладку.
Если говорить об алгоритме матричной факторизации, первое, что важно понять, что не обязательно нужны абсолютно все факторы — очень часто можно получить хорошую точность с помощью правильного сэмплирования, результат будет как если бы мы работали с полным объемом данных. Во-вторых, множество вещей можно сделать в оффлайне. Например, пользовательские факторы вы можете посчитать в онлайне, а факторы товаров в оффлайне.
Полное выступление можно посмотреть по ссылке.
Retail Rocket
Если вы хотите применить эти уроки, то милости просим к нам. Ищем инженера в нашу аналитическую команду Retail Rocket. Мы занимается разработкой рекомендательных алгоритмов на вычислительном кластере Spark/Hadoop (30+ серверов, 2 Петабайта данных). Результаты работы нашей команды можно увидеть на сотнях сайтов электронной коммерции в России и за рубежом. Наш технологический стек: Hadoop, Spark, Mongodb, Redis, Kafka. Основной язык программирования — Scala. У нас уже есть процессы проверки гипотез (новых алгоритмов) как в оффлайне, так и в онлайне (АБ-тесты), и мы постоянно в поиске того, как улучшить наши рекомендации. С этой целью изучаем научные статьи ведущих исследователей и проверяем их на практике. Ссылка на вакансию (ANALYTICS ENGINEER)Телеграм: t.me/ainewsline
Источник: habrahabr.ru