Выявление скрытых зависимостей в данных для повышения качества прогноза в машинном обучении
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-10-04 09:51

План статьи
- Постановка задачи.
- Формальное описание задачи.
- Примеры задач.
- Несколько примеров на синтетических данных со скрытыми линейными зависимостями.
- Какие ещё скрытые зависимости могут содержаться в данных.
- Автоматизация поиска зависимостей.
- Число признаков меньше пороговой величины.
- Число признаков превышает пороговую величину.
Постановка задачи
Нередко в машинном обучении встречаются ситуации, когда данные собираются априори, и лишь затем возникает необходимость разделить некоторую выборку по известным классам. Как следствие часто может возникнуть ситуация, когда имеющийся набор признаков плохо подходит для эффективной классификации. По крайней мере, при первом приближении.В такой ситуации можно строить композиции слабо работающих по отдельности методов, а можно начать с обогащения данных путём выявления скрытых зависимостей между признаками. И затем строить на основе найденных зависимостей новые наборы признаков, некоторые из которых могут потенциально дать существенный прирост качества классификации.
Формальное описание задачи
Перед нами ставится задача классификации L объектов, заданных n вещественными числами. Мы будем рассматривать простой двухклассовый случай, когда метки классов — это ?1 и +1. Наша цель — построить линейный классификатор, то есть такую функцию, которая возвращает ?1 или + 1. При этом набор признаковых описаний таков, что для объектов противоположных классов, измеренных на данном множестве признаков, практически не работает гипотеза компактности, а разделяющая гиперплоскость строится крайне неэффективно.Иными словами, всё выглядит так, будто задача классификации на данном множестве объектов не может быть решена эффективно.
Итак, мы имеем столбец ответов, содержащий числа -1 или 1, и соответствующую ему матрицу значений признаков X1…Xn, состоящую из L строк и n столбцов.
Мы ставим перед собой подзадачу найти такие зависимости F(Xi,Xj), которые бы могли выступить в роли новых признаков для классифицируемых объектов и помочь нам построить оптимальный классификатор.
Примеры задач
Давайте рассмотрим нашу задачу по нахождению функций F(Xi,Xj) на примерах. Разумеется, весьма жизненных.Примеры будут связаны с лепреконами. Лепреконы, если кто не в курсе, существуют где-то рядом с нами, хоть их практически никто и не видел. И у них, как и у людей, есть свои компьютеры, интернет и соцсети. Большую часть времени они посвящают поискам золота и складированию его в свои мешки. Однако же помимо честных лепреконов попадаются и такие, которые пытаются отлынить от этой важной работы. Их называют лепреконами-диссидентами. И именно из-за них скорость прироста объёмов золота у лепреконов никак не может достигнуть нужной величины!
Так как в мире лепреконов так же есть машинное обучение, их научились находить исходя из их поведения в крупных соцсетях. Но есть проблема! Каждый год появляется много молодых соцсетей, пытающихся захватить рынок, но ещё не умеющих собирать достаточно данных о своих пользователях для анализа! А тех данных, что они собирают, ну никак не достаточно, чтобы отличить порядочного лепрекона от лепрекона-диссидента! И тут то мы и сталкиваемся с необходимостью искать скрытые зависимости в имеющихся признаковых описаниях, чтобы на основе недостаточных на первый взгляд данных суметь построить оптимальный классификатор.
Однако пример с соцсетями будет вероятно чересчур сложным для разбора, так что давайте попробуем решить подобную задачу на примере ядерных процессоров лепреконов. Они характеризуются 4мя основными признаками:
a) Скорость вращения реактора (млн об/сек)
b) Вычислительная мощность (трл вычислений/сек)
c) Скорость вращения реактора под нагрузкой (млн об/сек) и
d) Вычислительная мощность под нагрузкой (трл вычислений/сек)
Ядерные процессоры производят 2 основные фирмы: 0 и 1 (‘Black Zero’ и ‘The First’). При этом у Black Zero цены вдвое ниже, но и ресурс также ниже впятеро! Однако главный гос. поставщик ядерных процессоров постоянно пытается обмануть заказчика и вместо оплаченных машин фирмы The First поставить более дешёвые и ненадёжные машины фирмы Black Zero. При этом разброс рабочих параметров реакторов настолько велик, что по основным характеристикам отличить одни от других для большинства измерений невозможно. В таблице 1 приведены характеристики 50ти случайно выбранных машин для каждой из фирм:
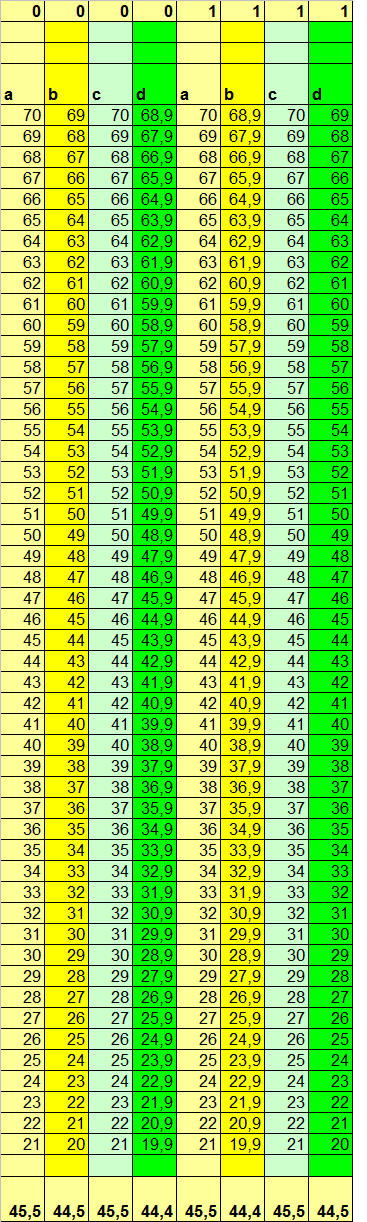
Таблица 1
Для удобства сравнения объекты классов 1 и 0 расположены не вертикально, а сбоку друг относительно друга. В приведённом примере видно, что в целом параметры вычислительной мощности зависят от оборотов реактора, причём, для машин разных производителей зависят несколько по-разному: для машин Black Zero в сравнении с машинами The First число вычислений выше при нормальных условиях для схожих оборотов реактора, но ниже под нагрузкой. Конечно, это потому, что машины фирмы The First без нагрузки входят в режим экономии плазмы, следствием чего является небольшое снижение производительности. Зато под нагрузкой они явно опережают конкурента.
Вот только мы видим эту зависимость, потому что данные специально так подобраны, чтобы эта зависимость была видна. В реальности же среди многих тысяч измерений и десятков (если не сотен) признаков, которые не могут быть так красиво отсортированы, как в этом придуманном примере, увидеть глазами такого рода зависимости обычно просто невозможно. А если ещё и не до конца ясна вся бизнес-специфика каждого признака, то пытаться найти глазами такие закономерности – занятие как минимум низкоэффективное.
Поэтому то, двигаясь в рамках парадигмы автоматизации обучения алгоритма, нам бы хотелось по максимуму исключить из процесса нахождения зависимостей между признаками человеческий фактор. Давайте рассмотрим несколько вариантов скрытых зависимостей и подумаем, как лучше всего организовать процесс их обнаружения.
Несколько примеров на синтетических данных со скрытыми линейными зависимостями
Вариант зависимости 1. Xj = K*Xi + C, K = 1
Первый вариант зависимости говорит: j-тый признак объекта линейно зависим от i-того признака, а также от свободного члена, представленного константой.В нашем узком примере коэффициент пропорциональности будет равен единице, чтобы лучше можно было увидеть вклад свободного члена.
Пусть b = a — 1, d = c – 1.1 для класса 0 и наоборот для класса 1 (b = a – 1.1, d = c – 1)
В данном случае, конечно же, очевидно, что новый столбец со значениями
(d – b)
даст для объектов 0-го и 1-го классов соответственно значения
(c – 1.1) – (a – 1) = c – a – 0.1
и
(c – 1) – (a – 1.1) = c – a + 0.1
соответственно. А это, в свою очередь, при однородности данных в колонках A и C (а это одно из условий в нашей задаче), даёт нам неплохой инструмент для разделения объектов. И мы как минимум можем рассчитывать на позитивный вклад данного нового столбца в итоговую классификацию.
Результат подобного вычисления на наших придуманных данных вы можете посмотреть в таблице 2:
 Таблица 2
Таблица 2Подобная ситуация, несмотря на кажущуюся надуманность, в действительности имеет место быть в жизни. Примером может служить необходимость для реализации некоего условия выполнить ряд регламентированных действий, имеющих константный набор сайд-эффектов. В случае с ядерными процессорами в нашем примере константная деградация вычислительной мощности может быть связана с необходимостью запуска фиксированного процесса для выхода на работу под нагрузкой. В жизни – запуск дополнительного генератора, фиксированное выделение ресурсов в резерв, энергия для запуска ДВС или промышленного генератора на ТЭС и т.д.
Однако выбор именно данной функции F(d, b) в реальной задаче конечно же не будет очевидным. Поэтому давайте рассмотрим для начала, к каким результатам приведёт нас иной выбор F(Xi, Xj)
F(Xi, Xj) = Xi/XjГоворя в терминах признаков нашей задачи, здесь мы можем попытаться измерить например деградацию вычислительной мощности под нагрузкой (B/D). Причём, исходя из предположения, что такая деградация не зависит от константы, а является полностью относительной величиной.
Давайте посмотрим, что получится в результате.
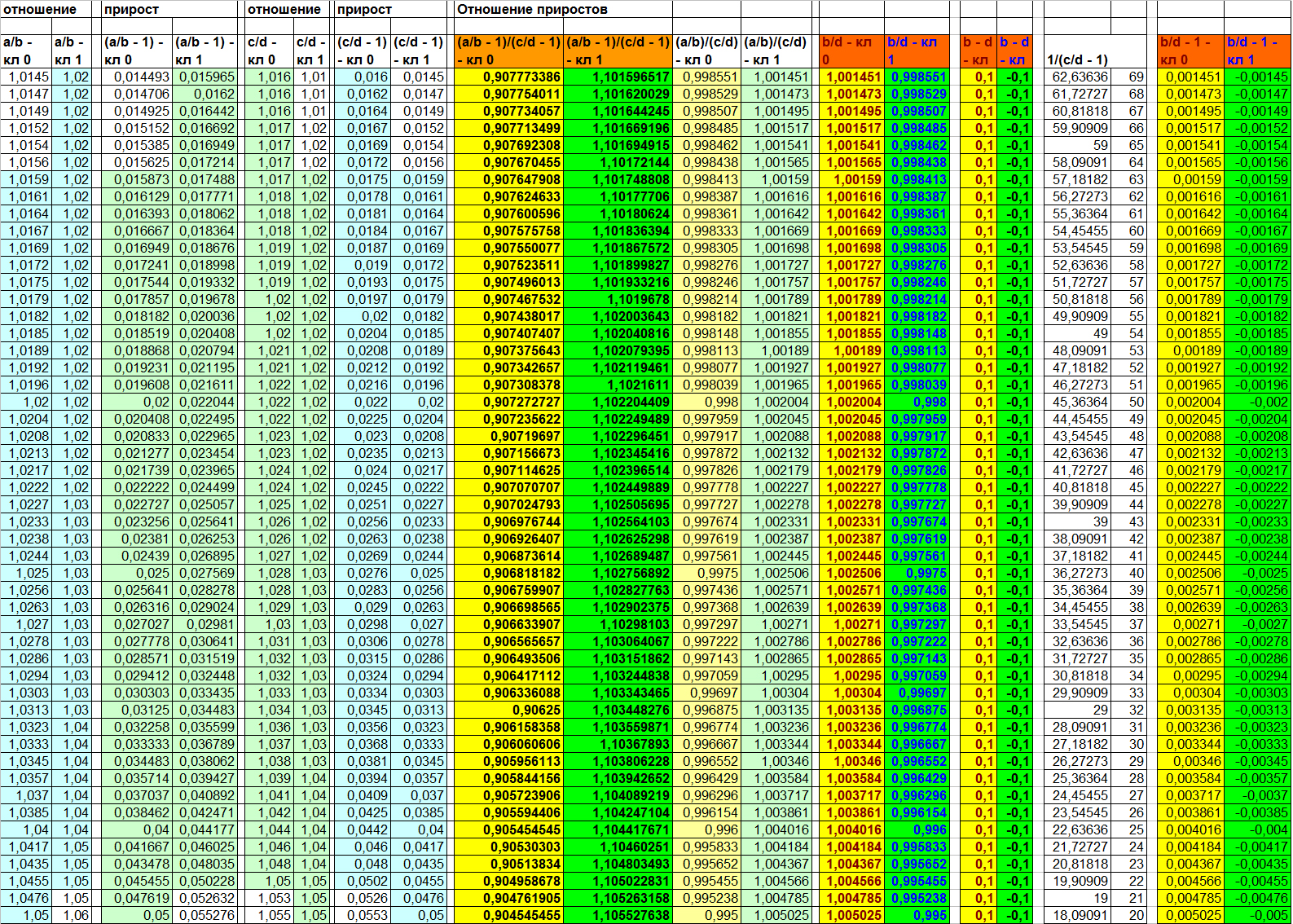
Таблица 3
Как можно увидеть в таблице 3, отношения (A/B) и (C/D) информативными не являются. Объекты противоположных классов на них по прежнему сильно перемешаны. А вот отношение B/D ожидаемо делает выборку линейно разделимой. Прямо как и в случае (B – D). Однако, забегая немного вперёд, скажу, что причина данной линейной разделимости по данному признаку всё же несколько иная, нежели для функции разности. Это будет наглядно видно на следующем примере.
Пока же давайте опустим этот нюанс и подумаем, что может быть не так в данном варианте зависимости. Для алгоритма — скорее всего ничего. А вот для человека визуально признаки для обоих классов могут показаться очень близкими. Конечно, в данном примере все значения красиво распределились по разные стороны от единицы, но в жизни такой наглядности может и не быть. Как же решить данную косметическую проблемку? Один из простых вариантов – посчитать прирост значения в числителе относительно величины значения в знаменателе. Что это значит?
Вычисляя отношение (X/Y), мы получаем ответ на вопрос «Сколько раз Y поместится в величину X». Однако же порой выгоднее решить вопрос «Сколько Y-ов нужно прибавить к величине Y, чтобы получился X». Во втором случае мы ищем прирост. Прирост может быть положительным и отрицательным и выражается простой формулой (X/Y – 1). Минус один – потому что за единицу измерения мы берём один Y.
Давайте ещё раз посмотрим в таблицу 3 (на две самые правые колонки) и обратим внимание на то, что теперь мы наглядно видим, что прирост для объектов разных классов есть величина разнознаковая. Стало быть, мы можем говорить о разнонаправленности прироста B от D для разных классов. И именно этот фактор в данном случае в действительности и играет ключевую роль в том, что признак (B/D) делает выборку линейно разделимой. Вывод: каждая из функций: (B – D) и (B/D) (или B/D — 1) делает выборку линейно разделимой несколько иным способом, а значит, возможны ситуации, когда лишь одна из них будет продуктивной для некоторой пары признаков. Но об этом более подробно чуть позже. Сейчас же давайте перейдём к третьей функции – последней для первого примера.
(A/B) / (C/D) – отношение линейных связей
или
(A/B — 1) / (C/D — 1) – отношение приростов
Что может побудить нас считать отношения линейных связей или отношения приростов? В нашем примере двух разных производителей техники такое вычисление имеет следующий смысл: «насколько изменится зависимость производительности от оборотов при подключении нагрузки».
Что ж, вполне законный вопрос. Учитывая, что речь идёт о разных производителях, разное поведение техники при повышении нагрузки вполне ожидаемо. В жизненных же ситуациях мы можем вести речь о том, что есть две взаимосвязи: F(Xi, Xj) и F(Xii, Xjj), и каждая из них в действительности есть функция от неизвестного нам набора параметров: F(M) и F’(M). И если такая гипотеза верна, мы можем предполагать, что даже если каждая из функций F и F’ одинаково проявляет себя для объектов разных классов, их композиция F''(F, F') может проявляться различно на объектах разных классов, так как в действительности у этих разных классов значимо различны неизвестные нам параметры из множества M.
В нашем примере, конечно, мы изначально знаем, откуда растут ноги у такой взаимосвязи второго порядка, так как сами и составляли соответствующим образом данные. В жизни же мы можем этого не знать и рассчитывать лишь на то, что такая взаимосвязь существует. И следовательно пытаться её найти.
Давайте вернёмся к таблице 3 (четыре центральных колонки) и посмотрим, как проявляют себя данные функции для пар (A/B) и (C/D). Мы видим, что обе они делают выборку линейно разделимой. Как и рассмотренные ранее (B – D) и (B/D).
Единственным важным различием в данном примере является то, что значения функции (A/B) / (C/D) лежат весьма близко друг к другу, а вот ширина разделяющей полосы для объектов при использовании функции (A/B — 1) / (C/D — 1) значительно шире. Глядя на такой результат, можно задаться двумя вопросами:
- Так ли важно это различие?
- Всегда ли обе функции показывают одинаковую разделяющую способность?
Ответ на первый вопрос: Да, если мы планируем так или иначе включать в композицию метрические методы классификации. Ведь при более широкой разделяющей полосе лучше срабатывает гипотеза компактности. К тому же мы можем вести речь и о качестве визуализации. Справедливости ради стоит, конечно, отметить, что в данном примере метрические методы после обучения всё равно безошибочно разделят выборку по признаку (A/B) / (C/D). Однако в жизни взаимопроникновение при использовании метрики может оказаться куда более существенным.
Ответ же на второй вопрос для данного примера, пожалуй, не является достаточно очевидным. Поэтому давайте оставим его висящим в воздухе до рассмотрения следующего примера.
Вариант зависимости 2. Xj = K*Xi + C, K = 1, C – однознаковый для обоих классов
Данный пример – частный случай первого, в котором свободный член принимает для всех объектов значение либо больше, либо меньше нуля. Посмотрим, к каким эффектам это приведёт.Пусть b = a — 1 для обоих классов, а вот d = c – 1.2 для класса 0 и c – 1.3 для класса 1)
В данном случае, конечно же, очевидно, что новый столбец со значениями
(B — D) даст для объектов 0-го и 1-го классов соответственно значения
(c – 1) – (a – 1.2) = c – a + 0.2
и
(c – 1) – (a – 1.3) = c – a + 0.3
соответственно. А это, в свою очередь, при однородности данных в колонках A и C (а это одно из условий в нашей задаче), даёт нам неплохой инструмент для разделения объектов. И мы опять как минимум можем рассчитывать на позитивный вклад данного нового столбца в итоговую классификацию.
Результат подобного вычисления на наших придуманных данных вы можете посмотреть в таблице 4:
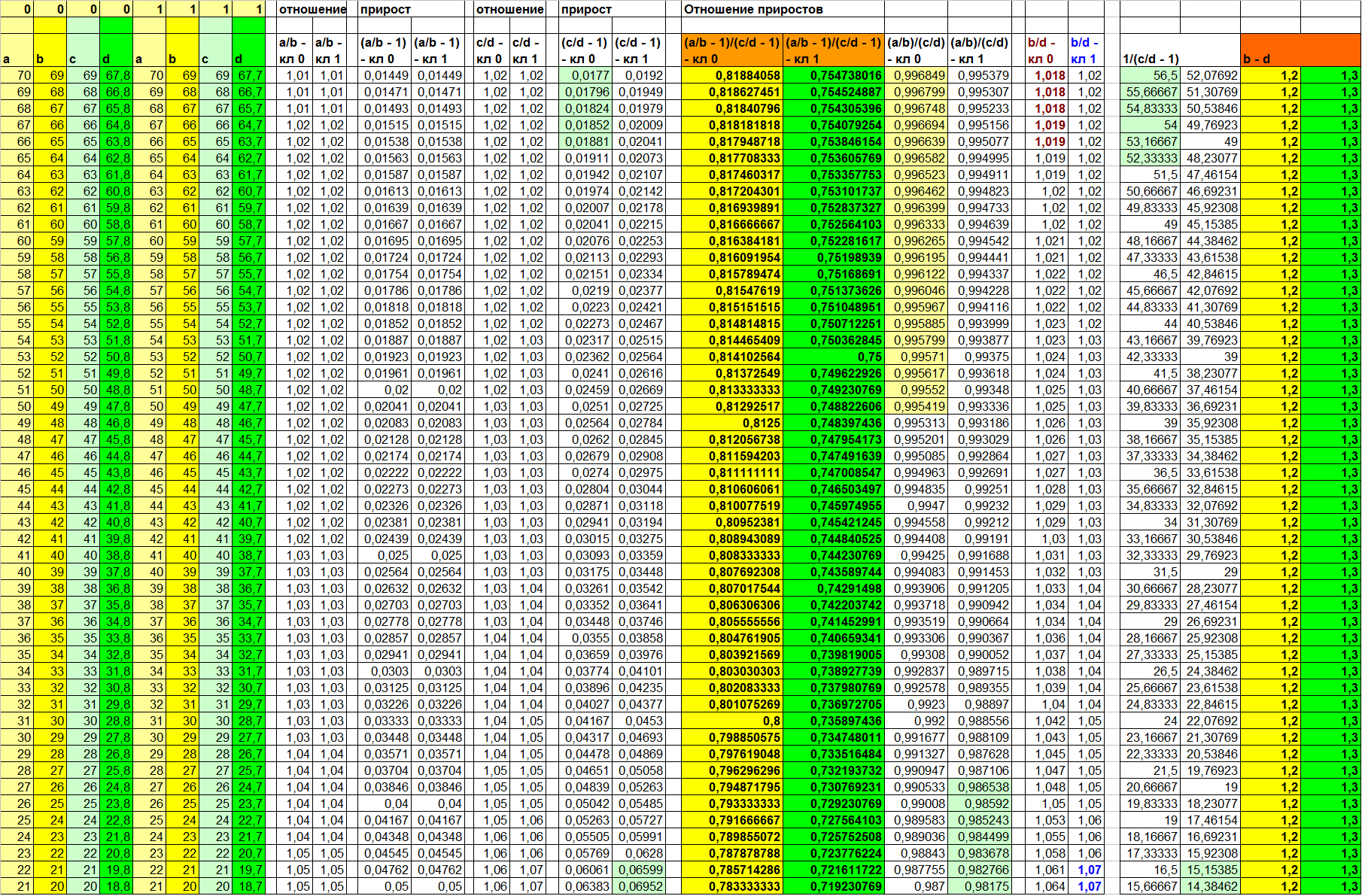
Таблица 4
Левые 8 колонок — актуальные значения признаков a, b, c, d для классов 0 и 1. Значения в остальных колонках — вычисленные в соответствии с функцией в заголовке. Значения (B — D) в двух правых колонках.
Итак, давайте посмотрим, что даст нам применение уже известных функций, которые в примере 1 смогли сделать выборку линейно разделимой.
F(Xi, Xj) = Xi/XjКак можно видеть в таблице 4, информативных отношений в данном случае найти не удаётся. И даже отношение (B/D) – колонок, значения в которых вычислены нами разными способами, не даёт нам сколь бы то ни было удовлетворительного результата (5-ая и 6-ая колонки справа). Но в чём же дело? Мы же всего лишь немного изменили значение свободного члена! Причина в том, что в первом примере свободный член для разных классов имел разный знак. И именно это и делало выборку линейно разделимой на признаке (B/D).
(A/B) / (C/D) – отношение линейных связей или
(A/B — 1) / (C/D — 1) – отношение приростов
Напомню, что в нашем надуманном примере про компьютеры лепреконов такое вычисление имеет смысл: «насколько изменится зависимость производительности от оборотов под нагрузкой».
На наших специально подогнанных и отсортированных данных мы невооружённым глазом видим, что деградация производительности под нагрузкой у машин фирмы The First немного выше, чем у машин фирмы Black Zero. (Но почему же тогда они стоят дороже? Очевидно, Black Zero пытается выжать из своих ядерных процессоров больше, чем те могут потянуть, сохранив при этом надёжность. Поэтому то они и служат в пять раз меньше, чем процессоры The First! Негоже жертвовать качеством в угоду маркетингу, Black Zero!)
Ну да вернёмся к нашим взаимосвязям. Если вновь заглянуть в таблицу 4, можно заметить одну очень интересную вещь!
Отношение приростов (A/B — 1) / (C/D — 1) делает выборку линейно разделимой, в то время как отношение линейных связей (A/B) / (C/D) оставляет довольно большой диапазон неопределённости! К слову говоря, вот и ответ на вопрос «Всегда ли обе функции показывают одинаковую разделяющую способность?»
(В таблице 4 это колонки с 7-ой по 10-ую справа. Непересекающиеся значения выделены цветом)
Что ж. Самое время перейти к третьему примеру, а пока просто запомнить следующее:
- функции отношения линейных связей и отношения приростов не всегда показывают одинаковую разделяющую способность;
- в примере, когда разделяющая способность функции отношения приростов была выше разделяющей способности функции отношения линейных связей, также стопроцентную разделяющую способность проявила функция разности, а вот отношения пар признаков были мало информативны для построения оптимального классификатора.
Вариант зависимости 3. Xj = K*Xi + C, K != 1, C = 0
Ещё один частный случай, но в котором в неизвестной зависимости играет роль коэффициент, а не свободный член.Пусть b = a — 1 для обоих классов, а вот d = (c * 0.99) для класса 0 и (c * 0.98) для класса 1)
Результаты вычислений приведены в таблице 5. Рассмотрим их бегло.
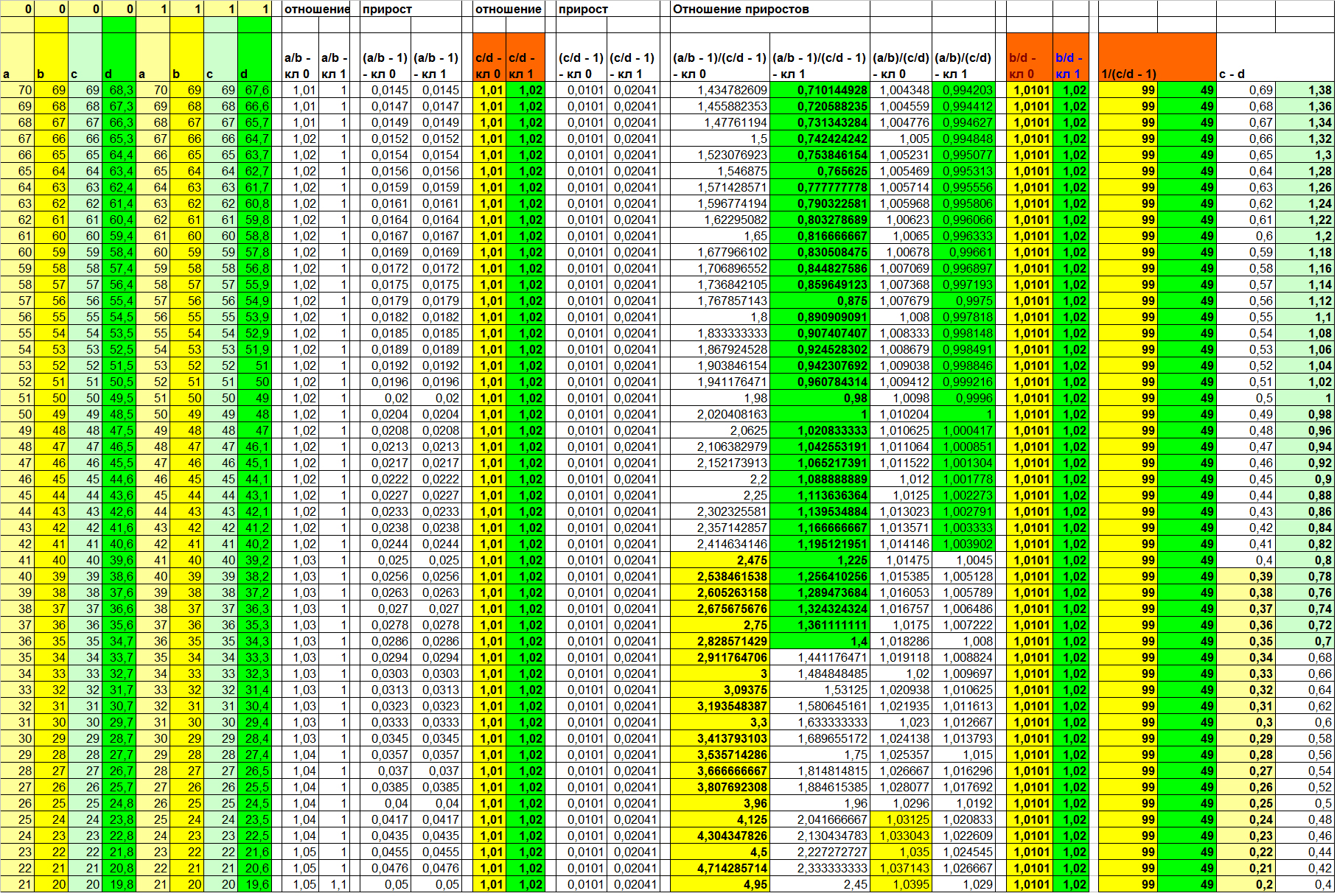
Таблица 5
Поскольку вклад в зависимость в этом примере вносит именно (и только!) коэффициент, ожидаемо сто процентную разделимость даёт функция отношения F(Xi, Xj) = Xi / Xj. А обратная к приросту (3-я и 4-ая колонки справа) ещё и улучшает визуализацию. Отношение линейных зависимостей вновь показывает результат, отличный от отношения приростов. Причём, опять в худшую сторону.
А вот бывшая в прошлых примерах стабильно информативной функция разности (две правые колонки) на этот раз оставляет довольно широкую зону неопределённости. И примечательно то, что она совпадает с зоной неопределённости функции отношения приростов. Сравните сами (колонки 1, 2 и 9, 10 справа; непересекающиеся значения разных классов выделены цветом).
Какова же будет картина, если вклад внесёт как коэффициент, так и свободный член? Ожидаемо ни одно из рассмотренных нами отношений в отдельности не делает выборку линейно разделимой. Однако диапазоны неопределённости для разных вычисленных колонок включают в себя разные подмножества объектов выборки! Что конечно же значит, что на множестве вычисленных признаков скорее всего возможно построить разделяющую гиперплоскость, на сто процентов разделяющую объекты разных классов.
Давайте на примере данных в таблице 6 рассмотрим, как проявила себя та или иная функция при заданных нами при формировании данных зависимостях:
для класса 0:
B = A - 1
D = 0,95*B - 0,55для класса 1:
B = A - 1,1
D = 0,965*B - 0,5
Таблица 6
Для вычисленных значений функций от B и D мы видим, что простое отношение, отношение линейных связей, прирост и обратная к приросту дали очень схожие результаты. При этом, как мы помним, в прошлом примере (таблица 5) простое отношение сделало выборку линейно разделимой, тогда как отношение линейных связей оставило весьма широкую зону неопределённости (что, к слову, обусловлено избыточностью применения для ситуации в прошлом примере функции отношения линейных связей).
Также мы видим, что отношение приростов, в отличие от прошлых примеров, разделило выборку хуже отношения линейных связей. А функция разности дала ещё худшую результативность, нежели отношение приростов (напомню, что во всех прошлых примерах их эффективности были одинаковыми). Это говорит о многом.
Во-первых, отношение приростов не обязательно должно показывать ту же результативность, что и простая разность.
Во-вторых, разные функции могут оставлять зоны неопределённости разной ширины — в зависимости от истинной природы искомой скрытой зависимости.
В-третьих, в зависимости от истинной природы искомой скрытой зависимости разные функции могут дать наилучший результат разделения объектов разных классов.
Перед тем, как перейти к тому, какие ещё могут существовать скрытые взаимосвязи и как лучше организовать их поиск, приведу ещё один пример синтетических данных с зависимой колонкой D. Но на этот раз я намеренно не буду приводить истинную функцию D(a, b, c). Взгляните на таблицу 7 и ещё раз убедитесь в верности трёх выводов, приведённых немного выше.
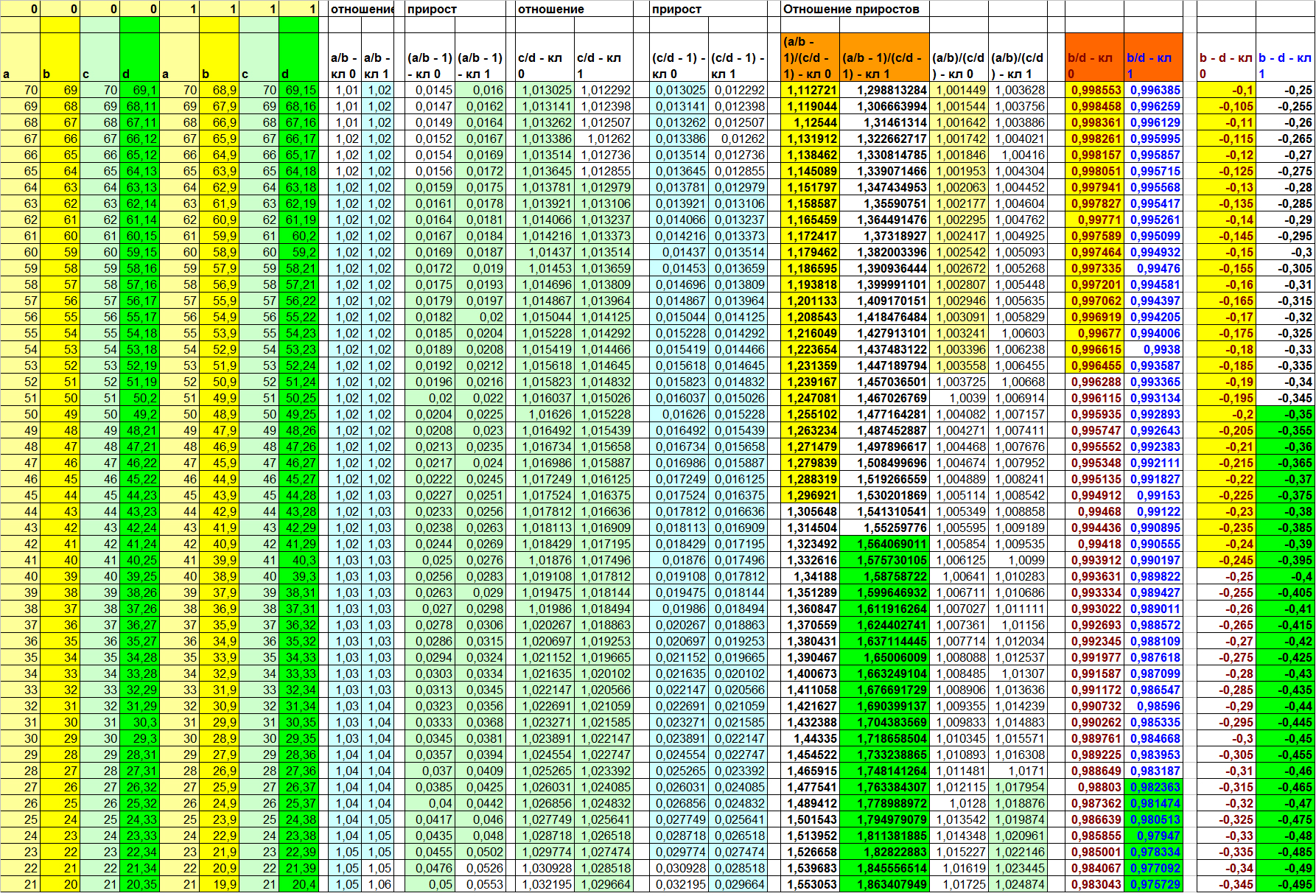
Таблица 7
Какие ещё скрытые зависимости могут содержаться в данных
В примерах выше мы использовали довольно примитивную линейную зависимость между признаками. Но может ли быть такое, что зависимость будет выражена не линейной функцией, а какой-то иной, более сложной?Почему бы и нет. Например, представьте себе данные, собираемые датчиками в среде размножения колонии зелёных микроорганизмов. Если предположить, что фиксируется концентрация продуктов жизнедеятельности M, а также ряд объективных физических параметров среды, включая освещённость lx, то мы можем полагать, что присутствует зависимость M(lx). Но линейна ли такая зависимость. Если положить, что освещённость линейно влияет на скорость размножения бактерий, а концентрация ПЖД — линейно зависит от численности колонии, то зависимость должна быть квадратичной. Причина — способ размножения одноклеточных. А именно — деление клеток. Думаю, здесь излишне доказывать, что увеличение скорости деления одноклеточных квадратично (от скорости) повлияет на их численность через время t. Следовательно, мы можем пытаться например вычислить отношение (?M / lx), полагаемое нами как некоторая аппроксимация искомой линейной зависимости скорости размножения зелёных бактерий от освещённости. И если два вида зелёных бактерий и впрямь различаются тем, насколько освещённость влияет на их скорость размножения, то данный новый признак наверняка сможет внести свой полезный вклад в качество итогового алгоритма классификации.
Конечно, зависимости могут быть самыми разными, и в основе лежит смысл, вложенный в тот или иной признак. Однако же давайте уйдём от смысловой нагрузки признаков, которыми описаны объекты выборки, а вместо этого подумаем, как можно автоматизировать процесс поиска скрытых зависимостей.
Автоматизация поиска зависимостей
Итак, мы хотим определить, есть ли в нашем признаковом описании скрытые зависимости. Положим, мы решили не искать сложных алгоритмов выбора пар признаков, и просто проверить нашу гипотезу о наличии связи для всего множества признаков N: {X1… Xn}. Начать мы решаем с пар признаков, и для каждой пары вычислить некоторое значение — результат применения для данной пары некоторой функции из множества M: {F1(Xi, Xj)… Fm(Xi, Xj)}. При этом мы полагаем, что функции множества уже отобраны нами с учётом некоторой специфики нашей задачи.
Несложно догадаться, что число пар, для каждой из которых мы хотим применить m функций из множества M, есть число сочетаний из n по 2, то есть:
n! / (2! * (n - 2)!) = n * (n - 1) / 2 = (n? - n) / 2 = ? n? - ? nВидно, что мы имеем дело с асимптотической сложностью O(n?).
А из этого вытекает два вывода:
- Такой полный перебор допустим только для выборки с числом признаков, не превышающим некоторой пороговой величины, вычисленной заранее.
- Вычисление зависимостей второго порядка, в которых участвуют уже вычисленные на основе первичных данных колонки (как отношение приростов), допустимо лишь в том случае, если существует строгий алгоритм отбора пар для таких проверок. В противном случае алгоритм полного прохода будет иметь сложность O(n?). Хотя в общем случае зависимости второго порядка так или иначе основаны пусть и на порой более слабых, но всё же достаточно информативных зависимостях первого порядка.
Соответственно, из сказанного выше следует, что возможны два случая:
- Число признаков меньше пороговой величины, и мы можем позволить себе проверку гипотезы на каждой паре.
- Число признаков превышает пороговую величину, и нам необходима стратегия отбора пар, на которых мы будем полноценно проверять гипотезу.
Рассмотрим сначала первый случай.
Число признаков меньше пороговой величины
Строго говоря, для нас не столько важно выявление некоей зависимости само по себе, сколько её разное поведение на объектах разных классов. Поэтому мы можем просто опустить момент проверки на предмет наличия зависимости, а вместо этого сразу провести проверку на предмет полезности новой колонки. Для этого достаточно применить один из известных быстрых классификаторов для данной колонки, измерив среднюю величину интересующей нас метрики качества на скользящем контроле. И затем, если показатель интересующей нас метрики качества выше заданной нами пороговой величины, оставить новую колонку, либо удалить её, если качество не дотянуло до требуемого.
Конечно же, здесь читателю в голову может прийти мысль: а что, если новая колонка вычислена на основе изначального признака, и без того имеющего высокую полезность для итогового алгоритма классификации? Ведь в этом случае получится, что мы просто создали лишний признак, опирающийся на уже имевшийся! Порождение мультиколлинеарности в чистом виде! Так вот именно на это мы и задаём порог метрики качества классификации для производных признаков. Несложно догадаться, что поскольку мы вычисляем функцию от пары признаков (а не от одного!), итог может быть и просто шумом, даже если на входе обе колонки были весьма информативными.
В этом несложно убедиться на примере синтетических данных, где значения в каждом признаке — независимо сгенерированные величины с заданными средней и отклонением. Причём, так, чтобы между средними разных классов было различие, а распределение на объектах каждого класса — нормальное (например, с помощью numpy.random.normal). Так вот поскольку мы априори генерируем значения признаков независимо друг от друга, попытка найти зависимости приводит лишь к зашумлённости, а производные признаки не дают удовлетворительного качества классификации.
Так вот приведённый выше пример говорит в пользу того, что если производный признак оказался информативным, мы можем судить о наличии взаимосвязи.
Пороговую величину для производных признаков можно выбирать разными способами. Либо разом для всей выборки, что явно проще, либо индивидуально для каждой пары. Во втором случае мы можем варьировать значение порога входа в зависимости от показателей интересующих нас метрик качества на каждой из колонок, поданных на вход.
Однако несмотря на кажущуюся логичность второго варианта выбора порога, в нём есть очень неприятный подводный камень. Речь о том, что не совсем верно выбирать в качестве порога величину метрики качества на одном из родительских столбцов. Причина в том, что может случиться и так, что производный признак с несколько более низкой величиной качества будет и впрямь аппроксимацией новой зависимости, и как следствие, может ошибаться на ином, нежели родители, множестве объектов. А это значит, что его включение в множество признаков для анализа может радикально повысить итоговое качество классификации!
Что же касается выбора общего порога входа для всех производных признаков, то здесь на мой взгляд весьма удобно выбрать порог исходя из того, какие значения интересующей нас метрики качества имеют (при применении по отдельности!) исходные колонки. Так, если для простоты примера взять Accuracy, то для его значений на исходных колонках [0.52, 0.53, 0.53, 0.54, 0.55, 0.57, 0.59, 0.61, 0.63] оптимальный порог для производных данных скорее всего будет лежать где-то в районе 0,6 (как показывает практика). Так или иначе, это не столь важно, ведь параметр является обучаемым, а его обучение повысит сложность алгоритма только линейно. При обучении же этого параметра так или иначе можно отталкиваться от плотности распределения Accuracy исходных признаков (Accuracy здесь только потому, что на нём данный пример!).
В принципе, здесь всё просто. Поэтому перейдём ко второму случаю.
Число признаков превышает пороговую величину
Данное условие означает, что мы не можем позволить себе проводить полноценный замер полезности для каждого производного признака. Либо даже больше: не можем позволить себе для каждой пары признаков генерировать производный. Оно и понятно: просто представьте, что признаков у нас тысяча. В этом случае число сочетаний будет равно999 * 1000 / 2 = 499 500И это ещё умножить на число тестируемых функций!
И даже если наш сервер способен посчитать качество классификации выбранным алгоритмом по отдельно взятому признаку 100 раз в секунду, ждать почти полтора часа, пока отработает алгоритм генерации признаков только для одной из выбранных нами функций — занятие как минимум странное. Хотя, с другой стороны порождающее немало свободного времени =)
Ну да вернёмся к нашим баранам. Как можно решать данную задачу?
Попытка уменьшить число исходных признаков на основе их полезности для классификации может оказаться не лучшей идеей, ведь на примере синтетических данных в первой части статьи было наглядно показано, что производный признак, каждый из родителей которого в чистом виде совершенно непригоден для задачи классификации, при идеальных условиях способен сделать выборку линейно разделимой.
Как же тогда быть? Видимо, вычислять производные признаки всё же придётся, правда, с некоторыми ограничениями.
Во-первых, в зависимости от того, насколько превышен порог по числу исходных признаков, мы можем для оценки полезности производных признаков генерировать их лишь для части исходных объектов выборки. Не буду вдаваться в то, какого размера подвыборки следует брать — на этот вопрос неплохо отвечает математическая статистика.
Во-вторых, оценку полезности каждого производного признака следует проводить по урезанному функционалу. Опять же, в зависимости от степени превышенности порога числа исходных. То есть, если до этого мы использовали для оценки качества производного признака, к примеру, метод k ближайших соседей с урезанным функционалом обучения, то теперь мы можем использовать его же, но с фиксировано заданными параметрами. Или применить для взвешивания полученного набора признаков метод опорных векторов с параметрами по умолчанию, и затем отбросить колонки с весом ниже определённого. Или же для более экстремальных случаев (с количеством исходных признаков) можно просто применить один из статистических критериев, например, простой Q-критерий Розенбаума. К сожалению, применение такого рода критериев не сможет помочь нам отобрать признаки, имеющие перемежающиеся пики в их распределениях плотности вероятности или просто разнонаправлено смещённые медианы.
Например, пусть значения получившегося признака для классов 1 и -1 равны соответственно:
[9,9,9,9,9,8,8,8,8,8,8,8,8,7,7,7,7,6,6,5,4,3,2,2,1,1,1,1,1,0,0,0,0,0,0,0,0,0]
[9,8,8,7,7,6,6,6,6,6,6,6,6,5,5,5,5,5,5,5,5,5,5,4,4,4,4,4,4,4,3,3,3,3,3,2,2,1,0]или (для смещённых средних):
[1,2,2,3,3,3,4,4,4,4,5,5,5,5,5,6,6,6,6] VS [1,1,1,1,2,2,2,2,2,3,3,3,3,4,4,4,5,5,6]Очевидно, что в обоих случаях критерий Розенбаума посчитает, что выборки не различаются вообще. Конечно, в данном случае превосходно сработает критерий Пирсона, так как он предусматривает разбиение на некоторое число непересекающихся интервалов и подсчёт числа значений для каждого интервала в отдельности. Однако при этом критерий Пирсона потребует и больше времени на выполнение, а это именно тот параметр, который мы пытаемся оптимизировать при первом — грубом приближении.
В-третьих, по причине того, что мы допускаем снижение качества оценки полезности производных признаков, мы также немного снижаем порог входа.
Таким образом, мы сравнительно малой кровью избавляемся от внушительного числа самых неинформативных признаков. А вот на оставшихся (опять же, в зависимости от их числа) можем применить методы более качественной оценки полезности признака.
Если подытожить, то мы говорим о деградации качества оценки для первичного быстрого отбрасывания самых неинформативных признаков для последующего более качественного оценивания оставшихся.
Что ж, пора, пожалуй, завершать. Если коротко подытожить всё вышесказанное, стоит отметить следующие моменты.
Выводы
- Часто для признакового описания данных в задачах классификации бывает возможно найти скрытые зависимости F(Xi, Xj), которые способны выступить в роли самостоятельных признаков и повысить качество классификации.
- Скрытые зависимости между признаками могут описываться разными функциями, и в разных случаях разные функции могут проявить себя лучше остальных.
- Для автоматизации процесса нахождения скрытых зависимостей стоит изначально выбрать набор функций, адекватность применения которых зависит от специфики задачи.
- Число производных столбцов для анализа равно k*(n? — n) / 2, где k — число выбранных функций, n — число исходных признаков.
- Для не очень большого числа признаков можно позволить себе полный перебор всех пар с полноценной проверкой полезности для каждого полученного признака.
- Если число исходных признаков превышает некоторую пороговую величину, проверку производных признаков стоит проводить в два этапа: быстрое отбрасывание самых неинформативных производных признаков и последующий более качественный разбор оставшихся. Гипотетически есть возможность вычисления производных признаков F(Xi, Xj) от множества признаков M', которые даст нам применение метода главных компонент на исходное множество признаков M, но встаёт вопрос о том, все ли скрытые зависимости в этом случае могут быть проявлены.
Что ж, на этом на этот раз всё. И да, теперь то уж мы точно сможем помочь лепреконам более эффективно находить диссидентов среди своих сородичей!
Телеграм: t.me/ainewsline
Источник: habrahabr.ru