Опубликован код для определения reCaptcha с точностью 85%
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-10-31 16:05
машинное обучение python, методы распознавания образов, архитектура нейронных сетей

Исследователи из Мэрилендского университета и компании Vicarious опубликовали реализации двух различных методов обхода средств отсеивания интернет-ботов на основе капчи, в том числе позволяющих обойти защиту популярного сервиса reCaptcha. Методы интересны различиями в подходах - первый проект легко реализуем при помощи существующих сервисов, а второй потребовал существенных исследований в области распознавания образов и машинного обучения.
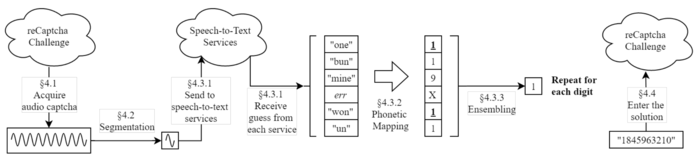
Первый проект получил название unCaptcha и позволяет восстановить цифровой код reCaptcha, предлагаемый в режиме звуковой капчи. Метод позволяет определить капчу с точностью 85.15%. На распознавание уходит приблизительно 5 секунд, что сопоставимо с длительностью предлагаемой звуковой последовательности. Реализация опубликована на GitHub под лицензией MIT.
Суть метода сводится к записи продиктованных цифр, разделения отдельных слов и передачи каждого слова одновременно в шесть online-сервисов распознавания речи (IBM, Google Cloud, Google Speech Recognition, Sphinx, Wit-AI, Bing Speech Recognition). Далее из распознанных фраз выделяются цифры или слова по произношению близкие к цифрам (например, true/to/too воспринимается как 2, tree/free как 3, sex как 6 и т.п.) и на основе оценки частоты совпадений выбирается наиболее вероятное значение.
Второй проект использует методы машинного обучения и распознавания образов для выбора правильной картинки при работе с различными капчами. Для распознавания используется специально разработанный алгоритм RCN (Recursive Cortical Network), эталонная реализация которого опубликована под лицензией MIT.
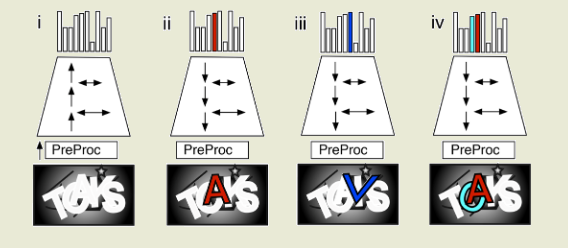
В условиях распознавания обычного текста RCN обеспечивает точность на уровне 90% и в отличие от традиционно применяемых для подобных задач свёрточных нейронных сетей (CNN, Сonvolutional Neural Network) требует существенно меньшего объёма данных для обучения, обеспечивая при этом отличную адаптацию к искажениям символов, наклону, наложению и размытию, не требуя при этом дополнительного обучения.
Например, cеть RCN позволила добиться точности в 66.6% при распознавании фраз на капче reCAPTCHA, использовав для обучения всего 500 изображений. Для капч BotDetect точность распознавания составила 64.4%, Yahoo - 57.4% и PayPal - 57.1% (капча считается ненадёжной при возможности автоматического подбора с точностью в 1%). При оптимизации модели под конкретный стиль удалось добиться точности распознавания на уровне 90%.
Для сравнения остроенная компанией Google свёрточная нейронная сеть обеспечила уровень распознавания reCAPTCHA в 89.9%, но потребовала обучения на базе из 2.3 млн изображений капч и продемонстрировала снижение точности до 38.4% при простом изменении на 15% пространства между символами, в то время как RCN легко адаптируется к изменениям в стиле без потери эффективности.
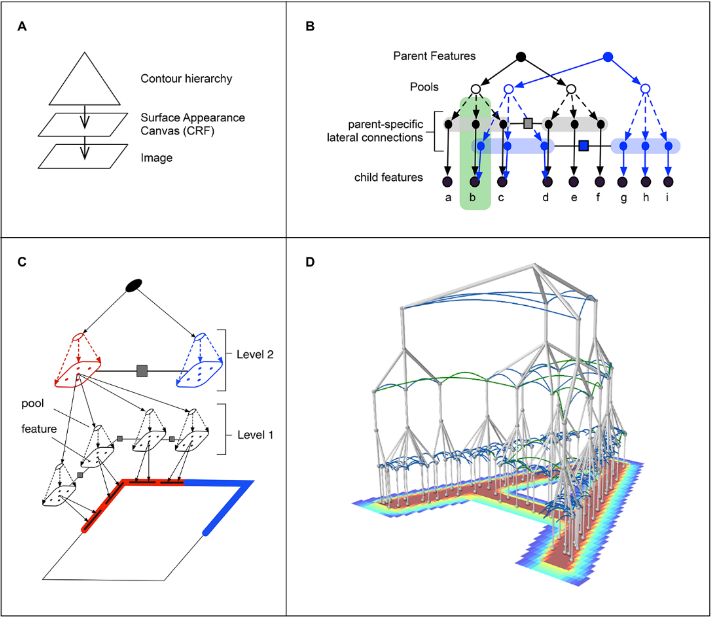
В RCN задействованы методы, сходные с работой человеческого зрения. Работа RCN напоминает поведение нейронов в коре головного мозга, одна часть которых осуществляет выделение контуров объектов, а другая занимается изучением поверхности и текстур, сообща решая задачу распознавания образа. В RCN одна часть сети осуществляет выделение контуров объектов, другая часть анализирует наложения и параметры разных объектов, а третья выполняет операции классификации выделенной иерархии объектов с учётом стиля и угла зрения. На последнем этапе осуществляется сопоставление с формами стандартных букв или цифр. Для каждой из букв алфавита формируется набор шаблонов, учитывающих разные начертания, наклон, растяжение и другие виды искажений. Сопоставление осуществляется с использованием генеративной вероятностной модели, выделяющей наиболее вероятную связь исходного объекта с объектами из базы сопоставлений.
Телеграм: t.me/ainewsline
Источник: www.opennet.ru