Нечёткое сравнение строк: пойми меня, если сможешь
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-10-30 09:56

На естественном языке сказать об одном и том же факте можно бесконечным числом способов. Можно переставлять слова местами, заменять их на синонимы, склонять по падежам (если говорим о языке с падежами) и тд.
Необходимость определять схожесть двух фраз возникла при решении одной небольшой практической задачи. Я не использовал машинное обучение, не вил нейронные сети, но использовал простые метрики и собранную статистику для калибровки коэффициентов.
Результатом работы, описанием процесса, кодом на git'е готов поделиться с вами.
Итак, кратко задачу можно озвучить так: «С определенной периодичностью из различных источников приходят актуальные новости. Необходимо фильтровать их таким образом, чтобы на выходе не было двух новостей об одном и том же факте.»
Из 4 и 5 пунктов ограничений можно сгенерировать новое ограничение: максимальное количество новостей, с которыми нужно сравнивать новую новость, составляет 24 часа * (60 мин. / 5 мин.) * 20 штук = 5760 новостей. (Надо отметить, что 20 новых новостей за 5 минут — это гипотетически возможное значение, но по факту приходит 1 или 2 действительно новых новости за 15-20 минут, а значит фактическое значение будет 24 * (60 /15) * 1 = 96).
Из ограничения 2 делаем вывод о том, что достаточно анализировать заголовки новостей, не обращая внимания на их содержание.
Строки переводятся в нижний регистр, удаляются все символы, отличные от букв, цифр и пробела.
Выделение слов
Словами считаются все последовательности символов без пробелов, которые имеют длину >= 3. Этим самым удаляются почти все предлоги, союзы и тд. — в какой степени это можно отнести к продолжению нормализации.
Сравнение слов по подстрокам
Здесь применяется коэффициент Танимото, но не к символам, а к кортежам из подряд идущих символов, причем кортежи составляются с нахлестом.
Применение коэффициента Танимото к заголовку
Мы знаем сколько всего слов в каждом из предложений, знаем количество «нечётко совпадающих» слов и применяем к этому знакомую формулу.
Алгоритм был протестирован на сотнях заголовков в течении нескольких дней, результаты его работы визуально оказались вполне приемлемыми, но надо было оптимально подобрать следующие коэффициенты:
ThresholdSentence — порог принятия нечеткой эквивалентности всего предложения;
ThresholdWord — порог принятия нечеткой эквивалентности между двумя словами;
SubtokenLength — размер подстроки при сравнении двух слов (от 1 до MinWordLength)
Наилучшие результаты c точность 87% и числом ложных срабатываний 3% получаются при следующих параметрах: ThresholdSentence = 0.25, ThresholdWord = 0.45, SubtokenLength = 2;
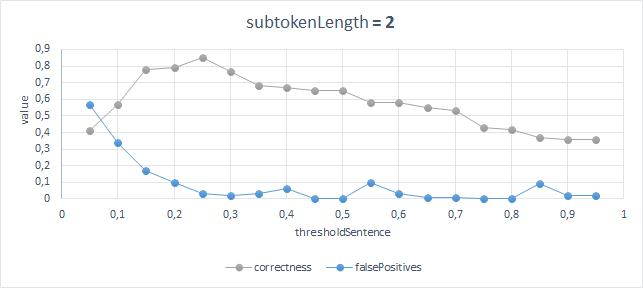 Сравнение результатов работы алгоритма с моделью
Сравнение результатов работы алгоритма с моделью
Трактовать результаты можно так:
Наилучшая точность и наименьшее число ошибок получается, если при сравнении слов считать длину подстрок равной 2 символам, при этом должно быть отношение количества совпадающих подстрок к количеству несовпадающих большим или равным 0.45, а два заголовка будут эквивалентными, если не менее четверти слов совпадали.
Если учитывать введенные ограничения, вполне корректные результаты. Конечно, искусственно можно придумать сколько угодно вариантов, на которых появятся ложные срабатывания.
Необходимость определять схожесть двух фраз возникла при решении одной небольшой практической задачи. Я не использовал машинное обучение, не вил нейронные сети, но использовал простые метрики и собранную статистику для калибровки коэффициентов.
Результатом работы, описанием процесса, кодом на git'е готов поделиться с вами.
Итак, кратко задачу можно озвучить так: «С определенной периодичностью из различных источников приходят актуальные новости. Необходимо фильтровать их таким образом, чтобы на выходе не было двух новостей об одном и том же факте.»
Предупреждение: в статье присутствуют заголовки реальных новостей. Я отношусь к ним исключительно как к рабочему материалу, не представляю какую-либо точку зрения на политическую или экономическую ситуацию в какой бы то ни было стране.
Ограничения задачи
Задача имеет прикладной характер, необходимо задать ограничения:- Каждая новость состоит из заголовка и тела (содержания).
- Заголовок — это осмысленное предложение на естественном языке, по которому человек может понять суть новости.
- Заголовок имеет длину не более 100 символов. Он может состоять из любых символов, включая цифры, пунктуацию и спец.символов.
- Максимальное количество новых новостей, которые могут появиться в промежуток 5 минут — 20 штук.
- Новую новость необходимо сравнивать со всеми новостями, которые приходили за последние сутки.
Из 4 и 5 пунктов ограничений можно сгенерировать новое ограничение: максимальное количество новостей, с которыми нужно сравнивать новую новость, составляет 24 часа * (60 мин. / 5 мин.) * 20 штук = 5760 новостей. (Надо отметить, что 20 новых новостей за 5 минут — это гипотетически возможное значение, но по факту приходит 1 или 2 действительно новых новости за 15-20 минут, а значит фактическое значение будет 24 * (60 /15) * 1 = 96).
Из ограничения 2 делаем вывод о том, что достаточно анализировать заголовки новостей, не обращая внимания на их содержание.
Примеры заголовков
16; Правительство внесло изменения в программу развития Курил
18; Кабмин увеличил финансирование федеральной программы развития Курил
19; Правительство увеличило финансирование программы развития Курил
6; Инженеры стали самыми востребованными на рынке труда
12; Названы самые востребованные в России профессии
20; Стали известны самые востребованные профессии в России
26; Инженеры признаны самыми востребованными на рынке труда в РФ
32; Инженеры стали самыми востребованными на рынке труда РФ в сентябре
51; Названы самые востребованные профессии в России
53; Минтруд назвал самые востребованные профессии в России
25; Сбербанк с 16 октября снижает ставки по потребительским кредитам
31; Сбербанк снизил процентные ставки по ряду кредитов
37; Сбербанк снизил ставки по ряду кредитов
0; В России выпустят собственную криптовалюту — крипторубль
5; Россия срочно создает крипторубль
27; В России займутся выпуском крипторубля
35; В России создадут свою криптовалюту
36; Россия начнет выпускать крипторубли
42; Россия выпустит собственную криптовалюту – крипторубль
Способы нечёткого сравнения строк
Опишу несколько методов для решения задачи определения степени схожести двух строк.Расстояние Левенштейна
Возвращает число, которое показывает сколько нужно сделать операций (вставка, удаление или замена) для того, чтобы превратить одну строку в другую. Свойства: простая реализация; зависимость от порядка слов; на выходе число; которое надо с чем-то сравнить.Алгоритм шинглов
Разбивает тексты на шинглы (англ. — чешуйки), т.е цепочки по 10 слов (с пересечениями), применив к шинглам хеш-функции получает матрицы, которые и сравнивает между собой. Свойства: чтобы реализовать алгоритм надо подробно изучать мат.часть; работает на больших текстах; нет зависимости от порядка предложений.Коэффициент Жаккара (частное — коэф. Танимото)
Вычисляет коэффициент по формуле: здесь a — количество символов в первой строке, b — количество символов во второй строке, c — количество совпадающих символов. Свойства: прост в реализации; низкая точность, так как «abc» и «bca» для него одно и то же.Комбинированных подход
Каждый из приведенных алгоритмов обладает критическими для решаемой задачи недостатками. В процессе работы было реализовано вычисление расстояния Левенштейна и коэффициента Танимото, но, как и ожидалось, они показали плохие результаты. Эмпирическими рассуждениями комбинированный подход сводится к следующим шагам. Нормализация сравниваемых предложенийСтроки переводятся в нижний регистр, удаляются все символы, отличные от букв, цифр и пробела.
Нормализация предложений
/// <summary> /// Приводит предложение к нормальному виду: /// - в нижнем регистре /// - удалены не буквы и не цифры /// </summary> /// <param name="sentence">Предложение.</param> /// <returns>Нормализованное предложение.</returns> private string NormalizeSentence(string sentence) { var resultContainer = new StringBuilder(100); var lowerSentece = sentence.ToLower(); foreach (var c in lowerSentece) { if (IsNormalChar(c)) { resultContainer.Append(c); } } return resultContainer.ToString(); } /// <summary> /// Возвращает признак подходящего символа. /// </summary> /// <param name="c">Символ.</param> /// <returns>True - если символ буква или цифра или пробел, False - иначе.</returns> private bool IsNormalChar(char c) { return char.IsLetterOrDigit(c) || c == ' '; }Выделение слов
Словами считаются все последовательности символов без пробелов, которые имеют длину >= 3. Этим самым удаляются почти все предлоги, союзы и тд. — в какой степени это можно отнести к продолжению нормализации.
Выделение слов
/// <summary> /// Разбивает предложение на слова. /// </summary> /// <param name="sentence">Предложение.</param> /// <returns>Набор слов.</returns> private string[] GetTokens(string sentence) { var tokens = new List<string>(); var words = sentence.Split(' '); foreach (var word in words) { if (word.Length >= MinWordLength) { tokens.Add(word); } } return tokens.ToArray(); }Сравнение слов по подстрокам
Здесь применяется коэффициент Танимото, но не к символам, а к кортежам из подряд идущих символов, причем кортежи составляются с нахлестом.
Нечеткое сравнение слов
/// <summary> /// Возвращает результат нечеткого сравнения слов. /// </summary> /// <param name="firstToken">Первое слово.</param> /// <param name="secondToken">Второе слово.</param> /// <returns>Результат нечеткого сравения слов.</returns> private bool IsTokensFuzzyEqual(string firstToken, string secondToken) { var equalSubtokensCount = 0; var usedTokens = new bool[secondToken.Length - SubtokenLength + 1]; for (var i = 0; i < firstToken.Length - SubtokenLength + 1; ++i) { var subtokenFirst = firstToken.Substring(i, SubtokenLength); for (var j = 0; j < secondToken.Length - SubtokenLength + 1; ++j) { if (!usedTokens[j]) { var subtokenSecond = secondToken.Substring(j, SubtokenLength); if (subtokenFirst.Equals(subtokenSecond)) { equalSubtokensCount++; usedTokens[j] = true; break; } } } } var subtokenFirstCount = firstToken.Length - SubtokenLength + 1; var subtokenSecondCount = secondToken.Length - SubtokenLength + 1; var tanimoto = (1.0 * equalSubtokensCount) / (subtokenFirstCount + subtokenSecondCount - equalSubtokensCount); return ThresholdWord <= tanimoto; }Применение коэффициента Танимото к заголовку
Мы знаем сколько всего слов в каждом из предложений, знаем количество «нечётко совпадающих» слов и применяем к этому знакомую формулу.
Нечеткое сравнение предложений
/// <summary> /// Вычисляет значение нечеткого сравнения предложений. /// </summary> /// <param name="first">Первое предложение.</param> /// <param name="second">Второе предложение.</param> /// <returns>Результат нечеткого сравнения предложений.</returns> public double CalculateFuzzyEqualValue(string first, string second) { if (string.IsNullOrWhiteSpace(first) && string.IsNullOrWhiteSpace(second)) { return 1.0; } if (string.IsNullOrWhiteSpace(first) || string.IsNullOrWhiteSpace(second)) { return 0.0; } var normalizedFirst = NormalizeSentence(first); var normalizedSecond = NormalizeSentence(second); var tokensFirst = GetTokens(normalizedFirst); var tokensSecond = GetTokens(normalizedSecond); var fuzzyEqualsTokens = GetFuzzyEqualsTokens(tokensFirst, tokensSecond); var equalsCount = fuzzyEqualsTokens.Length; var firstCount = tokensFirst.Length; var secondCount = tokensSecond.Length; var resultValue = (1.0 * equalsCount) / (firstCount + secondCount - equalsCount); return resultValue; } /// <summary> /// Возвращает эквивалентные слова из двух наборов. /// </summary> /// <param name="tokensFirst">Слова из первого предложения.</param> /// <param name="tokensSecond">Слова из второго набора предложений.</param> /// <returns>Набор эквивалентных слов.</returns> private string[] GetFuzzyEqualsTokens(string[] tokensFirst, string[] tokensSecond) { var equalsTokens = new List<string>(); var usedToken = new bool[tokensSecond.Length]; for (var i = 0; i < tokensFirst.Length; ++i) { for (var j = 0; j < tokensSecond.Length; ++j) { if (!usedToken[j]) { if (IsTokensFuzzyEqual(tokensFirst[i], tokensSecond[j])) { equalsTokens.Add(tokensFirst[i]); usedToken[j] = true; break; } } } } return equalsTokens.ToArray(); }Алгоритм был протестирован на сотнях заголовков в течении нескольких дней, результаты его работы визуально оказались вполне приемлемыми, но надо было оптимально подобрать следующие коэффициенты:
ThresholdSentence — порог принятия нечеткой эквивалентности всего предложения;
ThresholdWord — порог принятия нечеткой эквивалентности между двумя словами;
SubtokenLength — размер подстроки при сравнении двух слов (от 1 до MinWordLength)
Оценка качества работы алгоритмы
Для оценки качества работы были выделены 100 различных заголовков новостей, которые приходили друг за другом. Далее была размечена квадратная матрица 100x100, где я поставил 0, если заголовки были на разные темы и 1, если темы совпадали. Понимаю, что выборка небольшая и, возможно, не очень точно будет демонстрировать точность работы алгоритма, но меня на большее не хватило. Теперь, когда есть образец, с которым можно сравнивать выход алгоритма, будем оценивать точность простой формулой — отношением правильных ответов к общему числу сравнений. Кроме того, как метрику, можно оценивать число ложных срабатываний.Наилучшие результаты c точность 87% и числом ложных срабатываний 3% получаются при следующих параметрах: ThresholdSentence = 0.25, ThresholdWord = 0.45, SubtokenLength = 2;
Трактовать результаты можно так:
Наилучшая точность и наименьшее число ошибок получается, если при сравнении слов считать длину подстрок равной 2 символам, при этом должно быть отношение количества совпадающих подстрок к количеству несовпадающих большим или равным 0.45, а два заголовка будут эквивалентными, если не менее четверти слов совпадали.
Если учитывать введенные ограничения, вполне корректные результаты. Конечно, искусственно можно придумать сколько угодно вариантов, на которых появятся ложные срабатывания.
Реальный пример ложного срабатывания
ВТБ снизил минимальную ставку по кредитам наличными
Сбербанк снизил ставки по ряду кредитов
Заключение
Истоки этой задачи лежат в том, что мне понадобилось организовать себе оперативную доставку актуальных новостей. Источники информации — СМИ, которые я постоянно читаю, сидя в интернете, теряя при этом уйму времени, отвлекаясь на ненужную информацию, лишние переходы по ссылкам. В результате родились несколько небольших каналов telegram и групп в контакте. Если вдруг кому-то будет интересно, пишите сообщения — дам ссылки. Готовая реализация алгоритмы в виде библиотеки: SentencesFuzzyComparison.Телеграм: t.me/ainewsline
Источник: habrahabr.ru