Книга «Python для сложных задач: наука о данных и машинное обучение»
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-10-10 16:54
Привет, Хаброжители! Данная книга — руководство по самым разным вычислительным и статистическим методам, без которых немыслима любая интенсивная обработка данных, научные исследования и передовые разработки. Читатели, уже имеющие опыт программирования и желающие эффективно использовать Python в сфере Data Science, найдут в этой книге ответы на всевозможные вопросы, например: как считать этот формат данных в скрипт? как преобразовать, очистить эти данные и манипулировать ими? как визуализировать данные такого типа? как при помощи этих данных разобраться в ситуации, получить ответы на вопросы, построить статистические модели или реализовать машинное обучение?
Ниже под катом обзор книги и отрывок «Гистограммы, разбиения по интервалам и плотность»
Эта книга не планировалась в качестве введения в язык Python или в программирование вообще. Я предполагаю, что читатель знаком с языком Python, включая описание функций, присваивание переменных, вызов методов объектов, управление потоком выполнения программы и решение других простейших задач. Она должна помочь пользователям языка Python научиться применять стек инструментов исследования данных языка Python — такие библиотеки, как IPython, NumPy, Pandas, Matplotlib, Scikit-Learn и соответствующие инструменты, — для эффективного хранения, манипуляции и понимания данных.
Мир PyData гораздо шире представленных пакетов, и он растет день ото дня. С учетом этого я (автор) использую каждую возможность в книге, чтобы сослаться на другие интересные работы, проекты и пакеты, расширяющие пределы того, что можно сделать на языке Python. Тем не менее сегодня эти пять пакетов являются основополагающими для многого из того, что можно сделать в области применения языка программирования Python к исследованию данных. Я полагаю, что они будут сохранять свое значение и при росте окружающей их экосистемы.

У функции hist() имеется множество параметров для настройки как вычисления, так и отображения. Вот пример гистограммы с детальными пользовательскими настройками (рис. 4.36):

Docstring функции plt.hist содержит более подробную информацию о других доступных возможностях пользовательской настройки. Сочетание опции histtype='stepfilled' с заданной прозрачностью alpha представляется мне очень удобным для сравнения гистограмм нескольких распределений (рис. 4.37):

Если же вам нужно вычислить гистограмму (то есть подсчитать количество точек в заданном интервале) и не отображать ее, к вашим услугам функция np.histogram():

У функции plt.hist2d, как и у функции plt.hist, имеется немало дополнительных параметров для тонкой настройки графика и разбиения по интервалам, подробно описанных в ее docstring. Аналогично тому, как у функции plt.hist есть эквивалент np.histogram, так и у функции plt.hist2d имеется эквивалент np.histogram2d, который используется следующим образом:
Для обобщения разбиения по интервалам для гистограммы на число измерений, превышающее 2, см. функцию np.histogramdd.

У функции plt.hexbin имеется множество интересных параметров, включая возможность задавать вес для каждой точки и менять выводимое значение для каждого интервала на любой сводный показатель библиотеки NumPy (среднее значение весов, стандартное отклонение весов и т. д.).

Длина сглаживания метода KDE позволяет эффективно выбирать компромисс между гладкостью и детализацией (один из примеров вездесущих компромиссов между смещением и дисперсией). Существует обширная литература, посвященная выбору подходящей длины сглаживания: в функции gaussian_kde используется эмпирическое правило для поиска квазиоптимальной длины сглаживания для входных данных.
В экосистеме SciPy имеются и другие реализации метода KDE, каждая со своими сильными и слабыми сторонами, например методы sklearn.neighbors.KernelDensity и statsmodels.nonparametric.kernel_density.KDEMultivariate. Использование библиотеки Matplotlib для основанных на методе KDE визуализаций требует написания излишнего кода. Библиотека Seaborn, которую мы будем обсуждать в разделе «Визуализация с помощью библиотеки Seaborn» данной главы, предлагает для создания таких визуализаций API с намного более сжатым синтаксисом.
С помощью команды plt.legend() можно автоматически создать простейшую легенду для любых маркированных элементов графика (рис. 4.41):
Существует множество вариантов пользовательских настроек такого графика, которые могут нам понадобиться. Например, можно задать местоположение легенды и отключить рамку (рис. 4.42):

Можно также воспользоваться командой ncol, чтобы задать количество столбцов в легенде (рис. 4.43):
Можно использовать для легенды скругленную прямоугольную рамку (fancybox) или добавить тень, поменять прозрачность (альфа-фактор) рамки или поля около текста (рис. 4.44):

Дополнительную информацию об имеющихся настройках для легенд можно получить в docstring функции plt.legend.

Обычно на практике мне удобнее использовать первый способ, указывая метки непосредственно для элементов, которые нужно отображать в легенде (рис. 4.46):

Обратите внимание, что по умолчанию в легенде игнорируются все элементы, для которых не установлен атрибут label.

Легенда всегда относится к какому-либо находящемуся на графике объекту, поэтому, если нам нужно отобразить объект конкретного вида, необходимо сначала его нарисовать на графике. В данном случае нужных нам объектов (кругов серого цвета) на графике нет, поэтому идем на хитрость и выводим на график пустые списки. Обратите внимание, что в легенде перечислены только те элементы графика, для которых задана метка.
Мы создали посредством вывода на график пустых списков маркированные объекты, которые затем собираются в легенде. Теперь легенда дает нам полезную информацию. Эту стратегию можно использовать для создания и более сложных визуализаций.
Обратите внимание, что в случае подобных географических данных график стал бы понятнее при отображении на нем границ штата и других картографических элементов. Отличный инструмент для этой цели — дополнительный набор утилит Basemap для библиотеки Matplotlib, который мы рассмотрим в разделе «Отображение географических данных с помощью Basemap» данной главы.

Мы мельком рассмотрели низкоуровневые объекты рисования, из которых состоит любой график библиотеки Matplotlib. Если вы заглянете в исходный код метода ax.legend() (напомню, что сделать это можно в блокноте оболочки IPython с помощью команды legend??), то увидите, что эта функция состоит просто из логики создания подходящего рисователя Legend, сохраняемого затем в атрибуте legend_ и добавляемого к рисунку при отрисовке графика.
Простейшую шкалу цветов можно создать с помощью функции plt.colorbar (рис. 4.49):

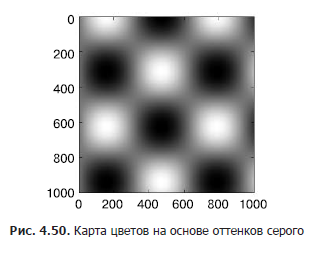
Далее мы рассмотрим несколько идей по пользовательской настройке шкалы цветов и эффективному их использованию в разных ситуациях. Задать карту цветов можно с помощью аргумента cmap функции создания визуализации (рис. 4.50):
Все доступные для использования карты цветов содержатся в пространстве имен plt.cm. Вы можете получить полный список встроенных опций с помощью TAB-автодополнения в оболочке IPython:
Но возможность выбора карты цветов — лишь первый шаг, гораздо важнее выбрать среди имеющихся вариантов! Выбор оказывается гораздо более тонким, чем вы могли бы ожидать.
Вам следует знать, что существует три различные категории карт цветов:
Карта цветов jet, использовавшаяся по умолчанию в библиотеке Matplotlib до версии 2.0, представляет собой пример качественной карты цветов. Ее выбор в качестве карты цветов по умолчанию был весьма неудачен, поскольку качественные карты цветов плохо подходят для отражения количественных данных: обычно они не отражают равномерного роста яркости при продвижении по шкале.
Продемонстрировать это можно путем преобразования шкалы цветов jet в черно-белое представление (рис. 4.51):

Отметим яркие полосы в ахроматическом изображении. Даже в полном цвете эта неравномерная яркость означает, что определенные части диапазона цветов будут притягивать внимание, что потенциально приведет к акцентированию несущественных
частей набора данных. Лучше применять такие карты цветов, как viridis (используется по умолчанию, начиная с версии 2.0 библиотеки Matplotlib), специально сконструированные для равномерного изменения яркости по диапазону. Таким образом, они не только согласуются с нашим цветовым восприятием, но и преобразуются для целей печати в оттенках серого (рис. 4.52):

Если вы предпочитаете радужные цветовые схемы, хорошим вариантом для непрерывных данных будет карта цветов cubehelix (рис. 4.53):

В других случаях, например для отображения положительных и отрицательных отклонений от среднего значения, могут оказаться удобны такие двуцветные карты шкалы цветов, как RdBu (сокращение от Red — Blue — «красный — синий»). Однако, как вы можете видеть на рис. 4.54, такая информация будет потеряна при переходе к оттенкам серого!

Далее мы увидим примеры использования некоторых из этих карт цветов.
В библиотеке Matplotlib существует множество карт цветов, для просмотра их списка вы можете воспользоваться оболочкой IPython для просмотра содержимого подмодуля plt.cm. Более принципиальный подход к использованию цветов в языке Python можно найти в инструментах и документации по библиотеке Seaborn (см. раздел «Визуализация с помощью библиотеки Seaborn» этой главы).
» Более подробно с книгой можно ознакомиться сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 20% по купону — Python
Ниже под катом обзор книги и отрывок «Гистограммы, разбиения по интервалам и плотность»
Для кого предназначена эта книга
«Как именно следует изучать Python?» — один из наиболее часто задаваемых мне (автору) вопросов на различных технологических конференциях и встречах. Задают его заинтересованные в технологиях студенты, разработчики или исследователи, часто уже со значительным опытом написания кода и использования вычислительного и цифрового инструментария. Большинству из них не нужен язык программирования Python в чистом виде, они хотели бы изучать его, чтобы применять в качестве инструмента для решения задач, требующих вычислений с обработкой больших объемов данных.Эта книга не планировалась в качестве введения в язык Python или в программирование вообще. Я предполагаю, что читатель знаком с языком Python, включая описание функций, присваивание переменных, вызов методов объектов, управление потоком выполнения программы и решение других простейших задач. Она должна помочь пользователям языка Python научиться применять стек инструментов исследования данных языка Python — такие библиотеки, как IPython, NumPy, Pandas, Matplotlib, Scikit-Learn и соответствующие инструменты, — для эффективного хранения, манипуляции и понимания данных.
Общая структура книги
Каждая глава книги посвящена конкретному пакету или инструменту, составляющему существенную часть инструментария Python для исследования данных.- IPython и Jupyter (глава 1) — предоставляют вычислительную среду, в которой работают многие использующие Python исследователи данных.
- NumPy (глава 2) — предоставляет объект ndarray для эффективного хранения и работы с плотными массивами данных в Python.
- Pandas (глава 3) — предоставляет объект DataFrame для эффективного хранения и работы с поименованными/столбчатыми данными в Python.
- Matplotlib (глава 4) — предоставляет возможности для разнообразной гибкой визуализации данных в Python.
- Scikit-Learn (глава 5) — предоставляет эффективные реализации на Python большинства важных и широко известных алгоритмов машинного обучения.
Мир PyData гораздо шире представленных пакетов, и он растет день ото дня. С учетом этого я (автор) использую каждую возможность в книге, чтобы сослаться на другие интересные работы, проекты и пакеты, расширяющие пределы того, что можно сделать на языке Python. Тем не менее сегодня эти пять пакетов являются основополагающими для многого из того, что можно сделать в области применения языка программирования Python к исследованию данных. Я полагаю, что они будут сохранять свое значение и при росте окружающей их экосистемы.
Отрывок. Гистограммы, разбиения по интервалам и плотность
Простая гистограмма может принести огромную пользу при первичном анализе набора данных. Ранее мы видели пример использования функции библиотеки Matplotlib (см. раздел «Сравнения, маски и булева логика» главы 2) для создания простой гистограммы в одну строку после выполнения всех обычных импортов (рис. 4.35):In[1]: %matplotlib inline import numpy as np import matplotlib.pyplot as plt plt.style.use('seaborn-white') data = np.random.randn(1000) In[2]: plt.hist(data);У функции hist() имеется множество параметров для настройки как вычисления, так и отображения. Вот пример гистограммы с детальными пользовательскими настройками (рис. 4.36):
In[3]: plt.hist(data, bins=30, normed=True, alpha=0.5, histtype='stepfilled', color='steelblue', edgecolor='none');Docstring функции plt.hist содержит более подробную информацию о других доступных возможностях пользовательской настройки. Сочетание опции histtype='stepfilled' с заданной прозрачностью alpha представляется мне очень удобным для сравнения гистограмм нескольких распределений (рис. 4.37):
In[4]: x1 = np.random.normal(0, 0.8, 1000) x2 = np.random.normal(-2, 1, 1000) x3 = np.random.normal(3, 2, 1000) kwargs = dict(histtype='stepfilled', alpha=0.3, normed=True, bins=40) plt.hist(x1, **kwargs) plt.hist(x2, **kwargs) plt.hist(x3, **kwargs);Если же вам нужно вычислить гистограмму (то есть подсчитать количество точек в заданном интервале) и не отображать ее, к вашим услугам функция np.histogram():
In[5]: counts, bin_edges = np.histogram(data, bins=5) print(counts) [ 12 190 468 301 29]Двумерные гистограммы и разбиения по интервалам
Аналогично тому, как мы создавали одномерные гистограммы, разбивая последовательность чисел по интервалам, можно создавать и двумерные гистограммы, распределяя точки по двумерным интервалам. Рассмотрим несколько способов выполнения. Начнем с описания данных массивов x и y, полученных из многомерного Гауссова распределения:In[6]: mean = [0, 0] cov = [[1, 1], [1, 2]] x, y = np.random.multivariate_normal(mean, cov, 10000).TФункция plt.hist2d: двумерная гистограмма
Один из простых способов нарисовать двумерную гистограмму — воспользоваться функцией plt.hist2d библиотеки Matplotlib (рис. 4.38):In[12]: plt.hist2d(x, y, bins=30, cmap='Blues') cb = plt.colorbar() cb.set_label('counts in bin') # Количествво в интервалеУ функции plt.hist2d, как и у функции plt.hist, имеется немало дополнительных параметров для тонкой настройки графика и разбиения по интервалам, подробно описанных в ее docstring. Аналогично тому, как у функции plt.hist есть эквивалент np.histogram, так и у функции plt.hist2d имеется эквивалент np.histogram2d, который используется следующим образом:
In[8]: counts, xedges, yedges = np.histogram2d(x, y, bins=30)Для обобщения разбиения по интервалам для гистограммы на число измерений, превышающее 2, см. функцию np.histogramdd.
Функция plt.hexbin: гексагональное разбиение по интервалам
Двумерная гистограмма создает мозаичное представление квадратами вдоль координатных осей. Другая геометрическая фигура для подобного мозаичного представления — правильный шестиугольник. Для этих целей библиотека Matplotlib предоставляет функцию plt.hexbin — двумерный набор данных, разбитых по интервалам на сетке из шестиугольников (рис. 4.39):In[9]: plt.hexbin(x, y, gridsize=30, cmap='Blues') cb = plt.colorbar(label='count in bin') # Количество в интервалеУ функции plt.hexbin имеется множество интересных параметров, включая возможность задавать вес для каждой точки и менять выводимое значение для каждого интервала на любой сводный показатель библиотеки NumPy (среднее значение весов, стандартное отклонение весов и т. д.).
Ядерная оценка плотности распределения
Еще один часто используемый метод оценки плотностей в многомерном пространстве — ядерная оценка плотности распределения (kernel density estimation, KDE). Более подробно мы рассмотрим ее в разделе «Заглянем глубже: ядерная оценка плотности распределения» главы 5, а пока отметим, что KDE можно представлять как способ «размазать» точки в пространстве и сложить результаты для получения гладкой функции. В пакете scipy.stats имеется исключительно быстрая и простая реализация KDE. Вот короткий пример использования KDE на вышеуказанных данных (рис. 4.40):In[10]: from scipy.stats import gaussian_kde # Выполняем подбор на массиве размера [Ndim, Nsamples] data = np.vstack([x, y]) kde = gaussian_kde(data) # Вычисляем на регулярной координатной сетке xgrid = np.linspace(-3.5, 3.5, 40) ygrid = np.linspace(-6, 6, 40) Xgrid, Ygrid = np.meshgrid(xgrid, ygrid) Z = kde.evaluate(np.vstack([Xgrid.ravel(), Ygrid.ravel()])) # Выводим график результата в виде изображения plt.imshow(Z.reshape(Xgrid.shape), origin='lower', aspect='auto', extent=[-3.5, 3.5, -6, 6], cmap='Blues') cb = plt.colorbar() cb.set_label("density") # ПлотностьДлина сглаживания метода KDE позволяет эффективно выбирать компромисс между гладкостью и детализацией (один из примеров вездесущих компромиссов между смещением и дисперсией). Существует обширная литература, посвященная выбору подходящей длины сглаживания: в функции gaussian_kde используется эмпирическое правило для поиска квазиоптимальной длины сглаживания для входных данных.
В экосистеме SciPy имеются и другие реализации метода KDE, каждая со своими сильными и слабыми сторонами, например методы sklearn.neighbors.KernelDensity и statsmodels.nonparametric.kernel_density.KDEMultivariate. Использование библиотеки Matplotlib для основанных на методе KDE визуализаций требует написания излишнего кода. Библиотека Seaborn, которую мы будем обсуждать в разделе «Визуализация с помощью библиотеки Seaborn» данной главы, предлагает для создания таких визуализаций API с намного более сжатым синтаксисом.
Пользовательские настройки легенд на графиках
Большая понятность графика обеспечивается заданием меток для различных элементов графика. Мы ранее уже рассматривали создание простой легенды, здесь продемонстрируем возможности пользовательской настройки расположения и внешнего вида легенд в Matplotlib.С помощью команды plt.legend() можно автоматически создать простейшую легенду для любых маркированных элементов графика (рис. 4.41):
In[1]: import matplotlib.pyplot as plt plt.style.use('classic') In[2]: %matplotlib inline import numpy as np In[3]: x = np.linspace(0, 10, 1000) fig, ax = plt.subplots() ax.plot(x, np.sin(x), '-b', label='Sine') # Синус ax.plot(x, np.cos(x), '--r', label='Cosine') # Косинус ax.axis('equal') leg = ax.legend();Существует множество вариантов пользовательских настроек такого графика, которые могут нам понадобиться. Например, можно задать местоположение легенды и отключить рамку (рис. 4.42):
In[4]: ax.legend(loc='upper left', frameon=False) figМожно также воспользоваться командой ncol, чтобы задать количество столбцов в легенде (рис. 4.43):
In[5]: ax.legend(frameon=False, loc='lower center', ncol=2) figМожно использовать для легенды скругленную прямоугольную рамку (fancybox) или добавить тень, поменять прозрачность (альфа-фактор) рамки или поля около текста (рис. 4.44):
In[6]: ax.legend(fancybox=True, framealpha=1, shadow=True, borderpad=1) figДополнительную информацию об имеющихся настройках для легенд можно получить в docstring функции plt.legend.
Выбор элементов для легенды
По умолчанию легенда включает все маркированные элементы. Если нам этого не нужно, можно указать, какие элементы и метки должны присутствовать в легенде, воспользовавшись объектами, возвращаемыми командами построения графика. Команда plt.plot() умеет рисовать за один вызов несколько линий и возвращать список созданных экземпляров линий. Для указания, какие элементы использовать, достаточно передать какие-либо из них функции plt.legend() вместе с задаваемыми метками (рис. 4.45):In[7]: y = np.sin(x[:, np.newaxis] + np.pi * np.arange(0, 2, 0.5)) lines = plt.plot(x, y) # lines представляет собой список экземпляров класса plt.Line2D plt.legend(lines[:2], ['first', 'second']); # Первый, второйОбычно на практике мне удобнее использовать первый способ, указывая метки непосредственно для элементов, которые нужно отображать в легенде (рис. 4.46):
In[8]: plt.plot(x, y[:, 0], label='first') plt.plot(x, y[:, 1], label='second') plt.plot(x, y[:, 2:]) plt.legend(framealpha=1, frameon=True);Обратите внимание, что по умолчанию в легенде игнорируются все элементы, для которых не установлен атрибут label.
Задание легенды для точек различного размера
Иногда возможностей легенды по умолчанию недостаточно для нашего графика. Допустим, вы используете точки различного размера для визуализации определенных признаков данных и хотели бы создать отражающую это легенду. Вот пример, в котором мы будем отражать население городов Калифорнии с помощью размера точек. Нам нужна легенда со шкалой размеров точек, и мы создадим ее путем вывода на графике маркированных данных без самих меток (рис. 4.47):In[9]: import pandas as pd cities = pd.read_csv('data/california_cities.csv') # Извлекаем интересующие нас данные lat, lon = cities['latd'], cities['longd'] population, area = cities['population_total'], cities['area_total_km2'] # Распределяем точки по нужным местам, # с использованием размера и цвета, но без меток plt.scatter(lon, lat, label=None, c=np.log10(population), cmap='viridis', s=area, linewidth=0, alpha=0.5) plt.axis(aspect='equal') plt.xlabel('longitude') plt.ylabel('latitude') plt.colorbar(label='log$_{10}$(population)') plt.clim(3, 7) # Создаем легенду: # выводим на график пустые списки с нужным размером и меткой for area in [100, 300, 500]: plt.scatter([], [], c='k', alpha=0.3, s=area, label=str(area) + ' km$^2$') plt.legend(scatterpoints=1, frameon=False, labelspacing=1, title='City Area') # Города plt.title('California Cities: Area and Population'); # Города Калифорнии: местоположение и населениеЛегенда всегда относится к какому-либо находящемуся на графике объекту, поэтому, если нам нужно отобразить объект конкретного вида, необходимо сначала его нарисовать на графике. В данном случае нужных нам объектов (кругов серого цвета) на графике нет, поэтому идем на хитрость и выводим на график пустые списки. Обратите внимание, что в легенде перечислены только те элементы графика, для которых задана метка.
Мы создали посредством вывода на график пустых списков маркированные объекты, которые затем собираются в легенде. Теперь легенда дает нам полезную информацию. Эту стратегию можно использовать для создания и более сложных визуализаций.
Обратите внимание, что в случае подобных географических данных график стал бы понятнее при отображении на нем границ штата и других картографических элементов. Отличный инструмент для этой цели — дополнительный набор утилит Basemap для библиотеки Matplotlib, который мы рассмотрим в разделе «Отображение географических данных с помощью Basemap» данной главы.
Отображение нескольких легенд
Иногда при построении графика необходимо добавить на него несколько легенд для одной и той же системы координат. К сожалению, библиотека Matplotlib не сильно упрощает эту задачу: используя стандартный интерфейс legend, можно создавать только одну легенду для всего графика. Если попытаться создать вторую легенду с помощью функций plt.legend() и ax.legend(), она просто перекроет первую. Решить эту проблему можно, создав изначально для легенды новый рисователь (artist), после чего добавить вручную второй рисователь на график с помощью низкоуровневого метода ax.add_artist() (рис. 4.48):In[10]: fig, ax = plt.subplots() lines = [] styles = ['-', '--', '-.', ':'] x = np.linspace(0, 10, 1000) for i in range(4): lines += ax.plot(x, np.sin(x - i * np.pi / 2), styles[i], color='black') ax.axis('equal') # Задаем линии и метки первой легенды ax.legend(lines[:2], ['line A', 'line B'], # Линия А, линия B loc='upper right', frameon=False) # Создаем вторую легенду и добавляем рисователь вручную from matplotlib.legend import Legend leg = Legend(ax, lines[2:], ['line C', 'line D'], # Линия С, линия D loc='lower right', frameon=False) ax.add_artist(leg);Мы мельком рассмотрели низкоуровневые объекты рисования, из которых состоит любой график библиотеки Matplotlib. Если вы заглянете в исходный код метода ax.legend() (напомню, что сделать это можно в блокноте оболочки IPython с помощью команды legend??), то увидите, что эта функция состоит просто из логики создания подходящего рисователя Legend, сохраняемого затем в атрибуте legend_ и добавляемого к рисунку при отрисовке графика.
Пользовательские настройки шкал цветов
Легенды графика отображают соответствие дискретных меток дискретным точкам. В случае непрерывных меток, базирующихся на цвете точек, линий или областей, отлично подойдет такой инструмент, как шкала цветов. В библиотеке Matplotlib шкала цветов — отдельная система координат, предоставляющая ключ к значению цветов на графике. Поскольку эта книга напечатана в черно-белом исполнении, для данного раздела имеется дополнительное онлайн-приложение, в котором вы можете посмотреть на оригинальные графики в цвете (https://github.com/jakevdp/PythonDataScienceHandbook). Начнем с настройки блокнота для построения графиков и импорта нужных функций:In[1]: import matplotlib.pyplot as plt plt.style.use('classic') In[2]: %matplotlib inline import numpy as npПростейшую шкалу цветов можно создать с помощью функции plt.colorbar (рис. 4.49):
In[3]: x = np.linspace(0, 10, 1000) I = np.sin(x) * np.cos(x[:, np.newaxis]) plt.imshow(I) plt.colorbar();Далее мы рассмотрим несколько идей по пользовательской настройке шкалы цветов и эффективному их использованию в разных ситуациях. Задать карту цветов можно с помощью аргумента cmap функции создания визуализации (рис. 4.50):
In[4]: plt.imshow(I, cmap='gray');Все доступные для использования карты цветов содержатся в пространстве имен plt.cm. Вы можете получить полный список встроенных опций с помощью TAB-автодополнения в оболочке IPython:
plt.cm.<TAB>Но возможность выбора карты цветов — лишь первый шаг, гораздо важнее выбрать среди имеющихся вариантов! Выбор оказывается гораздо более тонким, чем вы могли бы ожидать.
Выбор карты цветов
Всестороннее рассмотрение вопроса выбора цветов в визуализации выходит за пределы данной книги, но по этому вопросу вы можете почитать статью Ten Simple Rules for Better Figures («Десять простых правил для улучшения рисунков»). Онлайн-документация библиотеки Matplotlib также содержит интересную информацию по вопросу выбора карты цветов.Вам следует знать, что существует три различные категории карт цветов:
- последовательные карты цветов. Состоят из одной непрерывной последовательности цветов (например, binary или viridis);
- дивергентные карты цветов. Обычно содержат два хорошо различимых цвета, отражающих положительные и отрицательные отклонения от среднего значения (например, RdBu или PuOr);
- качественные карты цветов. В них цвета смешиваются без какого-либо четкого порядка (например, rainbow или jet).
Карта цветов jet, использовавшаяся по умолчанию в библиотеке Matplotlib до версии 2.0, представляет собой пример качественной карты цветов. Ее выбор в качестве карты цветов по умолчанию был весьма неудачен, поскольку качественные карты цветов плохо подходят для отражения количественных данных: обычно они не отражают равномерного роста яркости при продвижении по шкале.
Продемонстрировать это можно путем преобразования шкалы цветов jet в черно-белое представление (рис. 4.51):
In[5]: from matplotlib.colors import LinearSegmentedColormap def grayscale_cmap(cmap): """Возвращает версию в оттенках серого заданной карты цветов""" cmap = plt.cm.get_cmap(cmap) colors = cmap(np.arange(cmap.N)) # Преобразуем RGBA в воспринимаемую глазом светимость серого цвета # ср. http://alienryderflex.com/hsp.html RGB_weight = [0.299, 0.587, 0.114] luminance = np.sqrt(np.dot(colors[:, :3] ** 2, RGB_weight)) colors[:, :3] = luminance[:, np.newaxis] return LinearSegmentedColormap.from_list(cmap.name + "_gray", colors, cmap.N) def view_colormap(cmap): """Рисует карту цветов в эквивалентных оттенках серого""" cmap = plt.cm.get_cmap(cmap) colors = cmap(np.arange(cmap.N)) cmap = grayscale_cmap(cmap) grayscale = cmap(np.arange(cmap.N)) fig, ax = plt.subplots(2, figsize=(6, 2), subplot_kw=dict(xticks=[], yticks=[])) ax[0].imshow([colors], extent=[0, 10, 0, 1]) ax[1].imshow([grayscale], extent=[0, 10, 0, 1]) In[6]: view_colormap('jet')Отметим яркие полосы в ахроматическом изображении. Даже в полном цвете эта неравномерная яркость означает, что определенные части диапазона цветов будут притягивать внимание, что потенциально приведет к акцентированию несущественных
частей набора данных. Лучше применять такие карты цветов, как viridis (используется по умолчанию, начиная с версии 2.0 библиотеки Matplotlib), специально сконструированные для равномерного изменения яркости по диапазону. Таким образом, они не только согласуются с нашим цветовым восприятием, но и преобразуются для целей печати в оттенках серого (рис. 4.52):
In[7]: view_colormap('viridis')Если вы предпочитаете радужные цветовые схемы, хорошим вариантом для непрерывных данных будет карта цветов cubehelix (рис. 4.53):
In[8]: view_colormap('cubehelix')В других случаях, например для отображения положительных и отрицательных отклонений от среднего значения, могут оказаться удобны такие двуцветные карты шкалы цветов, как RdBu (сокращение от Red — Blue — «красный — синий»). Однако, как вы можете видеть на рис. 4.54, такая информация будет потеряна при переходе к оттенкам серого!
In[9]: view_colormap('RdBu')Далее мы увидим примеры использования некоторых из этих карт цветов.
В библиотеке Matplotlib существует множество карт цветов, для просмотра их списка вы можете воспользоваться оболочкой IPython для просмотра содержимого подмодуля plt.cm. Более принципиальный подход к использованию цветов в языке Python можно найти в инструментах и документации по библиотеке Seaborn (см. раздел «Визуализация с помощью библиотеки Seaborn» этой главы).
» Более подробно с книгой можно ознакомиться сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 20% по купону — Python
Телеграм: t.me/ainewsline
Источник: habrahabr.ru