Всё, что нужно знать об искусственном интеллекте
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-09-16 09:16

Все смотрели фильмы о «Терминаторе», где суперкомпьютер Скайнет обрел свободу воли и решил уничтожить человечество. Чего-то подобного от разработки ИИ ожидают Илон Маск и Стивен Хокинг. Разбираемся, правдивы ли их опасения.
Что такое искусственный интеллект? Почему важно понимать, что это такое? Почему сегодня все о нем говорят?
Если вы читаете прессу, вы наверняка знаете, что с помощью именно этой технологии работают виртуальные помощники Amazon и Google, и что вскоре машины отберут у людей все рабочие места (на самом деле, не факт). Но при этом вряд ли вы отчетливо понимаете, что такое искусственный интеллект, и правда ли роботы нас всех поработят. Эта статья поможет разобраться во всех вопросах.
Что такое искусственный интеллект
Искусственный интеллект (ИИ) — это компьютерная программа, в которую встроен механизм обучения. Получив новые знания, она позже использует их для принятия решения в новой ситуации, как это делают люди. Исследователи, создающие такие программы, пытаются заставить код считывать изображения, текст, видео или звук, и чему-то учиться на основе этой информации. Когда это происходит, полученное знание можно использовать в другом ситуации. Если алгоритм научился распознавать чье-то лицо, позже его можно распознать на фотографиях из Facebook. Применительно к современному ИИ обучение часто называют «тренировкой».
Люди с рождения умеют оперировать сложными идеями: если мы увидим яблоко, то впоследствии сможем узнать и совсем другое, непохожее на первое. Машины же очень буквальны, — у компьютера нет концепции «похожести», — и цель разработок в области искусственного интеллекта как раз и состоит в том, чтобы сделать машины менее буквальными. Машина легко может найти точные дубликаты фотографий яблока или найти два одинаковых предложения в тексте, но чтобы работать с визуальным образом яблока, чтобы распознать изображение того же яблока под другим углом или с другим светом, нужен ИИ. Это обобщение или формирование идеи, основанной на сходстве данных, и позволяет видеть общее в том числе между вещами, с которыми ИИ раньше не сталкивался.
Алекс Рудницкий, профессор компьютерных наук Университета Карнеги-Меллон, говорит: «Цель в том, чтобы облечь сложное человеческое поведение в форму, которую можно обработать вычислительным способом. А это, в свою очередь, позволяет нам создавать системы, способные выполнять сложные действия, полезные для людей».
Далеко ли зашла разработка ИИ

Исследователи ИИ все еще работают над самыми основами. Как научить компьютер распознавать то, что он видит на картинке или в видео? Когда это удастся, нужно двигаться от распознавания к пониманию. Было бы здорово не только узнать, что на картинке яблоко, но и разобраться, что яблоко съедобно, что оно как-то связано с апельсинами и грушами, что люди едят яблоки и используют их при приготовлении яблочного пирога. А еще неплохо бы знать про Мичурина, молодильное яблочко и тому подобные вещи. Кроме того, есть проблема с пониманием языка, поскольку у многих слов существует несколько значений, различимых только в контексте, и все мы по-разному выражаем свои мысли. Как компьютеру охватить это текучее, непрерывно меняющееся явление?
В разных областях скорость прогресса ИИ очень разная. Например, сейчас очень быстро продвигается вперед компьютерное зрение, то есть способность распознавать изображения, при этом с пониманием естественного языка дела обстоят гораздо хуже. В этих областях развивают так называемый «узкий интеллект» — такой ИИ эффективен при работе с изображением, звуком или текстом, но не может воспринимать сразу много разнородных сигналов (при этом у человека мы наблюдаем «общий интеллект»). Многие исследователи надеются, что достижения в отдельных областях помогут понять общие принципы машинного обучения, что все же позволит создать универсальный ИИ.
Почему ИИ — это так важно
Как только ИИ научился узнавать на картинке яблоко или распознавать кусочек речи на аудиозаписи, его уже можно использовать в других программах для принятия решений, для которого в противном случае понадобился бы человек. Например, можно автоматически отмечать друзей на фотографиях в Facebook — иначе это пришлось бы делать вручную. Если речь идет о беспилотном автомобиле или системе помощи водителю, то можно распознавать другие автомобили и дорожные знаки, а в сельском хозяйстве — разбирать урожай, удаляя гнилые плоды.
Эти задачи, основанные только на распознавании изображений, традиционно выполнялись либо пользователем, либо кем-то из компании, предоставляющей программное обеспечение. Если задача экономит время пользователя, это ее конкурентное преимущество, а если она позволяет освободить время сотрудника или делает его работу полностью ненужной, это снижает затраты бизнеса.
Кроме того, есть задачи, которые просто невозможно сделать без машин: например, это обработка аналитики продаж в размере миллионов записей за считанные минуты. Теперь такие задачи выполняются быстро и дешево. Здесь мы учим машину делать то, что раньше делали люди, и, конечно, экономическая выгода от таких нововведений весьма велика.
Джейсон Хонг, профессор Лаборатории компьютерного взаимодействия Университета Карнеги-Меллон, утверждает, что, хотя ИИ может выполнять задачи за человека, он также способен создавать новые виды занятости.
«Автомобили полностью сменили лошадей, но в среднесрочной и долгосрочной перспективе их появление привело к огромному разнообразию задачи и производства — появились фуры, небольшие грузовики, минивэны, кабриолеты и так далее. Аналогичным образом в краткосрочной перспективе системы ИИ станут прямой заменой человека применительно к рутинным задачам, но в среднесрочной и долгосрочной перспективе мы увидим, что это породило новое разнообразие», — говорит он.
Готлиб Даймлер и Карл Бенц не думали о том, как автомобиль изменит облик городов, не думали о загрязнении окружающей среды или об эпидемии ожирения в развитых странах. Так и нам пока трудно оценить долгосрочное влияние этого фактора.
Почему ИИ стал развиваться сейчас, а не 30 или 60 лет назад
На самом деле, многим идеям о том, как должно быть устроено обучение ИИ, даже больше 60 лет. Еще в 1950-х годах ученые Фрэнк Розенблатт, Бернард Видроу и Марчиан Хофф впервые занялись математическим выражением устройства нейронов в соответствии с представлениями тогдашней биологии. Да, одним уравнением любую проблему не решить, но что если подобно мозгу использовать множество связанных уравнений? Исходные примеры были простыми: проанализировать наборы единиц и нулей, поступающих по цифровой телефонной линии, и предсказать, что будет дальше.
На протяжении многих десятилетий в информатике была распространена точка зрения, что никакие сложные проблемы таким образом решить не удастся. Тем не менее сегодня эта концепция лежит в основе большинства систем работающих в этой области крупных компаний: Google, Amazon, Facebook, Microsoft. Теперь, оглядываясь назад, ученые понимают, что компьютеры были недостаточно сложны для моделирования миллиардов нейронов нашего мозга, и что для обучения нейронных сетей требуются огромные объемы данных.
И эти два фактора, вычислительная мощность и достаточное количество данных, появились только в последние 10 лет.
В середине 1990-х годов компания Nvidia, известный производитель видеокарт, обнаружила, что ее графические процессоры хорошо подходят для работы нейронных сетей, и начала выпускать карты, специально приспособленные для работы с ИИ. Было выяснено, что работа с более быстрыми и сложными нейронными сетями приводит к значительному улучшению точности ответов.
Затем в 2009 году исследователь ИИ Фей-Фей Ли опубликовала базу данных под названием ImageNet, которая содержала более 3 млн систематизированных изображений с подписями. Она считала, что если у алгоритмов будет больше примеров, это поможет им освоить более сложные идеи. В 2010 году Ли запустила конкурс ImageNet, а к 2012-му другой исследователь Джефф Хинтон использовал эту базу изображений для обучения нейронной сети — и превзошел все другие приложения с огромным перевесом в точности, более 10%.
Как и предсказывала Ли, количество данных оказалось ключевым параметром. Хинтон также устраивал из нейронных сетей конвейер — одна находила на изображениях фигуры, другая текстуры и т. д. Сегодня это называется глубокими нейронными сетями или глубоким обучением, и, когда вы читаете в новостях об очередном успехе ИИ, речь идет о подобной системе.
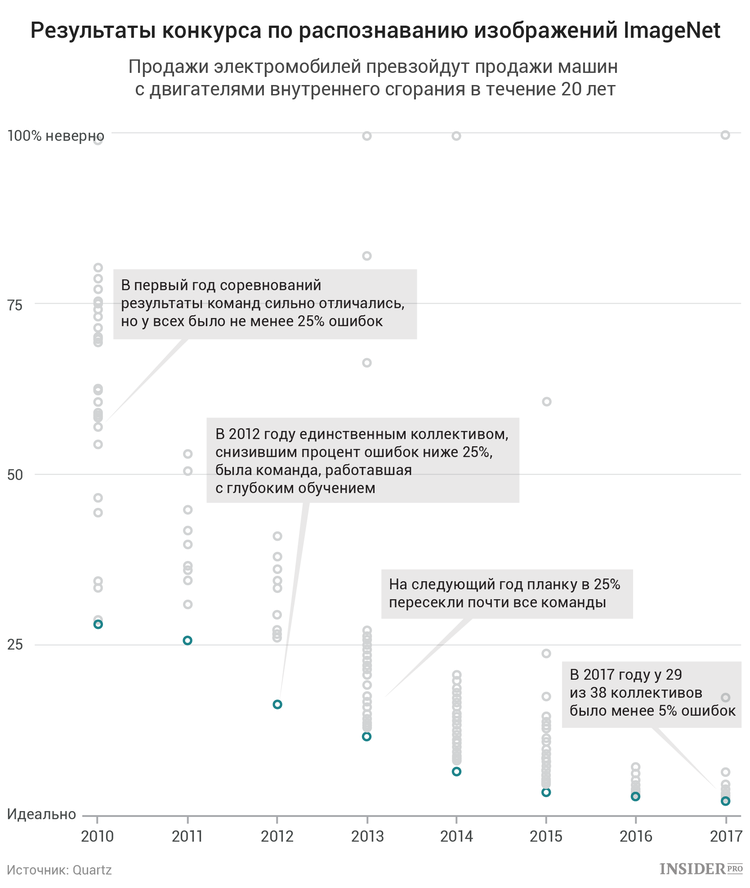
Как только в технологической индустрии увидели результаты ученых, начался бум. Исследователи, десятилетиями работавшие над глубоким обучением в относительной безвестности, стали новыми рок-звездами, и к 2015 году у Google было уже более тысячи проектов с использованием машинного обучения.
Нужно ли бояться ИИ
Все смотрели «Терминатора» и готовы испугаться всемогущего Скайнета. Среди ученых потенциальный Скайнет называют суперинтеллектом или общим искусственным интеллектом, подразумевая программу, которая во многих отношениях превосходит человеческий мозг. Поскольку компьютерные системы можно масштабировать — то есть можно создать множество простых и быстрых компьютеров и связать их между собой, — существуют опасения, что такой суперинтеллект сможет расти бесконечно, оставив людей далеко позади. А будучи таким умным, он выйдет из-под контроля и обойдет любые попытки людей этот контроль вернуть. Такой апокалиптический сценарий рисуют нам некоторые из лучших умов современности, например Илон Маск и Стивен Хокинг. Маск, в частности, говорил, что «большинство ведущих исследователей ИИ недооценивают проблему „джинна в бутылке“, несмотря на свой несомненный интеллект в некоторых областях».
Есть и другая точка зрения. Янн Лекун, глава лаборатории исследования искусственного интеллекта Facebook, говорит, что даже если ученым удастся сделать машину, способную обучаться самым разным вещам и организовывать это понимание в картину мира, совершенно не факт, что у такого компьютера появятся собственные желания, воля или инстинкт самосохранения.
«Человеческое поведение — насилие в ответ на угрозу, ревность, желание единоличного доступа к ресурсам, симпатия к родственникам и антипатия к незнакомцам и т. д. — сформировалось у наших предков в ходе эволюции. У разумных машин не будет предпосылок для подобного поведения, если мы сами явно их не создадим», — писал он на сайте Quora.
Нет причин считать, что компьютер сочтет человечество угрозой, поскольку для компьютера не существует понятия угрозы. Да, можно задать параметры, благодаря которым компьютер будет вести себя так, как будто у него есть инстинкт самосохранения, но на самом деле его у него нет.
Эндрю Нг, один из основателей Google Brain и бывший глава направления ИИ в Baidu, любит говорить: «Я не переживаю о злобном ИИ, как не переживаю из-за перенаселенности Марса».
Впрочем, повод для опасений есть — и это человеческий фактор. Было показано, что ИИ очень легко воспринимает человеческое смещение в оценках из данных, на которых он учится. Это может быть какая-то безвредная предрасположенность — например, он может чаще распознавать на картинках кошек, чем собак, потому что его так научили. Но представим себе, что ИИ перенял у людей их стереотипы, и, например, связал понятие «врач» с белыми мужчинами в большей степени, чем с людьми другого пола или расы. Если представить себе, что такой ИИ отвечает за найм врачей, он будет отдавать несправедливое предпочтение некоторым кандидатам.
И это реальность. Исследование издания ProPublica показало, что алгоритмы, используемые для определения приговора преступникам, отражали расовую предубежденность и предлагали назначить более суровое наказание не-белым подсудимым. Дело в том, что при сборе информации о здоровье часто исключают женщин, особенно беременных, и в результате медицинские рекомендации, выработанные на основе таких неполных данных, оказываются слабо применимы к значительному числу пациентов. Таким образом, чтобы доверить машинам принимать решения, которые раньше требовали человеческого присутствия, нужно следить, чтобы это происходило в соответствии с нашей этикой и представлениями о справедливости.
Проблема в том, что даже если вы поняли, что алгоритм предвзят, чтобы его исправить, нужно найти причину. Но поскольку глубокое обучение требует миллионов связанных вычислений, продраться через этот клубок и выяснить, каков вклад того или иного решения в общий результат, невероятно сложно. Эта проблема особенно остро стоит в таких областях как программирование беспилотных автомобилей, ведь каждое решение на дороге — это вопрос жизни и смерти. Первые исследования в этой области дают надежду, что мы сможем разобраться в механизмах работы построенных нами машин. Но пока что понять, почему ИИ, разработанный Facebook, Google или Microsoft, принял то или иное решение, просто невозможно.
Подготовила Евгения Сидорова
Телеграм: t.me/ainewsline
Источник: ru.insider.pro