Три идеи, как повысить эффективность разработки: итоги хакатона по Machine Learning в СберТехе
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-09-21 19:02
Семинары, кластеризация данных, алгоритмы машинного обучения

Мы регулярно проводим внешние хакатоны на разные темы. Но этим летом мы решили дать возможность проявить себя и сотрудникам – ведь наверняка им хочется порешать задачки на имеющихся данных. Что получилось у коллег в СберТехе — рассказывает samorlov, главный руководитель разработки в Отделе разработки лабораторного кластера супермассивов.

Участникам предложили разработать решения на Machine Learning, которые помогали бы предсказывать сроки выполнения доработок и критичность багов. Эти решения могли бы повысить эффективность разработки в СберТехе, в том числе:
Лучшие идеи участников планируется внедрить в СберТехе уже в ближайшее время.
Мы прекрасно понимали, что нельзя создать промышленное решение за ограниченное время хакатона. Иллюзий никто не питал и было понятно, что решения будут во многом сырыми. Но зачем придумывать задания из воздуха, если у нас есть вполне определенные задачи? В итоге мы дали ребятам фан (и конечно, денежное вознаграждение), а взамен получили несколько интересных идей, которые можно брать в работу.
Исходные данные
Задача решалась на основе данных из Jira внутренней и внешней рабочих сетей, а также из ЦУП (внутренняя автоматизированная система по управлению проектами). Если дата-сеты из Jira представляли собой текстовые поля с историей и вложениями, то в ЦУП хранилась более специфичная информация, используемая для планирования изменений.
Дата-сеты были выложены на файловую шару с доступом для участников. Поскольку это хакатон, предполагалось, что они сами разберутся, как и с чем работать. Как и в реальной жизни :)
Железо
Если в знаниях и навыках коллег мы почти не сомневались, то мощность настольных компьютеров, мягко говоря, не запредельна. Поэтому дополнительно по запросу предоставлялся небольшой Hadoop-кластер. Конфигурация кластера (80 CPU, 200 ГБ, 1,5 ТБ) напоминает одноюнитовый сервер с упором на вычисления, но нет, это все-таки кластер, развернутый в Openstack-е.
Конечно, это небольшой стенд. Он предназначен для отработки решений и интеграции нашей Лаборатории Данных и представлял собой сильно уменьшенную копию промышленного. Но для хакатона его хватило.
В Лаборатории Данных был задействован JupyterHUB, создававший отдельные инстансы JupyterNotebook. А чтобы можно было работать с параллельными вычислениями, с помощью Cloudera parcels мы добавили в Jupyter несколько вариантов kernel-ов с разными наборами python-библиотек.
В итоге на входе мы получили независимую работу N пользователей с возможностью использовать нужные версии библиотек, никому не мешая. Кроме того, без особой головной боли можно было запустить параллельные вычисления (мы знаем, что существует Data Science Workbench от Cloudera, и уже пробуем с ним работать, но на момент проведения хакатона этот инструмент еще не был доступен).
В качестве исходных данных команда использовала отзывы клиентов мобильного приложения Сбербанк Онлайн из Google Play и AppStore, а также информацию о багах из Jira.
 Сначала участники решили проблему разбивки отзывов на положительные и отрицательные с помощью классификатора на основе дерева. Затем, используя негативные отзывы, выделили основные темы, вызвавшие недовольство пользователей. Это, например:
Сначала участники решили проблему разбивки отзывов на положительные и отрицательные с помощью классификатора на основе дерева. Затем, используя негативные отзывы, выделили основные темы, вызвавшие недовольство пользователей. Это, например:
В отдельную категорию попали люди, писавшие, что «все плохо».
С помощью агломеративной иерархической кластеризации команда разделила отзывы по клиентским проблемам (преимущество такого подхода — возможность добавления экспертного мнения, к примеру, когда отзывы о целях и вкладах можно отнести к одному кластеру). Так, например, один из выделенных кластеров объединил проблемы со входом на устройстве Asus Zenfone 2 (период между появлением первых отзывов о проблеме и регистрацией бага в Jira составил 16 дней).
 Участники предложили максимально сократить время реагирования на проблемы пользователей, сделав онлайн-обработку отзывов с автосозданием багов по выделенным кластерам, используя преимущество банка — большое количество неравнодушных клиентов (1500 отзывов в день). В ходе работы удалось добиться accuracy = 86% и precision = 88% при определении негативных отзывов.
Участники предложили максимально сократить время реагирования на проблемы пользователей, сделав онлайн-обработку отзывов с автосозданием багов по выделенным кластерам, используя преимущество банка — большое количество неравнодушных клиентов (1500 отзывов в день). В ходе работы удалось добиться accuracy = 86% и precision = 88% при определении негативных отзывов.
Еще одно решение команды — визуализация процессов в разработке. Кейс был разобран на примере Сбербанк Онлайн Android (ASBOL).
 Участники посчитали количество переходов статусов багов между членами команды и отрисовали их в виде графа. С этим инструментом проще принимать управленческие решения и равномерно распределять нагрузку внутри команды. Кроме того, наглядно видно, кто является ключевым участником команды и где есть узкие места проекта. На основе этой информации предлагается автоматически назначать баги на конкретных участников команды, учитывая их загрузку и критичность бага.
Участники посчитали количество переходов статусов багов между членами команды и отрисовали их в виде графа. С этим инструментом проще принимать управленческие решения и равномерно распределять нагрузку внутри команды. Кроме того, наглядно видно, кто является ключевым участником команды и где есть узкие места проекта. На основе этой информации предлагается автоматически назначать баги на конкретных участников команды, учитывая их загрузку и критичность бага.
Дополнительно участники попробовали разобрать проблему автоматической приоритизации багов с использованием логистической регрессии и наивного байесовского классификатора. Для этого была определена важность бага по его описанию, наличию вложений и другим характеристика. Однако модель показала результат accuracy = 54% при кросс-валидации на 3-х фолдах – на момент сдачи работ не пригодный для внедрения прототип.
По мнению участников команды, плюсы их моделей в простоте, хорошей интерпретации результата и быстрой работе. Это шаг к real-time обработке отзывов пользователей при помощи машинного обучения, позволяющий в реальном времени взаимодействовать с пользователями, выявлять и устранять проблемы, повышая лояльность клиентов.
Презентация команды
Задачи:
Антон работал с багами из Jira. Дата-сет включал информацию о более чем 67 000 багов в статусе «завершен» с 2011 по 2017 год. Поиск решения поставленных задач он вел с помощью библиотек языка Python и других ML-библиотек.
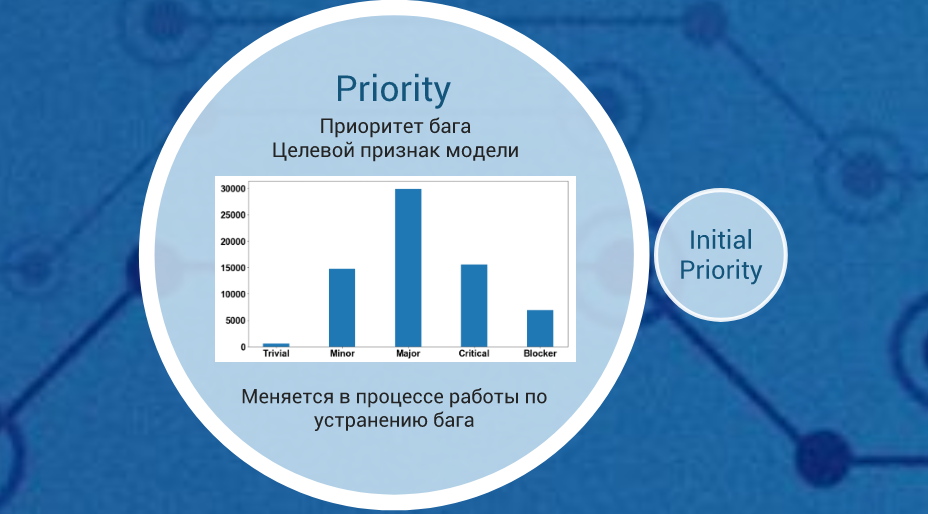 Антон проанализировал и отобрал признаки, влияющие на итоговый приоритет бага, и на их основе построил модель предсказания итогового приоритета. Кроме того, проведя анализ и поиск особенностей различных временных рядов, он построил модели прогноза числа багов. Предложенные решения будут полезны в тестировании.
Антон проанализировал и отобрал признаки, влияющие на итоговый приоритет бага, и на их основе построил модель предсказания итогового приоритета. Кроме того, проведя анализ и поиск особенностей различных временных рядов, он построил модели прогноза числа багов. Предложенные решения будут полезны в тестировании.
 В Agile результат предсказания количества дефектов по данной модели можно учитывать при планировании работ в будущих спринтах. Решение Антона поможет точнее определять время, необходимое на исправление проблем, что скажется на итоговой производительности.
В Agile результат предсказания количества дефектов по данной модели можно учитывать при планировании работ в будущих спринтах. Решение Антона поможет точнее определять время, необходимое на исправление проблем, что скажется на итоговой производительности.
Презентация участника
Цель: Создание системы прогнозирования на основе нейронной сети для минимизации рисков при управлении ИТ-проектами.
Из предложенных организаторами наборов исходных данных участник выбрал выгрузку списка задач из Jira. Задача — это отдельное задание на разработку компонента ПО. Каждая задача в процессе своего жизненного цикла проходит различные состояния: создание, разработка, различные виды тестирования и согласования, закрытие. Таких состояний может быть несколько десятков.
Николай построил и обучил нейронную сеть, способную предсказывать переходы задач в определенные состояния и прогнозировать даты этих событий, сообщать о возможных критических событиях или отклонениях от плановых значений — важных функциях для процесса управления.
 Для обучения нейронной сети Николай восстановил по журналу событий последовательность промежуточных состояний для каждой задачи. На вход нейронной сети было подано одно из промежуточных состояний задачи, на выход – конечное, таким образом сеть обучалась предсказывать события. Дополнительно для обучения использовались производные данные — например, таблица с временной разницей между всеми событиями в прошлом; учитывалась гипотеза о том, что задачи, по которым работы ведутся в выходные дни, могут быть проблемными.
Для обучения нейронной сети Николай восстановил по журналу событий последовательность промежуточных состояний для каждой задачи. На вход нейронной сети было подано одно из промежуточных состояний задачи, на выход – конечное, таким образом сеть обучалась предсказывать события. Дополнительно для обучения использовались производные данные — например, таблица с временной разницей между всеми событиями в прошлом; учитывалась гипотеза о том, что задачи, по которым работы ведутся в выходные дни, могут быть проблемными.
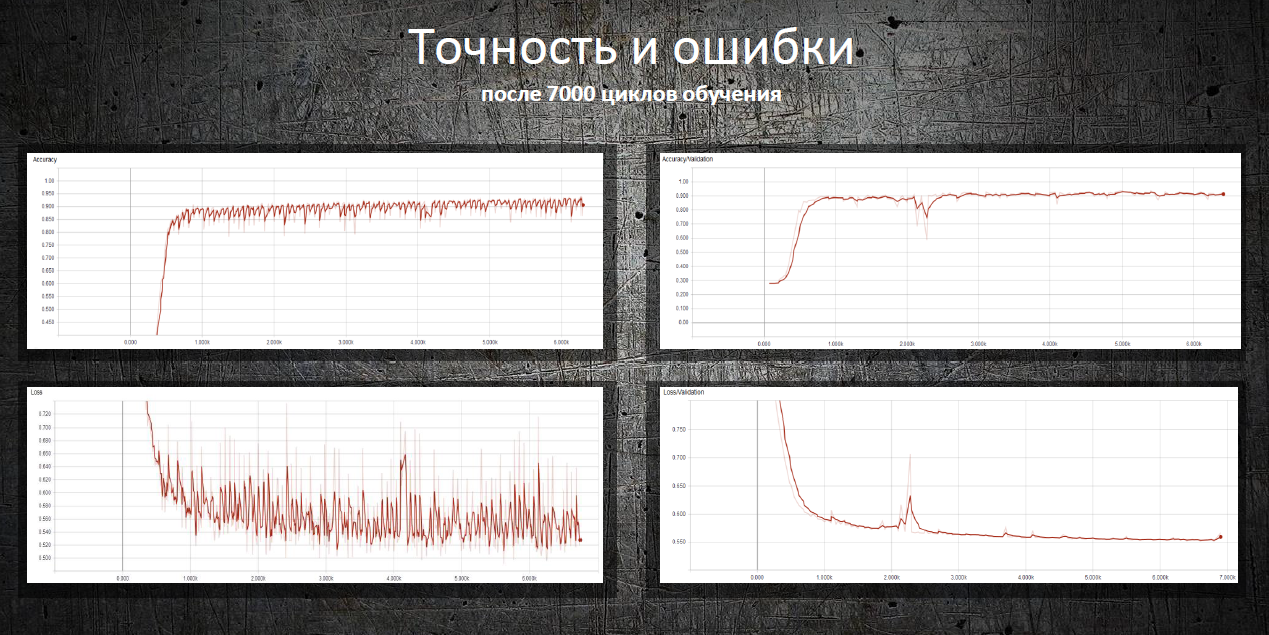
 Нейронная сеть предсказывает некоторые критические события с точностью 91-94%. Например, повторное открытие задачи. Дата закрытия задачи предсказывается с отклонением от 0 до 37 дней сразу после её создания. На более поздних этапах, когда проведены какие-либо работы по задаче, максимальное отклонение составляет не более недели.
Нейронная сеть предсказывает некоторые критические события с точностью 91-94%. Например, повторное открытие задачи. Дата закрытия задачи предсказывается с отклонением от 0 до 37 дней сразу после её создания. На более поздних этапах, когда проведены какие-либо работы по задаче, максимальное отклонение составляет не более недели.
 Презентация участника
Презентация участника
Участникам предложили разработать решения на Machine Learning, которые помогали бы предсказывать сроки выполнения доработок и критичность багов. Эти решения могли бы повысить эффективность разработки в СберТехе, в том числе:
- лучше планировать загрузку команд в ходе исправлений на разных этапах разработки;
- формировать структуру релизов в части hot fix;
- планировать работу в спринтах — определять story points, зарезервированные для исправления проблем;
- в целом снижать количество багов в программном коде;
- сократить время выхода продуктов на рынок;
- увеличить предсказуемость решений и эффективность тестирования.
Лучшие идеи участников планируется внедрить в СберТехе уже в ближайшее время.
Мы прекрасно понимали, что нельзя создать промышленное решение за ограниченное время хакатона. Иллюзий никто не питал и было понятно, что решения будут во многом сырыми. Но зачем придумывать задания из воздуха, если у нас есть вполне определенные задачи? В итоге мы дали ребятам фан (и конечно, денежное вознаграждение), а взамен получили несколько интересных идей, которые можно брать в работу.
Исходные данные
Задача решалась на основе данных из Jira внутренней и внешней рабочих сетей, а также из ЦУП (внутренняя автоматизированная система по управлению проектами). Если дата-сеты из Jira представляли собой текстовые поля с историей и вложениями, то в ЦУП хранилась более специфичная информация, используемая для планирования изменений.
Дата-сеты были выложены на файловую шару с доступом для участников. Поскольку это хакатон, предполагалось, что они сами разберутся, как и с чем работать. Как и в реальной жизни :)
Железо
Если в знаниях и навыках коллег мы почти не сомневались, то мощность настольных компьютеров, мягко говоря, не запредельна. Поэтому дополнительно по запросу предоставлялся небольшой Hadoop-кластер. Конфигурация кластера (80 CPU, 200 ГБ, 1,5 ТБ) напоминает одноюнитовый сервер с упором на вычисления, но нет, это все-таки кластер, развернутый в Openstack-е.
Конечно, это небольшой стенд. Он предназначен для отработки решений и интеграции нашей Лаборатории Данных и представлял собой сильно уменьшенную копию промышленного. Но для хакатона его хватило.
В Лаборатории Данных был задействован JupyterHUB, создававший отдельные инстансы JupyterNotebook. А чтобы можно было работать с параллельными вычислениями, с помощью Cloudera parcels мы добавили в Jupyter несколько вариантов kernel-ов с разными наборами python-библиотек.
В итоге на входе мы получили независимую работу N пользователей с возможностью использовать нужные версии библиотек, никому не мешая. Кроме того, без особой головной боли можно было запустить параллельные вычисления (мы знаем, что существует Data Science Workbench от Cloudera, и уже пробуем с ним работать, но на момент проведения хакатона этот инструмент еще не был доступен).
I место — автообработка багов
Цель: Создание pipeline автообработки багов в проектах Сбербанк-Технологии. Авторы решения: Анна Рожкова, Павел Швец и Михаил Баранов (Москва)
В качестве исходных данных команда использовала отзывы клиентов мобильного приложения Сбербанк Онлайн из Google Play и AppStore, а также информацию о багах из Jira.
Сначала участники решили проблему разбивки отзывов на положительные и отрицательные с помощью классификатора на основе дерева. Затем, используя негативные отзывы, выделили основные темы, вызвавшие недовольство пользователей. Это, например:- обновления
- антивирус (рут, прошивка)
- смс и платежи
В отдельную категорию попали люди, писавшие, что «все плохо».
С помощью агломеративной иерархической кластеризации команда разделила отзывы по клиентским проблемам (преимущество такого подхода — возможность добавления экспертного мнения, к примеру, когда отзывы о целях и вкладах можно отнести к одному кластеру). Так, например, один из выделенных кластеров объединил проблемы со входом на устройстве Asus Zenfone 2 (период между появлением первых отзывов о проблеме и регистрацией бага в Jira составил 16 дней).
Участники предложили максимально сократить время реагирования на проблемы пользователей, сделав онлайн-обработку отзывов с автосозданием багов по выделенным кластерам, используя преимущество банка — большое количество неравнодушных клиентов (1500 отзывов в день). В ходе работы удалось добиться accuracy = 86% и precision = 88% при определении негативных отзывов.Еще одно решение команды — визуализация процессов в разработке. Кейс был разобран на примере Сбербанк Онлайн Android (ASBOL).
Участники посчитали количество переходов статусов багов между членами команды и отрисовали их в виде графа. С этим инструментом проще принимать управленческие решения и равномерно распределять нагрузку внутри команды. Кроме того, наглядно видно, кто является ключевым участником команды и где есть узкие места проекта. На основе этой информации предлагается автоматически назначать баги на конкретных участников команды, учитывая их загрузку и критичность бага.Дополнительно участники попробовали разобрать проблему автоматической приоритизации багов с использованием логистической регрессии и наивного байесовского классификатора. Для этого была определена важность бага по его описанию, наличию вложений и другим характеристика. Однако модель показала результат accuracy = 54% при кросс-валидации на 3-х фолдах – на момент сдачи работ не пригодный для внедрения прототип.
По мнению участников команды, плюсы их моделей в простоте, хорошей интерпретации результата и быстрой работе. Это шаг к real-time обработке отзывов пользователей при помощи машинного обучения, позволяющий в реальном времени взаимодействовать с пользователями, выявлять и устранять проблемы, повышая лояльность клиентов.
Презентация команды
II место — оптимизация производственных процессов
Автор решения: Антон Баранов (Москва)
Задачи:
- предсказать итоговый приоритет бага, используя информацию о нем. Например: описание, этап обнаружения, проект и др.
- на основе данных о распределении багов во времени предсказать число багов определенного типа, системы, этапа и т.д., в прогнозный период.
Антон работал с багами из Jira. Дата-сет включал информацию о более чем 67 000 багов в статусе «завершен» с 2011 по 2017 год. Поиск решения поставленных задач он вел с помощью библиотек языка Python и других ML-библиотек.
Антон проанализировал и отобрал признаки, влияющие на итоговый приоритет бага, и на их основе построил модель предсказания итогового приоритета. Кроме того, проведя анализ и поиск особенностей различных временных рядов, он построил модели прогноза числа багов. Предложенные решения будут полезны в тестировании. В Agile результат предсказания количества дефектов по данной модели можно учитывать при планировании работ в будущих спринтах. Решение Антона поможет точнее определять время, необходимое на исправление проблем, что скажется на итоговой производительности.Презентация участника
III место: прогнозирование рисков
Автор решения: Николай Желтовский (Иннополис)Цель: Создание системы прогнозирования на основе нейронной сети для минимизации рисков при управлении ИТ-проектами.
Из предложенных организаторами наборов исходных данных участник выбрал выгрузку списка задач из Jira. Задача — это отдельное задание на разработку компонента ПО. Каждая задача в процессе своего жизненного цикла проходит различные состояния: создание, разработка, различные виды тестирования и согласования, закрытие. Таких состояний может быть несколько десятков.
Николай построил и обучил нейронную сеть, способную предсказывать переходы задач в определенные состояния и прогнозировать даты этих событий, сообщать о возможных критических событиях или отклонениях от плановых значений — важных функциях для процесса управления.
Для обучения нейронной сети Николай восстановил по журналу событий последовательность промежуточных состояний для каждой задачи. На вход нейронной сети было подано одно из промежуточных состояний задачи, на выход – конечное, таким образом сеть обучалась предсказывать события. Дополнительно для обучения использовались производные данные — например, таблица с временной разницей между всеми событиями в прошлом; учитывалась гипотеза о том, что задачи, по которым работы ведутся в выходные дни, могут быть проблемными. Нейронная сеть предсказывает некоторые критические события с точностью 91-94%. Например, повторное открытие задачи. Дата закрытия задачи предсказывается с отклонением от 0 до 37 дней сразу после её создания. На более поздних этапах, когда проведены какие-либо работы по задаче, максимальное отклонение составляет не более недели. Презентация участникаТелеграм: t.me/ainewsline
Источник: habrahabr.ru