Как мы учим ИИ помогать находить сотрудников
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-09-29 03:12
Ведущий разработчик SuperJob Сергей Сайгушкин рассказывает о подготовке данных и обучении модели скоринга резюме, внедрении в продакшн, мониторинге метрик качества и АБ-тестировании функционала скоринга резюме.
Статья подготовлена по материалам доклада на РИТ 2017 «Ранжирование откликов соискателей с помощью машинного обучения».
И даем возможность рекрутеру возможность фильтровать отклики по данному признаку в личном кабинете.
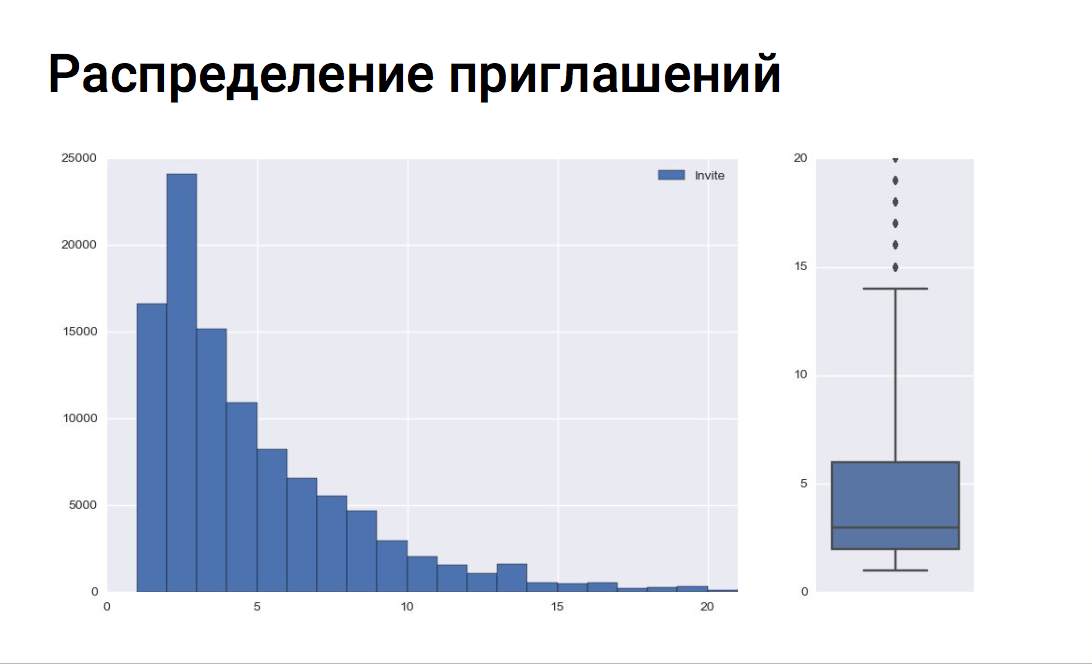
Ось Х — количество приглашений на собеседование
Ось Y — количество вакансий
На графике видно, что рекрутеры в основном приглашают 5—6 соискателей на одну вакансию. По боксплоту можно оценить медиану приглашений, верхний и нижний квартиль и выявить выбросы. В нашем примере все вакансии с более чем 14 приглашениями на собеседование являются выбросами.
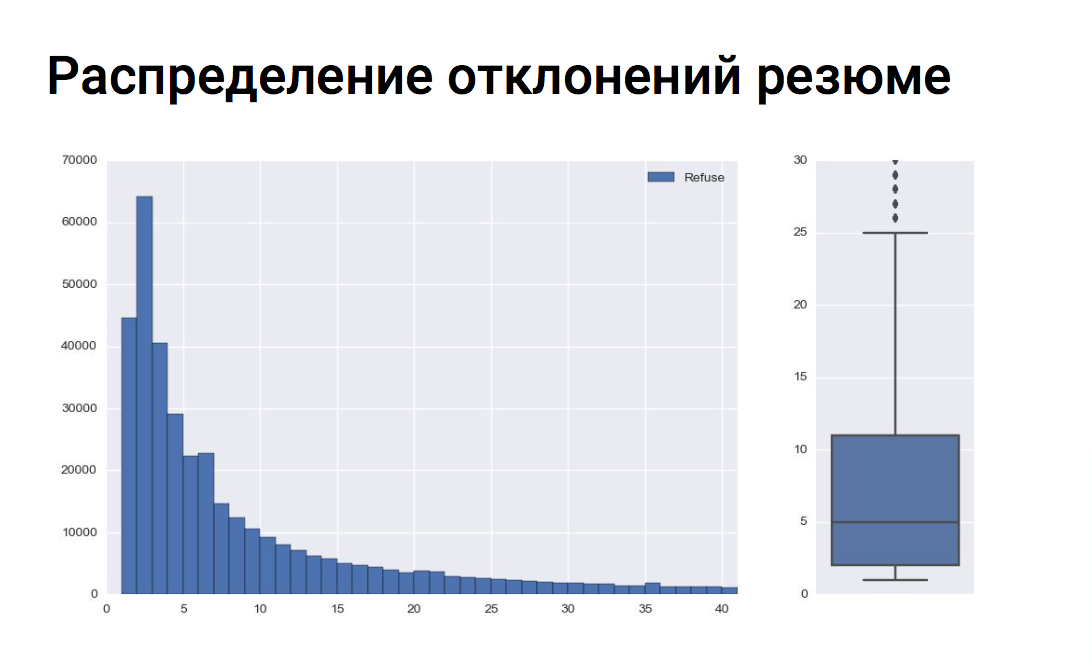 Ось Х — количество отклонений резюме
Ось Х — количество отклонений резюме
Ось Y — количество вакансий
В среднем для одной вакансии рекрутер отклоняет 8—9 соискателей. И все вакансии с количеством отклонений более 25 являются выбросами, что видно на боксплоте.
Генерация признаков
Наша модель использует более 170 признаков. Все признаки основаны на свойствах вакансии, резюме и их сочетаниях. В качестве примера можно привести зарплатную вилку вакансии, желаемую зарплату резюме и попадание зарплаты резюме в зарплатную вилку вакансии как сочетание признаков резюме и вакансии.
К категориальным признакам применяем бинарное кодирование (One-Hot Encoding). Требование вакансии о наличии определенного типа образования, категории водительских прав или знания одного из иностранных языков раскрывается в несколько бинарных фич для модели.
Работа с текстовыми признаками:
Текст очищаем от стоп-слов, пунктуации, лемматизируем. Из тестовых признаков формируем тематические группы:
Для каждой группы обучаем свой TF-IDF Vectorizer. Получаем векторайзеры, обученные на всем списке профессий, на всех требованиях вакансий совместно с навыками резюме и т.д. Например, у нас есть такая фича, как сходство профессии из вакансии с профессиями из опыта работы соискателя. Для каждой фразы получаем tf-idf вектор и вычисляем cosine similarity (косинус угла между векторами) c вектором другой фразы путем скалярного умножения векторов. Таким образом получаем меру сходства двух фраз.
В процессе генерации признаков мы консультировались с исследовательским центром SuperJob. Для рекрутеров был запущен опрос с целью выявить наиболее значимые признаки, по которым они принимают решение, пригласить кандидата или отклонить.
Результаты ожидаемы: рекрутеры смотрят на опыт работы, продолжительность работы на последнем месте, на среднюю продолжительность работы во всех компаниях. На то, является ли желаемая должность из резюме новой для кандидата, т.е. работал ли он по данной профессии раньше или нет. Мы учли данные опроса при составлении признаков для модели.
Примеры признаков:
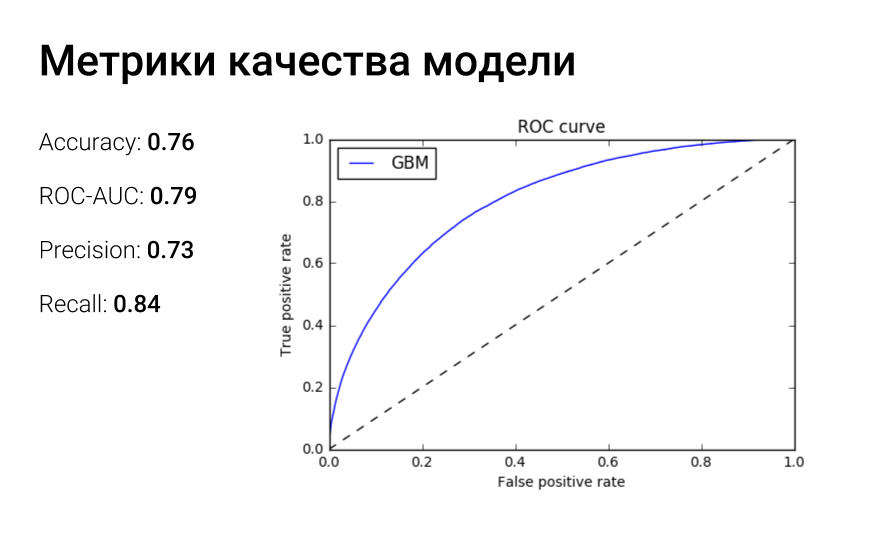
ROC-кривая отражает зависимость доли верных положительный классификаций от доли ложных положительных классификаций. А площадь под roc-кривой можно интерпретировать следующим образом: auc-roc равен вероятности того, что случайно взятый объект 1 класса получит оценку выше, чем случайно взятый объект класса 0.
Мы не останавливаемся на данной модели и проводим новые эксперименты. Сейчас работаем над наполнением списка синонимов профессий, используя doc2vec, чтобы точнее определять факт того, что профессия из резюме соответствует профессии вакансии, и чтобы ведущий php-разработчик и senior php developer не были разными профессиями для модели. Также идут работы над тематическим моделированием с использованием библиотеки BigARTM для получения ключевых тем вакансии и резюме.
Также нам было необходимо, чтобы как можно меньше подходящих резюме оказалось в нерелевантных, т.е. мы должны минимизировать количество ошибок второго рода или ложно-отрицательных срабатываний. Для этого мы немного снизили значение threshold-вероятности принадлежности к релевантному классу. Таким образом снизили количество FN-ошибок. Но это имело и обратный эффект: возросло количество FP-ошибок.

На фреймворке Flask реализовали небольшой микросервис с REST API скоринга, упаковали его в docker контейнер и развернули на выделенном под эту задачу сервере. В контейнере запущен uWSGI веб сервер с мастер-процессом и 24 процессами-воркерами, по одному на ядро.
После того как пользователь откликается на сайте на вакансию, сообщение об этом факте попадает в очередь rabbitmq. Обработчик очереди получает сообщение, подготавливает данные, объект вакансии, объект резюме и вызывает endpoint api скоринга. Далее значение скоринга сохраняется в базу данных для последующей фильтрации откликов рекрутером в своем личном кабинете.
Сначала мы хотели реализовать онлайн-скоринг непосредственно при обращении к личному кабинету, но, оценив количество откликов на некоторые вакансии и итоговое время работы модели над одной парой резюме-вакансия, реализовали скоринг в асинхронном режиме.
Сам процесс скоринга занимает примерно 0,04—0,05 секунды. Таким образом, чтобы пересчитать значение скоринга для всех активных откликов на текущем железе, понадобится примерно 18—20 часов. С одной стороны, это большая цифра, с другой — мы пересчитываем скоринг достаточно редко, только при внедрении в продакшн новой модели. И с этой проблемой на данный момент можно как-то жить.
Самую большую нагрузку на сервис скоринга генерируют не соискатели, откликающиеся на вакансии, а наш сервис почтовых рассылок «подписки на резюме». Данный сервис срабатывает раз в сутки и рекомендует соискателей на вакансии рекрутеров. Естественно, результат работы сервиса мы также должны проскорить, чтобы советовать рекрутеру только релевантные отклики.
В итоге в пике работы мы обрабатываем 1000—1200 запросов в секунду. Если количество откликов, которые нужно проскорить, возрастет, то мы поставим рядом еще один сервер и горизонтально отмасштабируем сервис скоринга.
Графики делают нашу жизнь спокойнее, мы уверены, что качество скоринга не изменилось и все этапы работают в штатном режиме.


Данный тест мы проводили с уровнем значимости в 5%, это означает, что существует 5% вероятность допустить ошибку первого рода или ложноположительное срабатывание.
После ab-тестирования собрали обратную связь от рекрутеров, которые попали в вариант с функционалом скоринга. Обратная связь также была положительной. Они пользуются функционалом, тратят меньше времени на массовый подбор.
Статья подготовлена по материалам доклада на РИТ 2017 «Ранжирование откликов соискателей с помощью машинного обучения».
Почему рекрутерам не хватает ИИ?
Есть два базовых способа работы рекрутера с SuperJob. Можно, используя внутренний поиск сервиса, отсматривать резюме и приглашать подходящих специалистов на собеседования. А можно разместить вакансию и работать с откликами специалистов. 15% вакансий на SuperJob получают более 100 откликов в сутки. Соискатели не всегда отправляют резюме, соответствующее должности. Поэтому эйчарам приходится тратить лишнее время, чтобы отобрать нужных кандидатов. Например, вакансия «Ведущий PHP-разработчик» обязательно соберет отклики программиста «1С», технического писателя и даже директора по маркетингу. Это осложняет и замедляет подбор даже на одну позицию. А в работе у рекрутера одновременно бывает несколько десятков вакансий. Мы разработали алгоритм скоринга резюме, который автоматически выделяет резюме, совсем не подходящие к вакансии. С помощью него мы определяем нерелевантные отклики и пессимизируем их в списке откликов в личном кабинете работодателя. Получаем задачу классификации на два класса: + подходящий — неподходящий откликИ даем возможность рекрутеру возможность фильтровать отклики по данному признаку в личном кабинете.
Готовь данные летом, зимой, осенью и весной. И еще — летом
Подготовка данных для обучения — это один из важнейших этапов. От того, насколько тщательно подготовлен этот этап, зависит ваш успех. Мы обучаемся на событиях из личного кабинета рекрутера. Выборка включает в себя примерно 10—12 миллионов событий за последние 3 месяца. В качестве меток классов используем события отклонения резюме и приглашения на собеседование. Если рекрутер сразу отклоняет резюме, без приглашения на собеседование, то скорее всего оно является нерелевантным. Соответственно, если рекрутер приглашает на собеседование (даже если впоследствии отклоняет), то отклик релевантен вакансии. Для каждой вакансии проверяем распределение приглашений на собеседование и отклонений без рассмотрения и соответственно не обучаем модель на событиях вакансий, в которых количество отклонений существенно превышает количество приглашений. Или наоборот: там, где рекрутер приглашает всех подряд (или отклоняет всех подряд), такие вакансии мы также считаем выбросами. Ось Х — количество приглашений на собеседование
Ось Y — количество вакансий
На графике видно, что рекрутеры в основном приглашают 5—6 соискателей на одну вакансию. По боксплоту можно оценить медиану приглашений, верхний и нижний квартиль и выявить выбросы. В нашем примере все вакансии с более чем 14 приглашениями на собеседование являются выбросами.
Ось Х — количество отклонений резюмеОсь Y — количество вакансий
В среднем для одной вакансии рекрутер отклоняет 8—9 соискателей. И все вакансии с количеством отклонений более 25 являются выбросами, что видно на боксплоте.
Кто не хочет работать головой — работает руками
После обучения модели для каждого рекрутера мы построили свою матрицу ошибок и обнаружили кластер работодателей, с которыми наша модель плохо справлялась. После анализа лога действий данных рекрутеров стало понятно, почему модель пессимизировала отклики соискателей, которых потом приглашали на собеседование. Данные рекрутеры массово приглашали на собеседование соискателей с резюме вообще из другой профессиональной области, не соответствующей вакансии, то есть приглашали всех подряд. То есть вакансия расходилась с резюме приглашенного кандидата практически полностью. Как ни странно, в основном это были клиенты с безлимитным тарифом. Они получают полный доступ к базе и берут количеством, а не качеством. Данных рекрутеров мы включили в черный список и не обучались на их действиях, т.к. паттерн поведения расходился с поставленной задачей. Самый запоминающийся пример был с вакансией полицейского московского метрополитена. Рекрутер приглашал на собеседование кого угодно: продавцов, торговых представителей, актеров — и отклонял сотрудников национальной гвардии и полицейских. Возможно, он перепутал кнопки «отклонить» и «пригласить» в интерфейсе личного кабинета. Генерация признаков
Наша модель использует более 170 признаков. Все признаки основаны на свойствах вакансии, резюме и их сочетаниях. В качестве примера можно привести зарплатную вилку вакансии, желаемую зарплату резюме и попадание зарплаты резюме в зарплатную вилку вакансии как сочетание признаков резюме и вакансии.
К категориальным признакам применяем бинарное кодирование (One-Hot Encoding). Требование вакансии о наличии определенного типа образования, категории водительских прав или знания одного из иностранных языков раскрывается в несколько бинарных фич для модели.
Работа с текстовыми признаками:
Текст очищаем от стоп-слов, пунктуации, лемматизируем. Из тестовых признаков формируем тематические группы:
- профессия вакансии и профессии из резюме;
- требования вакансии и ключевые навыки резюме;
- обязанности вакансии и обязанности с предыдущих мест работы соискателя.
Для каждой группы обучаем свой TF-IDF Vectorizer. Получаем векторайзеры, обученные на всем списке профессий, на всех требованиях вакансий совместно с навыками резюме и т.д. Например, у нас есть такая фича, как сходство профессии из вакансии с профессиями из опыта работы соискателя. Для каждой фразы получаем tf-idf вектор и вычисляем cosine similarity (косинус угла между векторами) c вектором другой фразы путем скалярного умножения векторов. Таким образом получаем меру сходства двух фраз.
В процессе генерации признаков мы консультировались с исследовательским центром SuperJob. Для рекрутеров был запущен опрос с целью выявить наиболее значимые признаки, по которым они принимают решение, пригласить кандидата или отклонить.
Результаты ожидаемы: рекрутеры смотрят на опыт работы, продолжительность работы на последнем месте, на среднюю продолжительность работы во всех компаниях. На то, является ли желаемая должность из резюме новой для кандидата, т.е. работал ли он по данной профессии раньше или нет. Мы учли данные опроса при составлении признаков для модели.
Примеры признаков:
- средняя продолжительность работы на одном месте, в месяцах;
- количество месяцев работы на последнем месте;
- разница между требуемым опытом вакансии и опытом из резюме;
- попадание желаемой зарплаты резюме в зарплатную вилку вакансии;
- мера сходства между желаемой должностью и предыдущим местом работы;
- мера сходства между специальностью образования и требованиями вакансии;
- рейтинг (заполненнность) резюме.
When it doubt, use xgboost
Для решения задачи классификации мы используем реализацию градиентного бустинга xgboost. После обучения модели мы смогли собрать статистику по значимым признакам. Среди значимых признаков ожидаемо оказались опыт работы, зарплатные фичи, попадание желаемой зарплаты из резюме в зарплатную вилку вакансии, мера сходства профессии вакансии и опыта работы соискателя, сходство требований вакансии и ключевых навыков резюме. Также в топе признаков оказался возраст соискателя. Мы решили провести эксперимент и убрали данный признак, так как не хотели дискриминировать наших соискателей. В итоге в топ попала фича «количество лет с момента получения высшего образования», которая, очевидно, коррелирует с возрастом. Мы убрали и этот признак и заново обучили модель. После всех манипуляций с возрастом мы увидели, что метрики качества модели немного просели. В итоге решили вернуть возраст, т.к. в массовом подборе он действительно важен рекрутеру, на него обращают внимание. Но компенсируем соискателям в возрасте очки скоринга, если их отклик немного не дотягивает до релевантного, т.к. считаем, что именно возраст соискателя пессимизировал его резюме. После нескольких итераций по обучению модели, подготовке фич мы получили модель с неплохими метриками качества.ROC-кривая отражает зависимость доли верных положительный классификаций от доли ложных положительных классификаций. А площадь под roc-кривой можно интерпретировать следующим образом: auc-roc равен вероятности того, что случайно взятый объект 1 класса получит оценку выше, чем случайно взятый объект класса 0.
Мы не останавливаемся на данной модели и проводим новые эксперименты. Сейчас работаем над наполнением списка синонимов профессий, используя doc2vec, чтобы точнее определять факт того, что профессия из резюме соответствует профессии вакансии, и чтобы ведущий php-разработчик и senior php developer не были разными профессиями для модели. Также идут работы над тематическим моделированием с использованием библиотеки BigARTM для получения ключевых тем вакансии и резюме.
Также нам было необходимо, чтобы как можно меньше подходящих резюме оказалось в нерелевантных, т.е. мы должны минимизировать количество ошибок второго рода или ложно-отрицательных срабатываний. Для этого мы немного снизили значение threshold-вероятности принадлежности к релевантному классу. Таким образом снизили количество FN-ошибок. Но это имело и обратный эффект: возросло количество FP-ошибок.
На фреймворке Flask реализовали небольшой микросервис с REST API скоринга, упаковали его в docker контейнер и развернули на выделенном под эту задачу сервере. В контейнере запущен uWSGI веб сервер с мастер-процессом и 24 процессами-воркерами, по одному на ядро.
После того как пользователь откликается на сайте на вакансию, сообщение об этом факте попадает в очередь rabbitmq. Обработчик очереди получает сообщение, подготавливает данные, объект вакансии, объект резюме и вызывает endpoint api скоринга. Далее значение скоринга сохраняется в базу данных для последующей фильтрации откликов рекрутером в своем личном кабинете.
Сначала мы хотели реализовать онлайн-скоринг непосредственно при обращении к личному кабинету, но, оценив количество откликов на некоторые вакансии и итоговое время работы модели над одной парой резюме-вакансия, реализовали скоринг в асинхронном режиме.
Сам процесс скоринга занимает примерно 0,04—0,05 секунды. Таким образом, чтобы пересчитать значение скоринга для всех активных откликов на текущем железе, понадобится примерно 18—20 часов. С одной стороны, это большая цифра, с другой — мы пересчитываем скоринг достаточно редко, только при внедрении в продакшн новой модели. И с этой проблемой на данный момент можно как-то жить.
Самую большую нагрузку на сервис скоринга генерируют не соискатели, откликающиеся на вакансии, а наш сервис почтовых рассылок «подписки на резюме». Данный сервис срабатывает раз в сутки и рекомендует соискателей на вакансии рекрутеров. Естественно, результат работы сервиса мы также должны проскорить, чтобы советовать рекрутеру только релевантные отклики.
В итоге в пике работы мы обрабатываем 1000—1200 запросов в секунду. Если количество откликов, которые нужно проскорить, возрастет, то мы поставим рядом еще один сервер и горизонтально отмасштабируем сервис скоринга.
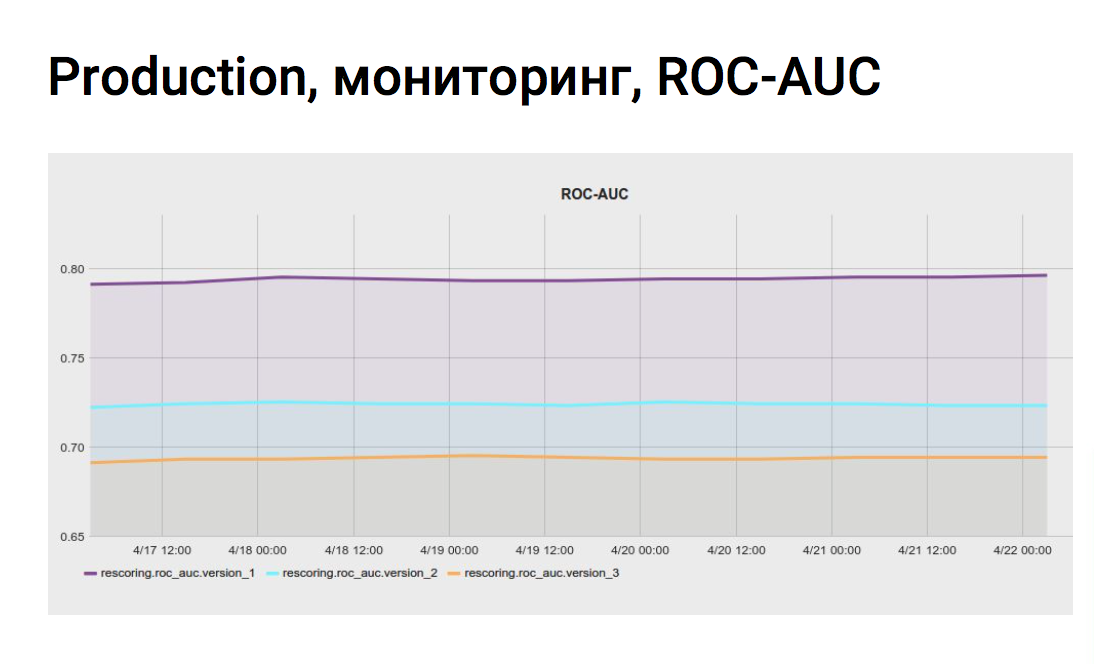
Мониторинг
Для того чтобы непрерывно оценивать метрики качества модели на актуальных данных личного кабинета, мы настроили задание мониторинга в jenkins. Скрипт несколько раз в сутки собирает данные из vertica по приглашениям и отклонениям, смотрит, как отработала модель на данных событиях, считает метрики и отправляет в систему мониторинга. Также мы можем сравнивать метрики разных моделей скоринга на одних данных из личного кабинета. Мы не сразу внедряем новые модели, сначала скорим все отклики экспериментальной моделью, сохраняем значения скоринга в базу, а потом на графиках смотрим, лучше отрабатывают экспериментальные модели или хуже.Графики делают нашу жизнь спокойнее, мы уверены, что качество скоринга не изменилось и все этапы работают в штатном режиме.
Реализация в личном кабинете
В списке откликов на определенную вакансию появились два таба, подходящие и неподходящие отклики. В качестве примера все та же вакансия ведущего программиста php в SuperJob. Резюме php-программиста, пусть и не ведущего или senior и резюме fullstack-разработчика со знанием php попало в подходящие отклики, а резюме программиста .net и руководителя it-отдела ожидаемо ушли в неподходящие. АБ-тестирование
После реализации функционала скоринга мы провели ab-тест на рекрутерах. Для теста мы выбрали следующие метрики:- Конверсия присланных резюме в приглашенные — impact 8.3%
- Число приглашенных резюме — impact 6.7%
- Конверсия открытых вакансий в закрытые — impact 6.0%
- Число закрытых вакансий — impact 5.4%
- Количество дней до закрытия вакансий — impact 7.7%
Данный тест мы проводили с уровнем значимости в 5%, это означает, что существует 5% вероятность допустить ошибку первого рода или ложноположительное срабатывание.
После ab-тестирования собрали обратную связь от рекрутеров, которые попали в вариант с функционалом скоринга. Обратная связь также была положительной. Они пользуются функционалом, тратят меньше времени на массовый подбор.
Выводы
Самое главное — обучающая выборка. Мониторим метрики качества модели. Фиксируем random_state.Телеграм: t.me/ainewsline
Источник: habrahabr.ru