Как мы обучали приложение Яндекс.Такси предсказывать пункт назначения
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-09-19 10:43
алгоритмы машинного обучения, реализация нейронной сети, ИИ проекты, поисковые системы, примеры ии

Представьте: вы открываете приложение, чтобы в очередной раз заказать такси в часто посещаемое вами место, и, конечно, в 2017 году вы ожидаете, что все, что нужно сделать – сказать приложению «Вызывай», и такси за вами тут же выедет. А куда вы хотели ехать, через сколько минут и на какой машине — все это приложение узнает благодаря истории заказов и машинному обучению. В общем-то все, как в шутках про идеальный интерфейс с единственной кнопкой «сделать хорошо», лучше которого только экран с надписью «все уже хорошо». Звучит здорово, но как же приблизить эту реальность?
 На днях мы выпустили новое приложение Яндекс.Такси для iOS. В обновленном интерфейсе один из акцентов сделан на выборе конечной точки маршрута («точки Б»). Но новая версия – это не просто новый UI. К запуску обновления мы существенно переработали технологию прогнозирования пункта назначения, заменив старые эвристики на обученный на исторических данных классификатор.
На днях мы выпустили новое приложение Яндекс.Такси для iOS. В обновленном интерфейсе один из акцентов сделан на выборе конечной точки маршрута («точки Б»). Но новая версия – это не просто новый UI. К запуску обновления мы существенно переработали технологию прогнозирования пункта назначения, заменив старые эвристики на обученный на исторических данных классификатор.
Как вы понимаете, кнопки «сделать хорошо» в машинном обучении тоже нет, поэтому простая на первый взгляд задача вылилась в довольно захватывающий кейс, в результате которого, мы надеемся, у нас получилось немного облегчить жизнь пользователей. Сейчас мы продолжаем внимательно следить за работой нового алгоритма и еще будем его менять, чтобы качество прогноза было стабильнее. На полную мощность запустимся в ближайшие несколько недель, но под катом уже готовы рассказать о том, что же происходит внутри.
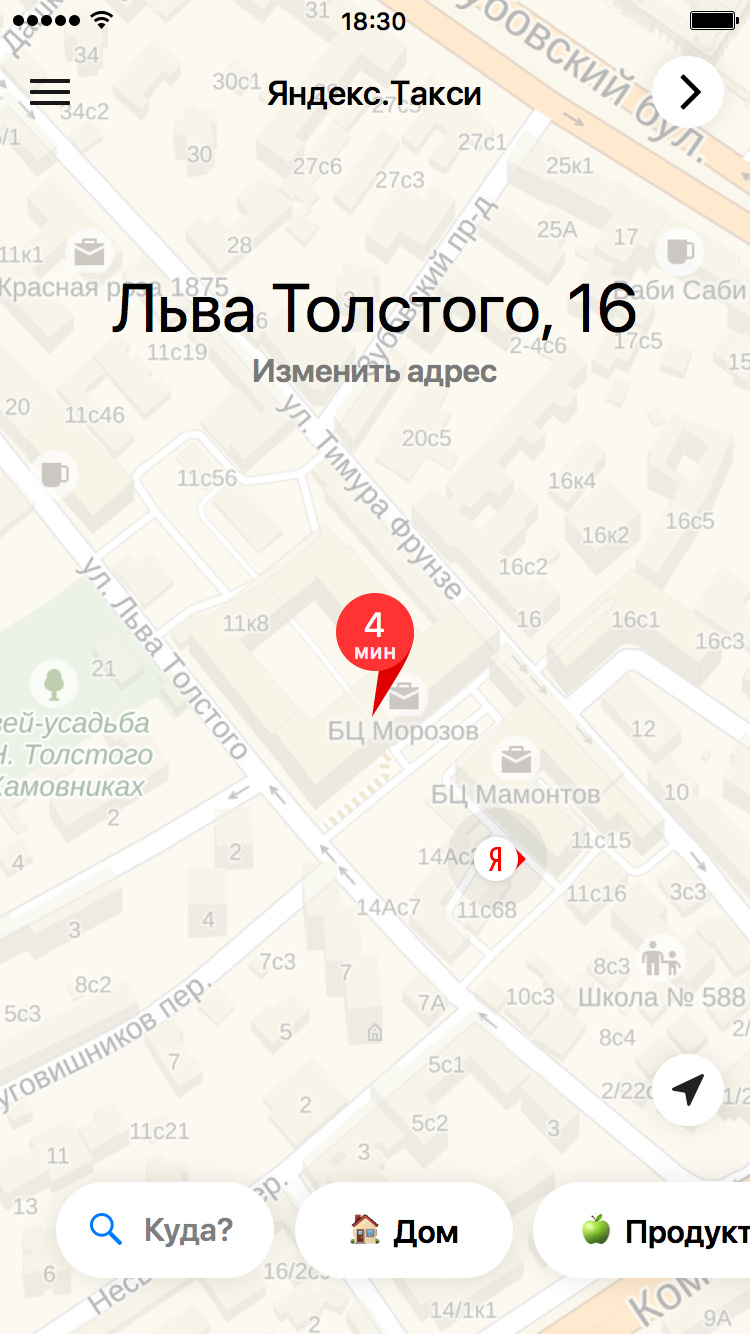
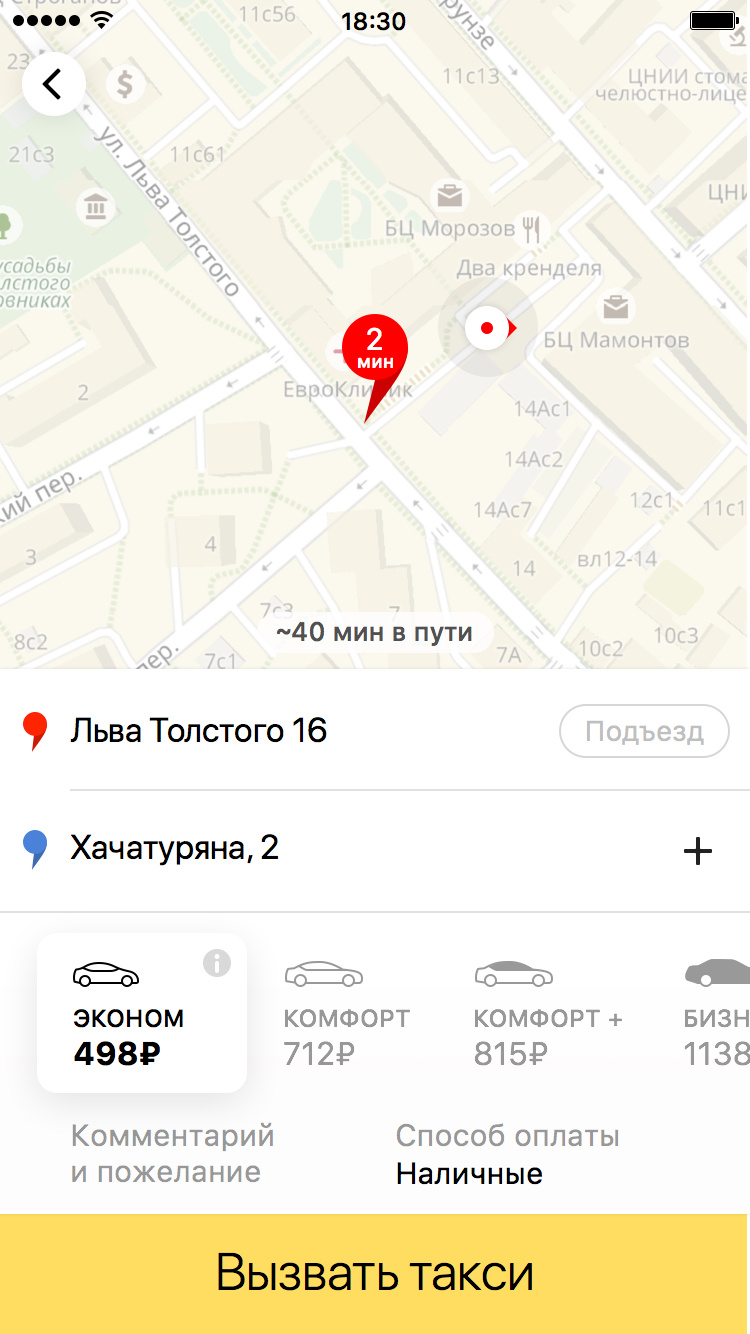
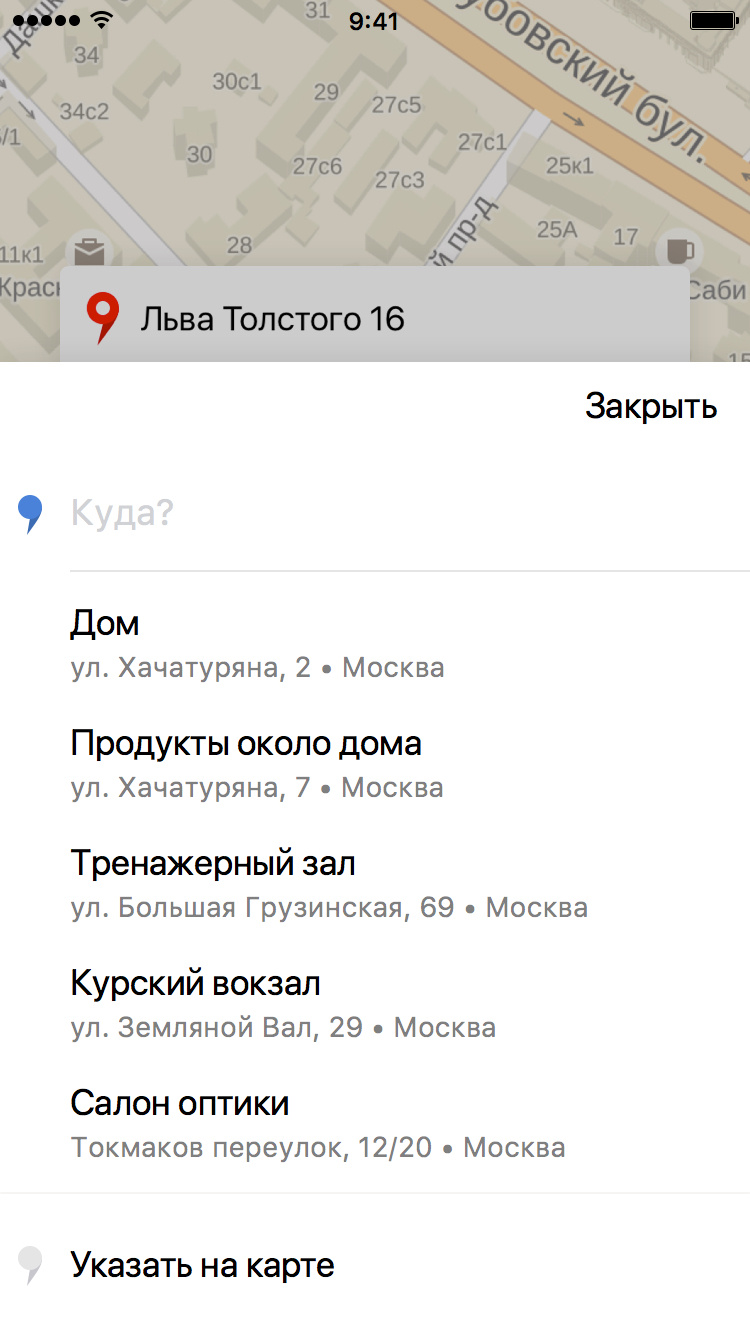 Если наш прогноз верный, пользователю не требуется вбивать адрес, и вообще есть повод порадоваться, что приложение в состоянии хоть немного запомнить его предпочтения. Именно для этих подсказок разрабатывалась модель, которая на основе истории поездок пользователя пытается предугадать, куда именно он сейчас скорее всего отправится.
Если наш прогноз верный, пользователю не требуется вбивать адрес, и вообще есть повод порадоваться, что приложение в состоянии хоть немного запомнить его предпочтения. Именно для этих подсказок разрабатывалась модель, которая на основе истории поездок пользователя пытается предугадать, куда именно он сейчас скорее всего отправится.
До построения модели на основе машинного обучения была реализована такая стратегия: берутся все точки из истории, «одинаковые» точки (с одинаковым адресом или находящиеся близко) сливаются, за разные параметры получившимся локациям начисляются различные баллы (если пользователь ездил в эту точку, ездил из этой точки, ездил в эту точку в какое-то временное окно и так далее). Затем выбираются локации с наибольшим числом баллов и рекомендуются пользователю. Как я уже говорил, исторически эта стратегия неплохо работала, но точность прогнозирования можно было повысить. А главное — мы знали как.
Начнём с первой метрики, то есть качества кандидатов. Стоит отметить, что только примерно в 72 процентах заказов выбранная точка Б (или очень близкая к ней географически) присутствовала ранее в истории. Это означает, что максимальное качество кандидатов ограничено этим числом, так как мы пока не можем рекомендовать точки, куда человек еще ни разу не ездил. Мы подобрали эвристики с назначением баллов так, что при отборе топ-20 кандидатов по этим баллам правильный ответ в них содержался в 71% случаев. При максимуме в 72% это весьма неплохой результат. Это качество кандидатов нас полностью устраивало, поэтому эту часть модели мы дальше не трогали, хотя, в принципе, могли бы. Например, вместо эвристик можно было обучить отдельную модель. Но так как механизм поиска кандидатов, основанный на эвристиках, уже был технически реализован, мы смогли сэкономить на разработке, лишь подобрав нужные коэффициенты.
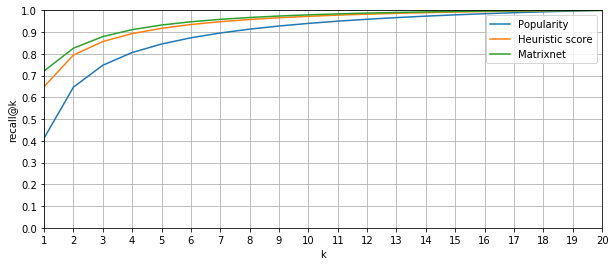
Снова вернемся к качеству переранжирования. Так как на главном экране заказа поездки показывать мы можем одну, две, ну максимум три точки, то нас интересует доля случаев, когда правильный ответ оказался в топ-1, топ-2 и топ-3 списка ранжирования соответственно. В машинном обучении долю правильных ответов в топ k списка ранжирования (от всех правильных ответов) называют recall@k. В нашем случае нас интересуют recall@1, recall@2 и recall@3. При этом «правильный ответ» в нашей задаче только один (с точностью до близко расположенных точек), а значит, эта метрика как раз будет показывать долю случаев, когда настоящая «точка Б» попадает в топ 1, топ 2 и топ 3 нашего алгоритма.
В качестве базового алгоритма ранжирования мы взяли сортировку по количеству баллов и получили следующие результаты (в процентах): recall@1 = 63,7; recall@2 = 78,5 и recall@3 = 84,6. Заметим, что проценты здесь – это доля от тех случаев, где правильный ответ в кандидатах вообще присутствовал. В какой-то момент возник логичный вопрос: возможно, простая сортировка по популярности уже даёт хорошее качество, а все идеи сортировки по баллам и использование машинного обучения излишни? Но нет, такой алгоритм показал самое плохое качество: recall@1 = 41,2; recall@2 = 64,6; recall@3 = 74,7.
Запомним исходные результаты и перейдем к обсуждению модели машинного обучения.
Теперь перейдём к модели для переранжирования. Так как мы хотим максимизировать recall@k, в первом приближении мы хотим прогнозировать вероятность поездки пользователя в определенное место и ранжировать места по вероятности. «В первом приближении» потому, что эти рассуждения верны только при очень точной оценке вероятностей, а когда в них появляются погрешности, recall@k может лучше оптимизироваться и другим решением. Простая аналогия: в машинном обучении, если мы точно знаем все распределения вероятностей, самый лучший классификатор — байесовский, но поскольку на практике распределения восстанавливаются по данным приближенно, часто другие классификаторы работают лучше.
Задача классификации ставилась следующим образом: объектами были пары (история предыдущих поездок пользователя; кандидат в рекомендации), где положительные примеры (класс 1) — пары, в которых пользователь все-таки поехал в эту точку Б, отрицательные примеры (класс 0) — пары, в которых пользователь в итоге поехал в другое место.
Таким образом, если побыть прожженным формалистом, модель оценивала не вероятность того, что человек поедет в конкретную точку, а сдвинутую вероятность того, что заданная пара «история-кандидат» является релевантной. Тем не менее, сортировка по этой величине столь же осмыслена, что и сортировка по вероятности поездки в точку. Можно показать, что при избытке данных это будут эквивалентные сортировки.
Классификатор мы обучали на минимизацию log loss, а в качестве модели использовали активно применяемый в Яндексе Матрикснет (градиентный бустинг над решающими деревьями). И если с Матрикснетом всё понятно, то почему всё-таки оптимизировался log loss?
Ну, во-первых, оптимизация этой метрики приводит к правильным оценкам вероятности. Причина, по которой так происходит, своими корнями уходит в математическую статистику, в метод максимального правдоподобия. Пусть вероятность единичного класса у i-го объекта равна , а истинный класс равен . Тогда, если считать исходы независимыми, правдоподобие выборки (грубо говоря, вероятность получить именно такой исход, который был получен) равно следующему произведению: В идеале нам хотелось бы иметь такие , чтобы получить максимум этого выражения (ведь мы хотим, чтобы полученные нами результаты были максимально правдоподобны, правда?). Но если прологарифмировать это выражение (так как логарифм — монотонная функция, то можно его максимизировать вместо исходного выражения), то мы получим . А это уже известный нам log loss, если заменить на их предсказания и умножить все выражение на минус-единицу.
Во-вторых, мы, конечно, доверяем теории, но на всякий случай попробовали оптимизировать разные функции потерь, и log loss показал самый большой recall@k, так что все в итоге сошлось.
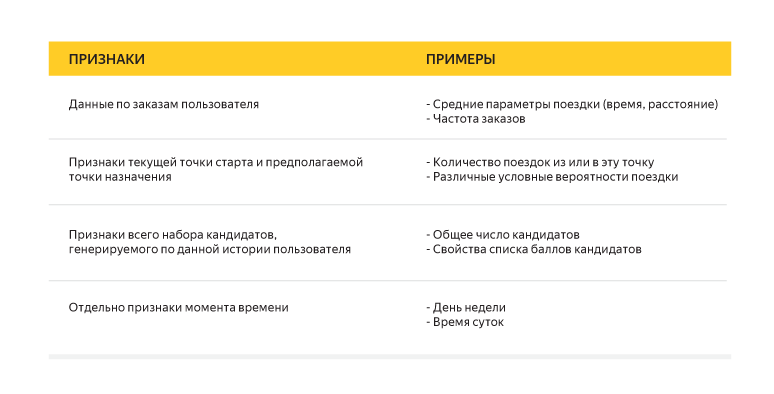
О методе поговорили, о функции ошибки – тоже, осталась одна важная деталь: признаки, по которым мы обучали наш классификатор. Для описания каждой пары «история-кандидат» мы использовали более сотни разных признаков. Вот несколько для примера:
И, наконец, о результатах: после переранжирования с помощью построенной нами модели мы получили следующие данные (опять же в процентах): recall@1 = 72,1 (+8,4); recall@2 = 82,6 (+4,1); recall@3 = 88 (+3,4). Совсем неплохо, но в будущем возможны улучшения за счет включения в признаки дополнительной информации.
Можно посмотреть на примере, как новый алгоритм прогнозирования будет выглядеть для пользователя:

Кроме того, как уже было сказано в начале поста – было бы здорово, если бы приложение само понимало, когда, куда и на какой машине нам нужно поехать. Сейчас сложно сказать, насколько по историческим данным возможно точно угадывать параметры заказа и настройки приложения, подходящие пользователю, но мы работаем в этом направлении, будем делать наше приложение все более «умным» и способным подстраиваться под вас.
На днях мы выпустили новое приложение Яндекс.Такси для iOS. В обновленном интерфейсе один из акцентов сделан на выборе конечной точки маршрута («точки Б»). Но новая версия – это не просто новый UI. К запуску обновления мы существенно переработали технологию прогнозирования пункта назначения, заменив старые эвристики на обученный на исторических данных классификатор. Как вы понимаете, кнопки «сделать хорошо» в машинном обучении тоже нет, поэтому простая на первый взгляд задача вылилась в довольно захватывающий кейс, в результате которого, мы надеемся, у нас получилось немного облегчить жизнь пользователей. Сейчас мы продолжаем внимательно следить за работой нового алгоритма и еще будем его менять, чтобы качество прогноза было стабильнее. На полную мощность запустимся в ближайшие несколько недель, но под катом уже готовы рассказать о том, что же происходит внутри.
Задача
При выборе пункта назначения, в поле «куда» у нас есть возможность предложить пользователю буквально 2-3 варианта на главном экране и еще несколько – если он перейдет в меню выбора точки Б: Если наш прогноз верный, пользователю не требуется вбивать адрес, и вообще есть повод порадоваться, что приложение в состоянии хоть немного запомнить его предпочтения. Именно для этих подсказок разрабатывалась модель, которая на основе истории поездок пользователя пытается предугадать, куда именно он сейчас скорее всего отправится.До построения модели на основе машинного обучения была реализована такая стратегия: берутся все точки из истории, «одинаковые» точки (с одинаковым адресом или находящиеся близко) сливаются, за разные параметры получившимся локациям начисляются различные баллы (если пользователь ездил в эту точку, ездил из этой точки, ездил в эту точку в какое-то временное окно и так далее). Затем выбираются локации с наибольшим числом баллов и рекомендуются пользователю. Как я уже говорил, исторически эта стратегия неплохо работала, но точность прогнозирования можно было повысить. А главное — мы знали как.
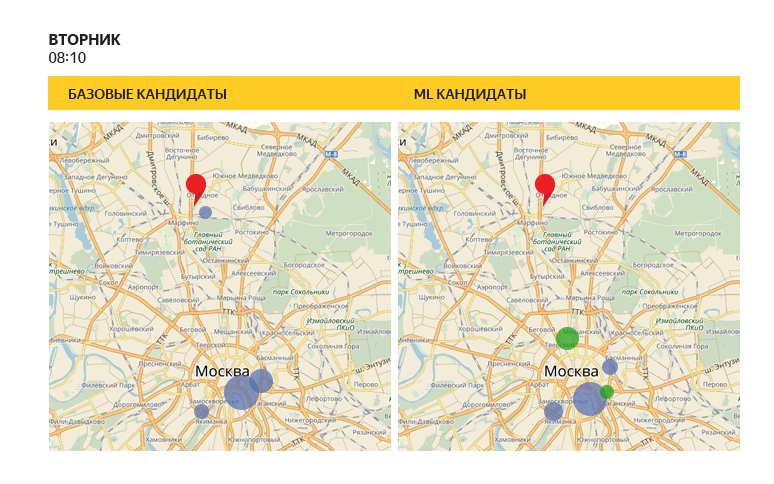
«Старые» эвристики и обученный классификатор могут давать разные прогнозы: на этом рисунке размер круга показывает, насколько высоко данная точка находится в списке рекомендаций в конкретный день и конкретное время. Обратите внимание, что обученный алгоритм в данном примере предложил несколько дополнительных локаций (зеленые круги).
Наша задача состояла в том, чтобы поверх «старой» стратегии использовать переранжирование наиболее вероятных «точек Б» с помощью машинного обучения. Общий подход такой: сначала начисляем баллы, как и раньше, затем берём топ n по этим баллам (где n заведомо больше, чем нужно в итоге порекомендовать), а далее переранжируем его и пользователю в итоге показываем только три наиболее вероятные точки Б. Точное число кандидатов в списке, конечно, определяется в ходе оптимизации, чтобы и качество кандидатов и качество переранжирования были как можно выше. В нашем случае оптимальное число кандидатов оказалось равным 20.Об оценке качества и результатах
Во-первых, качество нужно разделить на две части: качество кандидатов и качество ранжирования. Качество кандидатов — это то, насколько отобранные кандидаты в принципе возможно правильно переранжировать. А качество ранжирования — это насколько мы правильно предсказываем точку назначения при условии того, что она вообще есть среди кандидатов.Начнём с первой метрики, то есть качества кандидатов. Стоит отметить, что только примерно в 72 процентах заказов выбранная точка Б (или очень близкая к ней географически) присутствовала ранее в истории. Это означает, что максимальное качество кандидатов ограничено этим числом, так как мы пока не можем рекомендовать точки, куда человек еще ни разу не ездил. Мы подобрали эвристики с назначением баллов так, что при отборе топ-20 кандидатов по этим баллам правильный ответ в них содержался в 71% случаев. При максимуме в 72% это весьма неплохой результат. Это качество кандидатов нас полностью устраивало, поэтому эту часть модели мы дальше не трогали, хотя, в принципе, могли бы. Например, вместо эвристик можно было обучить отдельную модель. Но так как механизм поиска кандидатов, основанный на эвристиках, уже был технически реализован, мы смогли сэкономить на разработке, лишь подобрав нужные коэффициенты.
Снова вернемся к качеству переранжирования. Так как на главном экране заказа поездки показывать мы можем одну, две, ну максимум три точки, то нас интересует доля случаев, когда правильный ответ оказался в топ-1, топ-2 и топ-3 списка ранжирования соответственно. В машинном обучении долю правильных ответов в топ k списка ранжирования (от всех правильных ответов) называют recall@k. В нашем случае нас интересуют recall@1, recall@2 и recall@3. При этом «правильный ответ» в нашей задаче только один (с точностью до близко расположенных точек), а значит, эта метрика как раз будет показывать долю случаев, когда настоящая «точка Б» попадает в топ 1, топ 2 и топ 3 нашего алгоритма.
В качестве базового алгоритма ранжирования мы взяли сортировку по количеству баллов и получили следующие результаты (в процентах): recall@1 = 63,7; recall@2 = 78,5 и recall@3 = 84,6. Заметим, что проценты здесь – это доля от тех случаев, где правильный ответ в кандидатах вообще присутствовал. В какой-то момент возник логичный вопрос: возможно, простая сортировка по популярности уже даёт хорошее качество, а все идеи сортировки по баллам и использование машинного обучения излишни? Но нет, такой алгоритм показал самое плохое качество: recall@1 = 41,2; recall@2 = 64,6; recall@3 = 74,7.
Запомним исходные результаты и перейдем к обсуждению модели машинного обучения.
Доля случаев, когда фактический пункт назначения попадал в число первых k рекомендаций
Какая модель строилась
Для начала опишем механизм нахождения кандидатов. Как мы уже говорили, на основании статистики поездок пользователя разным местам начисляются баллы. Точка получает баллы, если в нее или из нее совершаются поездки; причем существенно больше баллов получают те точки, в которые пользователь ездил из места, где сейчас находится, а ещё больше баллов, если это происходило примерно в это же время. Далее логика понятная.Теперь перейдём к модели для переранжирования. Так как мы хотим максимизировать recall@k, в первом приближении мы хотим прогнозировать вероятность поездки пользователя в определенное место и ранжировать места по вероятности. «В первом приближении» потому, что эти рассуждения верны только при очень точной оценке вероятностей, а когда в них появляются погрешности, recall@k может лучше оптимизироваться и другим решением. Простая аналогия: в машинном обучении, если мы точно знаем все распределения вероятностей, самый лучший классификатор — байесовский, но поскольку на практике распределения восстанавливаются по данным приближенно, часто другие классификаторы работают лучше.
Задача классификации ставилась следующим образом: объектами были пары (история предыдущих поездок пользователя; кандидат в рекомендации), где положительные примеры (класс 1) — пары, в которых пользователь все-таки поехал в эту точку Б, отрицательные примеры (класс 0) — пары, в которых пользователь в итоге поехал в другое место.
Таким образом, если побыть прожженным формалистом, модель оценивала не вероятность того, что человек поедет в конкретную точку, а сдвинутую вероятность того, что заданная пара «история-кандидат» является релевантной. Тем не менее, сортировка по этой величине столь же осмыслена, что и сортировка по вероятности поездки в точку. Можно показать, что при избытке данных это будут эквивалентные сортировки.
Классификатор мы обучали на минимизацию log loss, а в качестве модели использовали активно применяемый в Яндексе Матрикснет (градиентный бустинг над решающими деревьями). И если с Матрикснетом всё понятно, то почему всё-таки оптимизировался log loss?
Ну, во-первых, оптимизация этой метрики приводит к правильным оценкам вероятности. Причина, по которой так происходит, своими корнями уходит в математическую статистику, в метод максимального правдоподобия. Пусть вероятность единичного класса у i-го объекта равна , а истинный класс равен . Тогда, если считать исходы независимыми, правдоподобие выборки (грубо говоря, вероятность получить именно такой исход, который был получен) равно следующему произведению: В идеале нам хотелось бы иметь такие , чтобы получить максимум этого выражения (ведь мы хотим, чтобы полученные нами результаты были максимально правдоподобны, правда?). Но если прологарифмировать это выражение (так как логарифм — монотонная функция, то можно его максимизировать вместо исходного выражения), то мы получим . А это уже известный нам log loss, если заменить на их предсказания и умножить все выражение на минус-единицу.
Во-вторых, мы, конечно, доверяем теории, но на всякий случай попробовали оптимизировать разные функции потерь, и log loss показал самый большой recall@k, так что все в итоге сошлось.
О методе поговорили, о функции ошибки – тоже, осталась одна важная деталь: признаки, по которым мы обучали наш классификатор. Для описания каждой пары «история-кандидат» мы использовали более сотни разных признаков. Вот несколько для примера:
И, наконец, о результатах: после переранжирования с помощью построенной нами модели мы получили следующие данные (опять же в процентах): recall@1 = 72,1 (+8,4); recall@2 = 82,6 (+4,1); recall@3 = 88 (+3,4). Совсем неплохо, но в будущем возможны улучшения за счет включения в признаки дополнительной информации.
Можно посмотреть на примере, как новый алгоритм прогнозирования будет выглядеть для пользователя:
Дальнейшие планы
Разумеется, впереди много экспериментов по улучшению модели. Будет и добавление новых данных для построения рекомендаций, в том числе интересов пользователя, а также предполагаемых «дома» и «работы» из Яндекс Крипты и связанных с ними признаков, и эксперимент по сравнению различных методов классификации в этой задаче. Например, у Яндекса уже есть не только используемый сугубо внутри команды Матрикснет, но и набирающий популярность и в Яндексе, и за его пределами CatBoost. При этом, конечно же, нам интересно сравнивать не только собственные разработки, но и другие реализации популярных алгоритмов.Кроме того, как уже было сказано в начале поста – было бы здорово, если бы приложение само понимало, когда, куда и на какой машине нам нужно поехать. Сейчас сложно сказать, насколько по историческим данным возможно точно угадывать параметры заказа и настройки приложения, подходящие пользователю, но мы работаем в этом направлении, будем делать наше приложение все более «умным» и способным подстраиваться под вас.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru