ИИ для покера: как научить алгоритмы блефовать
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-09-07 13:10
Все эти успехи — про игры с информационной симметрией, где игроки имеют идентичную информацию о текущем состоянии игры. Это свойство полноты информации лежит в основе алгоритмов, обеспечивающих эти успехи, например, локальном поиске во время игры.
Но как обстоит дело с играми с неполной информацией?
Самым наглядный пример такой игры — покер. Чтобы на деле разобраться с этой игрой и алгоритмами решения этой задачи, мы организуем хакатон по написанию игровых ботов на основе машинного обучения. О том как научить алгоритмы блефовать и попробовать свои силы в покер, не трогая карты, под катом.
1. ИИ в играх с неполной информациейМир полон задач, связанных с взаимодействием между несколькими агентами. Исторически люди были основными участниками этих многоагентных ситуаций, однако c развитием ИИ у нас появилась возможность ввести алгоритмы в нашу повседневную жизнь как равноправных участников и агентов, с которыми можно взаимодействовать. Прямо сейчас подобные компьютерные агенты решают множество задач: от простых и безобидных как автоматические телефонные системы, до критически важных как управление безопасностью и даже управление автономным транспортом. Это позволяет существенно автоматизировать многие повседневные процессы, перенося принятие решений на алгоритмы и тем самым снижая нагрузку на человека.
Особенностью многих задач, где мы применяем компьютерных агентов, является большое количество ограничений реального мира, сказывающееся на сложности их программирования. А самое важное для компьютерных агентов — доступ ко всей необходимой для принятия решений информации. Разберем как это сказывается на модельных задачах ИИ — на том, как наши агенты играют в игры.
Игры с асимметрией и неполнотой информации требуют значительно более сложных подходов к принятию решений по сравнению с аналогичными по размерам играми с идеальной информацией, полностью доступной в любое время. Оптимальное решение в любой момент времени зависит от знания стратегии противников, зависящей от скрытой для нас и доступной только им информации, оценить которую можно только по их прошлым действия. Однако и их предыдущие действия тоже зависят от скрытой от них информации о наших действиях и того, как наши действия эту информацию раскрывали. Этот рекурсивный процесс показывает основную сложность в построении эффективных алгоритмов принятия решений.
Сложности в программировании агентов
Под агентом мы будем понимать любого автономного участника процесса, принимающего решения: как человека, так и компьютер. В мультиагентной среде агенты взаимодействуют между собой и не всегда знают стратегии, цели и возможности других агентов. Оптимальное поведение агента, максимизирующего свой результат в подобной среде, зависит от действий других агентов. Для построения эффективного агента в мультиагентной среде необходимо адаптироваться к действиям других агентов, моделируя их стратегии и обучаясь на основе их поведения.

Чтобы агенты могли адаптироваться в реальном времени, им необходимо выбирать оптимальные действия по ходу достижения своих результатов. Если использовать подходы, основанные на обучении с подкреплением (Reinforcement Learning), агенты будут накапливать награду за свои действия. Агенты также будут балансировать между следованием своему запланированному поведению (exploitation) и экспериментальными разведочными действиями (exploration), пытаясь узнать полезную информацию о стратегиях других игроков.
В дополнение и к без того сложной постановке задачи агенты столкнутся и с другими ограничениями, связанными с работой в мультиагентной среде с неполной информацией. Выпишем основные трудности, с которыми столкнутся наши агенты:
- Ограниченное число наблюдений. Как правило, агентам будет доступен лишь небольшой набор наблюдений для обучения. Это особенно критично в реальных приложениях, где участие агентов-людей недоступно в течение продолжительного времени.
- Стохастичность наблюдений. И среда взаимодействия агентов и сами агенты часто подвержены большому количеству случайных факторов. Выделить полезный сигнал для обучения и адаптации становится особенно затруднительно, если поведение агента является случайной величиной, зависящей от большого количества других случайных величин.
- Неполнота наблюдаемой информации. Это является ключевым свойством среды, в которой работают агенты. Агентам доступен лишь частичный и ограниченный ее обзор, скрывающий от агентов большинство информации о мире.
- Динамическое поведение. С ходом времени агенты могут адаптироваться к поведению друг друга, нивелируя достигнутый в ходе обучения и адаптации прогресс. Среда также может меняться с ходом времени, провоцируя агентов на новые действия, стратегии и поведение.
Все эти характеристики накладывают серьезные сложности на написание компьютерных агентов. Моделирование поведения агентов даже с одной из этих сложностей является сложной наукоемкой задачей, не говоря о реальных средах, где инженерам и авторам таких агентов придется столкнуться с полным перечнем этих трудностей. Мы поговорили об общем случае сложных сред — теперь перейдем к играм.
ИИ для покера
Показательным примером сложной среды со всеми описанными нами свойствами является игра в покер. В ней есть и неполнота информации о картах, и стратегии участвующих игроков, и элемент случайности, связанный с раздачей карт, и другие описанные нами трудности, возникающие во время игры. Более того, количество возможных состояний игры, характеризующих игровые ситуации, огромно. Настолько огромно, что лишь незначительно (в логарифмической шкале) уступает Го: в безлимитном Холдеме их 10 160 в то время как в Го их порядка 10 170.
Несмотря на то, что покер является азартной игрой, он признан официальным видом спорта, а национальные федерации спортивного покера есть почти в каждой стране (включая Россию). Сегодня у этой игры есть миллионы поклонников по всему миру, но даже когда покер еще был далек от мировой популярности, его ценили не только игроки, но и ученые. Пионер современной теории игр Джон фон Нейман был настолько очарован этой игрой блефа и ставок, что говорил:
« Реальная жизнь вся состоит из блефа, из маленьких приёмов обмана, из размышлений о том, каких действий ожидает от тебя другой человек. Вот что представляет игра в моей теории». Джон фон Нейман
История развития ИИ для игры в покер насчитывает более 30 лет, но самые выдающиеся достижения произошли буквально в последние 3 года.
Первые программы и алгоритмы игры в покер появились еще в 80-х годах, например, система Orac от Mike Caro, написанная им в 1984 и продемонстрированная на турнире Stratosphere. В 1991 году в Университете Альберты (Канада) была создана первая в мире исследовательская группа, посвященная развитию ИИ для покера. В 1997 году эта группа продемонстрировала свою систему Loki, первую успешную и значимую реализацию ИИ для покера. Loki играл на уровне немного хуже среднего человеческого игрока, но эта была значимая веха для всего исследовательского направления. В 2000-х годах произошел сдвиг парадигмы написания ИИ для покерных ботов. Исследователи отошли от подходов к покеру, вдохновленных успехами Deep Blue в шахматах (успешно одолевшему Гарри Каспарова в 1996 году), к полноценной методологии и постановке задач моделирования сразу для покера.
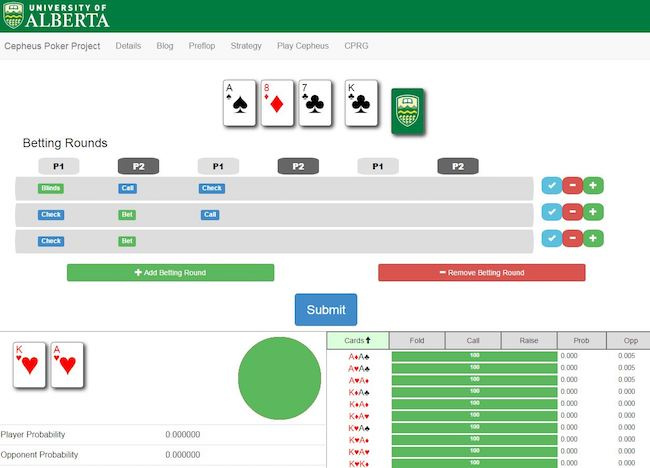 В 2015 году Университет Альберты представил свою систему Cepheus, которая буквально «решила» один из видов покера — лимитный Heads-up покер (упрощенная разновидность, порядка 10 18 игровых ситуаций). Это значимая веха в развитии AI, так как это единственная на данный момент игра с неполной информацией, имеющая полное оптимальное решение. Достичь этого удалось, поставив Cepheus играть сам с собой в течение двух месяцев (похожим образом обучался и AlphaGo, победивший чемпиона мира по игре Го).
В 2015 году Университет Альберты представил свою систему Cepheus, которая буквально «решила» один из видов покера — лимитный Heads-up покер (упрощенная разновидность, порядка 10 18 игровых ситуаций). Это значимая веха в развитии AI, так как это единственная на данный момент игра с неполной информацией, имеющая полное оптимальное решение. Достичь этого удалось, поставив Cepheus играть сам с собой в течение двух месяцев (похожим образом обучался и AlphaGo, победивший чемпиона мира по игре Го).
Важно отметить, что система не идеальна в том плане, что может иногда терять фишки в некоторых раздачах. Однако при достаточном числе партий Cepheus все равно выйдет победителем. Также важно заметить, что у безлимитной версии Heads-Up покера все еще нет аналогичного полного решения ввиду слишком большого числа игровых состояний.
В этом году произошло сразу два важных события в мире покерных ботов. Университет Альберты представил алгоритм DeepStack для игры в безлимитный Heads-Up покер. Основанный на глубоких нейронных сетях алгоритм успешно одолел множество человеческих соперников, включая профессиональных игроков и аналогично AlphaGo смог «обучиться» имитировать человеческую интуицию, продолжительно играя множество партий сам с собой.
Трансляция турнира Libratus против человека
Самое значимое событие 2017 года в мире покерных ботов, а возможно и ИИ в целом. Система Libratus от Университета Карнеги-Меллон с уверенностью одолела профессиональных игроков в покер — команду, состоящую из лучших мировых игроков в безлимитный Heads-Up покер. По их оценке, алгоритм был настолько хорош, что казалось словно он мухлюет и видит карты соперников. Матчи шли в реальном времени в течение 20-дневного турнира, а действия алгоритма считались на Питтсбургском суперкомпьютере.
Практическая ценность решений
Несмотря на кажущуюся малоприменимость покерных ботов к реальным задачам, их развитие принесло множество методов, которые с карточной игры можно перенести на практику. Алгоритмы современных покерных ботов, одолевающих лучших человеческих игроков, универсальны и в целом направлены на обучение агентов в средах с неполной и асимметричной информацией. Их можно перенести на множество приложений, где требуется принятие решений в аналогичной по сложности среде: от безопасности до маркетинга, в котором можно симулировать торги за аудиторию.
В банковской сфере тоже есть множество практических задач, где алгоритмы, стоящие за передовыми Покерными ботами нашли бы применение. Среди таких бизнес-задач Сбербанка стоит в первую очередь отметить управление риск-доходностью и ценообразование на рынке с множеством других банков-объектов. Но список этих приложений можно легко расширить на такие задачи как Customer Value Management или Next Best Action.
2. Sberbank Holdem Challenge

Хакатон по написанию игровых ботов на основе машинного обучения
Чтобы подстегнуть развитие машинного обучения и искусственного интеллекта мы организуем уникальный хакатон, который предваряется онлайн-соревнованием. Мы приглашаем специалистов по машинному обучению попробовать свои силы в написании игрового искусственного интеллекта, который сможет принимать оптимальные решения в условиях неопределенности и моделировать поведение других игроков в покере.
« Искусственный интеллект сегодня должен служить не только для разработки рациональных алгоритмов, но и для моделирования нерационального поведения участников рынка или, как в случае с нашим турниром, игроков в покер». Александр Ведяхин, старший вице-президент Сбербанка
Мы надеемся, что наработки победителей могут найти применение в разработках искусственного интеллекта Сбербанка. Тем не менее, даже если до практической применимости этих наработок могут пройти годы, подобные хакатоны важны для развития науки на подобных модельных задачах.
Задача участников
Игра, для которой необходимо написать своего покерного бота, — наиболее популярная разновидность покера: Безлимитный Техасский Холдем (No-limit Texas Hold’em). Она же является самой сложной разновидностью игры, к успехам в которой не подошла ни одна исследовательская группа: в ней участвует не 2, а 9 игроков, а число игровых комбинаций огромно и достигает 10 160.
Участникам предстоит реализовать агента, который будет играть в покер. Покерная игра представляет собой последовательную серию раздач (раундов), которая заканчивается, когда все покерные фишки остаются только у одного игрока, либо пока не выйдет лимит числа раундов. В каждой игре принимают участие 9 агентов игроков-ботов.
Из агентов участников будут случайным образом формироваться игры и турниры, по итогам которых будут определяться лучшие стратегии. В момент начала игры каждому агенту выдается банк времени, который можно использовать для принятия решений в течении турнира. Если агент выходит за лимит по времени или же агент присылает ответ, не соответствующий протоколу передачи данных, то симулятор совершает автоматический сброс карт в каждой из раздач до окончания турнира.
Программа соревнования
Соревнование проходит в 2 этапа: индивидуальный отборочный турнир и командный офлайн-хакатон для 100 финалистов. 100 лучших участников, которые пройдут отборочный онлайн-этап, будут приглашены на закрытый офлайн-хакатон.
- 30 августа, 12:00
Старт онлайн-этапа соревнования на платформе конкурса, начало отправки решений. - 18 сентября, 03:00 (срок продлен с 15 сентября 23:59)
Закрытие онлайн-этапа, рейтингование участников и отбор финалистов (топ-100). - 23 сентября, 10:00
Старт оффлайн-этапа хакатона в Корпоративном Университете Сбербанка. - 24 сентября, 16:00.
Финал хакатона, подведение итогов, церемония награждения победителей.
Отборочный онлайн-этап проходит в индивидуальном режиме. Во время онлайн-этапа команда конкурса предоставляет тестовую среду для оффлайн-хакатона, чтобы участники научились писать своих покерных ботов. Также во время онлайн-этапа каждую полночь по расписанию проводится более 100 случайных турниров, ежедневно определяющих рейтинг ботов. Во время оффлайн-этапа участники смогут формировать между собой команды, а определяющие рейтинг участников турниры будут происходить между всеми участниками каждый час.
Хакатон проходит при непосредственном участии Академии технологий и данных Корпоративного Университета Сбербанка, финал хакатона пройдет в кампусе Корпоративного Университета, где финалистам предстоит доработать свои алгоритмы.

Кампус Корпоративного Университета Сбербанка
Участникам офлайн-этапа предоставляются трансфер из Москвы на территорию кампуса, проживание в отеле, питание, а также остальные услуги и великолепные возможности кампуса. Там состоится финал соревнования и пройдет покер-турнир между ботами с участием профессиональных комментаторов.
К сожалению, в данном соревновании могут принять участие только граждане РФ. Логистика до Москвы также остается на самих участниках. В связи с этим, места в оффлайн-хакатоне тех, кто пройдет в топ-100, но по каким-то причинам не сможет приехать на оффлайн-этап, будут переданы следующим после них в списке рейтинговой таблицы.
Призовой фонд для лучших трех команд-победителей — 600 000 рублей.

3. Программирование стратегий
Давайте разберем, как можно реализовать своего покерного бота и привести его к победе. Для этого нам понадобятся 3 вещи:
— Язык программирования, с которым мы уверенно себя чувствуем (есть готовые примеры на Python и C++).
— Симулятор игры в покер, внутри которого будет работать наш бот. В качестве симулятора используется Open-Source библиотека PyPokerEngine
— Код самого бота, который совершает игровые действия внутри симулятора.
Давайте сперва разберемся с ботом, чтобы увидеть, что это не так сложно.
Пример простого бота
Посмотрим на пример самого простого бота на языке Python, который каждый раз совершает операцию CALL, то есть всегда уверен в себе и только и делает, что уравнивает ставку оппонентов:
from pypokerengine.players import BasePokerPlayer class FishPlayer(BasePokerPlayer): def declare_action(self, valid_actions, hole_card, round_state): call_action_info = valid_actions[1] action, amount = call_action_info["action"], call_action_info["amount"] return action, amount def receive_game_start_message(self, game_info): pass def receive_round_start_message(self, round_count, hole_card, seats): pass def receive_street_start_message(self, street, round_state): pass def receive_game_update_message(self, action, round_state): pass def receive_round_result_message(self, winners, hand_info, round_state): passБот представляет собой объект, в котором реализованы методы-обработчики игровых событий и метод выбора действия в момент хода бота declare_action. Подробнее про реализацию игровых стратегий можно прочитать в документации к библиотеке.
Разработка игровых стратегий доступна не только на языке Python и может быть осуществлена на любом другом языке программирования. Описание API и руководство по созданию ботов читайте в руководстве по подготовке ботов.
Ежедневно в 00:00 MSK проводится турнир между всеми отправленными в систему ботами. Если участник отправил несколько агентов, то учитывается только его последнее отправленное решение.
Во время турнира каждый бот играет серию игр со случайными соперниками — ботами других участников. Таблица результатов строится по убыванию средней суммы оставшихся фишек у бота по итогам всех игр за турнир.
В турнирной игре принимают участие ровно 9 ботов. Максимальное число раундов — 50. В начале игры каждый бот получает 1500 фишек, размер малого блайнда — 15.
Это соответствует следующим параметрам раунда в PyPokerEngine:
config = setup_config(max_round=50, initial_stack=1500, small_blind_amount=15)Анализ реплеев игр
По окончанию турнира, участникам будет доступны архивы с журналом игр всех ботов. Таким образом, вы сможете проанализировать стратегию своих оппонентов, просматривая их действия по время игры. Однако помните, что другие участники также могут анализировать стиль игры вашего бота и к следующему турниру устроить вашему боту засаду.
Пример файла с реплеем игры: example_game_replay.json
Реплеи игры записываются в виде JSON-объекта с полями:
rule: параметры игры
seats: информация о ботах, в частности для каждого бота указано его имя name — это имя соответствует участнику, отправившему бота
rounds: список всех раундов с указанием действий, совершенных ботами
Подготовка решения к отправке
В качестве среды для запуска ботов используется специально подготовленный docker-образ. В проверяющую систему необходимо отправить код бота, запакованный в ZIP-архив.
Пример архивов:
? example-python-bot.zip
? example-cpp-bot.zip
В корне архива обязательно должен быть файл metadata.json следующего содержания:
{ " image": "sberbank/python", "entry_point": "python bot.py" }Здесь image — название docker-образа, в котором будет запускаться решение, entry_point — команда, при помощи которой необходимо запустить решение. Для программы-бота текущей директорией будет являться корень архива, кроме исполняемого файла вы можете положить любые другие вспомогательные. Ограничение на размер архива — 1Гб.
Практически для любого языка программирования существует docker-окружение, в котором вы можете запустить своего бота:
- sberbank/python — Python3 с установленным большим набором библиотек
- gcc — для запуска компилируемых C/C++ решений (подробнее здесь)
- node — для запуска JavaScript
- openjdk — для Java
- mono — для C#
- Также подойдет любой другой образ, доступный для загрузки из DockerHub
Исполняемая команда обменивается с симулятором игры через stdin/stdout. Симулятор передает по одному событию в строчке stdin, в формате event_type< >data , где data — JSON-объект с параметрами события. Пример входных данных, которые симулятор подает в stdin. Описание событий и их параметров.
В ответ на событие declare_action бот должен в отведенное время ответить в stdout строчкой в формате:
action< >amount Здесь action — одно из доступных игроку действий (fold, call, raise), amount — количество фишек для действия raise, 0 в остальных случаях.
В случае использования буферизованного ввода/вывода, не забудьте сбрасывать буфер ( flush() ) после записи действия в stdout. Иначе симулятор может не получить сообщение и у бота выйдет лимит по времени.
Разработку бота на языке Python удобнее всего делать с помощью библиотеки PyPokerEngine как показано в примере выше. Запуск при этом рекомендуется делать в docker-окружении sberbank/python, в котором установлен Python 3, а также большой набор библиотек, включая непосредственно PyPokerEngine и джентельменский набор data scientist-а: numpy, scipy, pandas, sklearn, tensorflow, keras. Полный список установленных python-пакетов можно найти в этом файле.
Полный код примера покерного бота на python доступен ниже.
bot.py
import sys import json from pypokerengine.players import BasePokerPlayer class MyPlayer(BasePokerPlayer): # Do not forget to make parent class as "BasePokerPlayer" # we define the logic to make an action through this method. (so this method would be the core of your AI) def declare_action(self, valid_actions, hole_card, round_state): # valid_actions format => [raise_action_info, call_action_info, fold_action_info] call_action_info = valid_actions[1] action, amount = call_action_info["action"], call_action_info["amount"] return action, amount # action returned here is sent to the poker engine def receive_game_start_message(self, game_info): pass def receive_round_start_message(self, round_count, hole_card, seats): pass def receive_street_start_message(self, street, round_state): pass def receive_game_update_message(self, action, round_state): pass def receive_round_result_message(self, winners, hand_info, round_state): pass if __name__ == '__main__': player = MyPlayer() while True: line = sys.stdin.readline().rstrip() if not line: break event_type, data = line.split(' ', 1) data = json.loads(data) if event_type == 'declare_action': action, amount = player.declare_action(data['valid_actions'], data['hole_card'], data['round_state']) sys.stdout.write('{} {} '.format(action, amount)) sys.stdout.flush() elif event_type == 'game_start': player.set_uuid(data.get('uuid')) player.receive_game_start_message(data) elif event_type == 'round_start': player.receive_round_start_message(data['round_count'], data['hole_card'], data['seats']) elif event_type == 'street_start': player.receive_street_start_message(data['street'], data['round_state']) elif event_type == 'game_update': player.receive_game_update_message(data['new_action'], data['round_state']) elif event_type == 'round_result': player.receive_round_result_message(data['winners'], data['hand_info'], data['round_state']) else: raise RuntimeError('Bad event type "{}"'.format(event_type))metadata.json
{ " image": "sberbank/python", "entry_point": "python bot.py" }Для СС++ также обратите внимание на инструкцию по запуску ботов на компилируемых языках. Полная документация по подготовке ботов к отправке доступна здесь.
4. Подходы к созданию стратегий
За более чем 30-летнюю историю развития покерных ботов было создано несколько семейств подходов в разработке стратегий в покер.
Классические подходы
Одним из наиболее простых в реализации и наименее затратных по времени является экспертная система. По сути это набор фиксированных IF-THEN правил, который относит игровую ситуацию к одному из заранее определенных классов. В зависимости от силы собранной комбинации система предлагает принять одно из множества доступных решений.
Также эту задачу можно решать сугубо математическим методом и в каждый момент времени рассчитывать оптимальное решение с точки зрения равновесия по Нэшу. Однако, решение будет оптимальным в том случае, если решения остальных участников тоже оптимальны. Поиск такого решения является ресурсозатратным, поэтому на практике его можно использовать только наряду с большим кол-вом ограничений в правилах. Например, в лимитном техасском холдеме для двух агентов или при возникновении определенных игровых ситуаций.
Подходы на основе машинного обучения
Более эффективной является эксплуатационная стратегия, которая разделяет оппонентов на кластеры и против каждого кластера реализуется контр-стратегия. Большинство хороших игроков в покер используют именно такой подход. Но, в отличие от человека, у компьютера есть преимущество в том, что он может перебрать огромное кол-во исходов игры и при правильном прогнозировании поведения соперников принять максимально выгодное решение с точки зрения математического ожидания. Для прогнозирования поведения оппонентов в таком случае может хорошо помочь сбор статистики игр в прошлых матчах и реализация алгоритмов машинного обучения. К сожалению авторов алгоритмов, перебрать все возможные исходы событий в большинстве игровых ситуаций не получится даже у мощных компьютеров, поэтому нужно использовать алгоритмы оптимизации, такие как Monte Carlo Tree Search. Пример реализации подобной стратегии.
Наконец, можно подойти к созданию стратегии еще более абстрактно и реализовать нейросеть, на входе у которой будут параметры игровой ситуации, а на выходе — множество возможных решений. К минусам этого подхода стоит отнести то, что в этом случае потребуется большой набор данных для обучения. Этот минус можно нивелировать, запустив нейросеть играть саму с собой на подобие подхода AlphaGo, но нужно быть готовым к более чем одним суткам обучения и моделирования. Про более сложные научные подходы к созданию покерных ботов можно почитать статьи профессоров из канадского университета Альберты, которые решают эту задачу уже не одно десятилетие.

Архитектура нейронной сети Deepstack
В частности, выше представлена архитектура нейронной сети, использованной в алгоритме DeepStack, о котором мы писали в самом начале. На вход сети передаются данные о размере ставок, раскрытых картах и информация об игроках, после чего их данные преобразуются в представление «кластеров карточных рук». Эта информация подается на вход 7-слойной нейронной сети, после чего ее результат дополнительно пост-обрабатывается для удовлетворения теоретико-игровым критериям нулевой суммы. Подробности про DeepStack доступны в статье Университета Альберты.
Как мы можем видеть, простор для возможных решений одной из самых сложных для ИИ игр на сегодняшний день огромен. Участники Sberbank Holdem Challenge вольны использовать любой подход или их комбинацию, приводящую их бота к победе.
5. Платформа хакатона
Рабочая платформа для решения онлайн-этапа размещена на holdem.sberbank.ai. На ней вы найдете все необходимые материалы, а также сможете зарегистрировать и отправлять свои решения для онлайн-этапа.

Мы не ожидаем сверх-человеческих результатов решений на онлайн этапе, так как понимаем, что на такую сложную задачу требуется много времени. Однако, во время онлайн-этапа можно научиться писать собственных покерных ботов, разобраться с платформой и форматом решений.
И конечно, приложив чуть-чуть усилий, можно попасть на оффлайн-этап соревнования — базовый пример бота все еще в топ-100 :)
До конца онлайн-этапа осталось меньше двух недель — торопитесь!
6. Ссылки
Основная страница хакатона Sberbank Holdem Challenge
Платформа Sberbank Holdem Challenge
Успехи 2017 года покер-бота Libratus
20-летняя история развития ИИ для покера (En)
Обзор подходов к ИИ в покере
Научная группа применения ML в покере, университет Альберты
Алгоритм DeepStack, примененный для победы в Heads-Up безлимитный покер
Детальная статья от авторов DeepStack (En)
Правила игры в Texas Hold'em Poker]
Телеграм: t.me/ainewsline
Источник: habrahabr.ru