Случайный лес vs нейросети: кто лучше справится с задачей распознавания пола в речи (ч.2)
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-08-24 15:49

Первая часть нашего гайда была посвящена интересной задаче машинного обучения – распознаванию пола по голосу. Мы описали общий подход к большинству задач speech processing и с помощью случайного леса, обученного на статистиках акустических признаков, решили задачу с довольно большой точностью – 98,4% верно классифицированных аудиофрагментов.
Во второй части гайда мы посмотрим, справятся ли нейронные сети с этой задачей эффективнее случайного леса, а также попробуем учесть самый большой недостаток классических методов – неумение работать с последовательностями данных.
В каком-то смысле эта ступень избыточна: пол человека не меняется во время разговора (по крайней мере, на текущем этапе развития и в заданных стандартных условиях), поэтому рассчитывать на увеличение точности не стоит. Но в академических целях мы попробуем.
 / Фотография Tristan Bowersox / CC-SA
/ Фотография Tristan Bowersox / CC-SA
Очередная глава о том, как работают нейронные сети
Считается, что искусственная нейронная сеть (нейросеть) – это математическая модель человеческого мозга. На самом деле нет: 50-60 лет назад биологи на определенном уровне изучили электрические процессы в мозге, а математики создали упрощенную модель и запрограммировали.
Оказалось, что такие структуры способны решить некоторые простые задачи, но а) хуже классических методов и б) намного медленнее их. И неоспоримый статус-кво сохранялся на протяжении полувека – ученые разрабатывали теорию (способы обучения, архитектуры, фундаментальные математические вопросы), а компьютерная техника и ПО развились настолько, что на домашнем ПК стало возможно решать некоторые задачи на мировом уровне.
Но не все так гладко: нейросеть может научиться отличать гепарда от леопарда, а может посчитать одним из этих животных пятнистый диван. Кроме того, процессы обучения человека и машины разные: компьютеру нужны тысячи обучающих примеров, тогда как человеку хватает нескольких. Очевидно, что работа искусственных нейронных сетей не сильно похожа на мышление человека, и они являются не компьютерной моделью мозга, а лишь еще одним классом моделей в списке: Random Forest, SVM, XGBoost и т.д., хоть и с выгодными особенностями.
Исторически первая рабочая архитектура нейронной сети – многослойный персептрон. Он состоит из слоев, а каждый слой – из нейронов. Сигнал передается в одну сторону – от первого слоя к последнему, и каждый нейрон текущего слоя связан со всеми нейронами предыдущего, причем с разными весами. Вес связи между двумя нейронами имеет физический смысл ее значимости: чем больше его значение, тем больший вклад будет внесен в выходное значение нейрона. Обучить нейросеть – значит найти такие значения весов, чтобы на выходном слое получалось то, что нам нужно.
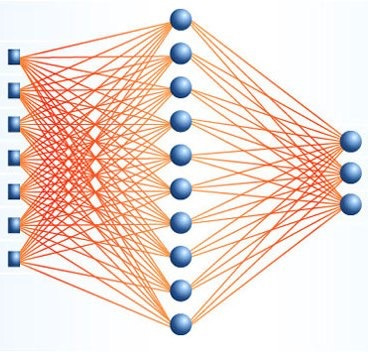
Полносвязные архитектуры качественно не отличаются от классических методов: на вход они принимают вектор чисел, каким-то образом их обрабатывают, а на выходе получается набор вероятностей принадлежности входного вектора к одному из классов (это так для задачи классификации, но можно рассмотреть и другие). На практике для обработки входных признаков используют другие архитектуры (сверточные, рекуррентные), получая так называемые высокоуровневые признаки, а затем обрабатывают их с помощью полносвязных слоев.
Разбор работы сверточных сетей можно найти тут и тут (их тысячи, поэтому оставляем выбор за читателем), а рекуррентные мы разберем отдельно. На вход они принимают последовательности чисел, не важно, признаки ли это, значения сигнала или метки слов. Роль нейронов для них обычно выполняют специальные ячейки, которые помимо суммирования входного сигнала и получения выходного имеют набор дополнительных параметров – внутренних значений, которые запоминаются и влияют на выходное значение ячейки.
Сегодня самой широко применяемой рекуррентной архитектурой является Long Short-Term Memory (LSTM). В простейшей реализации в каждой ячейке присутствуют три особенных элемента: входной, выходной и вентиль забывания. Они определяют, в каких пропорциях нужно «смешать» обработанные входные данные и запомненные значения, чтобы на выходе получился наиболее полезный сигнал. Обучить LSTM сеть – значит найти такие параметры вентилей и веса связей между LSTM ячейками на первых слоях и нейронами последних слоев, при которых для входной последовательности выходной слой возвращал бы вероятности принадлежности к каждому из классов.
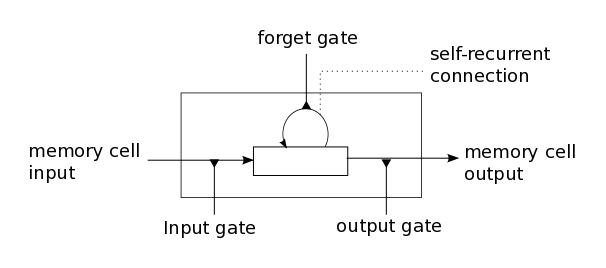
Первоначальные настройки
Надеемся, что вы прочитали первую часть этого гайда. В ней можно найти описание речевой базы, вычисленных признаков, а также результаты работы классификатора Random Forest. Он обучался на статистиках признаков, подсчитанных на хороших (до определенного предела), отфильтрованных участках речи – фреймах. Для каждого признака считались среднее, медианное, минимальное и максимальное значения, а также стандартное отклонение.
Нейросети более требовательны к количеству обучающих примеров. В прошлой части мы обучались на 436 аудиофрагментах от 109 спикеров (по четыре высказывания для каждого), взятых из базы VCTK. Оказалось, что ни одна из проверенных нами нейросетевых архитектур не смогла обучиться до разумных значений точности, и мы взяли больше фрагментов – всего 5000. Однако увеличенная выборка не привела к значительному росту точности – 98,5% верно классифицированных фрагментов. Первый эксперимент, который мы хотим поставить, заключается в обучении полносвязной нейронной сети на том же наборе признаков.
Весь код продолжаем писать на Python, реализацию нейронных сетей берем из Keras – удобнейшей библиотеки, посредством которой можно реализовать нужные архитектуры за пару строк.
Импортируем все, что нам понадобится:
import csv, os import numpy as np import sklearn from sklearn.ensemble import RandomForestClassifier as RFC from sklearn.model_selection import GroupKFold from keras.models import Model from keras.callbacks import ModelCheckpoint from keras.layers import Input, Dense, Dropout, LSTM, Activation, BatchNormalization from keras.layers.wrappers import Bidirectional from keras.utils import to_categorical
Реализацию случайного леса берем из sklearn, оттуда же – кросс-валидацию по группам. Из Keras берем базовый класс для моделей, слои, враппер Bidirectional, позволяющий использовать двунаправленную LSTM, а также функцию to_categorical, кодирующую метки классов в one-hot вектора.
Читаем все данные:
with open('data.csv', 'r')as c: r = csv.reader(c, delimiter=',') header = next(r) data = [] for row in r: data.append(row) data = np.array(data) genders = data[:, 0].astype(int) speakers = data[:, 1].astype(int) filenames = data[:, 2] times = data[:, 3].astype(float) pitch = data[:, 4:5].astype(float) features = data[:, 4:].astype(float)
И получаем выборку:
def make_sample(x, y, subj, names, statistics=[np.mean, np.std, np.median, np.min, np.max]): avx = [] avy = [] avs = [] keys = np.unique(names) for ki, k in enumerate(keys): idx = names == k v = [] for stat in statistics: v += stat(x[idx], axis=0).tolist() avx.append(v) avy.append(y[idx][0]) avs.append(subj[idx][0]) return np.array(avx), np.array(avy).astype(int), np.array(avs).astype(int) filter_idx = pitch[:, 0] > 1 filtered_average_features, filtered_average_genders, filtered_average_speakers = make_sample(features[filter_idx], genders[filter_idx], speakers[filter_idx], filenames[filter_idx])
Здесь мы применили фильтрацию по частоте – выкинули из рассмотрения те участки речи, на которых не определилась частота основного тона (pitch). Такое может произойти в двух случаях: фрейм не соответствует речи вообще, либо соответствует согласным звукам или шепоту. В нашей задаче мы можем выкинуть абсолютно все фреймы без питча, но во многих других фильтрацию нужно проводить менее жадно.
Дальше нужно реализовать полносвязную нейронную сеть:
def train_dnn(x, y, tx, ty): yc = to_categorical(y) # one-hot encoding for y tyc = to_categorical(ty)# one-hot encoding for y_test inp = Input(shape=(x.shape[1],)) model = BatchNormalization()(inp) model = Dense(100, activation='tanh')(model) model = Dropout(0.5)(model) model = Dense(100, activation='tanh')(model) model = Dropout(0.5)(model) model = Dense(100, activation='sigmoid')(model) model = Dense(2, activation='softmax')(model) model = Model(inputs=[inp], outputs=[model]) model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['acc']) modelcheckpoint = ModelCheckpoint('model.weights', monitor='val_loss', verbose=1, save_best_only=True, mode='min') model.fit(x, yc, validation_data=(tx, tyc), epochs=100, batch_size=100, callbacks=[modelcheckpoint], verbose=2) model.load_weights('model.weights') return model
Первый слой сети – Batch Normalization. Он позволяет избавиться от необходимости нормализовывать данные, а также ускоряет процесс обучения и дает возможность в какой-то степени избежать переобучения. Вначале каждый батч (порция данных на каждой итерации обучения) нормализуется на свои собственные среднее и стандартное отклонения, а затем шкалируется с помощью линейного преобразования, параметры которого подлежат оптимизации.
Примерно с той же целью после каждого полносвязного слоя стоят Dropout слои. Они случайно выбирают некоторую часть нейронов (в нашем случае половину) предыдущего слоя и обнуляют их выходные значения. Это позволяет сделать сеть более стабильной: даже если мы удалим часть связей, она все равно будет давать правильный ответ. Ровно по этой причине на практике слои с удвоенным числом нейронов и 50% dropout оказываются более эффективны, чем обычные слои.
Dense – непосредственно полносвязные слои. Их выходы представляют собой классическую взвешенную с некоторыми весами сумму входных сигналов, нелинейно преобразованную с помощью функции активации. На первых слоях это tanh, а на последнем – softmax, чтобы сумма выходного сигнала равнялась единице и соответствовала вероятностям быть в одном из классов. Model checkpoint – это скорее декоративная штука, перезаписывающая модель после каждой эпохи обучения, только если мера ошибки на тестовой выборке – validation loss – меньше, чем у прошлой сохраненной модели. Так гарантируется, что в model.weights будет записана наиболее эффективная модель.
Остается описать процесс кросс-валидации по спикерам и сравнить описанную выше полносвязную сеть и случайный лес на одних и тех же данных:
def subject_cross_validation(clf, x, y, subj, folds): gkf = GroupKFold(n_splits=folds) scores = [] for train, test in gkf.split(x, y, groups=subj): if clf == 'dnn': model = train_dnn(x[train], y[train], x[test], y[test]) score = model.evaluate(x[test], to_categorical(y[test]))[1] scores.append(score) elif clf == 'lstm': model = train_lstm(x[train], y[train], x[test], y[test]) score = model.evaluate(x[test], to_categorical(y[test]))[1] scores.append(score) else: clf.fit(x[train], y[train]) scores.append(clf.score(x[test], y[test])) return np.mean(scores) score_filtered = subject_cross_validation(RFC(n_estimators=1000), filtered_average_features, filtered_average_genders, filtered_average_speakers, 5) print score_filtered score_filtered = subject_cross_validation('dnn', filtered_average_features, filtered_average_genders, filtered_average_speakers, 5) print('Utterance classification an averaged features over filtered frames, accuracy:', score_filtered)
Получили примерно одинаковые значения точности – 98,6% для случайного леса и 98,7% для нейронной сети. Вероятно, можно оптимизировать параметры и получить более высокую точность, но сразу приступим к тому, ради чего все и затевалось: к рекуррентным сетям.
def make_sequences(x, y, subj, names): sx = [] sy = [] ss = [] keys = np.unique(names) sequence_length = 100 for ki, k in enumerate(keys): idx = names == k v = x[idx] w = np.zeros((sequence_length, v.shape[1]), dtype=float) sh = v.shape[0] if sh <= sequence_length: dh = sequence_length - sh if dh % 2 == 0: w[dh//2:sequence_length-dh//2, :] = v else: w[dh//2:sequence_length-1-dh//2, :] = v else: dh = sh - sequence_length w = v[sh//2-sequence_length//2:sh//2+sequence_length//2, :] sx.append(w) sy.append(y[idx][0]) ss.append(subj[idx][0]) return np.array(sx), np.array(sy).astype(int), np.array(ss).astype(int)
Для начала требуется составить выборку из последовательностей. Keras, несмотря на свою простоту, иногда бывает привередливым, и тут необходимо, чтобы входные переменные в методы .fit или .fit_on_batch могли быть естественным образом преобразованы в тензоры. Например, последовательности разной длины (а у нас именно этот случай) таким свойством не обладают.
Это сугубо техническое ограничение библиотеки можно обойти несколькими способами. Первый – обучение на батчах размера 1. Очевидные минусы такого подхода – неприменимость batch normalization и катастрофическое увеличение времени обучения.
Второй способ заключается в дописывании нулей к последовательности (padding), чтобы получилась нужная размерность. На первый взгляд это кажется неправильным, но сеть обучается не реагировать на такие значения. Также эти методы можно комбинировать – разбить последовательности по длине на несколько групп, внутри каждой провести padding и обучать.
Мы рассмотрим последовательности длины 100 – это соответствует одной секунде речи. Для этого длинные последовательности обрежем так, чтобы осталось ровно 100 точек, причем симметричных относительно середины, а короткие дополним нулями в начале и конце до искомой длины.
def train_lstm(x, y, tx, ty): yc = to_categorical(y) tyc = to_categorical(ty) inp = Input(shape=(x.shape[1], x.shape[2])) model = BatchNormalization()(inp) model = Bidirectional(LSTM(100, return_sequences=True, recurrent_dropout=0.1), merge_mode='concat')(model) model = Dropout(0.5)(model) model = Bidirectional(LSTM(100, return_sequences=True, recurrent_dropout=0.1), merge_mode='concat')(model) model = Dropout(0.5)(model) model = Bidirectional(LSTM(2, return_sequences=False, recurrent_dropout=0.1), merge_mode='ave')(model) model = Activation('softmax')(model) model = Model(inputs=[inp], outputs=[model]) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['acc']) modelcheckpoint = ModelCheckpoint('model.weights', monitor='val_loss', verbose=1, save_best_only=True, mode='min') model.fit(x, yc, validation_data=(tx, tyc), epochs=100, batch_size=50, callbacks=[modelcheckpoint], verbose=2) model.load_weights('model.weights') return model
Враппер Bidirectional с помощью merge_mode склеивает выходы слоя-аргумента для обычной входной последовательности и в обратном порядке. В нашем случае это LSTM слой со 100 ячейками. Флаг return_sequences определяет, будет ли возвращаться последовательность внутренних состояний ячеек, либо вернется только последняя.
Внутри LSTM и после рекуррентных слоев применяется dropout, а после последнего слоя (у которого return_sequences=False) стоит softmax функция активации. Также модель компилируется с оптимизатором Rmsprop – модификацией стохастического градиентного спуска. На практике часто оказывается, что для рекуррентных сетей он работает лучше, хотя это строго не доказано и всегда может быть по-другому.
filter_idx = pitch[:, 0] > 1 filtered_sequences_features, filtered_sequences_genders, filtered_sequences_speakers = make_sequences(features[filter_idx], genders[filter_idx], speakers[filter_idx], filenames[filter_idx]) score_lstmfiltered = subject_cross_validation('lstm', filtered_sequences_features, filtered_sequences_genders, filtered_sequences_speakers, 5) print score_lstm_filtered
Ура! 99,1% верно классифицированных точек на 5-fold кросс-валидации по спикерам. Это лучший результат среди всех рассмотренных архитектур.
Заключение
Львиная доля гидов по машинному обучению, статей и научно-популярных материалов посвящены распознаванию изображений. Сильно реже – обучению с подкреплением. Еще реже – audio processing. Отчасти, наверное, это связано с тем, что методы «из коробки» для обработки аудио не работают, и приходится тратить свое время на понимание процессов, предобработку данных и прочие неизбежные итерации. Но ведь именно сложность делает задачу интересной. Распознавание пола кажется простой задачей, ведь человек справляется с ней практически безошибочно. Но ее решение методами машинного обучения «в лоб» демонстрирует точность около 70%, что объективно мало. Однако даже простые алгоритмы позволяют достичь точности около 97-98%, если делать всё правильно: например, отфильтровать исходные данные. Сложные нейросетевые подходы увеличивают точность до более чем 99%, что едва ли принципиально отличается от человеческих показателей.
На самом деле потенциал рекуррентных нейронных сетей в этой статье раскрыт не полностью. Даже для задачи классификации (many to one) их можно использовать более эффективно. Но делать это, разумеется, мы пока не будем. Предлагаем читателям обойтись без фильтрации фреймов, позволив сети самой научиться обрабатывать только нужные фреймы, и рассмотреть более длинные (либо более короткие, или прореженные) последовательности.
Над материалом работали:
- Григорий Стерлинг, математик, ведущий эксперт Neurodata Lab по машинному обучению и анализу данных
- Ева Казимирова, биолог, физиолог, эксперт Neurodata Lab в области акустики, анализа голоса и речевых сигналов
Оставайтесь с нами.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru