Распознавание дорожных знаков с помощью CNN: Инструменты для препроцессинга изображений
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-08-01 15:52
реализация нейронной сети, распознавание образов, разработка беспилотных автомобилей

Привет, Хабр! Продолжаем серию материалов от выпускника нашей программы Deep Learning, Кирилла Данилюка, об использовании сверточных нейронных сетей для распознавания образов — CNN (Convolutional Neural Networks)
Введение
За последние несколько лет сфера компьютерного зрения (CV) переживает если не второе рождение, то огромный всплеск интереса к себе. Во многом такой рост популярности связан с эволюцией нейросетевых технологий. Например, сверточные нейронные сети (convolutional neural networks или CNN) отобрали себе большой кусок задач по генерации фич, ранее решаемых классическими методиками CV: HOG, SIFT, RANSAC и т.д.Маппинг, классификация изображений, построение маршрута для дронов и беспилотных автомобилей — множество задач, связанных с генерацией фич, классификацией, сегментацией изображений могут быть эффективно решены с помощью сверточных нейронных сетей.

MultiNet как пример нейронной сети (трех в одной), которую мы будем использовать в одном из следующих постов. Источник.
Предполагается, что читатель имеет общее представление о работе нейронных сетей. В сети есть огромное количество постов, курсов и книг на данную тему. К примеру:
- Chapter 6: Deep Feedforward Networks — глава из книги Deep Learning от I.Goodfellow, Y.Bengio и A.Courville. Очень рекомендую.
- CS231n Convolutional Neural Networks for Visual Recognition? — популярный курс от Fei-Fei Li и Andrej Karpathy из Стэнфорда. В курсе содержатся отличные материалы сделан упор на практику и проектирование.
- Deep Learning? — курс от Nando de Freitas из Оксфорда.
- Intro to Machine Learning? — бесплатный курс от Udacity для новичков с доступным изложением материала, затрагивает большое количество тем в машинном обучении.
Совет: чтобы убедиться в том, что вы владеете основами нейронных сетей, напишите свою сеть с нуля и поиграйте с ней!
Вместо того, чтобы повторять основы, данная серия статей фокусируется на нескольких конкретных архитектурах нейронных сетей: STN (spatial transformer network), IDSIA (сверточная нейросеть для классификации дорожных знаков), нейросеть от NVIDIA для end-to-end разработки автопилота и MultiNet для распознавания и классификации дорожной разметки и знаков. Приступим!
Тема данной статьи — показать несколько инструментов для предобработки изображений. Общий пайплайн обычно зависит от конкретной задачи, я же хотел бы остановиться именно на инструментах. Нейросети — совсем не те магические черные ящики, какими их любят преподносить в медиа: нельзя просто взять и «закинуть» данных в сетку и ждать волшебных результатов. По правилу shit in — shit out в лучшем случае, вы получите score хуже на несколько пунктов. А, скорее всего, просто не сможете обучить сеть и никакие модные техники типа нормализации батчей или dropout вам не помогут. Таким образом, работу нужно начинать именно с данных: их чистки, нормализации и нормировки. Дополнительно стоит задуматься над расширением (data augmentation) исходного картиночного датасета с помощью аффинных преобразований типа вращения, сдвигов, изменения масштаба картинок: это поможет снизить вероятность переобучения и обеспечит лучшую инвариантность классификатора к трансформациям.
Инструмент 1: Визуализация и разведочный анализ данных
В рамках этого и следующего постов мы будем использовать GTSRB ?—? датасет по распознаванию дорожных знаков в Германии. Наша задача — обучить классификатор дорожных знаков, используя размеченные данные из GTSRB. В общем случае, лучший способ получить представление об имеющихся данных — построить гистограмму распределения train, validation и/или test наборов данных: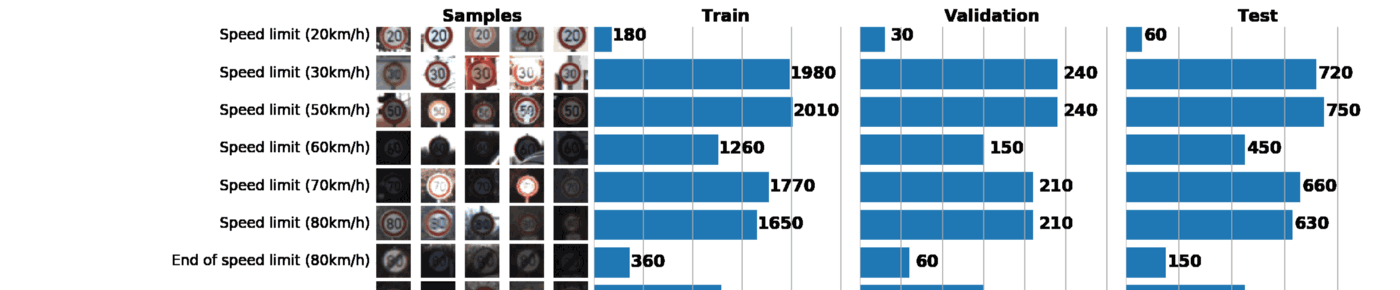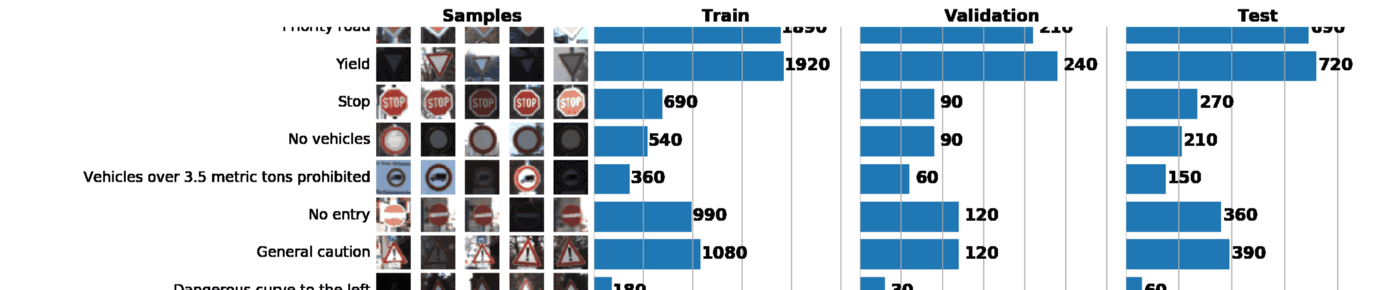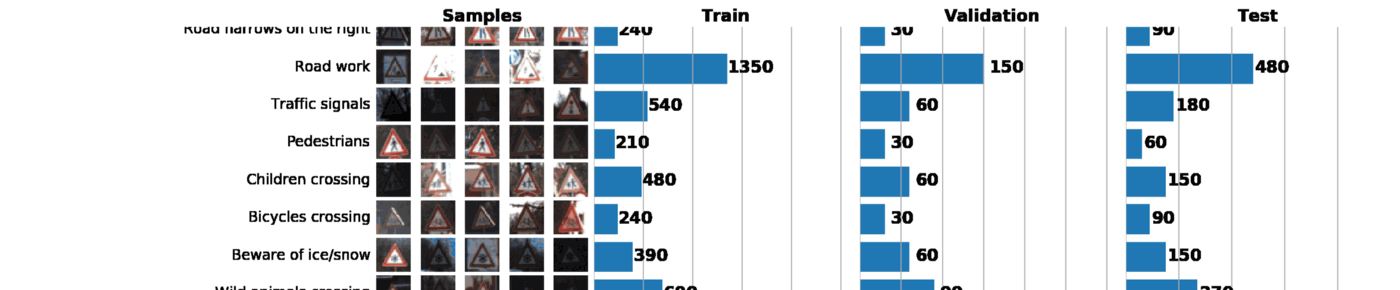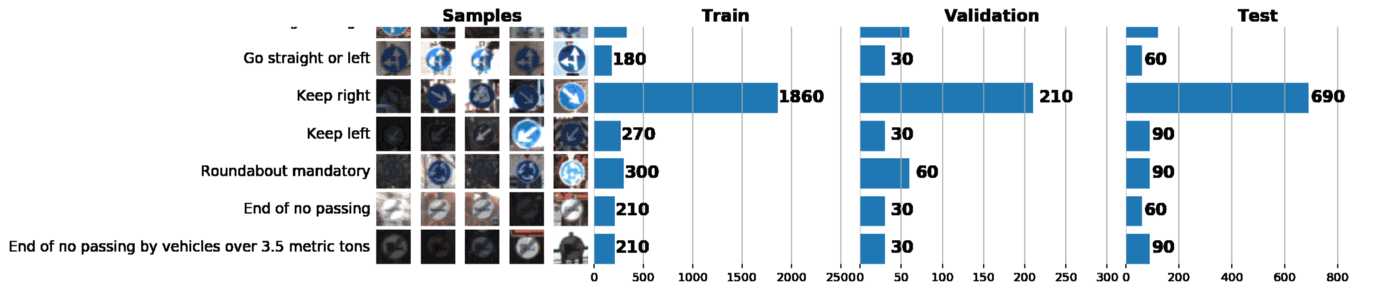
Базовая информация о нашем датасете:
Number of training examples = 34799 Number of validation examples = 4410 Number of testing examples = 12630 Image data shape = (32, 32, 3) Number of classes = 43На данном этапе
matplotlib — ваш лучший друг. Несмотря на то, что используя лишь pyplot можно отлично визуализировать данные, matplotlib.gridspec позволяет слить 3 графика воедино:gs = gridspec.GridSpec(1, 3, wspace=0.25, hspace=0.1) fig = plt.figure(figsize=(12,2)) ax1, ax2, ax3 = [plt.subplot(gs[:, i]) for i in range(3)]Gridspec очень гибок. К примеру, для каждой гистограммы можно установить свою ширину, как я это сделал выше. Gridspec рассматривает ось каждой гистограммы независимо от других, что позволяет создавать усложненные графики.
В результате всего один график может сказать о нашем наборе данных очень многое. Ниже указаны 3 задачи, которые можно решить с помощью грамотно построенного графика:
- Визуализация изображений. По графику сразу видно множество слишком темных или слишком светлых изображений, поэтому должна быть проведена своего рода нормализация данных, чтобы устранить вариацию яркости.
- Проверка выборки на несбалансированность. В случае, если в выборке превалируют экземпляры какого-либо класса, необходимо использовать методы undersampling или oversampling.
- Проверить, что распределения train, validation и test выборок похожи. Это можно проверить, взглянув на гистограммы выше, либо используя ранговый коэффициент корреляции Спирмена. (через
scipy)
Инструмент 2: IPython Parallel для scikit-image
Для того, чтобы улучшить сходимость нейронной сети, нужно привести все изображения к единому освещению путем (как рекомендовано в статье LeCun о распознавании дорожных знаков) преобразования их цветовой гаммы в градации серого. Это можно сделать как с помощью OpenCV, так и с помощью отличной библиотеки на Pythonscikit-image, которая может быть легко установлена с помощью pip (OpenCV же требует самостоятельной компиляции с кучей зависимостей). Нормализация контрастности изображений будет осуществляться с помощью адаптивной нормализации гистограммы (CLAHE, contrast limited adaptive histogram equalization):skimage.exposure.equalize_adapthist.Отмечу, что
skimage обрабатывает изображения одно за другим, используя лишь одно ядро процессора, что, очевидно, неэффективно. Чтобы распараллелить предобработку изображений, используем библиотеку IPython Parallel (ipyparallel). Одно из преимуществ этой библиотеки — простота: реализовать распараллеленный CLAHE можно всего несколькими строчками кода. Сначала в консоли (с установленной ipyparallel) запустим локальный кластер ipyparallel:$ ipcluster start
Наш подход к распараллеливанию очень прост: мы разделяем выборку на батчи и обрабатываем каждую партию независимо от остальных. Как только все батчи будут обработаны, мы сливаем их обратно в один набор данных. Моя реализация CLAHE приведена ниже:
from skimage import exposure def grayscale_exposure_equalize(batch_x_y): """Processes a batch with images by grayscaling, normalization and histogram equalization. Args: batch_x_y: a single batch of data containing a numpy array of images and a list of corresponding labels. Returns: Numpy array of processed images and a list of labels (unchanged). """ x_sub, y_sub = batch_x_y[0], batch_x_y[1] x_processed_sub = numpy.zeros(x_sub.shape[:-1]) for x in range(len(x_sub)): # Grayscale img_gray = numpy.dot(x_sub[x][...,:3], [0.299, 0.587, 0.114]) # Normalization img_gray_norm = img_gray / (img_gray.max() + 1) # CLAHE. num_bins will be initialized in ipyparallel client img_gray_norm = exposure.equalize_adapthist(img_gray_norm, nbins=num_bins) x_processed_sub[x,...] = img_gray_norm return (x_processed_sub, y_sub)Теперь, когда сама трансформация готова, напишем код, который применяет ее к каждому батчу из обучающей выборки:
import multiprocessing import ipyparallel as ipp import numpy as np def preprocess_equalize(X, y, bins=256, cpu=multiprocessing.cpu_count()): """ A simplified version of a function which manages multiprocessing logic. This function always grayscales input images, though it can be generalized to apply any arbitrary function to batches. Args: X: numpy array of all images in dataset. y: a list of corresponding labels. bins: the amount of bins to be used in histogram equalization. cpu: the number of cpu cores to use. Default: use all. Returns: Numpy array of processed images and a list of labels. """ rc = ipp.Client() # Use a DirectView object to broadcast imports to all engines with rc[:].sync_imports(): import numpy from skimage import exposure, transform, color # Use a DirectView object to set up the amount of bins on all engines rc[:]['num_bins'] = bins X_processed = np.zeros(X.shape[:-1]) y_processed = np.zeros(y.shape) # Number of batches is equal to cpu count batches_x = np.array_split(X, cpu) batches_y = np.array_split(y, cpu) batches_x_y = zip(batches_x, batches_y) # Applying our function of choice to each batch with a DirectView method preprocessed_subs = rc[:].map(grayscale_exposure_equalize, batches_x_y).get_dict() # Combining the output batches into a single dataset cnt = 0 for _,v in preprocessed_subs.items(): x_, y_ = v[0], v[1] X_processed[cnt:cnt+len(x_)] = x_ y_processed[cnt:cnt+len(y_)] = y_ cnt += len(x_) return X_processed.reshape(X_processed.shape + (1,)), y_processedНаконец, применим написанную функцию к обучающей выборке:
# X_train: numpy array of (34799, 32, 32, 3) shape # y_train: a list of (34799,) shape X_tr, y_tr = preprocess_equalize(X_train, y_train, bins=128)В результате мы используем не одно, а все ядра процессора (32 в моем случае) и получаем значительное увеличение производительности. Пример полученных изображений:

Результат нормализации изображений и переноса их цветовой гаммы в градации серого

Нормализация распределения для изображений формата RGB (я использовал другую функцию для rc[:].map)
Теперь весь процесс предобработки данных проходит за несколько десятков секунд, поэтому мы можем протестировать разные значения числа интервалов
num_bins, чтобы визуализировать их и выбрать наиболее подходящий:
num_bins: 8, 32, 128, 256, 512
Выбор большего числа
num_bins увеличивает контрастность изображений, в то же время сильно выделяя их фон, что зашумляет данные. Разные значения num_bins также могут быть использованы для аугментации контрастности датасета путем контраста для того, чтобы нейросеть не переобучалась из-за фона изображений.Наконец, используем ipython magic
%store, чтобы сохранить результаты для дальнейшего использования:# Same images, multiple bins (contrast augmentation) %store X_tr_8 %store y_tr_8 # ... %store X_tr_512 %store y_tr_512Инструмент 3: Онлайн-аугментация данных
Ни для кого не секрет, что добавление новых разнообразных данных в выборку снижает вероятность переобучения нейронной сети. В нашем случае мы можем сконструировать искусственные изображения путем трансформации имеющихся картинок c помощью вращения, зеркального отражения и аффиных преобразований. Несмотря на то, что мы можем провести данный процесс для всей выборки, сохранить результаты и затем использовать их же, более элегантным способом будет создавать новые изображения «на лету» (онлайн), чтобы можно было оперативно корректировать параметры аугментации данных.Для начала обозначим все планируемые преобразования, используя
numpy и skimage:import numpy as np from skimage import transform from skimage.transform import warp, AffineTransform def rotate_90_deg(X): X_aug = np.zeros_like(X) for i,img in enumerate(X): X_aug[i] = transform.rotate(img, 270.0) return X_aug def rotate_180_deg(X): X_aug = np.zeros_like(X) for i,img in enumerate(X): X_aug[i] = transform.rotate(img, 180.0) return X_aug def rotate_270_deg(X): X_aug = np.zeros_like(X) for i,img in enumerate(X): X_aug[i] = transform.rotate(img, 90.0) return X_aug def rotate_up_to_20_deg(X): X_aug = np.zeros_like(X) delta = 20. for i,img in enumerate(X): X_aug[i] = transform.rotate(img, random.uniform(-delta, delta), mode='edge') return X_aug def flip_vert(X): X_aug = deepcopy(X) return X_aug[:, :, ::-1, :] def flip_horiz(X): X_aug = deepcopy(X) return X_aug[:, ::-1, :, :] def affine_transform(X, shear_angle=0.0, scale_margins=[0.8, 1.5], p=1.0): """This function allows applying shear and scale transformations with the specified magnitude and probability p. Args: X: numpy array of images. shear_angle: maximum shear angle in counter-clockwise direction as radians. scale_margins: minimum and maximum margins to be used in scaling. p: a fraction of images to be augmented. """ X_aug = deepcopy(X) shear = shear_angle * np.random.rand() for i in np.random.choice(len(X_aug), int(len(X_aug) * p), replace=False): _scale = random.uniform(scale_margins[0], scale_margins[1]) X_aug[i] = warp(X_aug[i], AffineTransform(scale=(_scale, _scale), shear=shear), mode='edge') return X_augМасштабирование и рандомные повороты
rotate_up_to_20_deg увеличивают размер выборки, сохраняя принадлежность изображений к исходным классам. Отражения (flips) и вращения на 90, 180, 270 градусов могут, напротив, поменять смысл знака. Чтобы отслеживать такие переходы, создадим список возможных преобразований для каждого дорожного знака и классов, в которые они будут преобразованы (ниже приведен пример части такого списка):| label_class | label_name | rotate_90_deg | rotate_180_deg | rotate_270_deg | flip_horiz | flip_vert |
|---|---|---|---|---|---|---|
| 13 | Yield | 13 | ||||
| 14 | Stop | |||||
| 15 | No vehicles | 15 | 15 | 15 | 15 | 15 |
| 16 | Vehicles over 3.5 ton prohibited | |||||
| 17 | No entry | 17 | 17 | 17 |
Обратите внимание, что заголовки столбцов соответствуют названиям трансформирующих функций, определенных ранее, чтобы по ходу обработки можно было добавлять преобразования:
import pandas as pd # Generate an augmented dataset using a transform table augmentation_table = pd.read_csv('augmentation_table.csv', index_col='label_class') augmentation_table.drop('label_name', axis=1, inplace=True) augmentation_table.dropna(axis=0, how='all', inplace=True) # Collect all global functions in global namespace namespace = __import__(__name__) def apply_augmentation(X, how=None): """Apply an augmentation function specified in `how` (string) to a numpy array X. Args: X: numpy array with images. how: a string with a function name to be applied to X, should return the same-shaped numpy array as in X. Returns: Augmented X dataset. """ assert augmentation_table.get(how) is not None augmentator = getattr(namespace, how) return augmentator(X)Теперь мы можем построить пайплайн, который применяет все доступные функции (преобразования), перечисленные в
augmentation_table.csv ко всем классам:import numpy as np def flips_rotations_augmentation(X, y): """A pipeline for applying augmentation functions listed in `augmentation_table` to a numpy array with images X. """ # Initializing empty arrays to accumulate intermediate results of augmentation X_out, y_out = np.empty([0] + list(X.shape[1:]), dtype=np.float32), np.empty([0]) # Cycling through all label classes and applying all available transformations for in_label in augmentation_table.index.values: available_augmentations = dict(augmentation_table.ix[in_label].dropna(axis=0)) images = X[y==in_label] # Augment images and their labels for kind, out_label in available_augmentations.items(): X_out = np.vstack([X_out, apply_augmentation(images, how=kind)]) y_out = np.hstack([y_out, [out_label] * len(images)]) # And stack with initial dataset X_out = np.vstack([X_out, X]) y_out = np.hstack([y_out, y]) # Random rotation is explicitly included in this function's body X_out_rotated = rotate_up_to_20_deg(X) y_out_rotated = deepcopy(y) X_out = np.vstack([X_out, X_out_rotated]) y_out = np.hstack([y_out, y_out_rotated]) return X_out, y_outОтлично! Теперь у нас есть 2 готовые функции аугментации данных:
affine_transform: кастомизируемые аффинные преобразования без вращения (название я выбрал не очень удачное, потому что, что вращение является одним из аффинных преобразований).flips_rotations_augmentation: случайные вращения и преобразования на основеaugmentation_table.csv, меняющие классы изображений.
Финальный шаг — это создать генератор батчей:
def augmented_batch_generator(X, y, batch_size, rotations=True, affine=True, shear_angle=0.0, scale_margins=[0.8, 1.5], p=0.35): """Augmented batch generator. Splits the dataset into batches and augments each batch independently. Args: X: numpy array with images. y: list of labels. batch_size: the size of the output batch. rotations: whether to apply `flips_rotations_augmentation` function to dataset. affine: whether to apply `affine_transform` function to dataset. shear_angle: `shear_angle` argument for `affine_transform` function. scale_margins: `scale_margins` argument for `affine_transform` function. p: `p` argument for `affine_transform` function. """ X_aug, y_aug = shuffle(X, y) # Batch generation for offset in range(0, X_aug.shape[0], batch_size): end = offset + batch_size batch_x, batch_y = X_aug[offset:end,...], y_aug[offset:end] # Batch augmentation if affine is True: batch_x = affine_transform(batch_x, shear_angle=shear_angle, scale_margins=scale_margins, p=p) if rotations is True: batch_x, batch_y = flips_rotations_augmentation(batch_x, batch_y) yield batch_x, batch_yОбъединив датасеты с разным числом
num_bins в CLAHE в один большой train, подадим его в полученный генератор. Теперь у нас есть два вида аугментации: по контрастности и с помощью аффинных трансформаций, которые применяются к батчу на лету:
Сгенерированные с помощью augmented_batch_generator изображения
Замечание: аугментация нужна для train-сета. Test-сет мы тоже предобрабатываем, но не аугментируем.
Давайте проверим, что мы нечаянно не нарушили распределение классов на расширенном трейне по сравнению с исходным датасетом:
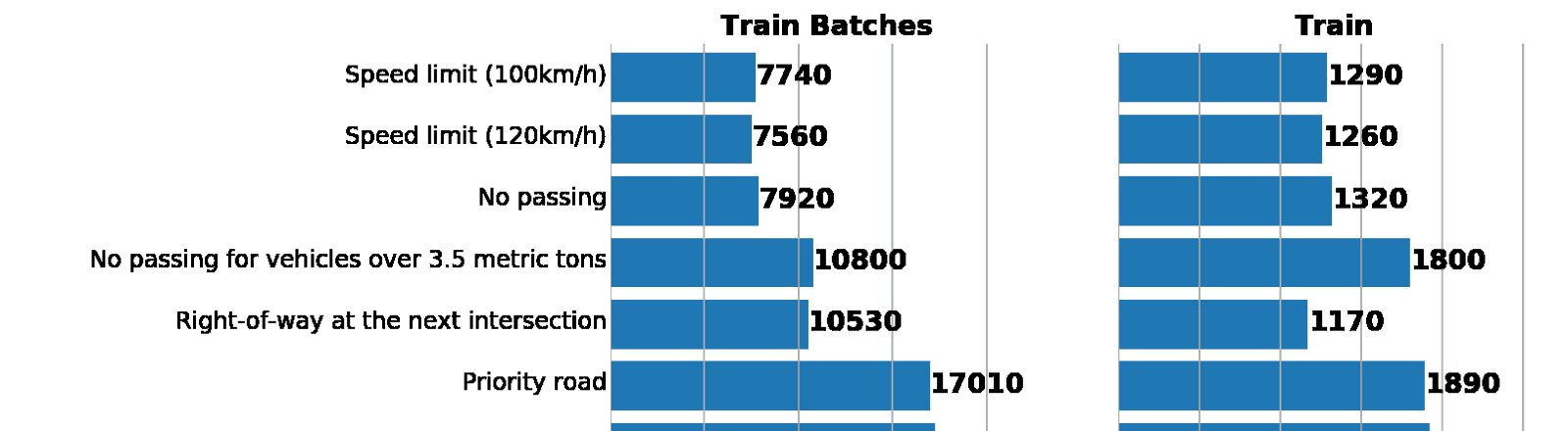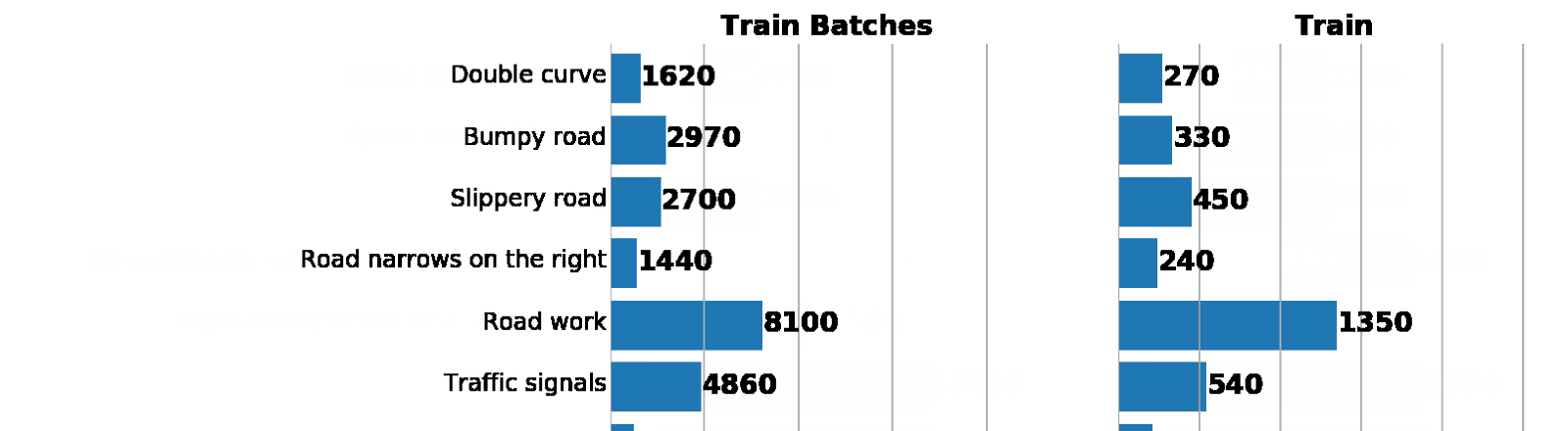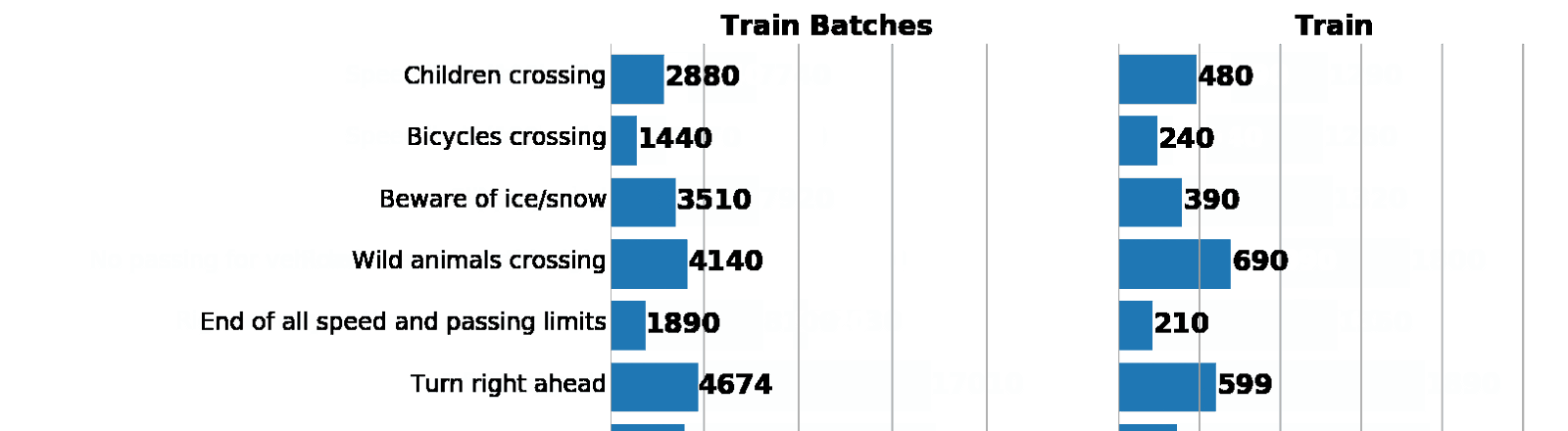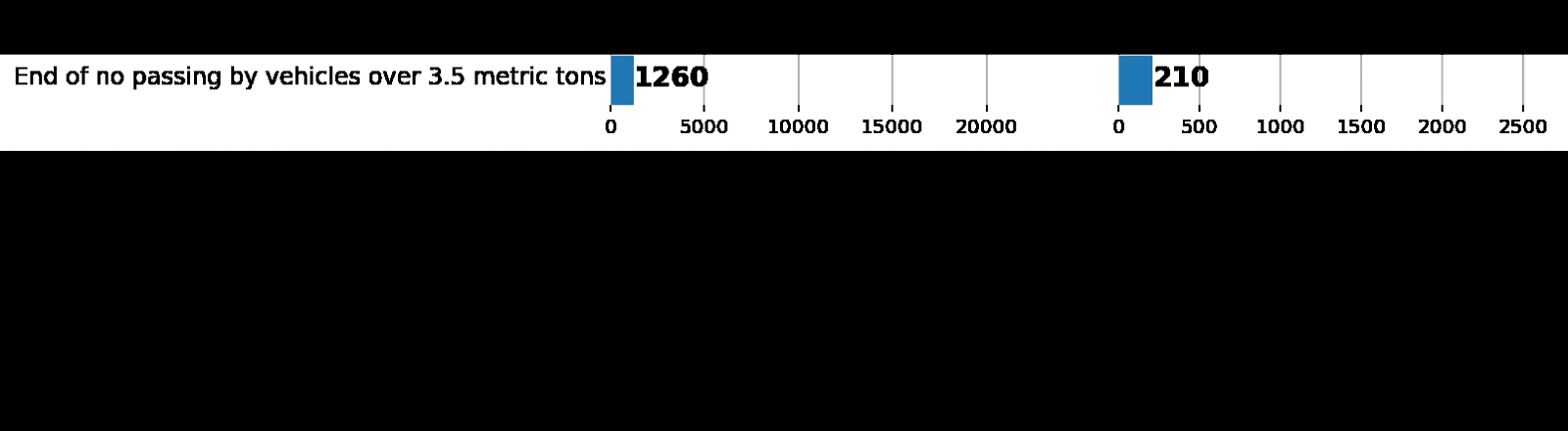
Слева: гистограмма распределения данных из augmented batch generator. Справа: изначальный train. Как видно, значения различаются, но распределения схожи.
Переход к нейронным сетям
После того, как выполнена предобработка данных, все генераторы готовы и датасет готов к анализу, мы можем перейти к обучению. Мы будем использовать двойную свёрточную нейронную сеть: STN (spatial transformer network) принимает на вход предобработанные батчи изображений из генератора и фокусируется на дорожных знаках, а IDSIA нейросеть распознает дорожный знак на изображениях, полученных от STN. Следующий пост будет посвящён этим нейросетям, их обучению, анализу качества и демо-версии их работы. Следите за новыми постами!
Слева: исходное предобработанное изображение. Справа: преобразованное STN изображение, которое принимает на вход IDSIA для классификации.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru