Популярность машинного обучения влияет на эволюцию архитектуры процессоров
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-08-31 07:05

Процесс развития архитектур центральных процессоров подобен эволюционному. Их создают разработчики для соответствия той или иной эволюционной нише, требующей каких-либо специфических вычислений, наборов инструкций и тому подобное. Иногда эволюционные ниши схлопываются — ?и вымирают целые семейства процессоров. В качестве примера можно привести Alpha. Сейчас основную нишу удерживают x86-совместимые решения, но о них чуть позже. В 2017 году уже ни у кого нет сомнений, что возникла новая экологическая ниша — специализированные процессоры для нейронных сетей и машинного обучения.

Google TPU
О таких решениях мы писали неоднократно. Здесь и Google Tensor Processing Unit, и разработка Fujitsu под названием DLU (Deep Learning Unit), и процессор Graphcore IPU (Intelligent Processing Unit), и многочисленные разработки и прототипы на базе ПЛИС компаний Altera и Xilinx, которыми интересуется всё больше крупных владельцев ЦОД по всему миру, например, Baidu. Да и графические чипы последних поколений отлично справляются с задачей создания и натаскивания нейросетей благодаря глубокой степени параллелизма, хотя делают они это не столь экономично, как специально созданные для этой цели решения. Смысл в том, что эволюционная ниша сформирована, и теперь в ней наблюдается типичная борьба за выживание: в графических чипах NVIDIA появляются специальные ядра для тензорных вычислений (в Volta V100 таких ядер 640).
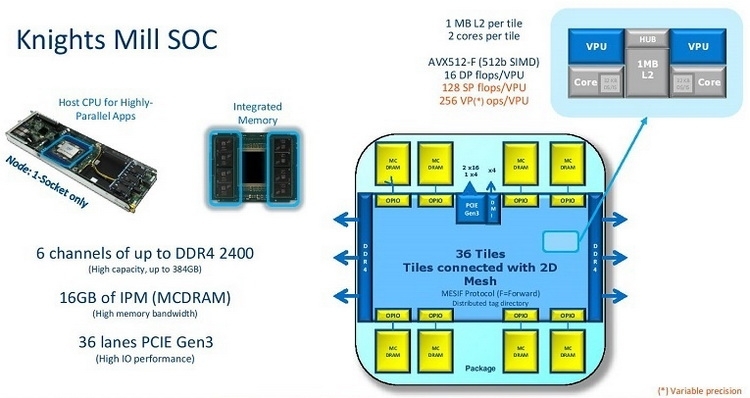
Intel Knights Mill
Обычно эти ядра оперируют математикой с упрощённой точностью (32 и 16 бит с плавающей запятой, а иногда и целочисленными форматами вплоть до 8 битных). У AMD есть аналогичный продукт — ускорители серии Radeon Instinct. Но что самое интересное, эволюционная «мутация» закрепляется и в обычных, казалось бы, x86-совместимых процессорах — совсем недавно мы описывали читателям чипы Intel Knights Mill, в которых часть общей производительности принесена в угоду производительности на специализированных задачах машинного обучения. Кто победит в эволюционной гонке? Пока сказать трудно. Такие решения, как NVIDIA Volta и Radeon Instinct может ждать судьба динозавров — по соотношению энергопотребления к производительности в специальных задачах они проигрывают тому же Google TPU.
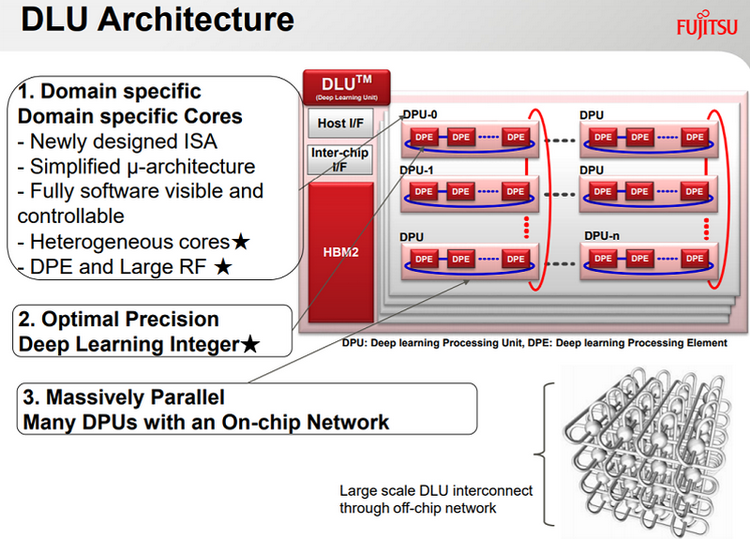
Fujitsu Deep Learning Unit
Роль протомлекопитающих в этом процессе, судя по всему, играют решения на базе ПЛИС, а королями нейронных сетей станут специализированные мощные процессоры, такие, как Google TPU. Но эволюция — процесс нелинейный, и ряд ниш вполне может найтись для решений, способных не только работать с системами машинного обучения. К тому же, сами системы обучения могут быть очень разными и требовать гибкости, к которой чипы типа ASIC не способны по определению. Может потребоваться и параллельное выполнение задач иного порядка, так что чипам вроде Intel Knights Mill тоже найдётся место на ветвистом дереве эволюции процессоров. Пока ясно одно — «ген» машинного обучения поселился в современных процессорах надолго.
Телеграм: t.me/ainewsline
Источник: servernews.ru