Лекция Владимира Игловикова на тренировке Яндекса по машинному обучению
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-08-06 19:29

Скорее всего, вы слышали об авторе этой лекции. Владимир ternaus Игловиков занял второе место в британском Data Science Challenge, но организаторы конкурса не стали выплачивать ему денежный приз из-за его российского гражданства. Затем наши коллеги из Mail.Ru Group взяли выплату приза на себя, а Владимир, в свою очередь, попросил перечислить деньги в Российский Научный Фонд. История получила широкий охват в СМИ.
Спустя несколько недель Владимир выступил на одной из тренировок Яндекса по машинному обучению. Он рассказал о своём подходе к участию в конкурсах, о сути Data Science Challenge и о решении, которое позволило ему занять второе место.
— Меня зовут Владимир Игловиков. Мне очень нравится, как у вас все организовано. Гораздо лучше, чем на тех митапах в Долине, где я задвигал речи.
Сегодня мы поговорим об этом конкурсе, который был, с одной стороны, наиболее простым за последние много месяцев с точки зрения сложности порога вхождения. Но с другой стороны, он так смешно разошелся по новостям, что я еще долго буду от этого оправляться.
Историческая справка. На Kaggle с декабря по март проходило соревнование про спутники, которое было хорошо известно в Slack-канале Open Data Science. Мы всем коллективом его решали и достаточно хорошо выступили. Из первых десяти мест пять были заняты людьми, которые, как минимум, зарегистрированы в ODS. Второе место заняла команда Романа Соловьева и Артура Кузина, они попилили 30 штук баксов под это дело. А на третьем месте — мы с Серегой Мушинским, наш приз тоже был нормальный.
 Задача достаточно интересная. Красивые картинки, интересные задачи, можно подтянуть под какой-то продукт. С ребятами контактировали различные компании, предлагали какой-то консалтинг, не консалтинг — чтобы они их знания применяли к другим картографическим задачам. Была интересная задача, и мы под это дело добавили немного пиара.
Задача достаточно интересная. Красивые картинки, интересные задачи, можно подтянуть под какой-то продукт. С ребятами контактировали различные компании, предлагали какой-то консалтинг, не консалтинг — чтобы они их знания применяли к другим картографическим задачам. Была интересная задача, и мы под это дело добавили немного пиара.
Были написаны посты — два поста на Хабре, мой и Артура. Я таки закончил и опубликовал пост на Kaggle в основном блоге, Артур до сих пор ленится. Артур прочитал речь здесь, и я две или три речи задвинул где-то в Долине. Под это дело мы опубликуем научную статью на следующей неделе, она на стадии полировки.
Организатором была британская разведка MI6, MI5 и лаборатория Defence Laboratory при Министерстве обороны. Они под это дело умудрились выбить со своего правительства достаточно большие деньги, полмиллиона долларов. В Долине это вообще ни о чем, и компания может себе это позволить, но интересно, что ученые при правительстве могли достать такие деньги даже в Британии.
Они выбили 465 штук баксов. Из них 100 пошло на призы, а остальные 365 были, в общем, освоены Kaggle за поддержку соревнования, за платформу, хостинг и т. д. Нормальный там маржинг. И организаторы в результате получили решение в том формате, который предоставляет Kaggle: куча кода и два скрипта, train и predict, а внутри куча всякой вермишели, непонятно что. Когда мы им это все презентовали, они достаточно сильно плыли в нашем решении. Не факт, что у них просто знаний и навыков хватает с этим что-то сделать. По факту они фиганули полмиллиона долларов, получили интересное решение, кучу красивых картинок, и непонятно, что с этим делать. Но сама идея им понравилась. И вообще британские ученые сейчас очень активно работают в этом отношении. Мне нравится, что они делают лучше, чем Минобороны России, США и всех остальных стран. У них много данных, много интересных задач. Правда, у них денег не очень много и они пытаются как-то пиариться и привлекать дата-саентистов.
Они нашли еще немного денег… ну, не так много. И нашли подрядчика, который запилил им копию Kaggle. Собрали каких-то данных, подготовили, почистили и сделали еще два соревнования, прямо по окончании той задачи на Kaggle про спутники. Одно было computer vision, про него чуть позже, а другое — natural language processing. Кто-то из наших участвовал, но в тройку не вошел. Но тоже говорят, что интересно. Черт его знает.
Британцы же на своей волне, тем более подрядчик к соревнованиям, к data science имеет достаточно ортогональное отношение. И они там начали чудить. Потом поговорю про метрику и про то, как они делили private и public, — что было достаточно смешно, и надо было бы этим воспользоваться, если бы мы заранее знали.
Из-за чего весь шум по новостям и как все это получилось? Правила у них написаны очень хитро: участвовать могут все, но если ты уходишь в топ на денежный приз — а в каждом соревновании денежный приз составлял 40 тыс. фунтов — то на него могли претендовать только люди определенных категорий. В общем, не все. И они сделали хитрые манипуляции на тему паспорта, места проживания, банка и т. д. Несмотря на то, что я резидент США, живу в Сан-Франциско, плачу налоги там, не спонсирую российское правительство и кого бы то ни было даже через уплату налогов, все равно мне приз не положен чисто по цвету паспорта. С другой стороны, это не такие большие деньги для меня были, все не так страшно. Зато хоть история получилась интересная, буду внукам рассказывать.
Когда мы презентовали решение задачи про спутники, которая шла зимой, мы спросили организаторов, какого лешего и доколе такая дискриминация будет твориться? Там достаточно адекватный мужик, ученый, он сказал, что это подрядчик что-то мутит, на самом деле все будет по-другому, все исправим, все будет замечательно. Так не случилось, но тем не менее.
 Теперь о самой проблеме. У Kaggle в последний год то data leak, то один, то пять, то еще какая-то муть с данными, то train и test разные. В общем, куча всякой экзотики. Это задалбывает. Когда ты приходишь домой по вечерам, ты не хочешь заниматься всей этой нездоровой инженерией, а хочешь, как белый человек, стакать XGBoost или тренировать сети, что-то такое.
Теперь о самой проблеме. У Kaggle в последний год то data leak, то один, то пять, то еще какая-то муть с данными, то train и test разные. В общем, куча всякой экзотики. Это задалбывает. Когда ты приходишь домой по вечерам, ты не хочешь заниматься всей этой нездоровой инженерией, а хочешь, как белый человек, стакать XGBoost или тренировать сети, что-то такое.
И вот британцы подготовили достаточно чистые данные. Там были вопросы к разметке, но совсем незначительные. Мы имеем 1200 спутниковых снимков, каждый сделан с высоты примерно 100 метров, думаю, чисто визуально. Каждый пиксель соответствует 5 см, и нужно было сделать стандартную задачу object detection. У нас есть девять классов, и вот примеры из их документации: мотоцикл, белая длинная машина и белая короткая машина. Сеть действительно путалась. Короткий хетчбэк или длинный хетчбэк — были вопросы к этому. Белый седан, хетчбэк, черный седан, хетчбэк, красный седан, хетчбэк, белый фургон и красно-белый автобус.
Реально по улицам еще ездят синие, желтые машинки и все остальные. Их надо было игнорировать. Почему они выбрали эти — кто их знает. В общем, надо найти машинки, но не все, а только определенные, и разбить их по классам. Плюс давайте добавим мотоциклы. Хорошо хоть не велосипеды и не самокаты. По сравнению с машиной — несмотря на то, что она 5 см на пиксель — мотоцикл достаточно шумный. Даже здесь он выглядит как некое немного расплывчатое пятно. Сама задача — стандартный object detection.
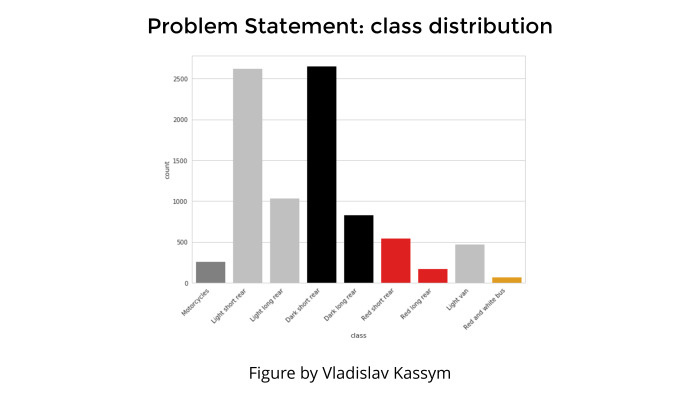 Любая задача классификации, любая презентация не обходится без картинки, которая показывает распределение классов. Это чтобы поговорить о том, что мы бы ушли в топ, но тут class inbalance, и он такой плохой, мы не смогли справиться, жизнь — печаль и все такое.
Любая задача классификации, любая презентация не обходится без картинки, которая показывает распределение классов. Это чтобы поговорить о том, что мы бы ушли в топ, но тут class inbalance, и он такой плохой, мы не смогли справиться, жизнь — печаль и все такое.
Здесь такого не было. Да, видно, что каких-то классов совсем мало — гораздо меньше, чем всех остальных. Например, крайний правый класс — автобус, или крайний левый класс — мотоциклы. Но это была не проблема, просто потому что мотоциклы от машин отличаются сильно и автобусы от всего остального отличаются сильно. И несмотря на то, что их мало, они настолько яркий класс, что с их детекцией проблем не было.
А во всяких этих белых хетчбэках и всем остальном действительно путались.
 Как данные были предоставлены? Понятно, что можно маркировать данные по-разному. У нас спутниковые снимки или другие изображения, и нужно отметить машинки, ну или собачек, кошек… Можно обводить bounding boxes, целиком область, в которую входит данный объект, или просто мышкой ткнуть на точку и сказать, что это наш объект.
Как данные были предоставлены? Понятно, что можно маркировать данные по-разному. У нас спутниковые снимки или другие изображения, и нужно отметить машинки, ну или собачек, кошек… Можно обводить bounding boxes, целиком область, в которую входит данный объект, или просто мышкой ткнуть на точку и сказать, что это наш объект.
Применяются оба метода, и даже недавно была статья от Google, в которой они на десяти страницах размусоливали, не как новую сеть построить, а как правильно тренировать индусов, чтобы маркировать объекты, тыкая точечками так, чтобы потом восстанавливать bounding boxes, и как это все красиво. Статья довольно достойная. Правда, не очень понятно, что с ней делать, если нет специально обученных индусов.
Много статей про то, как работать и с bounding boxes, и с точками. В принципе, когда вы предсказываете и классифицируете object detection через bounding box, точность выше просто потому, что надо предсказать координаты этого четырехугольника. Loss function более точная и привязанная к самим данным. А когда у вас точка, предсказывать центр действительно сложнее. Точка и есть точка. Но в данной задаче, как и в задаче про котиков, которая проходит сейчас на Kaggle, данные отмаркированы через точки.
На этой картинке по размеру одна четверть от больших снимков 200 на 200. Они нам дают изображение, где отмечены центры машин для 600 картинок, и надо было предсказать их для других 600.
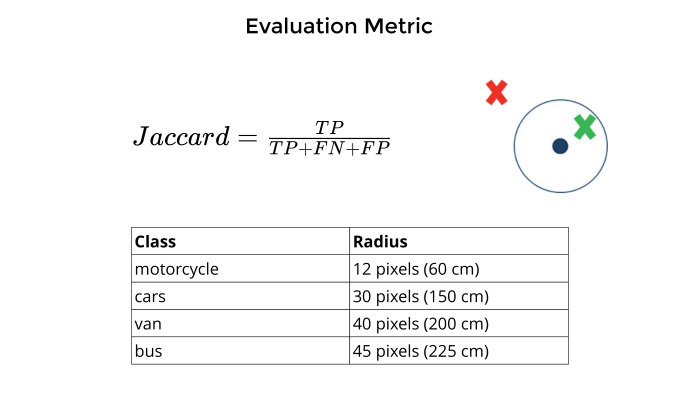 Метрика. Понятно, что любая задача не имеет смысла, пока не придумана численная оценка точности модели. Потом пытаешься ее подгонять, оптимизировать, чтобы все было прекрасно.
Метрика. Понятно, что любая задача не имеет смысла, пока не придумана численная оценка точности модели. Потом пытаешься ее подгонять, оптимизировать, чтобы все было прекрасно.
Метрикой в данной задаче выступал Jaccard. Как он мерился? Есть точка, которую они отмаркировали, центр машин. Вы предсказываете центр машин. Если они достаточно близко друг к другу, рядом, и это зависит от разных классов из таблицы снизу, то это true positive. Если нет — false positive. Если вообще ни черта нет — false negative.
Все это суммируется без усреднения по классам. Каждый мотоцикл вносит столько же, сколько автобус, фургон и все остальное. И Jaccard, true positive на общий union.
 Соревнований сейчас море. Даже по deep learning сейчас десять соревнований проходит. У всех призы, интересные задачи, одни котики или задача про шейки матки чего стоят, какие-то тропики в Амазонии — много всего интересного. И это на Kaggle, где нормальная платформа, комьюнити и все прекрасно. Да банальный ImageNet 2017 заканчивается через пару недель, а я еще даже код не начал писать.
Соревнований сейчас море. Даже по deep learning сейчас десять соревнований проходит. У всех призы, интересные задачи, одни котики или задача про шейки матки чего стоят, какие-то тропики в Амазонии — много всего интересного. И это на Kaggle, где нормальная платформа, комьюнити и все прекрасно. Да банальный ImageNet 2017 заканчивается через пару недель, а я еще даже код не начал писать.
Когда я открываю какое-то соревнование, первый вопрос — зачем мне это надо? Потому что убивать свои вечера, выходные или на работе не работать, а соревнования гонять — нужны причины. Часто в голове рисуется некий список плюсов и минусов. Если мне нравится, как он выглядит, причем минусов может быть больше, — я обычно участвую.
Про минусы. Почему не стоит участвовать? Потому что денег не будет. Я на Kaggle участвовал последние два года и никогда не думал про призовые деньги, потому что участвовать в соревновании из финансовых соображений — наивный оптимизм. Уйти в топ, да еще в деньги, реально тяжело. Там 3000 участников, все брутальные ребята, хорошо подготовлены, у них куча железа и они не работают. Реально тяжело.
После того, как на спутниковых снимках нам дали приз и мне понравилось, манера мышления как-то немного изменилась в более меркантильную сторону. Так что денег не будет по правилам. Это было известно заранее, несмотря на то, о чем они после этого рассказывали в новостях.
Каждое соревнование дает очень много знаний. Но в одиночку бодаться в новую область тяжело. Поэтому гораздо удобнее, когда вас 50 человек и каждый рассказывает, что у кого получилось. В таком режиме можно за месяц-два, ничего не понимая в данной задаче, подняться до эксперта достаточно высокого уровня. Нужен коллектив. Коллектива не было, потому что это не Kaggle, а ребята из Slack не горели желанием участвовать, просто потому что денег не будет и вообще правила дурацкие. Ну и лень всем было.
Многие из этих соревнований не просто дают знания. Предположим, кто-то из вас будет искать работу на Западе. Вы неожиданно выясните, что из тех людей, которые там есть, народа, знающего о Яндексе, ШАДе, МФТИ и всех остальных, — гораздо меньше, чем народа, знающего о существовании Kaggle. Поэтому имеет смысл с перспективой продавать это при приеме на работу. Насколько интересной может быть задача для каких-то людей, стартапов и т. п.? Понятно, что любая задача про спутниковые снимки будет интересна. Любая задача про медицинские изображения будет интересна. Постакать xgboost — под большим вопросом. Kaggle знают, а какую-то доморощенную британскую площадку никто не знает. И строчка в резюме, типа я взял площадку, о которой никто из вас не знает, и там я красавчик, поэтому возьмите меня к себе, — звучит не очень хорошо. Kaggle в этом отношении гораздо лучше.
А теперь список плюсов. Зачем все это нужно? Данные реально красивые, хорошо подготовленные. Задача интересная. В этой теме я ничего не соображал на момент начала соревнований, а значит, за месяц-два можно натаскаться до действительно профессионального и серьезного уровня. И нет проблем с валидацией, валидацию мы вообще не делали. Действительно, очень красивые данные — основная мотивация. Она в том, что можно на каких-то чистых данных натренировать что-то, что важно, интересно. Можно добавить скиллов в свой инструментарий.
Image detection. Тот же ImageNet, задача про котиков и все остальное. Много где используется image detection. Я последние полгода искал работу в Долине, и про классификацию изображений никто не спрашивает, потому что это просто и пошло. А вот про detection спрашивают все подряд, очень много всяких самодвижущихся машин и прочих интересных применений в бизнесе. Jни спрашивают: «Ты в этом что-то соображаешь?» — «Нет». И дальше разговор не шел. Этот вопрос чисто по знаниям надо было закрывать. И его задача тоже добавляла.
Данных здесь достаточно много, а не как обычно — 6 картинок на public, 26 на private, какой-то shuffle на leaderboard. Здесь такого не было. Достаточно много картинок и на train, и на test, и каждый класс достаточно хорошо представлен, все хорошо. Никаких data leak. Кто участвовал в Quora, где у них обсуждение на форуме шло в режиме: «А ты помнишь, в четвертом лике ты уже подкрутил параметр?» — «Не, я над пятым ликом работаю». Такого криминала там не было, что очень приятно.
И в каждом соревновании вы работаете, пишите какой-то код, потом он копипастится или переносится в другие задачи. было бы полезно натренироваться на этих британских машинках, а потом перенести всё на другие задачи, попытаться в них гордо въехать в топ. Пока не получилось, но я над этим работаю.
 Вся эта болтология в итоге сведется к тому, что решение на полстраницы. Что мы имеем? Тренировочные данные были размечены через точечки. Есть достаточно много статей о том, как все это считать, crowd counting и все остальное. И вообще: поскольку для многих компаний гораздо дешевле нанять индусов, тыкающих мышкой в какие-то объекты, нежели заставить их правильно обводить, то и точность нужна повыше, и времени больше. Просто дороже. Британцы, видимо, тоже наняли индусов, те натыкали, получились точечки — см. картинку снизу.
Вся эта болтология в итоге сведется к тому, что решение на полстраницы. Что мы имеем? Тренировочные данные были размечены через точечки. Есть достаточно много статей о том, как все это считать, crowd counting и все остальное. И вообще: поскольку для многих компаний гораздо дешевле нанять индусов, тыкающих мышкой в какие-то объекты, нежели заставить их правильно обводить, то и точность нужна повыше, и времени больше. Просто дороже. Британцы, видимо, тоже наняли индусов, те натыкали, получились точечки — см. картинку снизу.
Как с этим работать, сходу непонятно. Про это надо читать, писать какой-то код, но мне было лень, потому что я на всю задачу отвел себе месяц. В первые две недели из четырех я собирался с мыслями. За две недели до конца решил все-таки начать что-то делать. Изобретать уже времени не оставалось, да и не хотелось. А хотелось свести эту задачу к стандартной решенной классической задаче.
Я на работе убил два рабочих дня и перебил все эти точечки под bounding boxes. Прямо взял sloth и вручную перебил train set. Слева изначальные метки, справа те, что в конце. Особо внимательный увидит, что один bounding box я таки забыл обвести. Сейчас на Kaggle — да и везде — достаточно часто проходит трюк, когда добавляется дополнительная информация, дополнительные метки к тренировочным данным. И это позволяет гордо въехать в топ.
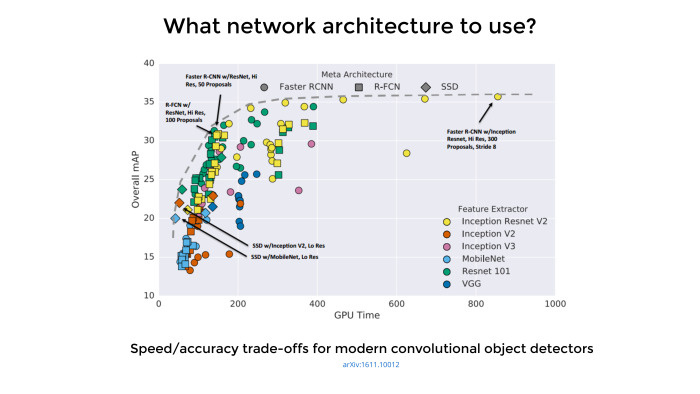 Google опубликовал достойную статью, последний выпуск был месяц назад. Там 11 авторов. Никакой новой архитектуры они не сделали, они реально воспользовались тем, что у Google много ресурсов, взяли много архитектур, чуть ли не сотню, написали под каждую код, прогнали через гугловские GPU, поставили много хороших экспериментов, собрали все в таблицу и опубликовали достаточно хорошую обзорную статью. Она объясняет, какие архитектуры чуть получше подходят для object detection, какие чуть похуже и чем можно пожертвовать.
Google опубликовал достойную статью, последний выпуск был месяц назад. Там 11 авторов. Никакой новой архитектуры они не сделали, они реально воспользовались тем, что у Google много ресурсов, взяли много архитектур, чуть ли не сотню, написали под каждую код, прогнали через гугловские GPU, поставили много хороших экспериментов, собрали все в таблицу и опубликовали достаточно хорошую обзорную статью. Она объясняет, какие архитектуры чуть получше подходят для object detection, какие чуть похуже и чем можно пожертвовать.
На основе этой статьи сложилось впечатление, что лучшие по точности архитектуры — на основе Faster R-CNN, а по скорости — на SSD. Поэтому в продакшен пилят SSD, а для соревнований и так далее — Faster RCNN.
 Есть два основных семейства. Faster R-CNN медленная, предсказания повыше в точности. И, что было очень важно для меня, мелкие объекты тоже достаточно аккуратно предсказывают. А вы видели, что мотоцикл на этих снимках еще надо было найти. То есть нужна была сетка, которая делает аккуратные предсказания и тренировку на малых объектах. SSD достаточно быстрая: предсказывает, тренируется. Но она менее точная, и с малыми объектами в силу нюансов архитектуры сети там реально все плохо. Поэтому я остановился на Faster R-CNN.
Есть два основных семейства. Faster R-CNN медленная, предсказания повыше в точности. И, что было очень важно для меня, мелкие объекты тоже достаточно аккуратно предсказывают. А вы видели, что мотоцикл на этих снимках еще надо было найти. То есть нужна была сетка, которая делает аккуратные предсказания и тренировку на малых объектах. SSD достаточно быстрая: предсказывает, тренируется. Но она менее точная, и с малыми объектами в силу нюансов архитектуры сети там реально все плохо. Поэтому я остановился на Faster R-CNN.
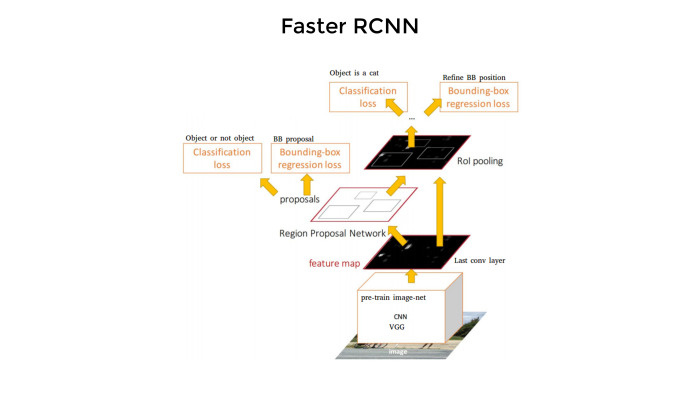 Вот сеть, архитектура выглядит вот так. Как вы видели, на этой картинке нужно найти все bounding boxes, а потом предсказать, какой класс в каждом из квадратиков там находится. Сеть работает примерно так. И она достаточно медленная — несмотря на то, что «Faster».
Вот сеть, архитектура выглядит вот так. Как вы видели, на этой картинке нужно найти все bounding boxes, а потом предсказать, какой класс в каждом из квадратиков там находится. Сеть работает примерно так. И она достаточно медленная — несмотря на то, что «Faster».
Сначала какие-то конволюционные слои на основе претренировочных сетей извлекают фичи. Потом одна ветвь предсказывает эти боксы. Потом идет классификация. Вот как интуитивно об этом думаешь — примерно так же тут все и происходит. Четыре loss-функции, все достаточно сложно, и с нуля писать код умаешься. Поэтому, естественно, никто этим не занимается.
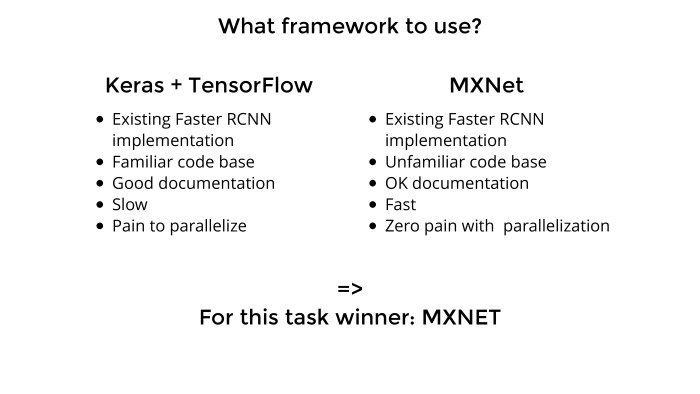 Мы выбрали, какую сеть использовать. Сейчас достаточно много на рынке всяких фреймворков: TensorFlow, Theano, Keras, MXNet, Cafe, еще какой-то зоопарк. Их реально очень много, и надо подумать, какую выбрать, какая здесь зайдет.
Мы выбрали, какую сеть использовать. Сейчас достаточно много на рынке всяких фреймворков: TensorFlow, Theano, Keras, MXNet, Cafe, еще какой-то зоопарк. Их реально очень много, и надо подумать, какую выбрать, какая здесь зайдет.
До этого я использовал исключительно Keras с бэкендом от Theana или TensorFlow. У Keras прекрасный API, очень удобно, там можно много штук делать из коробки, код на GitHub достаточно чистый, если надо что-то подкрутить — все достаточно просто.
Я знал код, достаточно нормальная документация, и к тому моменту, после первой задачи, я купил себе два GPU. Хотелось уже быть модным, распараллелить, чтобы все было быстро, как у мужиков в статьях, а не как у нас у всех обычно. Но с Keras была проблема. Я запустил, сделал предсказание и на тот момент даже ушел в топ-10 по этой задаче. Но он медленный, как эстонская черепаха. То ли такой overhead на вычислениях, то ли TensorFlow сам по себе медленный, а Keras добавляет overhead. Ну и имплементация, видимо, тоже была не самой удачной.
В то же время Артур Кузин очень активно в Slack топит за MXNet — что он быстрый, хороший, параллелится, все там прекрасно. В основном из-за параллелизации и хотелось этим воспользоваться. Параллелизацию остальные участники Slack подтвердили и сказали, что параллелится реально мизинцем левой ноги из коробки, все прекрасно. Faster R-CNN медленный, но у меня два GPU, хочется одно компенсировать другим. Keras не подходит — так давайте попробуем MXNet.
Что с ним плохо. Там непонятно что происходит в коде. Написан он тоже какими-то инопланетянами. Зато достаточно быстрый фреймворк. И из тех двух недель, что я работал над задачей, первую неделю я разбирался, кто там чей брат, как скормить данные, что куда скомпилировать. Скомпилировать там надо постараться. В общем, куча всякой экзотики. Но к концу недели я разобрался, подбил еще пару мужиков в чатике, и мы начали пилить MXNet. И все сразу стало хорошо. С первой же попытки уходишь в топ-5, тебе сразу приятно и ты прощаешь MXNet все.
 Само решение. Что было сделано? Берется MXNet, в нем, прям в самом репозитории, есть пример Faster R-CNN. Берется этот код, он сделан на примере (неразборчиво — прим. ред.), ты меняешь это на машинки. Затем взяли все спутниковые снимки, нужно было добавить батч-генератор, потому что снимки 2000 на 2000 в сеть просто так не скормишь. Надо их либо уменьшать, но тогда теряется информация и мотоцикл вообще будет не найти, либо резать на кусочки и скармливать сети.
Само решение. Что было сделано? Берется MXNet, в нем, прям в самом репозитории, есть пример Faster R-CNN. Берется этот код, он сделан на примере (неразборчиво — прим. ред.), ты меняешь это на машинки. Затем взяли все спутниковые снимки, нужно было добавить батч-генератор, потому что снимки 2000 на 2000 в сеть просто так не скормишь. Надо их либо уменьшать, но тогда теряется информация и мотоцикл вообще будет не найти, либо резать на кусочки и скармливать сети.
В итоге я случайным образом вырезал из картинок куски 1000 на 1000. Потом все любят докапываться до моих D4 group augmentation. Что это такое? Кто знает математику и теорию групп, это группа симметрии квадрата. Грубо говоря, если у нас какой-то квадрат и мы его отразим вокруг центральной оси, вертикальной или горизонтальной, повернем на 90 градусов, то он в пространстве не изменится. И группа симметрий там как раз D4, 8 элементов. Если говорить на нормальном человеческом языке, это повороты на углы, кратные 90, отражение, да и всё.
Как тренировалась сеть? Берется картинка 2000 на 2000, из нее вырезается рандомный кусок 1000 на 1000, потом применяется отражение или поворот, ну и потом результат скармливается сети. Всё.
Мы все привыкли, что в классификации пролетают какие-то 90 картинок в секунду, 100, такие цифры. А здесь на двух GPU — 8. Он действительно достаточно медленный, поэтому Faster в продакшен надо прикручивать очень аккуратно.
Натренировали сеть. Как делать предсказания? Изначально 2000 на 2000 режутся на куски 1000 на 1000 с перехлестом. Опять же, можно поизвращаться и сделать такой фокус — предсказать, например, на кусочке машинки, а потом взять этот изначальный спутниковый снимок, как-то отразить, сделать предсказание и потом отразить обратно. По сути, мы предсказываем то же самое в первом и втором случае, но немножко по-разному. Можно считать это некой ансамблевую технику. И — алгоритм non-maximum suppression. По сути, если мы порезали картинку 2000 на 2000 на куски с перехлестом, то одна машинка может оказаться в различных кусках. Когда мы предсказываем, получается два предсказания одной и той же машинки. Это надо чистить — что и делает алгоритм non-maximum suppression. Если два bounding box пересекаются в предсказаниях, тот, у которого confidence повыше, остается, а остальное режется под ноль.
Короче, берутся картинки, режутся на кусочки, делается предсказание, собираются обратно. Это происходило на высоком уровне.
Всякие аугментации немного добрасывают, и именно это отделило меня по точности от других ребят в Slack, от Сергея Мушинского и Владислава Кассыма.
Про скорость предсказания. Люблю добавлять в статьях, насколько быстро все работает, потому что так можно оценить, насколько все перечисленные модели далеки от продакшена, от реальных продуктов, и что с этим всем делать. На двух GPU — у меня дома в десктопе стоит два Titan Pascal X — получается где-то 20 предсказаний, 20 картинок в секунду. Вот и все решение.
 Когда все хорошо, говорить скучно. Давайте говорить о том, что не получается. Тут всякие автобусы друг к другу плотно натыканы, еще и под углами в правом нижнем углу. Зеленые bounding boxes — предсказания. Видно, что предсказаний гораздо меньше, чем автобусов. Выяснилось, да и остальные подтвердили, что когда надо предсказывать много объектов и они очень плотно упакованы, то сети как-то не хватает. Она что-то предсказывает, а что-то нет. Думаю, для людей, которые сейчас работают над задачей подсчета морских котиков на Kaggle, это будет особенно важно, потому что котики чуть ли не в три слоя друг на друге лежат. Понять, кто из них где, достаточно тяжело. Я зашел, попытался, но до топа мне еще далеко. Там такие фокусы не проходят, надо немного по-другому работать.
Когда все хорошо, говорить скучно. Давайте говорить о том, что не получается. Тут всякие автобусы друг к другу плотно натыканы, еще и под углами в правом нижнем углу. Зеленые bounding boxes — предсказания. Видно, что предсказаний гораздо меньше, чем автобусов. Выяснилось, да и остальные подтвердили, что когда надо предсказывать много объектов и они очень плотно упакованы, то сети как-то не хватает. Она что-то предсказывает, а что-то нет. Думаю, для людей, которые сейчас работают над задачей подсчета морских котиков на Kaggle, это будет особенно важно, потому что котики чуть ли не в три слоя друг на друге лежат. Понять, кто из них где, достаточно тяжело. Я зашел, попытался, но до топа мне еще далеко. Там такие фокусы не проходят, надо немного по-другому работать.
В ситуации close packed objects, когда объекты натыканы очень близко друг к другу, все идет не очень хорошо. Тут надо либо какие-то эвристики крутить, либо поворачивать, предсказывать и поворачивать обратно, черт его знает.
 Вот, достаточно редкая ошибка, но он любил мне предсказывать вагоны поездов как автобусы. Сравните их чисто визуально. Они по размеру и по расцветке примерно одинаковые, и сеть я сильно не осуждаю. Но это потом резалось какими-то эвристиками. На верхней картинке квадратики, а рядом с ними цифры, показывающие уверенность. Она меряется от 0 до 100. Сеть вообще не стесняется: здесь на 100% уверен, здесь не очень — 99%. По факту так и было. Сеть была очень сильно уверена в предсказаниях и не лажала. Есть подозрение, что под эту задачу все работало на ура.
Вот, достаточно редкая ошибка, но он любил мне предсказывать вагоны поездов как автобусы. Сравните их чисто визуально. Они по размеру и по расцветке примерно одинаковые, и сеть я сильно не осуждаю. Но это потом резалось какими-то эвристиками. На верхней картинке квадратики, а рядом с ними цифры, показывающие уверенность. Она меряется от 0 до 100. Сеть вообще не стесняется: здесь на 100% уверен, здесь не очень — 99%. По факту так и было. Сеть была очень сильно уверена в предсказаниях и не лажала. Есть подозрение, что под эту задачу все работало на ура.
 Был какой-то процент картинок, достаточно мало. Чтобы найти эти пять картинок, мне пришлось пролистать картинок 70–100 с предсказаниями. Да, он любил предсказывать какую-то ерунду как объекты. Красными квадратиками были отмечены мотоциклы. Их реально тяжело отмечать, просто потому что мало пикселей и мало фич можно извлекать. Слева сверху — угол здания, посередине — два рядом стоящих человека. Или больше. Может, чемодан кто-то из них держит. Сеть их может принять за мотоцикл. Справа — гараж какой-то, она его опознала как грузовик. Действительно, грузовики такого же цвета.
Был какой-то процент картинок, достаточно мало. Чтобы найти эти пять картинок, мне пришлось пролистать картинок 70–100 с предсказаниями. Да, он любил предсказывать какую-то ерунду как объекты. Красными квадратиками были отмечены мотоциклы. Их реально тяжело отмечать, просто потому что мало пикселей и мало фич можно извлекать. Слева сверху — угол здания, посередине — два рядом стоящих человека. Или больше. Может, чемодан кто-то из них держит. Сеть их может принять за мотоцикл. Справа — гараж какой-то, она его опознала как грузовик. Действительно, грузовики такого же цвета.
А снизу какой-то мусор, который был инкриминирован как красные машинки. Это, конечно, криминал. Такого, по идее, сеть не должна была делать, но я это списываю просто на то, что красных машинок было мало.
 Тут я не успел, но можно было добавить много картинок. На предыдущих слайдах были скорее исключения, чем правила. Точность моей модели была где-то 0,85 из 100, и я ошибся на 1200 машинок, если оценивать в них
Тут я не успел, но можно было добавить много картинок. На предыдущих слайдах были скорее исключения, чем правила. Точность моей модели была где-то 0,85 из 100, и я ошибся на 1200 машинок, если оценивать в них
А когда я глазами смотрю, я не вижу 1200. Я вижу 20, или, если сильно себя заставлю, 50.
Проблема в том, что многие машины визуально не отличить, причем что мне, что сети, что, видимо, тем индусам, которые всё размечали. Банально серая машина в тени не отличается от какой-нибудь черной машины. Или та же самая машина, но на солнце, выглядит уже как светлая и белая. Где как и что отмечается — оно не обязательно будет связано с реальной жизнью.
Синие машины тоже доставляют. Если есть ярко-синяя машина, а такие были, то с ней все понятно, мы ее не детектим. А если какая-то черная с синеватым отливом? Там достаточно много было таких и непонятно, нужно ли их детектировать.
Всякие белые и длинные хетчбэки детектировались как фургоны, и прочее. Там были проблемы с разметкой, парень, занявший первое место, это отметил на форуме. Мы с ним пообщались немножко. Если бы разметка была повыше уровнем, наши модели, ничего не делая, показывали бы не мои 0,85 или его 0,87, а где-нибудь 0,95–0,97. То есть сети работали реально обалденно. Мы поражались, когда делали визуальную оценку. Может, там дерево и одни фары торчат да багажник — а он и машину находит, и класс определяет. Меня это удивило в лучшую сторону.
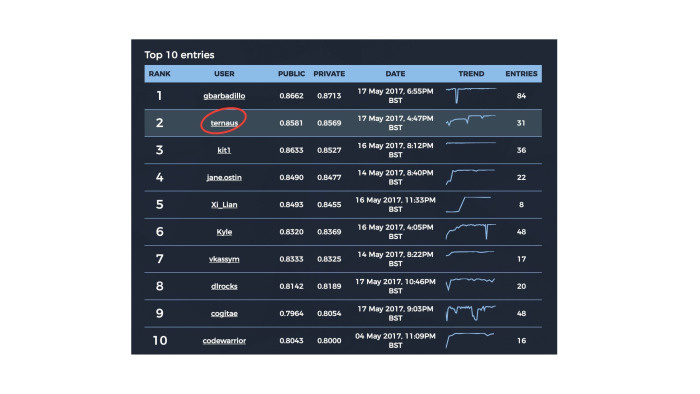 Вот табличка, которую я опубликовал в Facebook, когда британцы сказали, что по цвету паспорта денег не дадут. Она потом разошлась в новостях, где-то на «Вестях» вроде народ ее видел, еще где-то. Я эти передачи не смотрел, не знаю.
Вот табличка, которую я опубликовал в Facebook, когда британцы сказали, что по цвету паспорта денег не дадут. Она потом разошлась в новостях, где-то на «Вестях» вроде народ ее видел, еще где-то. Я эти передачи не смотрел, не знаю.
Здесь 10 участников, я второй, четвертый не будем говорить кто, хотя он назвал себя jane.ostin, ну и седьмое место — тоже наш парень из чата. Трое из десяти. Кайла все знают, легендарный альфа-гусь на Kaggle. Многие ребята из Kaggle тоже пришли сюда.
Британцы красавчики, что учудили здесь подсчет public и private. Все знают стандартные правила Kaggle: ты делаешь какой-то сабмит и тебе подсказывают оценку на private, а потом ты выбираешь два лучших сабмита, которые имеют право на жизнь. Потом соревнования оканчиваются, и по ним дается оценка того, насколько модель хороша в итоге. И только потом уже решается, кто победитель, а кто нет. Вам нужно в конце соревнования выбрать два лучших потенциальных сабмита.
Ребята, которые запиливали копию Kaggle, поняли, что должен быть private и public, разделили 33% на 66%. Они еще догадались, что public надо показывать по части public, а private — по части private. Но эту тему с двумя лучшими сабмитами они не поняли, и получилось, что public и private оценивались независимо. Можно думать, что на Kaggle надо указать два лучших сабмита, и они учитывались в private. Здесь учитывались все. И поэтому у парня на первом месте, который gbarbadillo, — у него 84 сабмита. Обычно на Kaggle нет никаких понтов, сабмить как можно больше, потому что ты же показываешь результат на public, но не на private. Здесь — нет, надо было сабмитить все подряд каждый день и по максимуму, просто потому что были шансы, что на private один из ваших рандомных сабмитов покажет чуть более удачный результат. Думаю, именно так он свои 0,87 и получил, потому что у нас разрыв где-то в 180 машинок, а 180 машинок я глазами не вижу. Наверное, модели у него получше были, раз он с б?льшим энтузиазмом к этому подошел. Ну и факт, что он гораздо больше сабмитил все подряд, тоже ему помог.
 Вот как это выглядит на картинке 2000 на 2000. Разного цвета боксы. Предсказания, судя по тому, что я глазами видел, верны. Вот так оно все и предсказывается. После этого для каждого бокса рассчитывается центр машинки, и результат уже идет в предсказание. Тут сеть тоже не стеснялась — 99, 100 и так далее, достаточно сложно. Машины тут где-то из-под дерева торчат, много интересных классов.
Вот как это выглядит на картинке 2000 на 2000. Разного цвета боксы. Предсказания, судя по тому, что я глазами видел, верны. Вот так оно все и предсказывается. После этого для каждого бокса рассчитывается центр машинки, и результат уже идет в предсказание. Тут сеть тоже не стеснялась — 99, 100 и так далее, достаточно сложно. Машины тут где-то из-под дерева торчат, много интересных классов.
 Итоговое решение. Что мы сделали? Я лично перебил центры машинок под bounding boxes, во многом потому что так было проще начать задачу. Если бы я этого не сделал, фиг бы кто из Slack подписался бы поучаствовать, коллективом работать удобнее. А так я им боксы набил, и они такие — ну, значит, попробуем.
Итоговое решение. Что мы сделали? Я лично перебил центры машинок под bounding boxes, во многом потому что так было проще начать задачу. Если бы я этого не сделал, фиг бы кто из Slack подписался бы поучаствовать, коллективом работать удобнее. А так я им боксы набил, и они такие — ну, значит, попробуем.
С точки зрения модели используем Faster R-CNN, у которой base был VGG-16. Изначально мы пробовали ResNet, но работало гораздо хуже. Потом переключились на VGG.
Использовали D4, про которую я недавно рассказывал, аугментацию train and test, ну и всё.
С точки зрения железа я использовал свой домашний компьютер. CPU не очень важен. Оперативы у меня 32 ГБ — что тоже, наверное, не очень важно. 16 бы хватило. Ну и два Titan — это важно. Британцы мне вчера написали e-mail и через несколько дней опубликуют у себя на сайте итоги соревнования: как они все восхитились, прониклись, как все красиво получилось — ну, обыкновенный пиар. Какие-то вопросы они задают участникам, даже фотографию попросили. Надо подумать, что им отправить. Один из вопросов был: а что сделало ваш подход уникальным по сравнению с другими участниками? Хочется ответить, что у меня был другой random seed, он просто был удачнее. Но по сути что я, что Серега, что Владислав занимались примерно одним и тем же. Мы брали MXNet, пилили точно так же. Просто, видимо, из-за того, что у меня было больше железа, я чуть дольше тренировал. Аугментации они добавили немножко, но в целом я только на этом, наверное, оторвался.
На тему двух GPU в Slack достаточно частый вопрос: вот я убедился, что deep learning возбуждает, красиво, умные слова, ИИ и прочее — но какое железо надо? Я студент, денег нет, сколько мне надо украсть? Нормальный ответ: чтобы начать, одного GTX 1080 хватит за глаза и на нем можно нормально все делать, в топ уходить. Но чтобы где-то как-то усугубить и претендовать на призовые места, имеет смысл вложиться в железо. Два GPU — нормально. Причем до соревнования я не умел их параллелить, потому что в Keras это океан боли. Зато можно проверять две идеи одновременно. Как показал эксперимент, соревнования — это не несколько умная у тебя модель, насколько ты сам умный или еще что-то, а как быстро ты можешь итерировать и отсекать свои и чужие идеи. И когда у вас два GPU, можно тренировать две сети и отсекать гораздо быстрее. Думаю, домой приеду, еще парочку куплю.
Спасибо. Затаскивали мы это соревнование не в одиночку, там были еще двое ребят, они тоже в десятке. Это Сергей Мушинский — привет, Ангарск! Это Владислав Кассым, тоже привет. И Сергей Белоусов. Он сам участвовать не мог по каким-то религиозным соображениям, зато он в области object detection большой эксперт, очень хорошо меня консультировал по статьям, глупым вопросам и всему остальному. Хочется подчеркнуть, что я в задаче ни черта не понимал еще месяц назад. И за месяц натаскаться с нуля до кое-чего, второе место, новости и так далее — для этого нужно общение с теми, кто готов отвечать на твои вопросы. Спасибо.
Спустя несколько недель Владимир выступил на одной из тренировок Яндекса по машинному обучению. Он рассказал о своём подходе к участию в конкурсах, о сути Data Science Challenge и о решении, которое позволило ему занять второе место.
Сегодня мы поговорим об этом конкурсе, который был, с одной стороны, наиболее простым за последние много месяцев с точки зрения сложности порога вхождения. Но с другой стороны, он так смешно разошелся по новостям, что я еще долго буду от этого оправляться.
Историческая справка. На Kaggle с декабря по март проходило соревнование про спутники, которое было хорошо известно в Slack-канале Open Data Science. Мы всем коллективом его решали и достаточно хорошо выступили. Из первых десяти мест пять были заняты людьми, которые, как минимум, зарегистрированы в ODS. Второе место заняла команда Романа Соловьева и Артура Кузина, они попилили 30 штук баксов под это дело. А на третьем месте — мы с Серегой Мушинским, наш приз тоже был нормальный.
Задача достаточно интересная. Красивые картинки, интересные задачи, можно подтянуть под какой-то продукт. С ребятами контактировали различные компании, предлагали какой-то консалтинг, не консалтинг — чтобы они их знания применяли к другим картографическим задачам. Была интересная задача, и мы под это дело добавили немного пиара.Были написаны посты — два поста на Хабре, мой и Артура. Я таки закончил и опубликовал пост на Kaggle в основном блоге, Артур до сих пор ленится. Артур прочитал речь здесь, и я две или три речи задвинул где-то в Долине. Под это дело мы опубликуем научную статью на следующей неделе, она на стадии полировки.
Организатором была британская разведка MI6, MI5 и лаборатория Defence Laboratory при Министерстве обороны. Они под это дело умудрились выбить со своего правительства достаточно большие деньги, полмиллиона долларов. В Долине это вообще ни о чем, и компания может себе это позволить, но интересно, что ученые при правительстве могли достать такие деньги даже в Британии.
Они выбили 465 штук баксов. Из них 100 пошло на призы, а остальные 365 были, в общем, освоены Kaggle за поддержку соревнования, за платформу, хостинг и т. д. Нормальный там маржинг. И организаторы в результате получили решение в том формате, который предоставляет Kaggle: куча кода и два скрипта, train и predict, а внутри куча всякой вермишели, непонятно что. Когда мы им это все презентовали, они достаточно сильно плыли в нашем решении. Не факт, что у них просто знаний и навыков хватает с этим что-то сделать. По факту они фиганули полмиллиона долларов, получили интересное решение, кучу красивых картинок, и непонятно, что с этим делать. Но сама идея им понравилась. И вообще британские ученые сейчас очень активно работают в этом отношении. Мне нравится, что они делают лучше, чем Минобороны России, США и всех остальных стран. У них много данных, много интересных задач. Правда, у них денег не очень много и они пытаются как-то пиариться и привлекать дата-саентистов.
Они нашли еще немного денег… ну, не так много. И нашли подрядчика, который запилил им копию Kaggle. Собрали каких-то данных, подготовили, почистили и сделали еще два соревнования, прямо по окончании той задачи на Kaggle про спутники. Одно было computer vision, про него чуть позже, а другое — natural language processing. Кто-то из наших участвовал, но в тройку не вошел. Но тоже говорят, что интересно. Черт его знает.
Британцы же на своей волне, тем более подрядчик к соревнованиям, к data science имеет достаточно ортогональное отношение. И они там начали чудить. Потом поговорю про метрику и про то, как они делили private и public, — что было достаточно смешно, и надо было бы этим воспользоваться, если бы мы заранее знали.
Из-за чего весь шум по новостям и как все это получилось? Правила у них написаны очень хитро: участвовать могут все, но если ты уходишь в топ на денежный приз — а в каждом соревновании денежный приз составлял 40 тыс. фунтов — то на него могли претендовать только люди определенных категорий. В общем, не все. И они сделали хитрые манипуляции на тему паспорта, места проживания, банка и т. д. Несмотря на то, что я резидент США, живу в Сан-Франциско, плачу налоги там, не спонсирую российское правительство и кого бы то ни было даже через уплату налогов, все равно мне приз не положен чисто по цвету паспорта. С другой стороны, это не такие большие деньги для меня были, все не так страшно. Зато хоть история получилась интересная, буду внукам рассказывать.
Когда мы презентовали решение задачи про спутники, которая шла зимой, мы спросили организаторов, какого лешего и доколе такая дискриминация будет твориться? Там достаточно адекватный мужик, ученый, он сказал, что это подрядчик что-то мутит, на самом деле все будет по-другому, все исправим, все будет замечательно. Так не случилось, но тем не менее.
Теперь о самой проблеме. У Kaggle в последний год то data leak, то один, то пять, то еще какая-то муть с данными, то train и test разные. В общем, куча всякой экзотики. Это задалбывает. Когда ты приходишь домой по вечерам, ты не хочешь заниматься всей этой нездоровой инженерией, а хочешь, как белый человек, стакать XGBoost или тренировать сети, что-то такое.И вот британцы подготовили достаточно чистые данные. Там были вопросы к разметке, но совсем незначительные. Мы имеем 1200 спутниковых снимков, каждый сделан с высоты примерно 100 метров, думаю, чисто визуально. Каждый пиксель соответствует 5 см, и нужно было сделать стандартную задачу object detection. У нас есть девять классов, и вот примеры из их документации: мотоцикл, белая длинная машина и белая короткая машина. Сеть действительно путалась. Короткий хетчбэк или длинный хетчбэк — были вопросы к этому. Белый седан, хетчбэк, черный седан, хетчбэк, красный седан, хетчбэк, белый фургон и красно-белый автобус.
Реально по улицам еще ездят синие, желтые машинки и все остальные. Их надо было игнорировать. Почему они выбрали эти — кто их знает. В общем, надо найти машинки, но не все, а только определенные, и разбить их по классам. Плюс давайте добавим мотоциклы. Хорошо хоть не велосипеды и не самокаты. По сравнению с машиной — несмотря на то, что она 5 см на пиксель — мотоцикл достаточно шумный. Даже здесь он выглядит как некое немного расплывчатое пятно. Сама задача — стандартный object detection.
Любая задача классификации, любая презентация не обходится без картинки, которая показывает распределение классов. Это чтобы поговорить о том, что мы бы ушли в топ, но тут class inbalance, и он такой плохой, мы не смогли справиться, жизнь — печаль и все такое.Здесь такого не было. Да, видно, что каких-то классов совсем мало — гораздо меньше, чем всех остальных. Например, крайний правый класс — автобус, или крайний левый класс — мотоциклы. Но это была не проблема, просто потому что мотоциклы от машин отличаются сильно и автобусы от всего остального отличаются сильно. И несмотря на то, что их мало, они настолько яркий класс, что с их детекцией проблем не было.
А во всяких этих белых хетчбэках и всем остальном действительно путались.
Как данные были предоставлены? Понятно, что можно маркировать данные по-разному. У нас спутниковые снимки или другие изображения, и нужно отметить машинки, ну или собачек, кошек… Можно обводить bounding boxes, целиком область, в которую входит данный объект, или просто мышкой ткнуть на точку и сказать, что это наш объект.Применяются оба метода, и даже недавно была статья от Google, в которой они на десяти страницах размусоливали, не как новую сеть построить, а как правильно тренировать индусов, чтобы маркировать объекты, тыкая точечками так, чтобы потом восстанавливать bounding boxes, и как это все красиво. Статья довольно достойная. Правда, не очень понятно, что с ней делать, если нет специально обученных индусов.
Много статей про то, как работать и с bounding boxes, и с точками. В принципе, когда вы предсказываете и классифицируете object detection через bounding box, точность выше просто потому, что надо предсказать координаты этого четырехугольника. Loss function более точная и привязанная к самим данным. А когда у вас точка, предсказывать центр действительно сложнее. Точка и есть точка. Но в данной задаче, как и в задаче про котиков, которая проходит сейчас на Kaggle, данные отмаркированы через точки.
На этой картинке по размеру одна четверть от больших снимков 200 на 200. Они нам дают изображение, где отмечены центры машин для 600 картинок, и надо было предсказать их для других 600.
Метрика. Понятно, что любая задача не имеет смысла, пока не придумана численная оценка точности модели. Потом пытаешься ее подгонять, оптимизировать, чтобы все было прекрасно.Метрикой в данной задаче выступал Jaccard. Как он мерился? Есть точка, которую они отмаркировали, центр машин. Вы предсказываете центр машин. Если они достаточно близко друг к другу, рядом, и это зависит от разных классов из таблицы снизу, то это true positive. Если нет — false positive. Если вообще ни черта нет — false negative.
Все это суммируется без усреднения по классам. Каждый мотоцикл вносит столько же, сколько автобус, фургон и все остальное. И Jaccard, true positive на общий union.
Соревнований сейчас море. Даже по deep learning сейчас десять соревнований проходит. У всех призы, интересные задачи, одни котики или задача про шейки матки чего стоят, какие-то тропики в Амазонии — много всего интересного. И это на Kaggle, где нормальная платформа, комьюнити и все прекрасно. Да банальный ImageNet 2017 заканчивается через пару недель, а я еще даже код не начал писать.Когда я открываю какое-то соревнование, первый вопрос — зачем мне это надо? Потому что убивать свои вечера, выходные или на работе не работать, а соревнования гонять — нужны причины. Часто в голове рисуется некий список плюсов и минусов. Если мне нравится, как он выглядит, причем минусов может быть больше, — я обычно участвую.
Про минусы. Почему не стоит участвовать? Потому что денег не будет. Я на Kaggle участвовал последние два года и никогда не думал про призовые деньги, потому что участвовать в соревновании из финансовых соображений — наивный оптимизм. Уйти в топ, да еще в деньги, реально тяжело. Там 3000 участников, все брутальные ребята, хорошо подготовлены, у них куча железа и они не работают. Реально тяжело.
После того, как на спутниковых снимках нам дали приз и мне понравилось, манера мышления как-то немного изменилась в более меркантильную сторону. Так что денег не будет по правилам. Это было известно заранее, несмотря на то, о чем они после этого рассказывали в новостях.
Каждое соревнование дает очень много знаний. Но в одиночку бодаться в новую область тяжело. Поэтому гораздо удобнее, когда вас 50 человек и каждый рассказывает, что у кого получилось. В таком режиме можно за месяц-два, ничего не понимая в данной задаче, подняться до эксперта достаточно высокого уровня. Нужен коллектив. Коллектива не было, потому что это не Kaggle, а ребята из Slack не горели желанием участвовать, просто потому что денег не будет и вообще правила дурацкие. Ну и лень всем было.
Многие из этих соревнований не просто дают знания. Предположим, кто-то из вас будет искать работу на Западе. Вы неожиданно выясните, что из тех людей, которые там есть, народа, знающего о Яндексе, ШАДе, МФТИ и всех остальных, — гораздо меньше, чем народа, знающего о существовании Kaggle. Поэтому имеет смысл с перспективой продавать это при приеме на работу. Насколько интересной может быть задача для каких-то людей, стартапов и т. п.? Понятно, что любая задача про спутниковые снимки будет интересна. Любая задача про медицинские изображения будет интересна. Постакать xgboost — под большим вопросом. Kaggle знают, а какую-то доморощенную британскую площадку никто не знает. И строчка в резюме, типа я взял площадку, о которой никто из вас не знает, и там я красавчик, поэтому возьмите меня к себе, — звучит не очень хорошо. Kaggle в этом отношении гораздо лучше.
А теперь список плюсов. Зачем все это нужно? Данные реально красивые, хорошо подготовленные. Задача интересная. В этой теме я ничего не соображал на момент начала соревнований, а значит, за месяц-два можно натаскаться до действительно профессионального и серьезного уровня. И нет проблем с валидацией, валидацию мы вообще не делали. Действительно, очень красивые данные — основная мотивация. Она в том, что можно на каких-то чистых данных натренировать что-то, что важно, интересно. Можно добавить скиллов в свой инструментарий.
Image detection. Тот же ImageNet, задача про котиков и все остальное. Много где используется image detection. Я последние полгода искал работу в Долине, и про классификацию изображений никто не спрашивает, потому что это просто и пошло. А вот про detection спрашивают все подряд, очень много всяких самодвижущихся машин и прочих интересных применений в бизнесе. Jни спрашивают: «Ты в этом что-то соображаешь?» — «Нет». И дальше разговор не шел. Этот вопрос чисто по знаниям надо было закрывать. И его задача тоже добавляла.
Данных здесь достаточно много, а не как обычно — 6 картинок на public, 26 на private, какой-то shuffle на leaderboard. Здесь такого не было. Достаточно много картинок и на train, и на test, и каждый класс достаточно хорошо представлен, все хорошо. Никаких data leak. Кто участвовал в Quora, где у них обсуждение на форуме шло в режиме: «А ты помнишь, в четвертом лике ты уже подкрутил параметр?» — «Не, я над пятым ликом работаю». Такого криминала там не было, что очень приятно.
И в каждом соревновании вы работаете, пишите какой-то код, потом он копипастится или переносится в другие задачи. было бы полезно натренироваться на этих британских машинках, а потом перенести всё на другие задачи, попытаться в них гордо въехать в топ. Пока не получилось, но я над этим работаю.
Вся эта болтология в итоге сведется к тому, что решение на полстраницы. Что мы имеем? Тренировочные данные были размечены через точечки. Есть достаточно много статей о том, как все это считать, crowd counting и все остальное. И вообще: поскольку для многих компаний гораздо дешевле нанять индусов, тыкающих мышкой в какие-то объекты, нежели заставить их правильно обводить, то и точность нужна повыше, и времени больше. Просто дороже. Британцы, видимо, тоже наняли индусов, те натыкали, получились точечки — см. картинку снизу.Как с этим работать, сходу непонятно. Про это надо читать, писать какой-то код, но мне было лень, потому что я на всю задачу отвел себе месяц. В первые две недели из четырех я собирался с мыслями. За две недели до конца решил все-таки начать что-то делать. Изобретать уже времени не оставалось, да и не хотелось. А хотелось свести эту задачу к стандартной решенной классической задаче.
Я на работе убил два рабочих дня и перебил все эти точечки под bounding boxes. Прямо взял sloth и вручную перебил train set. Слева изначальные метки, справа те, что в конце. Особо внимательный увидит, что один bounding box я таки забыл обвести. Сейчас на Kaggle — да и везде — достаточно часто проходит трюк, когда добавляется дополнительная информация, дополнительные метки к тренировочным данным. И это позволяет гордо въехать в топ.
Google опубликовал достойную статью, последний выпуск был месяц назад. Там 11 авторов. Никакой новой архитектуры они не сделали, они реально воспользовались тем, что у Google много ресурсов, взяли много архитектур, чуть ли не сотню, написали под каждую код, прогнали через гугловские GPU, поставили много хороших экспериментов, собрали все в таблицу и опубликовали достаточно хорошую обзорную статью. Она объясняет, какие архитектуры чуть получше подходят для object detection, какие чуть похуже и чем можно пожертвовать.На основе этой статьи сложилось впечатление, что лучшие по точности архитектуры — на основе Faster R-CNN, а по скорости — на SSD. Поэтому в продакшен пилят SSD, а для соревнований и так далее — Faster RCNN.
Есть два основных семейства. Faster R-CNN медленная, предсказания повыше в точности. И, что было очень важно для меня, мелкие объекты тоже достаточно аккуратно предсказывают. А вы видели, что мотоцикл на этих снимках еще надо было найти. То есть нужна была сетка, которая делает аккуратные предсказания и тренировку на малых объектах. SSD достаточно быстрая: предсказывает, тренируется. Но она менее точная, и с малыми объектами в силу нюансов архитектуры сети там реально все плохо. Поэтому я остановился на Faster R-CNN. Вот сеть, архитектура выглядит вот так. Как вы видели, на этой картинке нужно найти все bounding boxes, а потом предсказать, какой класс в каждом из квадратиков там находится. Сеть работает примерно так. И она достаточно медленная — несмотря на то, что «Faster». Сначала какие-то конволюционные слои на основе претренировочных сетей извлекают фичи. Потом одна ветвь предсказывает эти боксы. Потом идет классификация. Вот как интуитивно об этом думаешь — примерно так же тут все и происходит. Четыре loss-функции, все достаточно сложно, и с нуля писать код умаешься. Поэтому, естественно, никто этим не занимается.
Мы выбрали, какую сеть использовать. Сейчас достаточно много на рынке всяких фреймворков: TensorFlow, Theano, Keras, MXNet, Cafe, еще какой-то зоопарк. Их реально очень много, и надо подумать, какую выбрать, какая здесь зайдет.До этого я использовал исключительно Keras с бэкендом от Theana или TensorFlow. У Keras прекрасный API, очень удобно, там можно много штук делать из коробки, код на GitHub достаточно чистый, если надо что-то подкрутить — все достаточно просто.
Я знал код, достаточно нормальная документация, и к тому моменту, после первой задачи, я купил себе два GPU. Хотелось уже быть модным, распараллелить, чтобы все было быстро, как у мужиков в статьях, а не как у нас у всех обычно. Но с Keras была проблема. Я запустил, сделал предсказание и на тот момент даже ушел в топ-10 по этой задаче. Но он медленный, как эстонская черепаха. То ли такой overhead на вычислениях, то ли TensorFlow сам по себе медленный, а Keras добавляет overhead. Ну и имплементация, видимо, тоже была не самой удачной.
В то же время Артур Кузин очень активно в Slack топит за MXNet — что он быстрый, хороший, параллелится, все там прекрасно. В основном из-за параллелизации и хотелось этим воспользоваться. Параллелизацию остальные участники Slack подтвердили и сказали, что параллелится реально мизинцем левой ноги из коробки, все прекрасно. Faster R-CNN медленный, но у меня два GPU, хочется одно компенсировать другим. Keras не подходит — так давайте попробуем MXNet.
Что с ним плохо. Там непонятно что происходит в коде. Написан он тоже какими-то инопланетянами. Зато достаточно быстрый фреймворк. И из тех двух недель, что я работал над задачей, первую неделю я разбирался, кто там чей брат, как скормить данные, что куда скомпилировать. Скомпилировать там надо постараться. В общем, куча всякой экзотики. Но к концу недели я разобрался, подбил еще пару мужиков в чатике, и мы начали пилить MXNet. И все сразу стало хорошо. С первой же попытки уходишь в топ-5, тебе сразу приятно и ты прощаешь MXNet все.
Само решение. Что было сделано? Берется MXNet, в нем, прям в самом репозитории, есть пример Faster R-CNN. Берется этот код, он сделан на примере (неразборчиво — прим. ред.), ты меняешь это на машинки. Затем взяли все спутниковые снимки, нужно было добавить батч-генератор, потому что снимки 2000 на 2000 в сеть просто так не скормишь. Надо их либо уменьшать, но тогда теряется информация и мотоцикл вообще будет не найти, либо резать на кусочки и скармливать сети.В итоге я случайным образом вырезал из картинок куски 1000 на 1000. Потом все любят докапываться до моих D4 group augmentation. Что это такое? Кто знает математику и теорию групп, это группа симметрии квадрата. Грубо говоря, если у нас какой-то квадрат и мы его отразим вокруг центральной оси, вертикальной или горизонтальной, повернем на 90 градусов, то он в пространстве не изменится. И группа симметрий там как раз D4, 8 элементов. Если говорить на нормальном человеческом языке, это повороты на углы, кратные 90, отражение, да и всё.
Как тренировалась сеть? Берется картинка 2000 на 2000, из нее вырезается рандомный кусок 1000 на 1000, потом применяется отражение или поворот, ну и потом результат скармливается сети. Всё.
Мы все привыкли, что в классификации пролетают какие-то 90 картинок в секунду, 100, такие цифры. А здесь на двух GPU — 8. Он действительно достаточно медленный, поэтому Faster в продакшен надо прикручивать очень аккуратно.
Натренировали сеть. Как делать предсказания? Изначально 2000 на 2000 режутся на куски 1000 на 1000 с перехлестом. Опять же, можно поизвращаться и сделать такой фокус — предсказать, например, на кусочке машинки, а потом взять этот изначальный спутниковый снимок, как-то отразить, сделать предсказание и потом отразить обратно. По сути, мы предсказываем то же самое в первом и втором случае, но немножко по-разному. Можно считать это некой ансамблевую технику. И — алгоритм non-maximum suppression. По сути, если мы порезали картинку 2000 на 2000 на куски с перехлестом, то одна машинка может оказаться в различных кусках. Когда мы предсказываем, получается два предсказания одной и той же машинки. Это надо чистить — что и делает алгоритм non-maximum suppression. Если два bounding box пересекаются в предсказаниях, тот, у которого confidence повыше, остается, а остальное режется под ноль.
Короче, берутся картинки, режутся на кусочки, делается предсказание, собираются обратно. Это происходило на высоком уровне.
Всякие аугментации немного добрасывают, и именно это отделило меня по точности от других ребят в Slack, от Сергея Мушинского и Владислава Кассыма.
Про скорость предсказания. Люблю добавлять в статьях, насколько быстро все работает, потому что так можно оценить, насколько все перечисленные модели далеки от продакшена, от реальных продуктов, и что с этим всем делать. На двух GPU — у меня дома в десктопе стоит два Titan Pascal X — получается где-то 20 предсказаний, 20 картинок в секунду. Вот и все решение.
Когда все хорошо, говорить скучно. Давайте говорить о том, что не получается. Тут всякие автобусы друг к другу плотно натыканы, еще и под углами в правом нижнем углу. Зеленые bounding boxes — предсказания. Видно, что предсказаний гораздо меньше, чем автобусов. Выяснилось, да и остальные подтвердили, что когда надо предсказывать много объектов и они очень плотно упакованы, то сети как-то не хватает. Она что-то предсказывает, а что-то нет. Думаю, для людей, которые сейчас работают над задачей подсчета морских котиков на Kaggle, это будет особенно важно, потому что котики чуть ли не в три слоя друг на друге лежат. Понять, кто из них где, достаточно тяжело. Я зашел, попытался, но до топа мне еще далеко. Там такие фокусы не проходят, надо немного по-другому работать.В ситуации close packed objects, когда объекты натыканы очень близко друг к другу, все идет не очень хорошо. Тут надо либо какие-то эвристики крутить, либо поворачивать, предсказывать и поворачивать обратно, черт его знает.
Вот, достаточно редкая ошибка, но он любил мне предсказывать вагоны поездов как автобусы. Сравните их чисто визуально. Они по размеру и по расцветке примерно одинаковые, и сеть я сильно не осуждаю. Но это потом резалось какими-то эвристиками. На верхней картинке квадратики, а рядом с ними цифры, показывающие уверенность. Она меряется от 0 до 100. Сеть вообще не стесняется: здесь на 100% уверен, здесь не очень — 99%. По факту так и было. Сеть была очень сильно уверена в предсказаниях и не лажала. Есть подозрение, что под эту задачу все работало на ура. Был какой-то процент картинок, достаточно мало. Чтобы найти эти пять картинок, мне пришлось пролистать картинок 70–100 с предсказаниями. Да, он любил предсказывать какую-то ерунду как объекты. Красными квадратиками были отмечены мотоциклы. Их реально тяжело отмечать, просто потому что мало пикселей и мало фич можно извлекать. Слева сверху — угол здания, посередине — два рядом стоящих человека. Или больше. Может, чемодан кто-то из них держит. Сеть их может принять за мотоцикл. Справа — гараж какой-то, она его опознала как грузовик. Действительно, грузовики такого же цвета.А снизу какой-то мусор, который был инкриминирован как красные машинки. Это, конечно, криминал. Такого, по идее, сеть не должна была делать, но я это списываю просто на то, что красных машинок было мало.
Тут я не успел, но можно было добавить много картинок. На предыдущих слайдах были скорее исключения, чем правила. Точность моей модели была где-то 0,85 из 100, и я ошибся на 1200 машинок, если оценивать в нихА когда я глазами смотрю, я не вижу 1200. Я вижу 20, или, если сильно себя заставлю, 50.
Проблема в том, что многие машины визуально не отличить, причем что мне, что сети, что, видимо, тем индусам, которые всё размечали. Банально серая машина в тени не отличается от какой-нибудь черной машины. Или та же самая машина, но на солнце, выглядит уже как светлая и белая. Где как и что отмечается — оно не обязательно будет связано с реальной жизнью.
Синие машины тоже доставляют. Если есть ярко-синяя машина, а такие были, то с ней все понятно, мы ее не детектим. А если какая-то черная с синеватым отливом? Там достаточно много было таких и непонятно, нужно ли их детектировать.
Всякие белые и длинные хетчбэки детектировались как фургоны, и прочее. Там были проблемы с разметкой, парень, занявший первое место, это отметил на форуме. Мы с ним пообщались немножко. Если бы разметка была повыше уровнем, наши модели, ничего не делая, показывали бы не мои 0,85 или его 0,87, а где-нибудь 0,95–0,97. То есть сети работали реально обалденно. Мы поражались, когда делали визуальную оценку. Может, там дерево и одни фары торчат да багажник — а он и машину находит, и класс определяет. Меня это удивило в лучшую сторону.
Вот табличка, которую я опубликовал в Facebook, когда британцы сказали, что по цвету паспорта денег не дадут. Она потом разошлась в новостях, где-то на «Вестях» вроде народ ее видел, еще где-то. Я эти передачи не смотрел, не знаю.Здесь 10 участников, я второй, четвертый не будем говорить кто, хотя он назвал себя jane.ostin, ну и седьмое место — тоже наш парень из чата. Трое из десяти. Кайла все знают, легендарный альфа-гусь на Kaggle. Многие ребята из Kaggle тоже пришли сюда.
Британцы красавчики, что учудили здесь подсчет public и private. Все знают стандартные правила Kaggle: ты делаешь какой-то сабмит и тебе подсказывают оценку на private, а потом ты выбираешь два лучших сабмита, которые имеют право на жизнь. Потом соревнования оканчиваются, и по ним дается оценка того, насколько модель хороша в итоге. И только потом уже решается, кто победитель, а кто нет. Вам нужно в конце соревнования выбрать два лучших потенциальных сабмита.
Ребята, которые запиливали копию Kaggle, поняли, что должен быть private и public, разделили 33% на 66%. Они еще догадались, что public надо показывать по части public, а private — по части private. Но эту тему с двумя лучшими сабмитами они не поняли, и получилось, что public и private оценивались независимо. Можно думать, что на Kaggle надо указать два лучших сабмита, и они учитывались в private. Здесь учитывались все. И поэтому у парня на первом месте, который gbarbadillo, — у него 84 сабмита. Обычно на Kaggle нет никаких понтов, сабмить как можно больше, потому что ты же показываешь результат на public, но не на private. Здесь — нет, надо было сабмитить все подряд каждый день и по максимуму, просто потому что были шансы, что на private один из ваших рандомных сабмитов покажет чуть более удачный результат. Думаю, именно так он свои 0,87 и получил, потому что у нас разрыв где-то в 180 машинок, а 180 машинок я глазами не вижу. Наверное, модели у него получше были, раз он с б?льшим энтузиазмом к этому подошел. Ну и факт, что он гораздо больше сабмитил все подряд, тоже ему помог.
Вот как это выглядит на картинке 2000 на 2000. Разного цвета боксы. Предсказания, судя по тому, что я глазами видел, верны. Вот так оно все и предсказывается. После этого для каждого бокса рассчитывается центр машинки, и результат уже идет в предсказание. Тут сеть тоже не стеснялась — 99, 100 и так далее, достаточно сложно. Машины тут где-то из-под дерева торчат, много интересных классов. Итоговое решение. Что мы сделали? Я лично перебил центры машинок под bounding boxes, во многом потому что так было проще начать задачу. Если бы я этого не сделал, фиг бы кто из Slack подписался бы поучаствовать, коллективом работать удобнее. А так я им боксы набил, и они такие — ну, значит, попробуем.С точки зрения модели используем Faster R-CNN, у которой base был VGG-16. Изначально мы пробовали ResNet, но работало гораздо хуже. Потом переключились на VGG.
Использовали D4, про которую я недавно рассказывал, аугментацию train and test, ну и всё.
С точки зрения железа я использовал свой домашний компьютер. CPU не очень важен. Оперативы у меня 32 ГБ — что тоже, наверное, не очень важно. 16 бы хватило. Ну и два Titan — это важно. Британцы мне вчера написали e-mail и через несколько дней опубликуют у себя на сайте итоги соревнования: как они все восхитились, прониклись, как все красиво получилось — ну, обыкновенный пиар. Какие-то вопросы они задают участникам, даже фотографию попросили. Надо подумать, что им отправить. Один из вопросов был: а что сделало ваш подход уникальным по сравнению с другими участниками? Хочется ответить, что у меня был другой random seed, он просто был удачнее. Но по сути что я, что Серега, что Владислав занимались примерно одним и тем же. Мы брали MXNet, пилили точно так же. Просто, видимо, из-за того, что у меня было больше железа, я чуть дольше тренировал. Аугментации они добавили немножко, но в целом я только на этом, наверное, оторвался.
На тему двух GPU в Slack достаточно частый вопрос: вот я убедился, что deep learning возбуждает, красиво, умные слова, ИИ и прочее — но какое железо надо? Я студент, денег нет, сколько мне надо украсть? Нормальный ответ: чтобы начать, одного GTX 1080 хватит за глаза и на нем можно нормально все делать, в топ уходить. Но чтобы где-то как-то усугубить и претендовать на призовые места, имеет смысл вложиться в железо. Два GPU — нормально. Причем до соревнования я не умел их параллелить, потому что в Keras это океан боли. Зато можно проверять две идеи одновременно. Как показал эксперимент, соревнования — это не несколько умная у тебя модель, насколько ты сам умный или еще что-то, а как быстро ты можешь итерировать и отсекать свои и чужие идеи. И когда у вас два GPU, можно тренировать две сети и отсекать гораздо быстрее. Думаю, домой приеду, еще парочку куплю.
Спасибо. Затаскивали мы это соревнование не в одиночку, там были еще двое ребят, они тоже в десятке. Это Сергей Мушинский — привет, Ангарск! Это Владислав Кассым, тоже привет. И Сергей Белоусов. Он сам участвовать не мог по каким-то религиозным соображениям, зато он в области object detection большой эксперт, очень хорошо меня консультировал по статьям, глупым вопросам и всему остальному. Хочется подчеркнуть, что я в задаче ни черта не понимал еще месяц назад. И за месяц натаскаться с нуля до кое-чего, второе место, новости и так далее — для этого нужно общение с теми, кто готов отвечать на твои вопросы. Спасибо.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru