7 советов UX-специалисту по работе с машинным обучением
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Разработка ИИГородские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
Атаки на ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Внедрение ИИИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Big data
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Работа разума и сознаниеМодель мозгаРобототехника, БПЛАТрансгуманизмОбработка текстаТеория эволюцииДополненная реальностьЖелезоКиберугрозыНаучный мирИТ индустрияРазработка ПОТеория информацииМатематикаЦифровая экономика
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-08-29 14:50

Алёна Лазарева, редактор-фрилансер, адаптировала статью UX-специалистов из Google о том, как использовать машинное обучение в своей работе и не забывать о нуждах пользователя.
Машинное обучение (Machine Learning или ML) — обширный подраздел искусственного интеллекта, изучающий методы построения алгоритмов, способных обучаться.
Машинное обучение позволяет компьютеру обнаруживать паттерны и взаимосвязи в данных, поэтому это отличный инструмент для создания персонализированного и динамического UX. Область его применения широка: от рекомендательных механизмов Netflix до беспилотных автомобилей. Задача UX-специалиста при работе над проектом под управлением ML — дать пользователю контроль над технологией, а не наоборот.
Машинное обучение постепенно заставляет нас переосмыслить подход к созданию практически всех продуктов. В этой статье мы собрали семь советов о том, как UX-дизайнерам сосредоточиться на нуждах пользователя при работе с ML.
 Поэтому первый пункт достаточно прост: машинное обучение не может определить, какие проблемы и задачи необходимо решить.
Поэтому первый пункт достаточно прост: машинное обучение не может определить, какие проблемы и задачи необходимо решить.
Вам всё еще придется выполнять эту трудную работу самим. Этнография, контекстные запросы, интервью, опросы, чтение заявок на поддержку клиентов, анализ логов и общение с пользователями помогут выяснить, понимаете ли вы потребности пользователей.
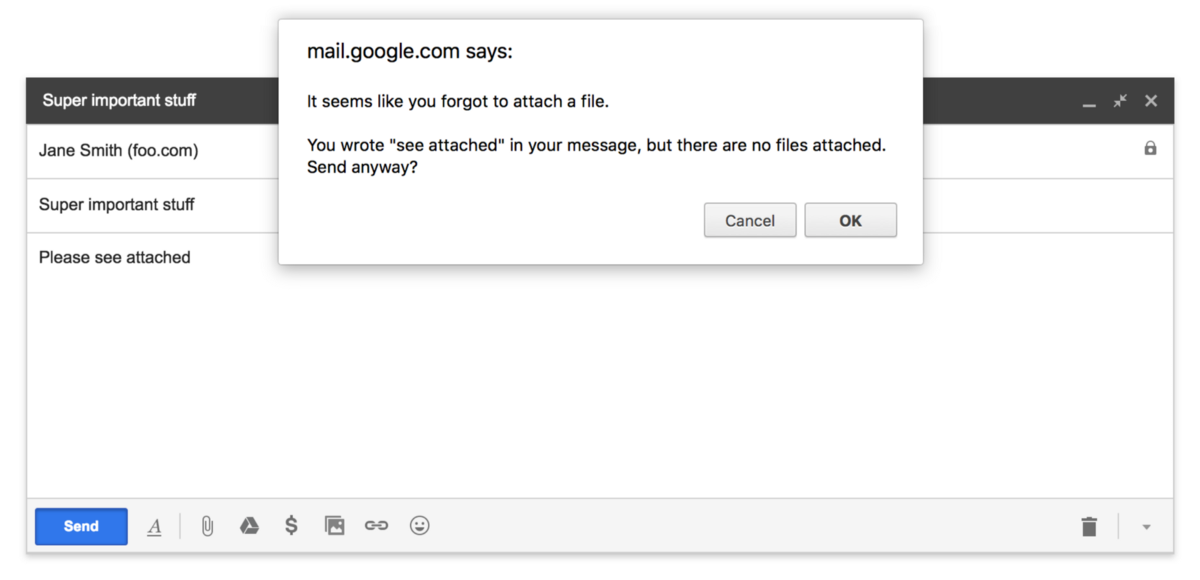
Если Gmail находит в письме фразы типа «вложение» или «прикреплённые файлы», то он проверяет, не забыли ли вы прикрепить документ. Если вложения нет, появляется напоминание. Здесь хорошо работает эвристический алгоритм. Машинное обучение с этой задачей справилось бы лучше, но стоило бы намного дороже.
Мы разработали набор упражнений и даем его командам, когда они решают использовать машинное обучение. Упражнения помогают понять, какие мысли и ожидания возникают у пользователей при взаимодействии с ML-системой, и какие данные необходимы для её построения.
Ответы на эти вопросы стоит обсудить с командой и положить в основу исследования пользователей. После того как вы закончите работу с упражнениями, скетчами и сторибордами, занесите все идеи в матрицу:

Занесите идеи в эту матрицу. Попросите команду проголосовать за то, какие идеи будут иметь наибольшее влияние на пользователя, и какие больше выиграют от применения ML.
Это позволит выделить наиболее эффективные идеи, и определить, какие из них сильно зависят от машинного обучения, а какие могут лишь немного выиграть от его применения. Идеи, с которых стоит начать, окажутся в правом верхнем углу матрицы. И если вы до сих пор не привлекли разработчиков к обсуждению, то самое время это сделать.
Тем не менее есть два подхода к исследованиям пользователей, которые могут помочь: используйте личные примеры пользователей и проведите эксперимент «Волшебник страны Оз».
При проведении пользовательских исследований с первыми прототипами, попросите участников поделиться некоторыми личными данными — например, фотографиями, списками контактов, рекомендациями музыки или фильмов, которые они получают. Вам нужно обязательно проинформировать участников, как эти данные будут использоваться во время тестирования и когда они будут удалены. С помощью этих примеров вы сможете сымитировать правильные и неправильные ответы системы. Например, вы можете имитировать работу системы, которая дает рекомендации фильмов пользователю. Обратите внимание, как пользователь объяснит, почему система выдала именно этот результат. Этот метод поможет вам больше, чем использование фиктивных примеров или описания концепта продукта.
Второй подход, который хорошо работает для тестирования еще не созданных продуктов под управлением ML-системы — это исследование «Волшебник страны Оз».
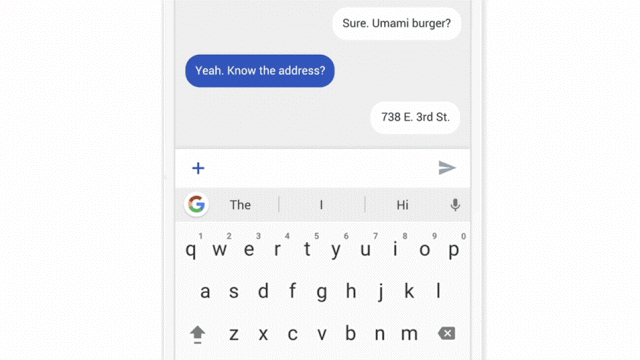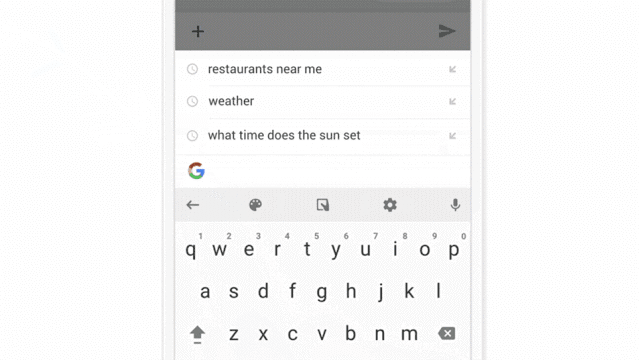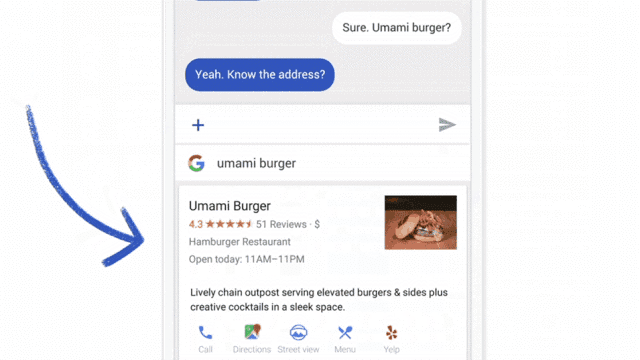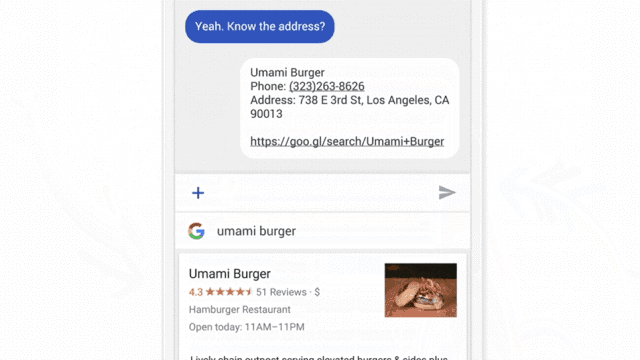
Интерфейсы чата — одна из самых простых ML-систем, которую можно протестировать с помощью подхода «Волшебник страны Оз». Для этого тестирования попросите члена вашей команды имитировать действия искусственного интеллекта в ответ на действия пользователя.
Важное условие при проведении исследования — пользователь должен думать, что он взаимодействует с автономной системой. Но на самом деле его экран контролирует человек, хорошо знакомый с продуктом (как правило, это член команды). Его задача — имитация действий ML-системы: ответы чат-бота, предложение контактов для звонка, рекомендация фильмов. Когда пользователь взаимодействует с тем, что он воспринимает как искусственный интеллект, он формирует представления о системе и корректирует поведение в соответствии с ними. Наблюдение за этим процессом крайне важно в нашей работе.
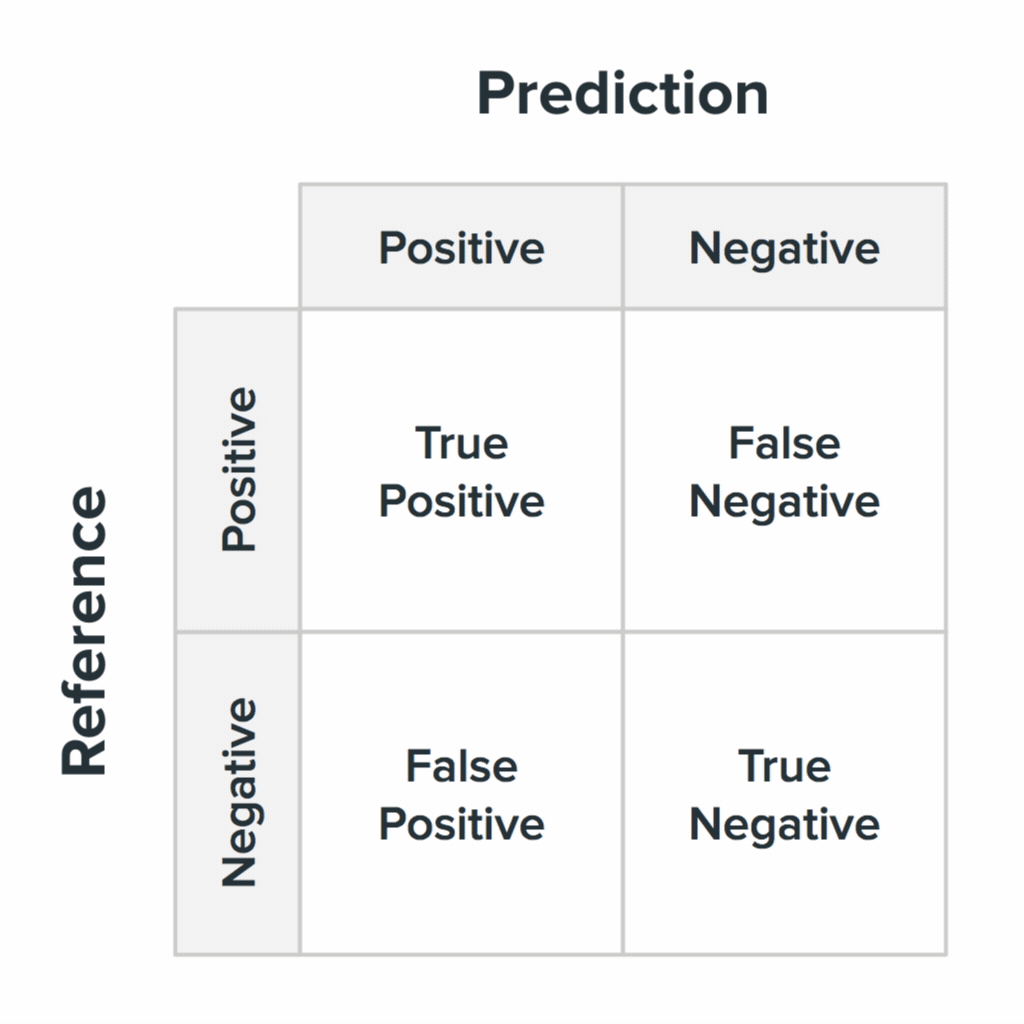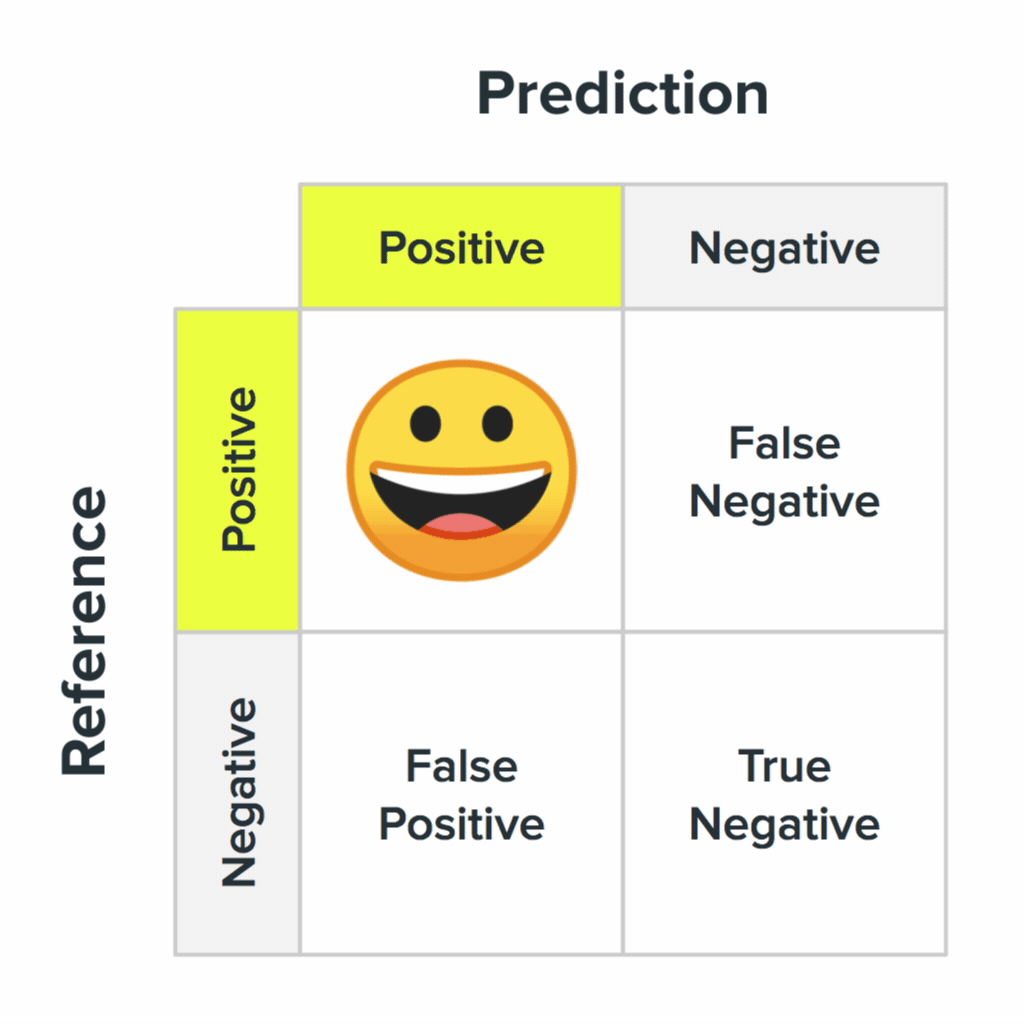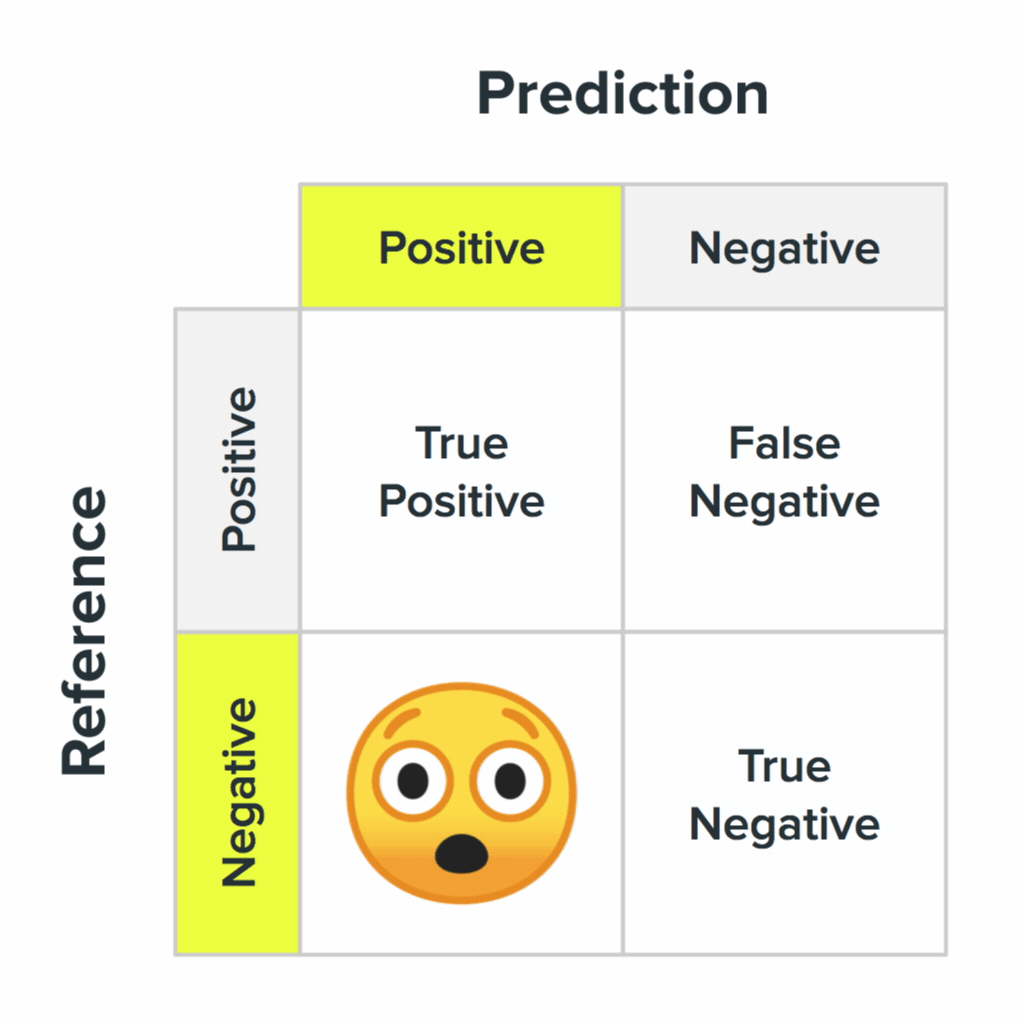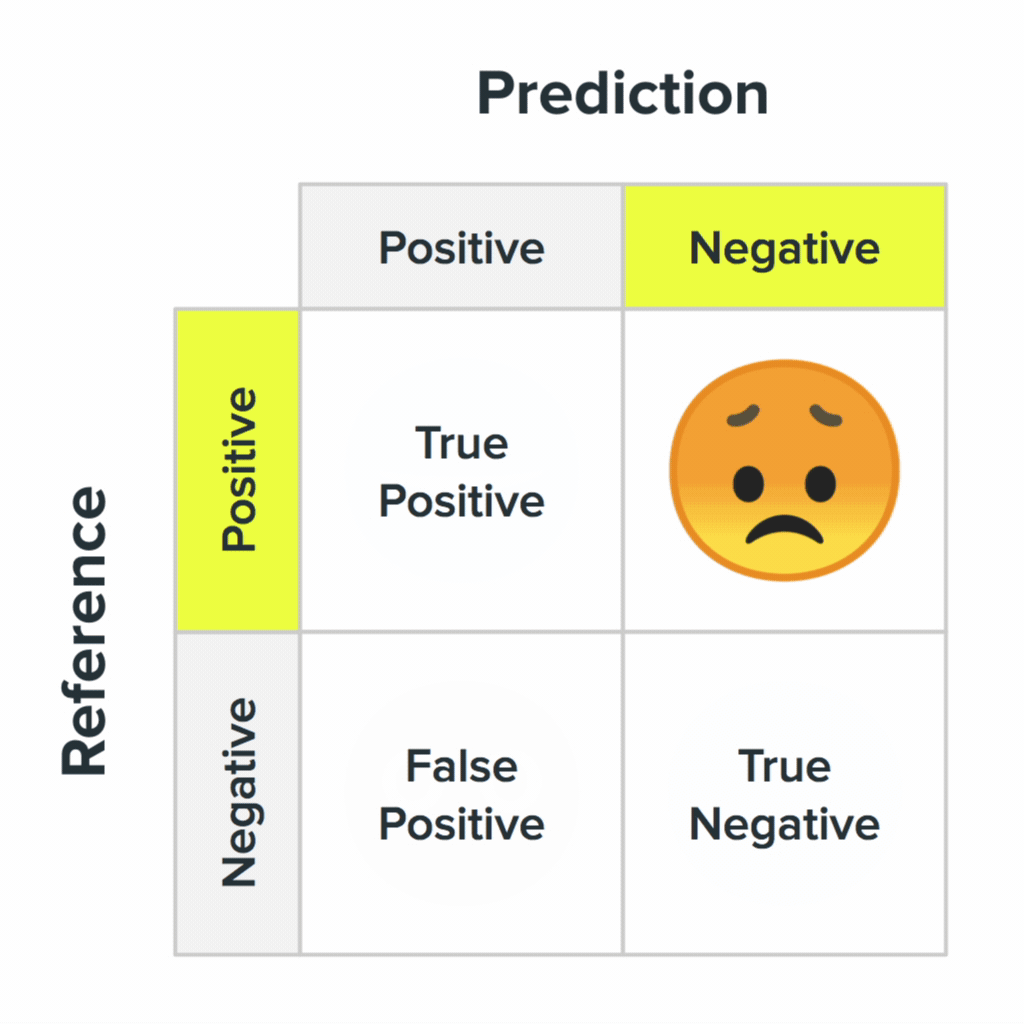
Четыре состояния матрицы неточностей и их вероятные значения для пользователей.
Для ML-системы все ошибки равны, а вот люди воспринимают их по-разному. Возьмём для примера классификатор «человек или тролль?». Случайная классификация человека как тролля — это просто ошибка системы. У нее нет знаний о культурном аспекте и она никого не хочет обидеть. Система не понимает, что люди, которых она определила как троллей, могут оскорбиться сильнее по сравнению с троллями, которые были случайно определены как люди.
Говоря терминами ML, вам нужно найти компромисс между точностью и полнотой системы. Например, когда вы ищете в Google фотографии игровой площадки, вы можете увидеть такие результаты:
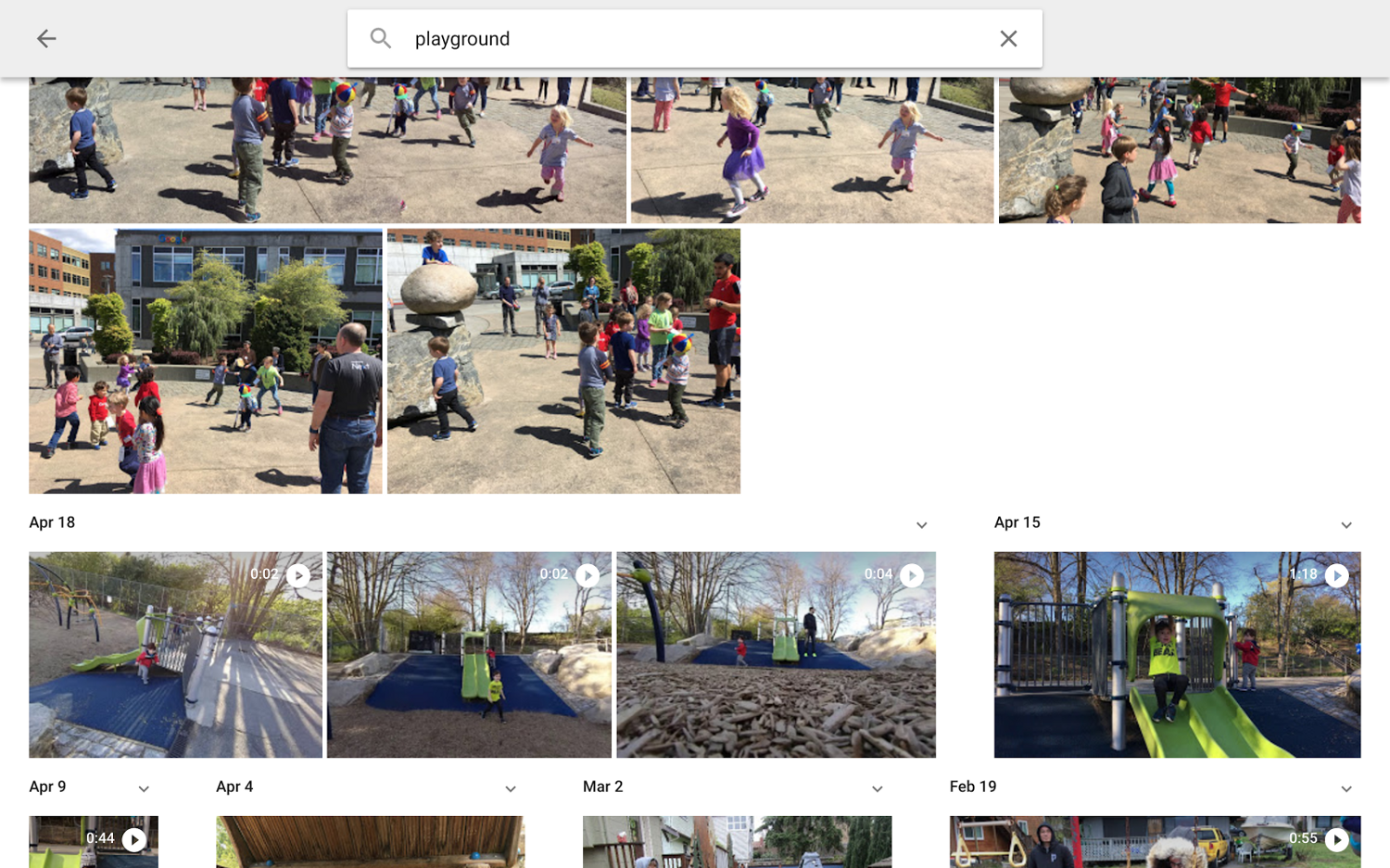 Результаты включают в себя несколько фото играющих детей, но не на игровой площадке. В этом случае полнота приоритетнее точности: лучше добавить несколько фотографий, не совсем точно отвечающих условиям запроса, чем исключить нужную.
Результаты включают в себя несколько фото играющих детей, но не на игровой площадке. В этом случае полнота приоритетнее точности: лучше добавить несколько фотографий, не совсем точно отвечающих условиям запроса, чем исключить нужную.
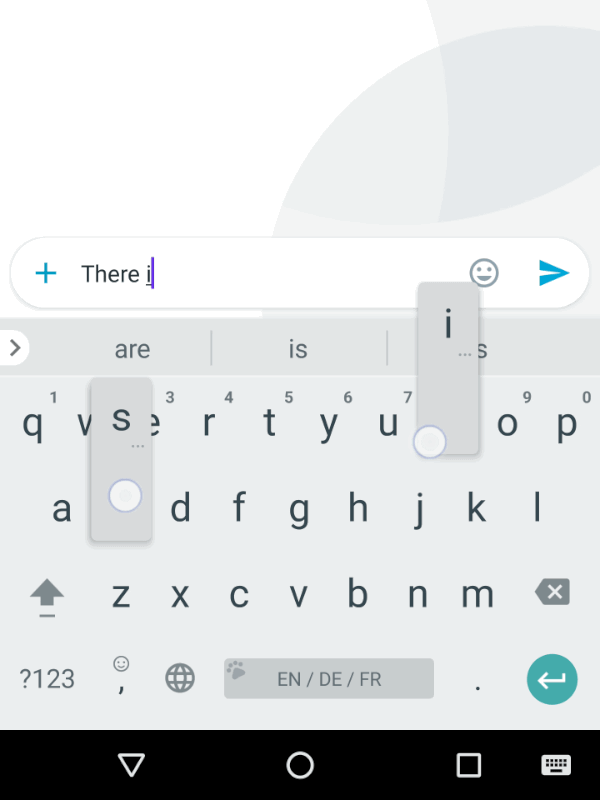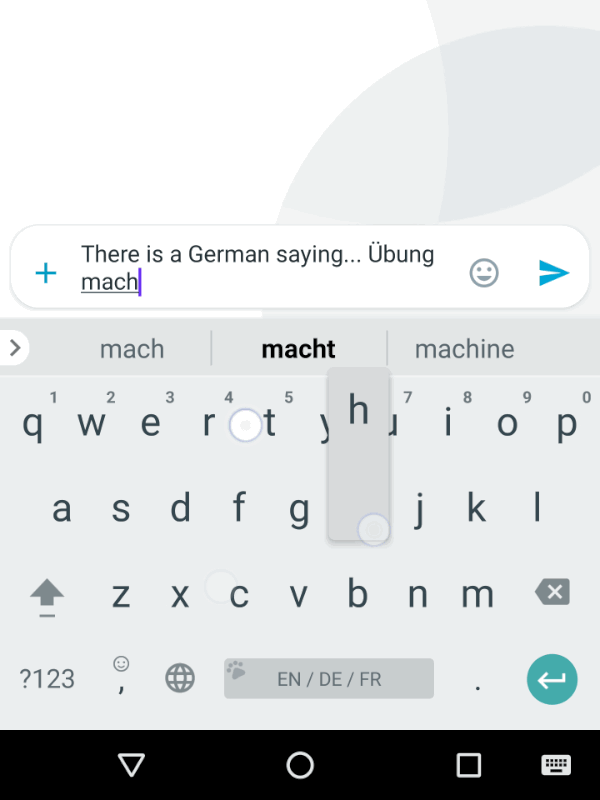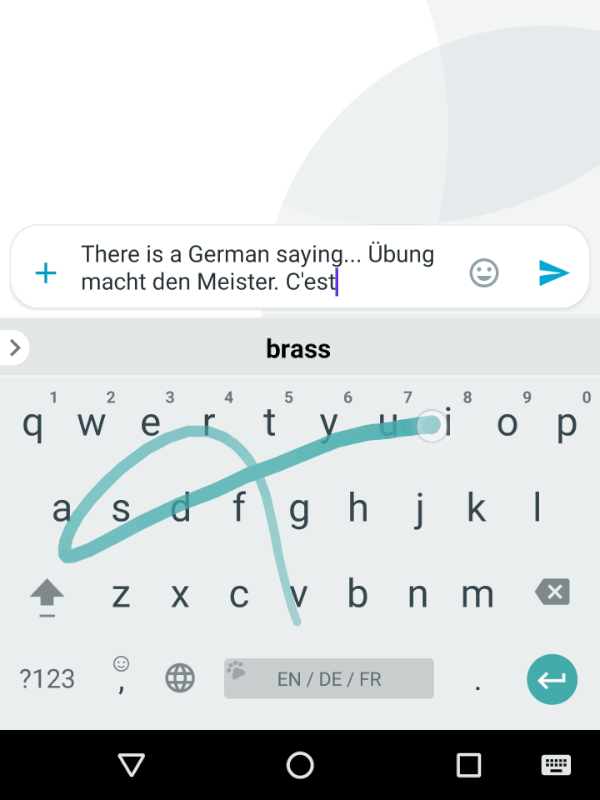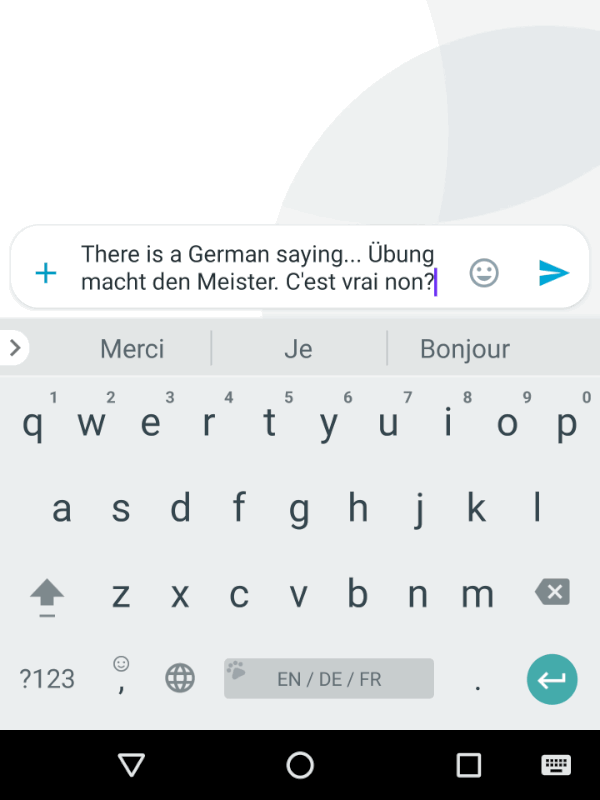
Клавиатура Gboard эволюционирует, чтобы предсказать следующее слово пользователя. Чем больше пользователь использует эту функцию, тем лучше становятся рекомендации.
Когда ML-системы обучаются на существующих наборах данных, они будут адаптироваться к новыми данным такими способами, которые мы не представляем изначально. Поэтому придется корректировать исследование пользователей и стратегию получения обратной связи. Это означает, что в продуктовом цикле нужно заранее планировать:
Вам стоит уделить достаточно времени оценке производительности ML-системы с помощью измерения точности и ошибок по мере увеличения числа пользователей. Также советуем наблюдать за пользователями, чтобы понять, как на них влияют успехи и неудачи системы.
Кроме того, для улучшения работы ML-системы нужно подумать о том, как получать обратную связь от пользователей на протяжении всего жизненного цикла продукта. Шаблоны взаимодействия, облегчающие обратную связь, а также быстрая реакция на нее делают хороший продукт великолепным.
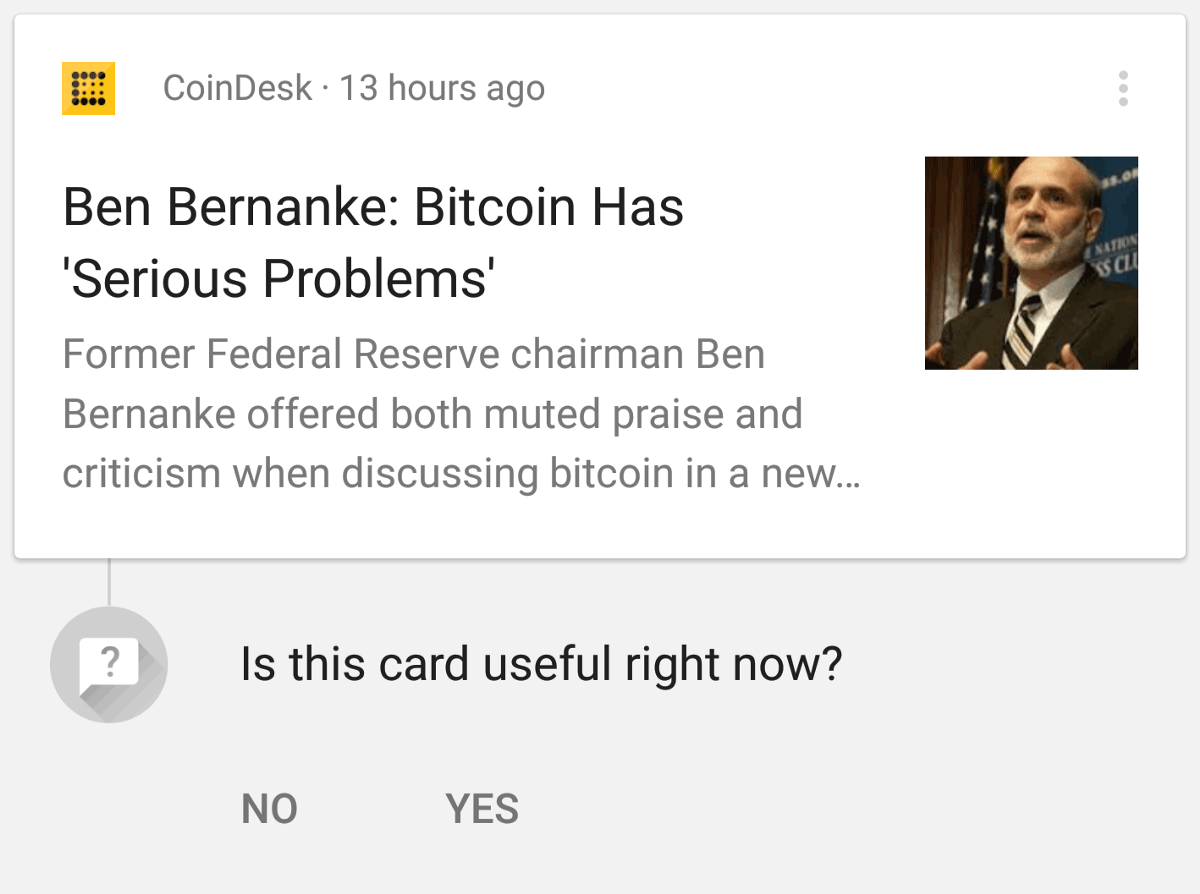
Время от времени приложение Google спрашивает о полезности карточек, чтобы лучше понимать предпочтения.
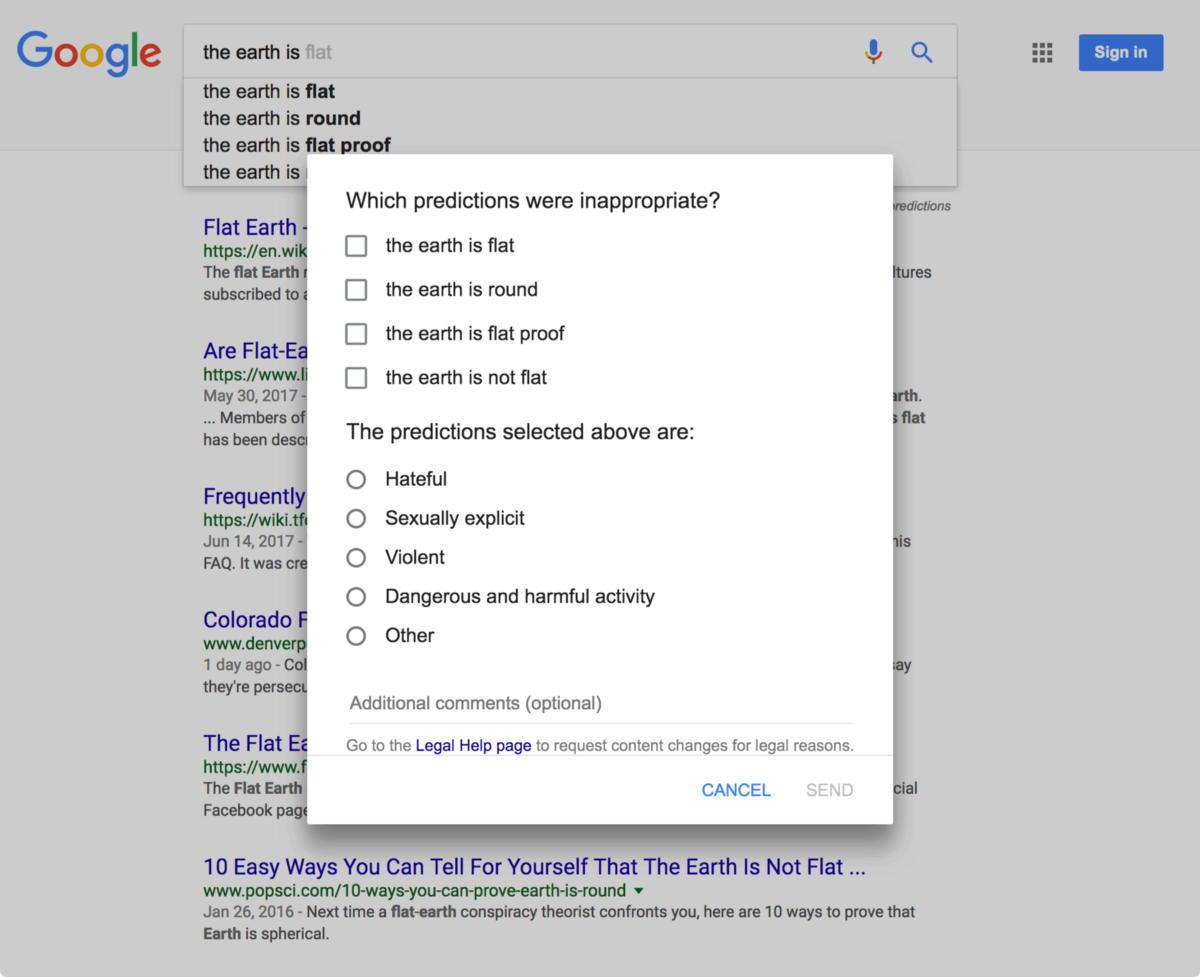
Пользователи могут оставить отзыв об автозаполнении Google Search, в том числе о том, почему предложенные варианты кажутся неуместными.

Вы сможете пройти этот тест?
Трудности возникают, когда дело доходит до субъективных предположений. Например, будут ли полезными пользователю рекомендуемая статья или ответ по электронной почте. Обучение модели занимает много времени, и получение полного набора данных может стоить слишком дорого. Поэтому неправильное использование тегов может оказать огромное влияние на жизнеспособность вашего продукта.
Итак, вот как это делается. Начните с разумных предположений и обсудите их с коллегами. Обычно это выглядит так: «мы предполагаем, что _________ пользователи в ситуациях ________ предпочтут ________, а не ________ ». По результатам обсуждений как можно скорее подготовьте прототип, чтобы начать собирать обратную связь и приступить к разработке продукта. Найдите экспертов, которые станут лучшими преподавателями для вашей ML-системы. Убедитесь, что они компетентны в области, в которой вы будете делать прогнозы. Мы рекомендуем нанять сразу несколько человек или для подстраховки доверить эту роль кому-то из команды. В нашей команде мы называем этих людей «специалистами по контенту».
Вместе с вами они создадут примеры работы ИИ, которые помогут сформировать план для сбора данных и определить теги для начала обучения системы.
Есть много способов для решения любой проблемы ML. Как UX-специалист, вы имеете право на свое видение, но не стоит навязывать его разработчикам. Доверяйте их интуиции и позволяйте экспериментировать, даже если они не решаются тестировать работу системы на пользователях, прежде чем будет готова система оценки.
Машинное обучение — это творческий и выразительный технический процесс. Обучение модели может быть медленным, а инструментов для визуализации еще не так много, поэтому разработчикам часто приходится использовать свою фантазию при настройке алгоритма. Существует методология под названием «активное обучение», где они вручную «настраивают» модель после каждой итерации. Ваша задача состоит в том, чтобы помочь им сделать выбор, ориентированный на пользователя.
 Для лучших результатов организуйте совместную работу разработчиков и продуктовой команды
Для лучших результатов организуйте совместную работу разработчиков и продуктовой команды
Поэтому вдохновляйте их примерами — личными историями, видеороликами, прототипами, результатами пользовательских исследований, крутыми проектами, чтобы показать, каким должен быть хороший UX. Поработайте над их пониманием целей пользовательских исследований. Расскажите им о методологиях, которые используете в работе, чтобы они лучше понимали особенности устройства продукта и цели UX. Чем раньше ваши коллеги усвоят ваши методы, тем надежнее и эффективнее будет процесс разработки.
Для кого: инженеры, программисты, аналитики, маркетологи — все, кто только начинает вникать в технологию Big Data.
Формат занятий: онлайн
? Подробности по ссылке
2. Программа «Data Scientist»
Для кого: специалисты, работающие или собирающиеся работать с Big Data, а также те, кто планирует построить карьеру в области Data Science. Для обучения необходимо владеть как минимум одним из языков программирования (желательно Python) и помнить программу по математике старших классов (а лучше вуза).
Темы курса:
Формат занятий: офлайн, г. Москва, центр Digital October. Преподают специалисты из Yandex Data Factory, Ростелеком, «Сбербанк-Технологии», Microsoft, OWOX, Clever DATA, МТС.
? Подробности по ссылке
3. Программы по UX:
Машинное обучение (Machine Learning или ML) — обширный подраздел искусственного интеллекта, изучающий методы построения алгоритмов, способных обучаться.
Машинное обучение позволяет компьютеру обнаруживать паттерны и взаимосвязи в данных, поэтому это отличный инструмент для создания персонализированного и динамического UX. Область его применения широка: от рекомендательных механизмов Netflix до беспилотных автомобилей. Задача UX-специалиста при работе над проектом под управлением ML — дать пользователю контроль над технологией, а не наоборот.
Машинное обучение постепенно заставляет нас переосмыслить подход к созданию практически всех продуктов. В этой статье мы собрали семь советов о том, как UX-дизайнерам сосредоточиться на нуждах пользователя при работе с ML.
Определите проблемы, которые решает продукт
Многие компании решают использовать машинное обучение, не вполне осознавая, какую проблему должен решить их продукт. Такой подход допустим при проведении исследований или при знакомстве с возможностями новой технологии. Во всех остальных случаях стоит начинать с осмысления потребностей пользователя, иначе есть риск создать мощную систему для решения незначительной или несуществующей проблемы. Поэтому первый пункт достаточно прост: машинное обучение не может определить, какие проблемы и задачи необходимо решить. Вам всё еще придется выполнять эту трудную работу самим. Этнография, контекстные запросы, интервью, опросы, чтение заявок на поддержку клиентов, анализ логов и общение с пользователями помогут выяснить, понимаете ли вы потребности пользователей.
Выясните реальную необходимость в машинном обучении
Не стоит думать, что сам факт использования машинного обучения делает продукт качественным. Существует множество задач, которые можно решать без применения этой сложной технологии. Поэтому ваша цель на данном этапе — определить, есть ли необходимость в машинном обучении, поможет ли оно вашему продукту или только навредит. Если Gmail находит в письме фразы типа «вложение» или «прикреплённые файлы», то он проверяет, не забыли ли вы прикрепить документ. Если вложения нет, появляется напоминание. Здесь хорошо работает эвристический алгоритм. Машинное обучение с этой задачей справилось бы лучше, но стоило бы намного дороже.
Мы разработали набор упражнений и даем его командам, когда они решают использовать машинное обучение. Упражнения помогают понять, какие мысли и ожидания возникают у пользователей при взаимодействии с ML-системой, и какие данные необходимы для её построения.
- Опишите способ, которым человек может сейчас решить вашу задачу?
- Если бы человек выполнял эту задачу, какой отзыв помог бы ему улучшить результат? Ответьте на этот вопрос для четырех фаз матрицы неточностей.
- Если бы человек выполнял эту задачу, что хотел бы получить пользователь?
Ответы на эти вопросы стоит обсудить с командой и положить в основу исследования пользователей. После того как вы закончите работу с упражнениями, скетчами и сторибордами, занесите все идеи в матрицу:
Занесите идеи в эту матрицу. Попросите команду проголосовать за то, какие идеи будут иметь наибольшее влияние на пользователя, и какие больше выиграют от применения ML.
Это позволит выделить наиболее эффективные идеи, и определить, какие из них сильно зависят от машинного обучения, а какие могут лишь немного выиграть от его применения. Идеи, с которых стоит начать, окажутся в правом верхнем углу матрицы. И если вы до сих пор не привлекли разработчиков к обсуждению, то самое время это сделать.
Тестируйте прототип, используя личные данные и эксперимент «Волшебник страны Оз»
Работая с ML-системами, вы неизбежно столкнетесь со сложностями при прототипировании. Невозможно быстро создать реалистичный прототип, если главная задача продукта — анализ уникальных пользовательских данных. Также не получится внести значительные изменения в дизайн, если на момент тестирования в продукт будет встроена система машинного обучения.Тем не менее есть два подхода к исследованиям пользователей, которые могут помочь: используйте личные примеры пользователей и проведите эксперимент «Волшебник страны Оз».
При проведении пользовательских исследований с первыми прототипами, попросите участников поделиться некоторыми личными данными — например, фотографиями, списками контактов, рекомендациями музыки или фильмов, которые они получают. Вам нужно обязательно проинформировать участников, как эти данные будут использоваться во время тестирования и когда они будут удалены. С помощью этих примеров вы сможете сымитировать правильные и неправильные ответы системы. Например, вы можете имитировать работу системы, которая дает рекомендации фильмов пользователю. Обратите внимание, как пользователь объяснит, почему система выдала именно этот результат. Этот метод поможет вам больше, чем использование фиктивных примеров или описания концепта продукта.
Второй подход, который хорошо работает для тестирования еще не созданных продуктов под управлением ML-системы — это исследование «Волшебник страны Оз».
Интерфейсы чата — одна из самых простых ML-систем, которую можно протестировать с помощью подхода «Волшебник страны Оз». Для этого тестирования попросите члена вашей команды имитировать действия искусственного интеллекта в ответ на действия пользователя.
Важное условие при проведении исследования — пользователь должен думать, что он взаимодействует с автономной системой. Но на самом деле его экран контролирует человек, хорошо знакомый с продуктом (как правило, это член команды). Его задача — имитация действий ML-системы: ответы чат-бота, предложение контактов для звонка, рекомендация фильмов. Когда пользователь взаимодействует с тем, что он воспринимает как искусственный интеллект, он формирует представления о системе и корректирует поведение в соответствии с ними. Наблюдение за этим процессом крайне важно в нашей работе.
Взвесьте затраты на ложнопозитивные и ложнонегативные ответы
Ваша система будет ошибаться. Важно понять, как выглядят эти ошибки в глазах пользователей. Во втором пункте мы упоминали матрицу неточности: эта ключевая концепция в машинном обучении описывает процесс, когда система отвечает правильно или ошибается. Четыре состояния матрицы неточностей и их вероятные значения для пользователей.
Для ML-системы все ошибки равны, а вот люди воспринимают их по-разному. Возьмём для примера классификатор «человек или тролль?». Случайная классификация человека как тролля — это просто ошибка системы. У нее нет знаний о культурном аспекте и она никого не хочет обидеть. Система не понимает, что люди, которых она определила как троллей, могут оскорбиться сильнее по сравнению с троллями, которые были случайно определены как люди.
Говоря терминами ML, вам нужно найти компромисс между точностью и полнотой системы. Например, когда вы ищете в Google фотографии игровой площадки, вы можете увидеть такие результаты:
Результаты включают в себя несколько фото играющих детей, но не на игровой площадке. В этом случае полнота приоритетнее точности: лучше добавить несколько фотографий, не совсем точно отвечающих условиям запроса, чем исключить нужную. Планируйте адаптацию системы
Главная ценность использования ML-систем в том, что они меняются сами и меняют представление пользователя о продукте. Чем больше человек взаимодействует с системой, тем точнее будут результаты, которые он получит. Помогите своим пользователям разобраться и стимулируйте их на обратную связь. Это будет полезно как для них, так и для продукта. Клавиатура Gboard эволюционирует, чтобы предсказать следующее слово пользователя. Чем больше пользователь использует эту функцию, тем лучше становятся рекомендации.
Когда ML-системы обучаются на существующих наборах данных, они будут адаптироваться к новыми данным такими способами, которые мы не представляем изначально. Поэтому придется корректировать исследование пользователей и стратегию получения обратной связи. Это означает, что в продуктовом цикле нужно заранее планировать:
- анализ отношения пользователя к продукту;
- долгосрочное исследование;
- исследований с широким охватом.
Вам стоит уделить достаточно времени оценке производительности ML-системы с помощью измерения точности и ошибок по мере увеличения числа пользователей. Также советуем наблюдать за пользователями, чтобы понять, как на них влияют успехи и неудачи системы.
Кроме того, для улучшения работы ML-системы нужно подумать о том, как получать обратную связь от пользователей на протяжении всего жизненного цикла продукта. Шаблоны взаимодействия, облегчающие обратную связь, а также быстрая реакция на нее делают хороший продукт великолепным.
Время от времени приложение Google спрашивает о полезности карточек, чтобы лучше понимать предпочтения.
Пользователи могут оставить отзыв об автозаполнении Google Search, в том числе о том, почему предложенные варианты кажутся неуместными.
Обучайте свой алгоритм, используя правильные теги
Теги — важный аспект машинного обучения. Есть специалисты, которые пересматривают тонны контента и расставляют соответствующие теги: например, «есть ли кошка на этой фотографии?» Достаточное количество фотографий с метками «кошка» или «не кошка» — это готовый набор данных для обучения модели, которая будет распознавать кошек. Точнее, эта модель будет делать предположение с некоторой вероятностью, есть ли кошка на фотографии, которую она никогда не видела раньше. Вы сможете пройти этот тест?
Трудности возникают, когда дело доходит до субъективных предположений. Например, будут ли полезными пользователю рекомендуемая статья или ответ по электронной почте. Обучение модели занимает много времени, и получение полного набора данных может стоить слишком дорого. Поэтому неправильное использование тегов может оказать огромное влияние на жизнеспособность вашего продукта.
Итак, вот как это делается. Начните с разумных предположений и обсудите их с коллегами. Обычно это выглядит так: «мы предполагаем, что _________ пользователи в ситуациях ________ предпочтут ________, а не ________ ». По результатам обсуждений как можно скорее подготовьте прототип, чтобы начать собирать обратную связь и приступить к разработке продукта. Найдите экспертов, которые станут лучшими преподавателями для вашей ML-системы. Убедитесь, что они компетентны в области, в которой вы будете делать прогнозы. Мы рекомендуем нанять сразу несколько человек или для подстраховки доверить эту роль кому-то из команды. В нашей команде мы называем этих людей «специалистами по контенту».
Вместе с вами они создадут примеры работы ИИ, которые помогут сформировать план для сбора данных и определить теги для начала обучения системы.
Расширьте UX-команду
Подумайте о худшем замечании, которое вы получали от начальства. А теперь представьте, что кто-то стоит у вас за спиной и комментирует каждое ваше действие. Держите этот образ в уме и убедитесь, что вы не обращаетесь так с вашими разработчиками.Есть много способов для решения любой проблемы ML. Как UX-специалист, вы имеете право на свое видение, но не стоит навязывать его разработчикам. Доверяйте их интуиции и позволяйте экспериментировать, даже если они не решаются тестировать работу системы на пользователях, прежде чем будет готова система оценки.
Машинное обучение — это творческий и выразительный технический процесс. Обучение модели может быть медленным, а инструментов для визуализации еще не так много, поэтому разработчикам часто приходится использовать свою фантазию при настройке алгоритма. Существует методология под названием «активное обучение», где они вручную «настраивают» модель после каждой итерации. Ваша задача состоит в том, чтобы помочь им сделать выбор, ориентированный на пользователя.
Для лучших результатов организуйте совместную работу разработчиков и продуктовой командыПоэтому вдохновляйте их примерами — личными историями, видеороликами, прототипами, результатами пользовательских исследований, крутыми проектами, чтобы показать, каким должен быть хороший UX. Поработайте над их пониманием целей пользовательских исследований. Расскажите им о методологиях, которые используете в работе, чтобы они лучше понимали особенности устройства продукта и цели UX. Чем раньше ваши коллеги усвоят ваши методы, тем надежнее и эффективнее будет процесс разработки.
Заключение
Это семь советов, которые мы считаем важными в Google. Надеемся, что они пригодятся, если при разработке продукта вы используете машинное обучение. Не забывайте, что эта работа требует ориентироваться на людей, находить уникальную ценность для них и делать каждый опыт взаимодействия с продуктом поистине восхитительным.О курсах Нетологии
1. Программа «Big Data: основы работы с большими массивами данных»Для кого: инженеры, программисты, аналитики, маркетологи — все, кто только начинает вникать в технологию Big Data.
- введение в историю и основы технологии;
- способы сбора больших данных;
- типы данных;
- основные и продвинутые методы анализа больших данных;
- основы программирования, архитектуры хранения и обработки для работы с большими массивами данных.
Формат занятий: онлайн
? Подробности по ссылке
2. Программа «Data Scientist»
Для кого: специалисты, работающие или собирающиеся работать с Big Data, а также те, кто планирует построить карьеру в области Data Science. Для обучения необходимо владеть как минимум одним из языков программирования (желательно Python) и помнить программу по математике старших классов (а лучше вуза).
Темы курса:
- экспресс-обучение основным инструментам, Hadoop, кластерные вычисления;
- деревья решений, метод k-ближайших соседей, логистическая регрессия, кластеризация;
- уменьшение размерности данных, методы декомпозиции, спрямляющие пространства;
- введение в рекомендательные системы;
- распознавание изображений, машинное зрение, нейросети;
- обработка текста, дистрибутивная семантика, чатботы;
- временные ряды, модели ARMA/ARIMA, сложные модели прогнозирования.
Формат занятий: офлайн, г. Москва, центр Digital October. Преподают специалисты из Yandex Data Factory, Ростелеком, «Сбербанк-Технологии», Microsoft, OWOX, Clever DATA, МТС.
? Подробности по ссылке
3. Программы по UX:
Телеграм: t.me/ainewsline
Источник: habrahabr.ru