Пишем свою нейросеть: пошаговое руководство
МЕНЮ
Искусственный интеллект
Поиск
Регистрация на сайте
Помощь проекту
ТЕМЫ
Новости ИИ
Голосовой помощник
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Слежка за людьми
Угроза ИИ
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Распознавание лиц
Распознавание образов
Распознавание речи
Техническое зрение
Чат-боты
Авторизация
2017-07-14 21:00

Отличный гайд про нейросеть от теории к практике. Вы узнаете из каких элементов состоит ИНС, как она работает и как ее создать самому.
Если вы в поисках пособия по искусственным нейронным сетям (ИНС), то, возможно, у вас уже имеются некоторые предположения относительно того, что это такое. Но знали ли вы, что нейронные сети — основа новой и интересной области глубинного обучения? Глубинное обучение — область машинного обучения, в наше время помогло сделать большой прорыв во многих областях, начиная с игры в Го и Покер с живыми игроками, и заканчивая беспилотными автомобилями. Но, прежде всего, глубинное обучение требует знаний о работе нейронных сетей.

В этой статье будут представлены некоторые понятия, а также немного кода и математики, с помощью которых вы сможете построить и понять простые нейронные сети. Для ознакомления с материалом нужно иметь базовые знания о матрицах и дифференциалах. Код будет написан на языке программирования Python с использованием библиотеки numpy. Вы построите ИНС, используя Python, которая с высокой точностью классифицировать числа на картинках.
1 Что такое искусственная нейросеть?
Искусственные нейросеть (ИНС) — это программная реализация нейронных структур нашего мозга. Мы не будем обсуждать сложную биологию нашей головы, достаточно знать, что мозг содержит нейроны, которые являются своего рода органическими переключателями. Они могут изменять тип передаваемых сигналов в зависимости от электрических или химических сигналов, которые в них передаются. Нейросеть в человеческом мозге — огромная взаимосвязанная система нейронов, где сигнал, передаваемый одним нейроном, может передаваться в тысячи других нейронов. Обучение происходит через повторную активацию некоторых нейронных соединений. Из-за этого увеличивается вероятность вывода нужного результата при соответствующей входной информации (сигналах). Такой вид обучения использует обратную связь — при правильном результате нейронные связи, которые выводят его, становятся более плотными.
Искусственные нейронные сети имитируют поведение мозга в простом виде. Они могут быть обучены контролируемым и неконтролируемым путями. В контролируемой ИНС, сеть обучается путем передачи соответствующей входной информации и примеров исходной информации. Например, спам-фильтр в электронном почтовом ящике: входной информацией может быть список слов, которые обычно содержатся в спам-сообщениях, а исходной информацией — классификация для уведомления (спам, не спам). Такой вид обучения добавляет веса связям ИНС, но это будет рассмотрено позже.
Неконтролируемое обучение в ИНС пытается «заставить» ИНС «понять» структуру передаваемой входной информации «самостоятельно». Мы не будем рассматривать это в данном посте.
2 Структура ИНС
2.1 Искусственный нейрон
Биологический нейрон имитируется в ИНС через активационную функцию. В задачах классификации (например определение спам-сообщений) активационная функция должна иметь характеристику «включателя». Иными словами, если вход больше, чем некоторое значение, то выход должен изменять состояние, например с 0 на 1 или -1 на 1 Это имитирует «включение» биологического нейрона. В качестве активационной функции обычно используют сигмоидальную функцию:
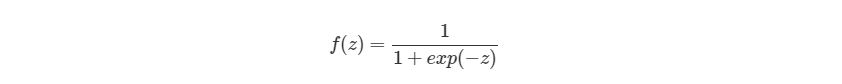
Которая выглядит следующим образом:
1 2 3 4 5 6 7 8 9 10 | import matplotlib.pylab asplt import numpy asnp x=np.arange(-8,8,0.1) f=1/(1+np.exp(-x)) plt.plot(x,f) plt.xlabel('x') plt.ylabel('f(x)') plt.show() |
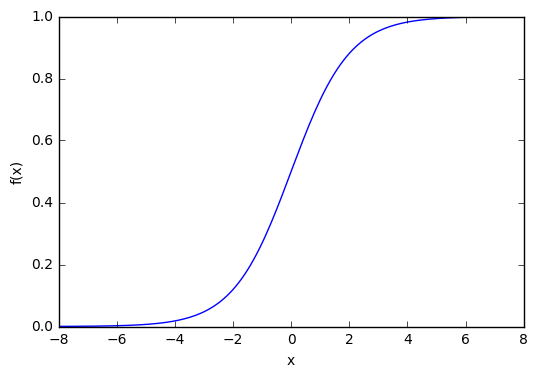
Из графика можно увидеть, что функция «активационная» — она растет с 0 до 1 с каждым увеличением значения х. Сигмоидальная функция является гладкой и непрерывной. Это означает, что функция имеет производную, что в свою очередь является очень важным фактором для обучения алгоритма.
2.2 Узлы
Как было упомянуто ранее, биологические нейроны иерархически соединены в сети, где выход одних нейронов является входом для других нейронов. Мы можем представить такие сети в виде соединенных слоев с узлами. Каждый узел принимает взвешенный вход, активирует активационную функцию для суммы входов и генерирует выход.
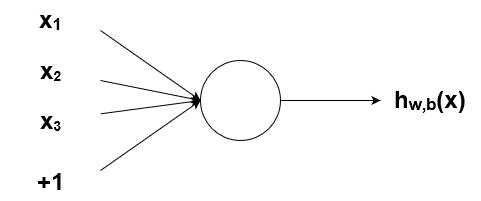
Круг на картинке изображает узел. Узел является «местоположением» активационной функции, он принимает взвешенные входы, складывает их, а затем вводит их в активационную функцию. Вывод активационной функции представлен через h. Примечание: в некоторых источниках узел также называют перцептроном.
Что такое «вес»? По весу берутся числа (не бинарные), которые затем умножаются на входе и суммируются в узле. Иными словами, взвешенный вход в узел имеет вид:
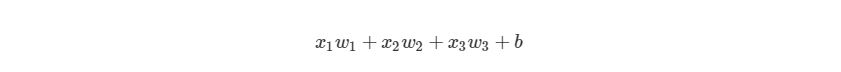
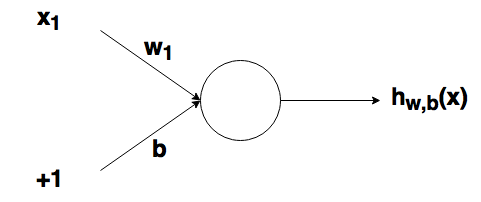
где wi— числовые значения веса ( b мы будем обсудим позже). Весы нам нужны, они являются значениями, которые будут меняться в течение процесса обучения. b является весом элемента смещения на 1, включение веса b делает узел гибким. Проще это понять на примере.
2.3 Смещение
Рассмотрим простой узел, в котором есть по одному входу и выходу:

Ввод для активационной функции в этом узле просто x1w1. На что влияет изменение в w1 в этой простой сети?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | w1=0.5 w2=1.0 w3=2.0 l1='w = 0.5' l2='w = 1.0' l3='w = 2.0' forw,lin[(w1,l1),(w2,l2),(w3,l3)]: f=1/(1+np.exp(-x *w)) plt.plot(x,f,label=l) plt.xlabel('x') plt.ylabel('h_w(x)') plt.legend(loc=2) plt.show() |
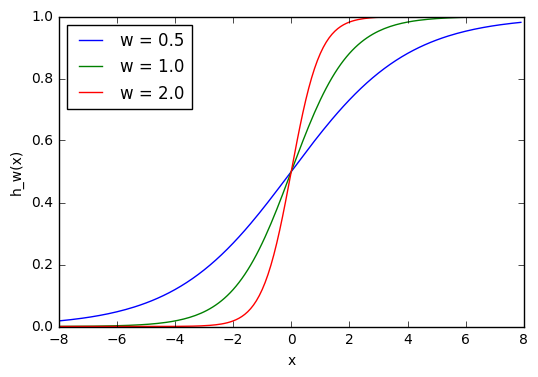
Здесь мы можем видеть, что при изменении веса изменяется также уровень наклона графика активационной функции. Это полезно, если мы моделируем различные плотности взаимосвязей между входами и выходами. Но что делать, если мы хотим, чтобы выход изменялся только при х более 1? Для этого нам нужно смещение. Рассмотрим такую сеть со смещением на входе:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | w=5.0 b1=-8.0 b2=0.0 b3=8.0 l1='b = -8.0' l2='b = 0.0' l3='b = 8.0' forb,lin[(b1,l1),(b2,l2),(b3,l3)]: f=1/(1+np.exp(-(x *w+b))) plt.plot(x,f,label=l) plt.xlabel('x') plt.ylabel('h_wb(x)') plt.legend(loc=2) plt.show() |
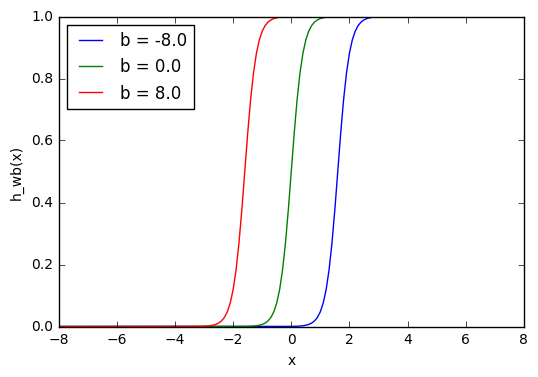
Из графика можно увидеть, что меняя «вес» смещения b, мы можем изменять время запуска узла. Смещение очень важно в случаях, когда нужно имитировать условные отношения.
2.4 Составленная структура
Выше было объяснено, как работает соответствующий узел / нейрон / перцептрон. Но, как вы знаете, в полной нейронной сети находится много таких взаимосвязанных между собой узлов. Структуры таких сетей могут принимать мириады различных форм, но самая распространенная состоит из входного слоя, скрытого слоя и выходного слоя. Пример такой структуры приведены ниже:
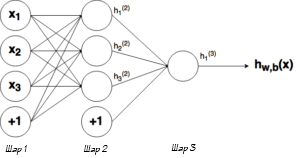
Ну рисунке выше можно увидеть три слоя сети — Слой 1 является входным слоем, где сеть принимает внешние входные данные. Слой 2 называют скрытым слоем, этот слой не является частью ни входа, ни выхода. Примечание: нейронные сети могут иметь несколько скрытых слоев, в данном примере для примера был показан лишь один. И наконец, Слой 3 является исходным слоем. Вы можете заметить, что между Шаром 1 (Ш1) и Шаром 2 (Ш2) существует много связей. Каждый узел в Ш1 имеет связь со всеми узлами в Ш2, при этом от каждого узла в Ш2 идет по одной связи к единому выходному узлу в Ш3. Каждая из этих связей должна иметь соответствующий вес.
2.5 Обозначение
Вся математика, приведенная выше, требует очень точной нотации. Нотация, которая используется здесь, используется и в руководстве по глубинному обучению от Стэнфордского Университета. В следующих уравнениях вес соответствующего связи будет обозначаться как w ij(l), где i — номер узла в слое l+1, а j- номер узла в слое l. Например, вес связи между узлом 1 в слое 1 и узлом 2 в слое 2 будет обозначаться как w 21(l). Непонятно, почему индексы 2-1 означают связь 1-2? Такая нотация более понятна, если добавить смещения.
Из графика выше видно, что смещение 1 связано со всеми узлами в соседнем слое. Смещение в Ш1 имеет связь со всеми узлами в Ш2. Так как смещение не является настоящим узлом с активационной функцией, оно не имеет и входов (его входное значение всегда равно константе). Вес связи между смещением и узлом будем обозначать через bi(l), где i- номер узла в слое l+1, так же, как в w ij(l). К примеру с w 21(l) вес между смещением в Ш1 и вторым узлом в Ш2 будет иметь обозначение b2(1).
Помните, что эти значения -w ij(l)и bi(l) — будут меняться в течение процесса обучения ИНС.
Обозначение связи с исходным узлом будет выглядеть следующим образом: hjl, где j- номер узла в слое l. Тогда в предыдущем примере, связью с исходным узлом является h1(2).
Теперь давайте рассмотрим, как рассчитывать выход сети, когда нам известны вес и вход. Процесс нахождения выхода в нейронной сети называется процессом прямого распространения.
3 Процесс прямого распространения
Чтобы продемонстрировать, как находить выход, имея уже известный вход, в нейронных сетях, начнем с предыдущего примера с тремя слоями. Ниже такая система представлена в виде системы уравнений:
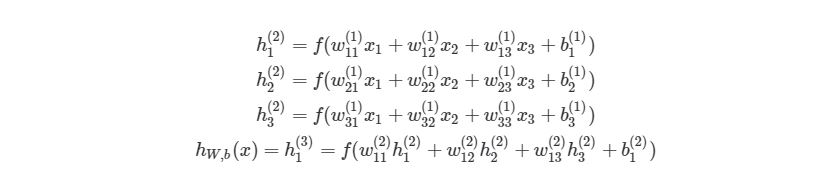
, где f(?) — активационная функция узла, в нашем случае сигмоидальная функция. В первой строке h1(2)— выход первого узла во втором слое, его входами соответственно являются w11(1)x1(1), w12(1)x2(1),w13(1)x3(1) и b1(1). Эти входы было сложены, а затем переданы в активационную функцию для расчета выхода первого узла. С двумя следующими узлами аналогично.
Последняя строка рассчитывает выход единого узла в последнем третьем слое, он является конечной исходной точкой в нейронной сети. В нем вместо взвешенных входных переменных (x1,x2,x3)берутся взвешенные выходы узлов с другой слоя (h1(2),h2(2),h3(2))и смещения. Такая система уравнений также хорошо показывает иерархическую структуру нейронной сети.
3.1 Пример прямого распространения
Приведем простой пример первого вывода нейронной сети языке Python . Обратите внимание, веса w11(1),w12(1),… между Ш1 и Ш2 идеально могут быть представлены в матрице:
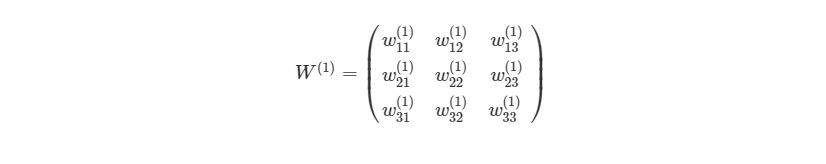
Представим эту матрицу через массивы библиотеки numpy.
1 2 3 4 5 6 7 8 | import numpy asnp w1=np.array([ [0.2,0.2,0.2], [0.4,0.4,0.4], [0.6,0.6,0.6] ]) |
Мы просто присвоили некоторые рандомные числовые значения весу каждой связи с Ш1. Аналогично можно сделать и с Ш2:
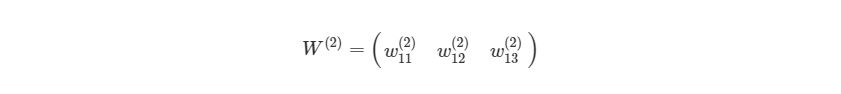
1 2 3 4 | w2=np.zeros((1,3)) w2[,:]=np.array([0.5,0.5,0.5]) |
Мы можем присвоить некоторые значения весу смещения в Ш1 и Ш2:
1 2 3 4 | b1=np.array([0.8,0.8,0.8]) b2=np.array([0.2]) |
Наконец, перед написанием основной программы для расчета выхода нейронной сети, напишем отдельную функцию для активационной функции:
1 2 3 4 | deff(x): return1/(1+np.exp(-x)) |
3.2 Первая попытка реализовать процесс прямого распространения
Приведем простой способ расчета выхода нейронной сети, используя вложенные циклы в Python. Позже мы быстро рассмотрим более эффективные способы.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | def simple_looped_nn_calc(n_layers,x,w,b): forlinrange(n_layers-1):#Формируется входной массив - перемножения весов в каждом слое# Если первый слой, то входной массив равен вектору х# Если слой не первый, вход для текущего слоя равен# выходу предыдущего ifl==: node_in=x else: node_in=h#формирует выходной массив для узлов в слое l + 1 h=np.zeros((w[l].shape[],))#проходит по строкам массива весов foriinrange(w[l].shape[]):#считает сумму внутри активационной функции f_sum=#проходит по столбцам массива весов forjinrange(w[l].shape[1]): f_sum+=w[l][i][j]*node_in[j]#добавляет смещение f_sum+=b[l][i] #использует активационную функцию для расчета #i - того выхода, в данном случае h1, h2, h3 h[i]=f(f_sum) returnh |
Данная функция принимает в качестве входа номер слоя в нейронной сети, х — входной массив / вектор:
1 2 3 4 5 | w=[w1,w2] b=[b1,b2]#Рандомный входной вектор x x=[1.5,2.0,3.0] |
Функция сначала проверяет, чем является входной массив для соответствующего слоя с узлами / весами. Если рассматривается первый слой, то входом для второго слоя является входной массив xx, Умноженный на соответствующие веса. Если слой не первый, то входом для последующего будет выход предыдущего.
Вызов функции:
1 2 3 | simple_looped_nn_calc(3,x,w,b) |
возвращает результат 0.8354. Можно проверить правильность, вставив те же значения в систему уравнений:

3.3 Более эффективная реализация
Использование циклов — не самый эффективный способ расчета прямого распространения на языке Python , потому что циклы в этом языке программирования работают довольно медленно. Мы кратко рассмотрим лучшие решения. Также можно будет сравнить работу алгоритмов, используя функцию в IPython:
1 2 3 | %timeit simple_looped_nn_calc(3,x,w,b) |
В данном случае процесс прямого распространения с циклами занимает около 40 микросекунд. Это довольно быстро, но не для больших нейронных сетей с > 100 узлами на каждом слое, особенно при их обучении. Если мы запустим этот алгоритм на нейронной сети с четырьмя слоями, то получим результат 70 микросекунд. Эта разница является достаточно значительной.
3.4 Векторизация в нейронных сетях
Можно более компактно написать предыдущие уравнения, тем самым найти результат эффективнее. Сначала добавим еще одну переменную zi(l), которая является суммой входа в узел i слоя l, Включая смещение. Тогда для первого узла в Ш2, z будет равна:
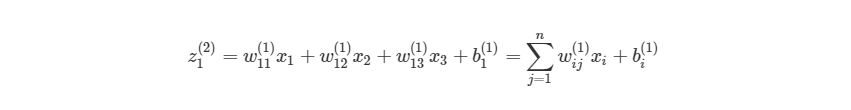
, где n- количество узлов в Ш1. Используя это обозначение, систему уравнений можно сократить:
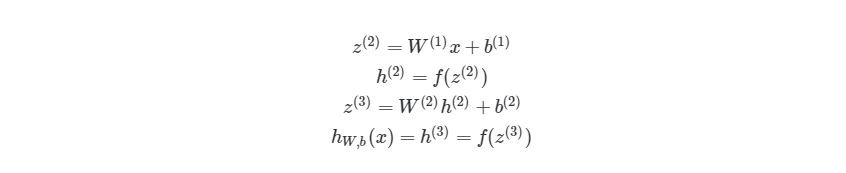
Обратите внимание на W, что означает матричную форму представления весов. Помните, что теперь все элементы в уравнении сверху являются матрицами / векторами. Но на этом упрощение не заканчивается. Данные уравнения можно свести к еще более краткому виду:
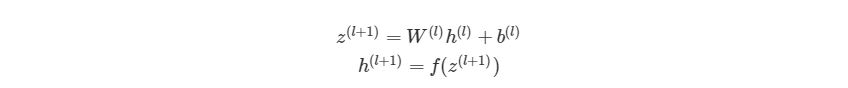
Так выглядит общая форма процесса прямого распространения, выход слоя l становится входом в слой l+1. Мы знаем, что h(1) является входным слоем x, а h(nl)(где nl- номер слоя в сети) является исходным слоем. Мы также не стали использовать индексы i и j-за того, что можно просто перемножить матрицы — это даст нам тот же результат. Поэтому данный процесс и называется «векторизацией». Этот метод имеет ряд плюсов. Во-первых, код его реализации выглядит менее запутанным. Во-вторых, используются свойства по линейной алгебре вместо циклов, что делает работу программы быстрее. С numpy можно легко сделать такие подсчеты. В следующей части быстро повторим операции над матрицами, для тех, кто их немного подзабыл.
3.5 Умножение матриц
Распишем z(l+1)=W(l)h(l)+b(l) на выражение из матрицы и векторов входного слоя ( h(l)=x):

Для тех, кто не знает или забыл, как перемножаются матрицы. Когда матрица весов умножается на вектор, каждый элемент в строке матрицы весов умножается на каждый элемент в столбце вектора, после этого все произведения суммируются и создается новый вектор (3х1). После перемножения матрицы на вектор, добавляются элементы из вектора смещения и получается конечный результат.
Каждая строка полученного вектора соответствует аргументу активационной функции в оригинальной НЕ матричной системе уравнений выше. Это означает, что в Python мы можем реализовать все, не используя медленные циклы. К счастью, библиотека numpy дает возможность сделать это достаточно быстро, благодаря функциям-операторам над матрицами. Рассмотрим код простой и быстрой версии функции simple_looped_nn_calc:
1 2 3 4 5 6 7 8 9 10 11 | def matrix_feed_forward_calc(n_layers,x,w,b): forlinrange(n_layers-1): ifl==: node_in=x else: node_in=h z=w[l].dot(node_in)+b[l] h=f(z) returnh |
Обратите внимание на строку 7, в которой происходит перемножение матрицы и вектора. Если вместо функции умножения a.dot (b) вы используете символ *, то получится нечто похожее на поэлементное умножение вместо настоящего произведения матриц.
Если сравнить время работы этой функции с предыдущей на простой сети с четырьмя слоями, то мы получим результат лишь на 24 микросекунды меньше. Но если увеличить количество узлов в каждом слое до 100-100-50-10, то мы получим гораздо большую разницу. Функция с циклами в этом случае дает результат 41 миллисекунду, когда у функции с векторизацией это занимает лишь 84 микросекунды. Также существуют еще более эффективные реализации операций над матрицами, которые используют пакеты глубинного обучения, такие как TensorFlow и Theano.
На этом все о процессе прямого распространения в нейронных сетях. В следующих разделах мы поговорим о способах обучения нейронных сетей, используя градиентный спуск и обратное распространение.
4 Градиентный спуск и оптимизация
Расчеты значений весов, которые соединяют слои в сети, это как раз то, что мы называем обучением системы. В контролируемом обучении идея заключается в том, чтобы уменьшить погрешность между входом и нужным выходом. Если у нас есть нейросеть с одним выходным слоем и некоторой вход xx и мы хотим, чтобы на выходе было число 2, но сеть выдает 5, то нахождение погрешности выглядит как abs(2-5)=3. Говоря языком математики, мы нашли норму ошибки L1(Это будет рассмотрено позже).
Смысл контролируемого обучения в том, что предоставляется много пар вход-выход уже известных данных и нужно менять значения весов, основываясь на этих примерах, чтобы значение ошибки стало минимальным. Эти пары входа-выхода обозначаются как (x(1),y(1)),…,(x(m),y(m)), где m является количеством экземпляров для обучения. Каждое значение входа или выхода может представлять собой вектор значений, например x(1) не обязательно только одно значение, оно может содержать N-размерный набор значений. Предположим, что мы обучаем нейронную сеть выявлению спам-сообщений — в таком случае x(1) может представлять собой количество соответствующих слов, которые встречаются в сообщении:
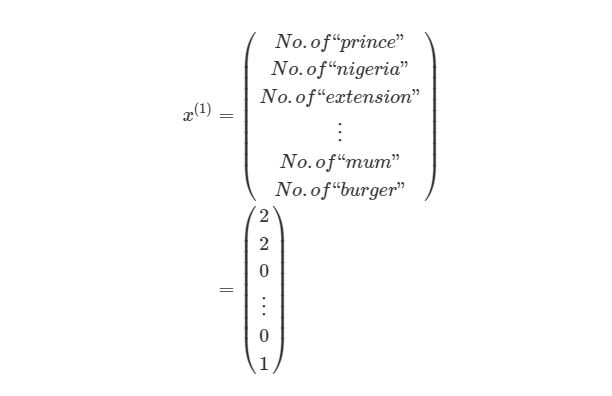
y(1) в этом случае может представлять собой единое скалярное значение, например, 1 или 0, обозначающий, было сообщение спамом или нет. В других приложениях это также может быть вектор с K измерениями. Например, мы имеем вход xx, Который является вектором черно-белых пикселей, считанных с фотографии. При этом y может быть вектором с 26 элементами со значениями 1 или 0, обозначающие, какая буква была изображена на фото, например (1,0,…,0)для буквы а, (0,1,…,0) для буквы б и т.д.
В обучении сети, используя (x,y), целью является улучшение нахождения правильного y при известном x. Это делается через изменение значений весов, чтобы минимизировать погрешность. Как тогда менять их значение? Для этого нам и понадобится градиентный спуск. Рассмотрим следующий график:
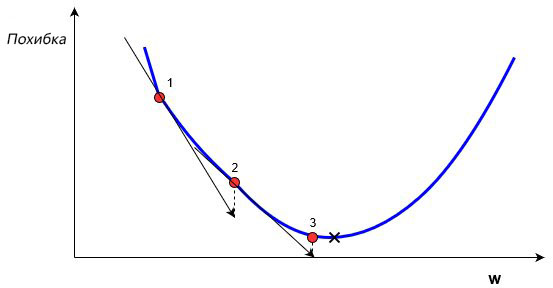
На этом графике изображено погрешность, зависящую от скалярного значения веса, w. Минимально возможная погрешность обозначена черным крестиком, но мы не знаем какое именно значение w дает нам это минимальное значение. Подсчет начинается с рандомного значения переменной w, которая дает погрешность, обозначенную красной точкой под номером «1» на кривой. Нам нужно изменить w таким образом, чтобы достичь минимальной погрешности, черного крестика. Одним из самых распространенных способов является градиентный спуск.
Сначала находится градиент погрешности на «1» по отношению к w. Градиент является уровнем наклона кривой в соответствующей точке. Он изображен на графике в виде черных стрелок. Градиент также дает некоторую информацию о направлении — если он положителен при увеличении w, то в этом направлении погрешность будет увеличиваться, если отрицательный — уменьшаться (см. График). Как вы уже поняли, мы пытаемся сделать, чтобы погрешность с каждым шагом уменьшалась. Величина градиента показывает, как быстро кривая погрешности или функция меняется в соответствующей точке. Чем больше значение, тем быстрее меняется погрешность в соответствующей точке в зависимости от w.
Метод градиентного спуска использует градиент, чтобы принимать решение о следующей смены в w для того, чтобы достичь минимального значения кривой. Он итеративным методом, каждый раз обновляет значение w через:
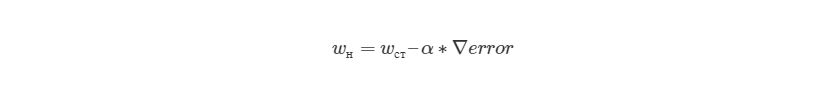
, где wн означает новое значение w, wст— текущее или «старое» значение w, ?error является градиентом погрешности на wст и ? является шагом. Шаг ? также будет означать, как быстро ответ приближается к минимальной погрешности. При каждой итерации в таком алгоритме градиент должен уменьшаться. Из графика выше можно заметить, что с каждым шагом градиент «стихает». Как только ответ достигнет минимального значения, мы уходим из итеративного процесса. Выход можно реализовать способом условия «если погрешность меньше некоторого числа». Это число называют точностью.
4.1 Простой пример на коде
Рассмотрим пример простой имплементации градиентного спуска для нахождения минимума функции f(x)=x4-3x3+2 на языке Python . Градиент этой функции можно найти аналитически через производную f»(x)=4x3-9x2. Это означает, что для любого xx мы можем найти градиент по этой простой формуле. Мы можем найти минимум через производную — x=2.25.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | x_old=# Нет разницы, какое значение, главное abs(x_new - x_old) > точность x_new=6# Алгоритм начинается с x = 6 gamma=0.01# Размер шага precision=0.00001# Точность def df(x): y=4*x **3-9*x **2 returny whileabs(x_new-x_old)>precision: x_old=x_new x_new+=-gamma *df(x_old) print("Локальный минимум находится на %f"%x_new) |
Вывод этой функции: «Локальный минимум находится на 2.249965», что удовлетворяет правильному ответу с некоторой точностью. Этот код реализует алгоритм изменения веса, о котором рассказывалось выше, и может находить минимум функции с соответствующей точностью. Это был очень простой пример градиентного спуска, нахождение градиента при обучении нейронной сети выглядит несколько иначе, хотя и главная идея остается той же — мы находим градиент нейронной сети и меняем веса на каждом шагу, чтобы приблизиться к минимальной погрешности, которую мы пытаемся найти. Но в случае ИНС нам нужно будет реализовать градиентный спуск с многомерным вектором весов.
Мы будем находить градиент нейронной сети, используя достаточно популярный метод обратного распространения ошибки, о котором будет написано позже. Но сначала нам нужно рассмотреть функцию погрешности более детально.
4.2 Функция оценки
Существует более общий способ изобразить выражения, которые дают нам возможность уменьшить погрешность. Такое общее представление называется функция оценки. Например, функция оценки для пары вход-выход (xz, yz) в нейронной сети будет выглядеть следующим образом:
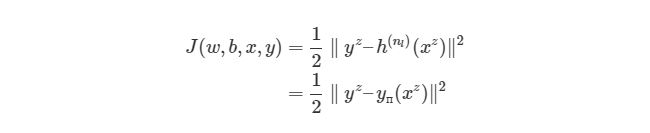
Выражение является функцией оценки учебного экземпляра zth, где h(nl)является выходом последнего слоя, то есть выход нейронной сети. h(nl) можно представить как yпyп, Что означает полученный результат, когда нам известен вход xz. Две вертикальные линии означают норму L2 погрешности или сумму квадратов ошибок. Сумма квадратов погрешностей является довольно распространенным способом представления погрешностей в системе машинного обучения. Вместо того, чтобы брать абсолютную погрешность abs(ypred(xz)-yz), мы берем квадрат погрешности. Мы не будем обсуждать причину этого в данной статье. 1/2 в начале просто константой, которая нормализует ответ после того, как мы продифференцируем функцию оценки во время обратного распространения.
Обратите внимание, что приведенная ранее функция оценки работает только с одной парой (x,y). Мы хотим минимизировать функцию оценки со всеми mm парами вход-выход:
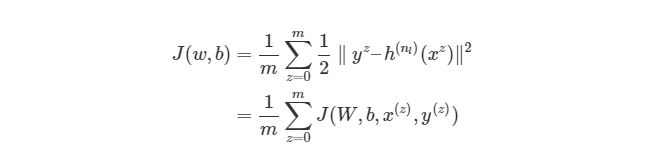
Тогда как же мы будем использовать функцию J для обучения наших сетей? Конечно, используя градиентный спуск и обратное распространение ошибок. Сначала рассмотрим градиентный спуск в нейронных сетях более детально.
4.3 Градиентный спуск в нейронных сетях
Градиентный спуск для каждого веса w(ij)(l) и смещение bi(l) в нейронной сети выглядит следующим образом:
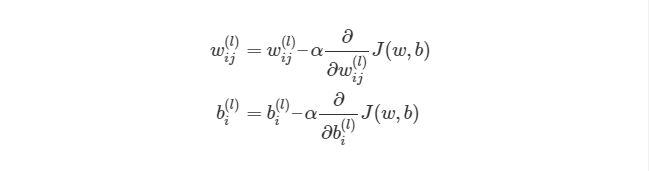
Выражение выше фактически аналогично представлению градиентного спуска:
wnew=wold-?*?error. Нет лишь некоторых обозначений, но достаточно понимать, что слева расположены новые значения, а справа — старые. Опять же задействован итерационный метод для расчета весов на каждой итерации, но на этот раз основываясь на функции оценки J(w,b).
Значения ?/?wij(l)и ?/?bi(l) являются частными производными функции оценки, основываясь на значениях веса. Что это значит? Вспомните простой пример градиентного спуска ранее, каждый шаг зависит от наклона погрешности / оценки по отношению к весу. Производная также имеет значение наклона / градиента. Конечно, производная обозначается как d/dx. x в нашем случае является вектором, а это значит, что наша производная тоже будет вектором, который является градиент каждого измерения x.
4.4 Пример двумерного градиентного спуска
Рассмотрим пример стандартного двумерного градиентного спуска. Ниже представлены диаграмму работы двух итеративных двумерных градиентных спусков:
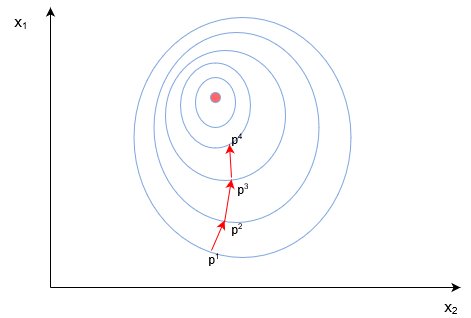
Синим обозначены контуры функции оценки, они обозначают области, в которых значение погрешности примерно одинаковы. Каждый шаг (p1?p2?p3) В градиентном спуске используют градиент или производную, которые обозначаются стрелкой / вектором. Этот вектор проходит через два пространства [x1, x2][x1,x2]и показывает направление, в котором находится минимум. Например, производная, исчисленная в p1 может быть d/dx=[2.1,0.7], Где производная является вектором с двумя значениями. Частичная производная ?/?x1 в этом случае равна скаляру ?[2.1]- иными словами, это значение градиента только в одном измерении поискового пространства (x1).
В нейронных сетях не существует простой полной функции оценки, с которой можно легко посчитать градиент, похожей на функцию, которую мы ранее рассматривали f(x)=x4-3x3+2). Мы можем сравнить выход нейронной сети с нашим ожидаемым значением y(z), После чего функция оценки будет меняться из-за изменения в значениях веса, но как мы это сделаем со всеми скрытыми слоями в сети?
Поэтому нам нужен метод обратного распространения. Этот метод дает нам возможность «делить» функцию оценки или ошибку со всеми весами в сети. Другими словами, мы можем выяснить, как каждый вес влияет на погрешность.
4.5 Углубляемся в обратное распространение
Если математика вам не очень хорошо дается, то вы можете пропустить этот раздел. В следующем разделе вы узнаете, как реализовать обратное распространение языке программирования. Но если вы не против немного больше поговорить о математике, то продолжайте читать, вы получите более глубокие знания по обучению нейронных сетей.
Сначала, давайте вспомним базовые уравнения для нейронной сети с тремя слоями из предыдущих разделов:
Выход этой нейронной сети находится по формуле:
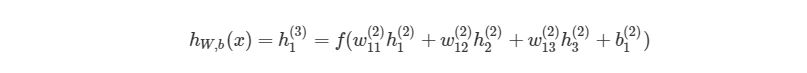
Мы можем упростить это уравнение к h1(3)=f(z1(2)), добавив новое значение z1(2), которое означает:
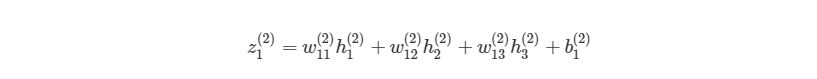
Предположим, что мы хотим узнать, как влияет изменение в весе w12(2) на функцию оценки. Это означает, что нам нужно вычислить ?J/?w12(2). Чтобы сделать это, нужно использовать правило дифференцирования сложной функции:
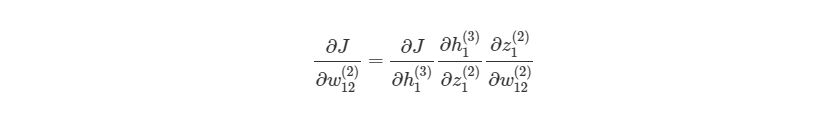
Если присмотреться, то правая часть полностью сокращается (по принципу 2552=22=1). ?J?w12(2) были разбиты на три множителя, два из которых можно прекрасно заменить. Начнем с ?z1(2)/?w12(2):
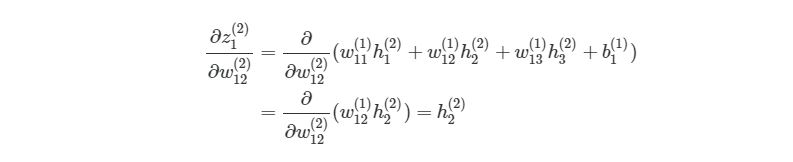
Частичная производная z1(2) по w12(2) зависит только от одного произведения в скобках, w12(1)h2(2), Так как все элементы в скобках, кроме w12(2), не изменяются. Производная от константы всегда равна 1, а ?/?w12(2))сокращается до просто h2(2), Что является обычным выходом второго узла из слоя 2.
Следующая частичная производная сложной функции ?h1(3)/?z1(2) является частичной производной активационной функции выходного узла h1(3). Так что нам нужно брать производные активационной функции, следует условие ее включения в нейронные сети — функция должна быть дифференцированной. Для сигмоидальной активационной функции производная будет выглядеть так:
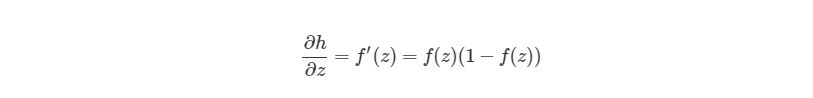
, где f(z)является самой активационной функцией. Теперь нам нужно разобраться, что делать с ?J?h1(3). Вспомните, что J(w,b,x,y) есть функция квадрата погрешности, выглядит так:
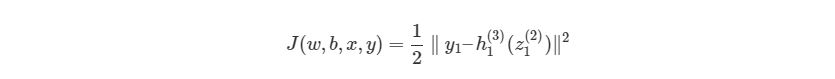
здесь y1 является ожидаемым выходом для выходного узла. Опять используем правило дифференцирования сложной функции:
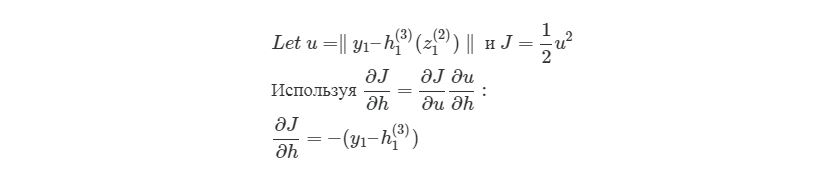
Мы выяснили, как находить ?J/?w12(2)по крайней мере для весов связей с исходным слоем. Перед тем, как перейти к одному из скрытых слоев, введем некоторые новые значения ?, чтобы немного сократить наши выражения:
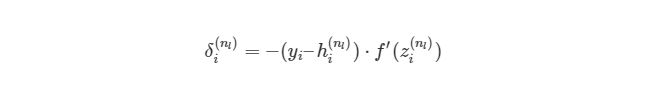
, где i является номером узла в выходном слое. В нашем примере есть только один узел, поэтому i=1. Напишем полный вид производной функции оценки:
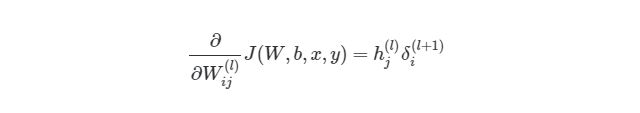
, где выходной слой, в нашем случае, l=2, а i соответствует номеру узла.
4.6 Распространение в скрытых слоях
Что делать с весами в скрытых слоях (в нашем случае в слое 2)? Для весов, которые соединены с выходным слоем, производная ?J/?h=-(yi-hi(nl))имела смысл, т.к. функция оценки может быть сразу найдена через сравнение выходного слоя с существующими данными. Но выходы скрытых узлов не имеют подобных уже существующих данных для проверки, они связаны с функцией оценки только через другие слои узлов. Как мы можем найти изменения в функции оценки из-за изменений весов, которые находятся глубоко в нейронной сети? Как уже было сказано, мы используем метод обратного распространения.
Мы уже сделали тяжелую работу по правилу дифференцирования сложных функций, теперь рассмотрим все более графически. Значение, которое будет обратно распространяться, — ?i(nl), т.к. оно в ближайшей связи с функцией оценки. А что с узлом j во втором слое (скрытом слое)? Как он влияет на ?i(nl) в нашей сети? Он меняет другие значения из-за веса wij(2)(см. диаграмму ниже, где j=1 i=1).
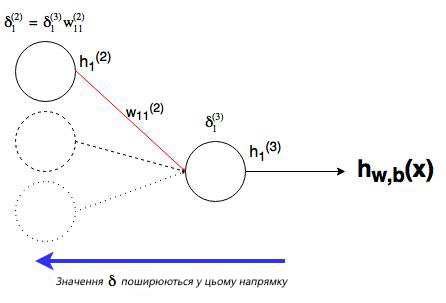
Как можно понять из рисунка, выходной слой соединяется со скрытым узлом из-за веса. В случае, когда в исходном слое есть только один узел, общее выражение скрытого слоя будет выглядеть так:
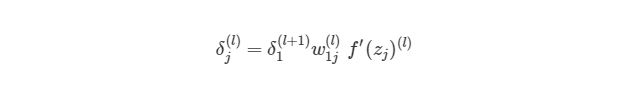
, где j номер узла в слое l. Но что будет, если в исходном слое находится много выходных узлов? В этом случае ?j(l) находится по взвешенной сумме всех связанных между собой погрешностей, как показано на диаграмме ниже:
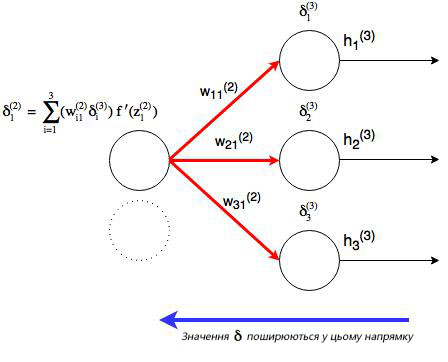
На рисунке показано, что каждое значение ? из исходного слоя суммируется для нахождения ?1(2), Но каждый выход ? должен быть взвешенным соответствующими значению wi1(2). Другими словами, узел 1 в слое 2 способствует изменениям погрешностей в трех выходных узлах, при этом полученная погрешность (или значение функции оценки) в каждом из этих узлов должна быть «передана назад» значению ? этого узла. Сформируем общее выражение значение ? для узлов в скрытом слое:
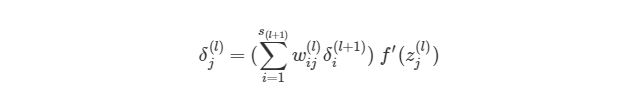
, где j является номером узла в слое l, i- номер узла в слое l+1(что аналогично обозначениям, которое мы использовали ранее). s(l+1)— это количество узлов в слое l+1.
Теперь мы знаем, как находить:
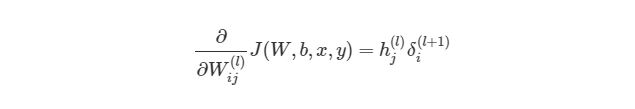
Но что делать с весами смещения? Принцип работы с ними аналогичный обычным весам, используя правила дифференцирования сложных функций:
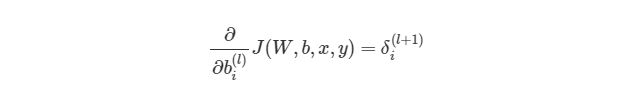
Отлично, теперь мы знаем, как реализовать градиентный спуск в нейронных сетях:
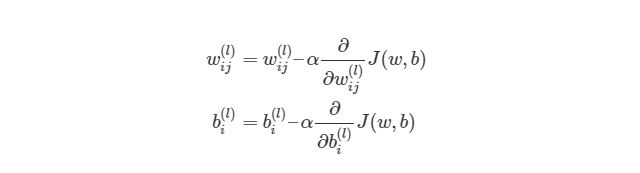
Однако, для такой реализации, нам нужно будет снова применить циклы. Как мы уже знаем из предыдущих разделов, циклы в языке программирования Python работают довольно медленно. Нам нужно будет понять, как можно векторизовать такие подсчеты.
4.7 Векторизация обратного распространения
Для того, чтобы понять, как векторизовать процесс градиентного спуска в нейронных сетях, рассмотрим сначала упрощенную векторизованную версию градиента функции оценки (внимание: это пока неправильная версия!):
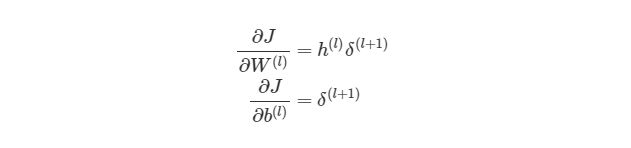
Что представляет собой h(l)? Все просто, вектор (sl?1), где sl является количеством узлов в слое l. Как тогда выглядит произведение h(l)?(l+1)? Мы знаем, что ???J/?W(l) должно быть того же размера, что и матрица весов W(l), Мы также знаем, что результат h(l)?(l+1) должен быть того же размера, что и матрица весов для слоя l. Иными словами, произведение должно быть размера (sl + 1? sl).
Мы знаем, что ?(l+1) имеет размер (sl+1?1), а h (l)— размер (sl?1). По правилу умножения матриц, если матрицу (n?m)умножить на матрицу (o?p), То мы получим матрицу размера (n?p). Если мы просто перемножим h(l) на ?(l+1), то количество столбцов в первом векторе (один столбец) не будет равно количеству строк во втором векторе (3 строки). Поэтому, для того, чтобы можно было умножить эти матрицы и получить результат размера (sl+1? sl), Нужно сделать трансформирование. Оно меняет в матрице столбцы на строки и наоборот (например матрицу вида (sl?1)на (1?sl)). Трансформирование обозначается как буква T над матрицей. Мы можем сделать следующее:
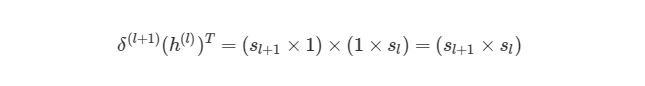
Используя операцию трансформирования, мы можем достичь результата, который нам нужен.
Еще одно трансформирование нужно сделать с суммой погрешностей в обратном распространении:
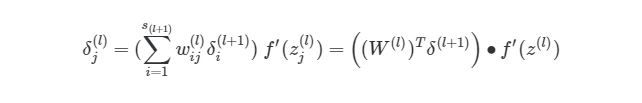
символ (?) в предыдущем выражении означает поэлементное умножение (произведение Адамара), не является умножением матриц. Обратите внимание, что произведение матриц (((W(l))T?(l+1))требует еще одного сложения весов и значений ?.
4.8 Реализация этапа градиентного спуска
Как тогда интегрировать векторизацию в этапы градиентного спуска нашего алгоритма? Во-первых, вспомним полный вид нашей функции оценки, который нам нужно сократить:
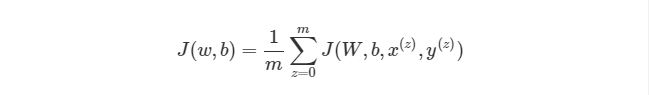
Из формулы видно, что полная функция оценки состоит из суммы поэтапных расчетов функции оценки. Также следует вспомнить, как находится градиентный спуск (поэлементная и векторизованная версии):
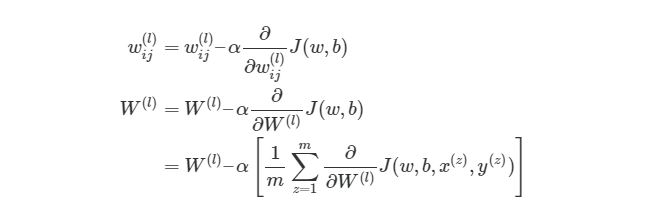
Это означает, что по прохождению через экземпляры обучения нам нужно иметь отдельную переменную, которая равна сумме частных производных функции оценки каждого экземпляра. Такая переменная соберет в себе все значения для «глобального» подсчета. Назовем такую «суммированную» переменную ?W(l). Соответствующая переменная для смещения будет обозначаться как ?b(l). Следовательно, при каждой итерации в процессе обучения сети нам нужно будет сделать следующие шаги:
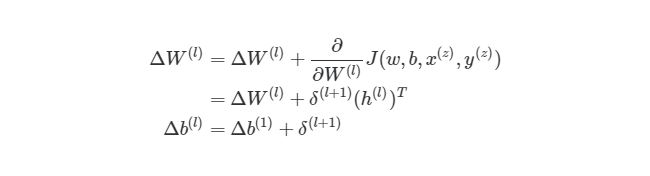
Выполняя эти операции на каждой итерации, мы подсчитываем упомянутую ранее сумму ?mz= 1?/?W(l)J( w , b , x(z), y(z))(и аналогичная формула для b). После того, как будут проитерированы все экземпляры и получены все значения ?, мы обновляем значения параметров веса:
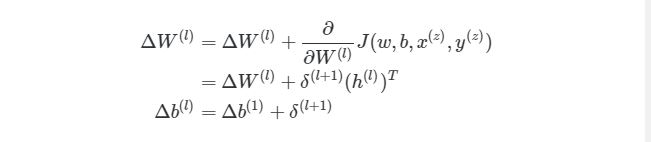
4.9 Конечный алгоритм градиентного спуска
И, наконец, мы пришли к определению метода обратного распространения через градиентный спуск для обучения наших нейронных сетей. Финальный алгоритм обратного распространения выглядит следующим образом:
Рандомная инициализация веса для каждого слоя W(l). Когда итерация < границы итерации:
01. Зададим ?W и ?b начальное значение ноль
02. Для экземпляров от 1 до m: а. Запустите процесс прямого распространения через все nl слоев. Храните вывод активационной функции в h(l)б. Найдите значение ?( nl) выходного слоя. Обновите ?W(l)и ?b( l ) для каждого слоя
03. Запустите процесс градиентного спуска, используя:
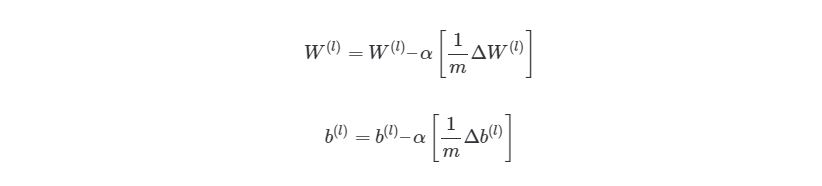
Из этого алгоритма следует, что мы будем повторять градиентный спуск, пока функция оценки не достигнет минимума. На этом этапе нейросеть считается обученной и готовой к использованию.
Далее мы попробуем реализовать этот алгоритм на языке программирования для обучения нейронной сети распознаванию чисел, написанных от руки.
5 Имплементация нейросети языке Python
В предыдущем разделе мы рассмотрели теорию по обучению нейронной сети через градиентный спуск и метод обратного распространения. В этом разделе мы используем полученные знания на практике — напишем код, который прогнозирует, основываясь на данных MNIST. База данных MNIST — это набор примеров в нейронных сетях и глубинном обучении. Она включает в себя изображения цифр, написанных от руки, с соответствующими ярлыками, которые объясняют, что это за число. Каждое изображение размером 8х8 пикселей. В этом примере мы используем сети данных MNIST для библиотеки машинного обучения scikit learn в языке программирования Python . Пример такого изображения можно увидеть под кодом:
1 2 3 4 5 6 7 8 9 10 | from sklearn.datasets import load_digits digits=load_digits() print(digits.data.shape) import matplotlib.pyplot asplt plt.gray() plt.matshow(digits.images[1]) plt.show() |
Код, который мы собираемся написать в нашей нейронной сети, будет анализировать цифры, которые изображают пиксели на изображении. Для начала, нам нужно отсортировать входные данные. Для этого мы сделаем две следующие вещи:
01. Масштабировать данные
02. Разделить данные на тесты и учебные тесты
5.1 Масштабирование данных
Почему нам нужно масштабировать данные? Во-первых, рассмотрим представление пикселей одного из сетов данных:
1 2 3 4 5 6 7 8 9 10 11 | digits.data[,:] Out[2]: array([0.,0.,5.,13.,9.,1.,0.,0.,0.,0.,13., 15.,10.,15.,5.,0.,0.,3.,15.,2.,0.,11., 8.,0.,0.,4.,12.,0.,0.,8.,8.,0.,0., 5.,8.,0.,0.,9.,8.,0.,0.,4.,11.,0., 1.,12.,7.,0.,0.,2.,14.,5.,10.,12.,0., 0.,0.,0.,6.,13.,10.,0.,0.,0. ]) |
Заметили ли вы, что входные данные меняются в интервале от 0 до 15? Достаточно распространенной практикой является масштабирование входных данных так, чтобы они были только в интервале от [0, 1], или [1, 1]. Это делается для более легкого сравнения различных типов данных в нейронной сети. Масштабирование данных можно легко сделать через библиотеку машинного обучения scikit learn:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | from sklearn.preprocessing import StandardScaler X_scale=StandardScaler() X=X_scale.fit_transform(digits.data) X[,:] Out[3]: array([0.,-0.33501649,-0.04308102,0.27407152,-0.66447751, -0.84412939,-0.40972392,-0.12502292,-0.05907756,-0.62400926, 0.4829745,0.75962245,-0.05842586,1.12772113,0.87958306, -0.13043338,-0.04462507,0.11144272,0.89588044,-0.86066632, -1.14964846,0.51547187,1.90596347,-0.11422184,-0.03337973, 0.48648928,0.46988512,-1.49990136,-1.61406277,0.07639777, 1.54181413,-0.04723238,0.,0.76465553,0.05263019, -1.44763006,-1.73666443,0.04361588,1.43955804,0., -0.06134367,0.8105536,0.63011714,-1.12245711,-1.06623158, 0.66096475,0.81845076,-0.08874162,-0.03543326,0.74211893, 1.15065212,-0.86867056,0.11012973,0.53761116,-0.75743581, -0.20978513,-0.02359646,-0.29908135,0.08671869,0.20829258, -0.36677122,-1.14664746,-0.5056698,-0.19600752]) |
Стандартный инструмент масштабирования в scikit learn нормализует данные через вычитание и деление. Вы можете видеть, что теперь все данные находятся в интервале от -2 до 2. По же на счет выходных данных yy, то обычно нет необходимости их масштабировать.
5.2 Создание тестов и учебных наборов данных
В машинном обучении появляется такой феномен, который называется «переобучением». Это происходит, когда модели, во время учебы, становятся слишком запутанными — они достаточно хорошо обучены, но когда им передаются новые данные, которые они никогда на «видели», то результат, который они выдают, становится плохим. Иными словами, модели генерируются не очень хорошо. Чтобы убедиться, что мы не создаем слишком сложные модели, обычно набор данных разбивают на учебные наборы и тестовые наборы. Учебный набором данных, на которых модель будет учиться, а тестовый набор — это данные, на которых модель будет тестироваться после завершения обучения. Количество учебных данных должно быть всегда больше тестовых данных. Обычно они занимают 60-80% от набора данных.
Опять же, scikit learn легко разбивает данные на учебные и тестовые наборы:
1 2 3 4 5 | from sklearn.model_selection import train_test_split y=digits.target X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.4) |
В этом случае мы выделили 40% данных на тестовые наборы и 60% соответственно на обучение. Функция train_test_split в scikit learn добавляет данные рандомно в различные базы данных — то есть, функция не берет первые 60% строк для учебного набора, а то, что осталось, использует как тестовый.
5.3 Настройка выходного слоя
Для того, чтобы получать результат — числа от 0 до 9, нам нужен выходной слой. Более-менее точная нейросеть, как правило, имеет выходной слой с 10 узлами, каждый из которых выдает число от 0 до 9. Мы хотим научить сеть так, чтобы, например, при цифре 5 на изображении, узел с цифрой 5 в исходном слое имел наибольшее значение. В идеале, мы бы хотели иметь следующий вывод: [0, 0, 0, 0, 0, 1, 0, 0, 0, 0]. Но на самом деле мы можем получить что-то похожее на это: [0.01, 0.1, 0.2, 0.05, 0.3, 0.8, 0.4, 0.03, 0.25, 0.02]. В таком случае мы можем взять крупнейших индекс в исходном массиве и считать это нашим полученным числом.
В данных MNIST нужны результаты от изображений записаны как отдельное число. Нам нужно конвертировать это единственное число в вектор, чтобы его можно было сравнивать с исходным слоем с 10 узлами. Иными словами, если результат в MNIST обозначается как «1», то нам нужно его конвертировать в вектор: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]. Такую конвертацию осуществляет следующий код:
1 2 3 4 5 6 7 8 | import numpy asnp def convert_y_to_vect(y): y_vect=np.zeros((len(y),10)) foriinrange(len(y)): y_vect[i,y[i]]=1 returny_vect |
1 2 3 4 5 6 7 | y_v_train=convert_y_to_vect(y_train) y_v_test=convert_y_to_vect(y_test) y_train[],y_v_train[] Out[8]: (1,array([0.,1.,0.,0.,0.,0.,0.,0.,0.,0.])) |
Этот код конвертирует «1» в вектор [0, 1, 0, 0, 0, 0, 0, 0, 0, 0].
5.4 Создаем нейросеть
Следующим шагом является создание структуры нейронной сети. Для входного слоя, мы знаем, что нам нужно 64 узла, чтобы покрыть 64 пикселей изображения. Как было сказано ранее, нам нужен выходной слой с 10 узлами. Нам также потребуется скрытый слой в нашей сети. Обычно, количество узлов в скрытых слоях не менее и не больше количества узлов во входном и выходном слоях. Объявим простой список на языке Python , который определяет структуру нашей сети:
1 2 3 | nn_structure=[64,30,10] |
Мы снова используем сигмоидальную активационную функцию, так что сначала нужно объявить эту функцию и ее производную:
1 2 3 4 | deff(x): return1/(1+np.exp(-x)) |
1 2 3 4 | def f_deriv(x): returnf(x)*(1-f(x)) |
Сейчас мы не имеем никакого представления, как выглядит наша нейросеть. Как мы будем ее учить? Вспомним наш алгоритм из предыдущих разделов:
Рандомно инициализируем веса для каждого слоя W(l) Когда итерация <границы итерации:
01. Зададим ?W и ?b начальное значение ноль
02. Для экземпляров от 1 до m: а. Запустите процесс прямого распространения через все nl слоев. Храните вывод активационной функции в h(l)б. Найдите значение ?( nl) выходного слоя. Обновите ?W(l)и ?b( l ) для каждого слоя
03. Запустите процесс градиентного спуска, используя:
Значит первым этапом является инициализация весов для каждого слоя. Для этого мы используем словари в языке программирования Python (обозначается через {}). Рандомные значения предоставляются весам для того, чтобы убедиться, что нейросеть будет работать правильно во время обучения. Для рандомизации мы используем random_sample из библиотеки numpy. Код выглядит следующим образом:
1 2 3 4 5 6 7 8 9 10 | import numpy.random asr def setup_and_init_weights(nn_structure): W={} b={} forlinrange(1,len(nn_structure)): W[l]=r.random_sample((nn_structure[l],nn_structure[l-1])) b[l]=r.random_sample((nn_structure[l],)) returnW,b |
Следующим шагом является присвоение двум переменным ?W и ?b нулевых начальных значений (они должны иметь такой же размер, что и матрицы весов и смещений)
1 2 3 4 5 6 7 8 9 | def init_tri_values(nn_structure): tri_W={} tri_b={} forlinrange(1,len(nn_structure)): tri_W[l]=np.zeros((nn_structure[l],nn_structure[l-1])) tri_b[l]=np.zeros((nn_structure[l],)) returntri_W,tri_b |
Далее запустим процесс прямого распространения через нейронную сеть:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | def feed_forward(x,W,b): h={1:x} z={} forlinrange(1,len(W)+1): #Если первый слой, то весами является x, в противном случае #Это выход из последнего слоя ifl==1: node_in=x else: node_in=h[l] z[l+1]=W[l].dot(node_in)+b[l]# z^(l+1) = W^(l)*h^(l) + b^(l) h[l+1]=f(z[l+1])# h^(l) = f(z^(l)) returnh,z |
И наконец, найдем выходной слой ? (nl) и значение ? (l) в скрытых слоях для запуска обратного распространения:
1 2 3 4 5 | def calculate_out_layer_delta(y,h_out,z_out): # delta^(nl) = -(y_i - h_i^(nl)) * f'(z_i^(nl)) return-(y-h_out)*f_deriv(z_out) |
1 2 3 4 5 | def calculate_hidden_delta(delta_plus_1,w_l,z_l): # delta^(l) = (transpose(W^(l)) * delta^(l+1)) * f'(z^(l)) returnnp.dot(np.transpose(w_l),delta_plus_1)*f_deriv(z_l) |
Теперь мы можем соединить все этапы в одну функцию:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | def train_nn(nn_structure,X,y,iter_num=3000,alpha=0.25): W,b=setup_and_init_weights(nn_structure) cnt= m=len(y) avg_cost_func=[] print('Начало градиентного спуска для {} итераций'.format(iter_num)) whilecnt1: delta[l]=calculate_hidden_delta(delta[l+1],W[l],z[l]) # triW^(l) = triW^(l) + delta^(l+1) * transpose(h^(l)) tri_W[l]+=np.dot(delta[l+1][:,np.newaxis],np.transpose(h[l][:,np.newaxis])) # trib^(l) = trib^(l) + delta^(l+1) tri_b[l]+=delta[l+1] # запускает градиентный спуск для весов в каждом слое forlinrange(len(nn_structure)-1,,-1): W[l]+=-alpha *(1.0/m *tri_W[l]) b[l]+=-alpha *(1.0/m *tri_b[l]) # завершает расчеты общей оценки avg_cost=1.0/m *avg_cost avg_cost_func.append(avg_cost) cnt+=1 returnW,b,avg_cost_func |
Функция сверху должна быть немного объяснена. Во-первых, мы не задаем лимит работы градиентного спуска, основываясь на изменениях или точности функции оценки. Вместо этого, мы просто запускаем её с фиксированным числом итераций (3000 в нашем случае), а затем наблюдаем, как меняется общая функция оценки с прогрессом в обучении. В каждой итерации градиентного спуска, мы перебираем каждый учебный экземпляр (range (len (y)) и запускаем процесс прямого распространения, а после него и обратное распространение. Этап обратного распространения является итерацией через слои, начиная с выходного слоя к началу — range (len (nn_structure), 0, 1). Мы находим среднюю оценку на исходном слое (l == len (nn_structure)). Мы также обновляем значение ?W и ?b с пометкой tri_W и tri_b, для каждого слоя, кроме исходного (исходный слой не имеет никакого связи, который связывает его со следующим слоем).
И наконец, после того, как мы прошлись по всем учебным экземплярам, накапливая значение tri_W и tri_b, мы запускаем градиентный спуск и меняем значения весов и смещений:

После окончания процесса, мы возвращаем полученные вес и смещение со средней оценкой для каждой итерации. Теперь время вызвать функцию. Ее работа может занять несколько минут, в зависимости от компьютера.
1 2 3 | W,b,avg_cost_func=train_nn(nn_structure,X_train,y_v_train) |
Мы можем увидеть, как функция средней оценки уменьшилась после итерационной работы градиентного спуска:
1 2 3 4 5 6 7 | plt.plot(avg_cost_func) plt.ylabel('Средняя J') plt.xlabel('Количество итераций') plt.show() |
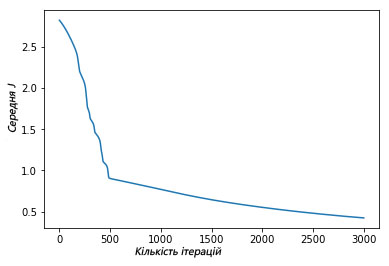
Выше изображен график, где показано, как за 3000 итераций нашего градиентного спуска функция средней оценки снизилась и маловероятно, что подобная итерация изменит результат.
5.5 Оценка точности модели
Теперь, после того, как мы научили нашу нейросеть MNIST, мы хотим увидеть, как хорошо она работает на тестах. Дан входной тест (64 пикселя), нам нужно получить вывод нейронной сети — это делается через запуск процесса прямого распространения через сеть, используя наши полученные значения веса и смещения. Как было сказано ранее, мы выбираем результат выходного слоя через выбор узла с максимальным выводом. Для этого можно использовать функцию numpy.argmax, она возвращает индекс элемента массива с наибольшим значением:
1 2 3 4 5 6 7 8 9 | def predict_y(W,b,X,n_layers): m=X.shape[] y=np.zeros((m,)) foriinrange(m): h,z=feed_forward(X[i,:],W,b) y[i]=np.argmax(h[n_layers]) returny |
Теперь, наконец, мы можем оценить точность результата (процент раз, когда сеть выдала правильный результат), используя функцию accuracy_score из библиотеки scikit learn:
1 2 3 4 5 | from sklearn.metrics import accuracy_score y_pred=predict_y(W,b,X_test,3) accuracy_score(y_test,y_pred)*100 |
Мы получили результат 86% точности. Звучит довольно неплохо? На самом деле, нет, это довольно низкая точностью. В наше время точность алгоритмов глубинного обучения достигает 99.7%, мы немного отстали.
Предлагаем также посмотреть:
Лучший видеокурс по нейронным сетям на русском
Источник: proglib.io