Отжиг и вымораживание: две свежие идеи, как ускорить обучение глубоких сетей
МЕНЮ
Главная страница
Поиск
Регистрация на сайте
Помощь проекту
Архив новостей
ТЕМЫ
Новости ИИ
Городские сумасшедшие
ИИ в медицине
ИИ проекты
Искусственные нейросети
Искусственный интеллект
Слежка за людьми
Угроза ИИ
ИИ теория
Компьютерные науки
Машинное обуч. (Ошибки)
Машинное обучение
Машинный перевод
Нейронные сети начинающим
Психология ИИ
Реализация ИИ
Реализация нейросетей
Создание беспилотных авто
Трезво про ИИ
Философия ИИ
Генетические алгоритмы
Капсульные нейросети
Основы нейронных сетей
Промпты. Генеративные запросы
Распознавание лиц
Распознавание образов
Распознавание речи
Творчество ИИ
Техническое зрение
Чат-боты
Авторизация
2017-07-06 14:12
свёрточные нейронные сети, большие данные big data, алгоритмы машинного обучения

В этом посте изложены две недавно опубликованные идеи, как ускорить процесс обучения глубоких нейронных сетей при увеличении точности предсказания. Предложенные (разными авторами) способы ортогональны друг другу, и могут использоваться совместно и по отдельности. Предложенные здесь способы просты для понимания и реализации. Собственно, ссылки на оригиналы публикаций:
1. Ансамбль снимков: много моделей по цене одной
Обычные ансамбли моделей
Ансамбли — это группы моделей, используемых коллективно для получения предсказания. Идея проста: обучи несколько моделей с разными гиперпараметрами, и усредни их предсказания при тестировании. Эта методика дает заметный прирост в точности предсказания, большинство победителей соревнований по машинному обучению делают это используют ансамбли.
Так в чем проблема?
Обучение N моделей потребует в N раз больше времени по сравнению с тренировкой одной модели. Вместо того, чтобы майнить, приходится тратить ресурсы GPU и долго ждать результатов.
Механика SGD
Стохастический градиентный спуск (SGD) — жадный алгоритм. Он перемещается в пространстве параметров в направлении наибольшего уклона. При этом, есть один ключевой параметр: скорость обучения. Если скорость обучения слишком высока, SGD игнорирует узкие лощины в рельефе гиперплоскости параметров (минимумы) и перескакивает через них как танк через окопы. С другой стороны, если скорость обучения мала, SGD проваливается в один из локальных минимумов и не может выбраться из него.
Однако, есть возможность вытащить SGD из локального минимума повысив скорость обучения.
Следим за руками...
Авторы статьи используют этот контролируемый параметр SGD для скатывания в локальный минимум и выхода оттуда. Разные локальные минимумы могут давать одинаковый процент ошибок при тестировании, но конкретные ошибки для каждого локального минимума будут разными!
На этой картинке очень наглядно поясняется концепция. Слева показано, как работает обычный SGD, пытаясь найти локальный минимум. Справа: SGD проваливается в первый локальный минимум, делается снимок обученной модели, затем SGD выбирается из локального минимума и ищет следующий. Так вы получаете три локальных минимума с одинаковым процентом ошибок, но различающимися характеристиками ошибок.
Из чего состоит ансамбль?
Авторы эксплуатируют свойство локальных минимумов отражать различные «точки зрения» на предсказания модели. Каждый раз, когда SGD достигает локального минимума, сохраняют снимок модели, из которых при тестировании и составят ансамбль.
Циклический косинусный отжиг
Для автоматического принятия решения, когда погружаться в локальный минимум, и когда выходить из него, авторы используют функцию отжига скорости обучения: Формула выглядит громоздко, но на самом деле довольно проста. Авторы используют монотонно убывающую функцию. Альфа — новое значение скорости обученя. Альфа-ноль — предыдущее значение. Т — общее число итераций, которое вы планируете использовать (размер батча Х число эпох). М — число снимков модели, которое хотите получить (размер ансамбля).
Формула выглядит громоздко, но на самом деле довольно проста. Авторы используют монотонно убывающую функцию. Альфа — новое значение скорости обученя. Альфа-ноль — предыдущее значение. Т — общее число итераций, которое вы планируете использовать (размер батча Х число эпох). М — число снимков модели, которое хотите получить (размер ансамбля).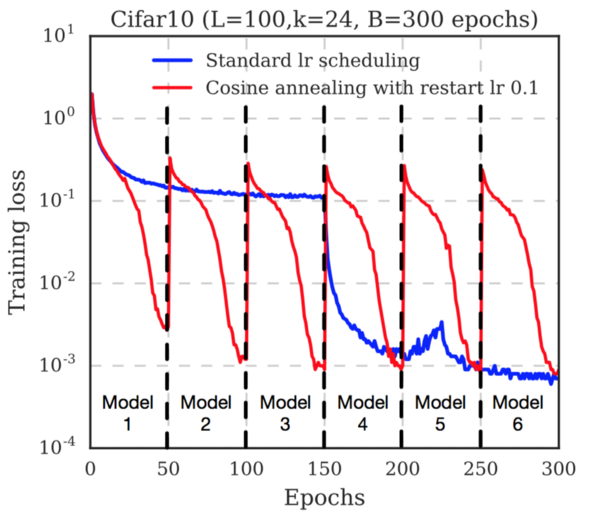
Обратите внимание, как быстро снижается функция потерь перед сохранением каждого снимка. Это потому, что скорость обучения непрерывно снижается. После сохранения снимка скорость обучения восстанавливают (авторы используют уровень 0.1). Это выводит траекторию градиентного спуска из локального минимума, и начинается поиск нового минимума.
Заключение
Авторы приводят результаты тестирования на нескольких датасетах (Cifar 10, Cifar 100, SVHN, Tiny IMageNet) и нескольких популярных архитектурах нейронных сетей (ResNet-110, Wide-ResNet-32, DenseNet-40, DenseNet-100). Во всех случаях ансамбль, обученный предложенным способом показал наименьший процент ошибок.
Таким образом, предложена полезная стратегия получения прироста точности без дополнительных вычислительных затрат при обучении моделей. О влиянии разных параметров, таких как Т и М на производительность, см. оригинал статьи.
2. Вымораживание: ускорение обучения путем последовательного замораживания слоёв
Авторы статьи продемонстрировали ускорение обучения путем замораживания слоёв без потери точности предсказания.
Что означает замораживание слоёв?
Замораживание слоя предотвращает изменение весовых коэффициентов слоя при обучении. Эта методика часто используется при обучении переносом (transfer learning), когда базовую модель, обученную на другом датасете, замораживают.
Как замораживание влияет на скорость модели?
Если вы не хотите изменять весовые коэффициенты слоя, обратный проход по этому слою можно полностью исключить. Это серьезно ускоряет процесс вычислений. Например, если половина слоев в вашей модели заморожена, для тренировки модели потребуется вдвое меньше вычислений.
С другой стороны, вам все-таки нужно обучить модель, так что если вы заморозите слои слишком рано, модель будет давать неточные предсказания.
В чем новизна?
Авторы показали способ, как замораживать слои один за другим как можно раньше, оптимизируя время обучения за счет исключения обратных проходов. В начале модель целиком обучаема, как обычно. После нескольких итераций первый слой модели замораживают, и продолжают обучать остальные слои. После еще нескольких итераций замораживают следующий слой, и так далее.
(Опять) отжиг скорости обучения
Авторы использовали отжиг скорости обучения. Важное отличие их подхода: скорость обучения изменяется от слоя к слою, а не для всей модели. Они использовали следующее выражение: Здесь альфа — скорость обучения, t — номер итерации, i — номер слоя в модели.
Здесь альфа — скорость обучения, t — номер итерации, i — номер слоя в модели.
Обратите внимание, поскольку первый слой модели будет заморожен первым, его тренировка продлится наименьшее количество циклов. Для компенсации этого авторы масштабировали начальный коэффициент обучения для каждого слоя:
В результате, авторы добились ускорения обучения на 20% за счет падения точности на 3%, либо ускорения на 15% без снижения точности предсказания.
Однако, предложенный метод не очень хорошо работает с моделями, в которых не используются пропуски слоёв (такими как VGG-16). В таких сетях ни ускорения, ни влияния на точность предсказания не обнаружено.
Телеграм: t.me/ainewsline
Источник: habrahabr.ru